吴恩达机器学习课程-第六周(part2)
1.机器学习系统的设计
以垃圾邮件分类算法为例开启讨论:
1.1 首先要做什么
一般而言首先需要确定如何选择并表达特征向量 x x x,假设选出垃圾邮件中100个常见词构建一个语料库,当这些词出现该邮件中,便将向量相应位置置为1,于是该邮件的向量表示为 x = [ 0 , 0 , 1 , 1 , . . . ] T x=[0,0,1,1,...]^T x=[0,0,1,1,...]T。
除此之外,为了构建该分类算法,还有很多事可以做:
- 收集更多数据
- 基于邮件的正文构建更复杂的特征
- …
1.2 误差分析
假设在交叉验证集中有500个样本,其中算法分错了100个样本,此时可以通过以下几个方面分析将这100个样本:
- 分错的样本属于什么类别,比如100个中40个是诈骗邮件,后续就可以重点分析这些邮件中的词语分布情况
- 哪些额外特征可以提高分类准确率,比如标点符号等
除此之外,一个量化的数值评估十分重要,它可以直观体现出算法表现是变好和还是变差了,这个数值也称为误差度量值
1.3 类偏斜的误差度量
例如要预测癌症是否是恶性的,1000个训练集中只有5个样本是恶性肿瘤。此时将训练集全部预测为良性肿瘤,分类误差只有 0.5 % 0.5\% 0.5%,但是采用一个复杂的算法训练的分类误差却有 1 % 1\% 1%,这是如果仅通过简单的分类误差判断算法的优劣,会认为全部预测为良性肿瘤这种方式是一种好的分类算法。
出现以上问题的原因在于正例和负例数量差距过大,这也被称为类偏斜。为了解决该问题,可以采用查准率(Precision)和查全率(Recall)。首先需要了解以下概念:
- 正确肯定(True Positive,TP):预测为真,实际为真
- 正确否定(True Negative,TN):预测为假,实际为假
- 错误肯定(False Positive,FP):预测为真,实际为假
- 错误否定(False Negative,FN):预测为假,实际为真
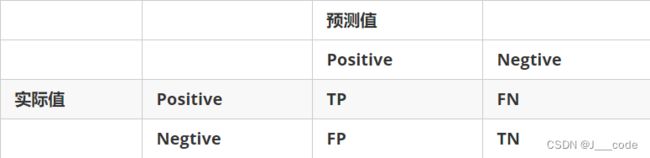
根据上述概念,可以知道查准率和查全率的计算公式:
- P r e c i s i o n = T P / ( T P + F P ) Precision=TP/(TP+FP) Precision=TP/(TP+FP),可以理解为在所有预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好
- R e c a l l = T P / ( T P + F N ) Recall=TP/(TP+FN) Recall=TP/(TP+FN),可以理解为在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好
有了这两个评价指标后,当再次采用全部预测为良性肿瘤的方式,预测恶性肿瘤的数目为0,即 T P = 0 TP=0 TP=0,意味着查全率为0
1.4 查准率和查全率之间的权衡
当 h θ ( x ) ≥ 0.5 h_\theta(x)\ge0.5 hθ(x)≥0.5,预测 y = 1 y=1 y=1(有癌症);当 h θ ( x ) < 0.5 h_\theta(x)\lt0.5 hθ(x)<0.5,预测 y = 0 y=0 y=0(无癌症)
假设此时为了避免随意地判定病人患癌,让其接收治疗,需要要在非常确定的情况下才预测 y = 1 y=1 y=1,可以增加阈值(比如将0.5换为0.7,相对于告诉病人有 70 70% 70的可能性有癌症),这样可以减少错误预测病人为恶性肿瘤的情况,同时也提升了查准率。但此时只会给一小部分病人预测 y = 1 y=1 y=1,自然查全率降低了
假设此时为了防止漏判病人患癌,让其错过最佳治疗时间,需要增加预测为 y = 1 y=1 y=1病人的数目,即提高查全率,此时需要降低阈值,但是降低了查准率,因为预测患有癌症的病人数目变大,错误误差的比例也会变大
对于不同的算法或者不同的阈值,可能算法1的查全率较高但是算法2的查准率较高,如何判断算法的优劣?如何选择阈值?此时需要另一个度量值F1值(F1 Score),选择 F 1 F1 F1最高的算法或阈值即可:

2.参考
https://www.bilibili.com/video/BV164411b7dx?p=65-68
http://www.ai-start.com/ml2014/html/week6.html