PCA详解
本文目录
- 一、来源及作用
-
- 存在问题
- 基本作用
- 二、 基本原理及求解步骤
-
- 核心思想
- 如何选择投影方向
- 三、原理分析
-
- 最大投影方差
- 最小重构代价
- 四、SVD与PCA的关系
一、来源及作用
存在问题
在我们训练模型的过程中,有时会出现在训练集上误差较小,但到了测试集误差又较大,我们称之为泛化误差,造成这种现象往往是以下几个原因:
- 训练数据不足
- 训练集与测试集数据分布不同
- 特征维度过高,造成过拟合
而为了解决这一问题,我们又有以下几种方法:
- 增加样本数量
- 使用正则项
- 对数据进行降维
其中对数据进行降维可以进行人工特征筛选,但往往费时又费力,效果还有可能不好,因此我们可以采用一些模型来进行数据降,其中比较常用的就是PCA(Principal Component Analysis),即主成分分析。
基本作用
PCA经常被用作以下几个方面:
- 数据降维(降低高维数据,简化计算)
- 数据去噪
- 处理共线特征,降低算法的开销,同时防止样本过拟合
二、 基本原理及求解步骤
核心思想
PCA的核心思想是经过线性变换,将数据从 n n n维线性空间映射至 k k k维( k < n k < n k<n),并且期望在投影方向上信息量最大,同时将数据进行反向重构时代价最小。
比如下面一组数据:
如果我们将其投影至X轴,则其效果如下:
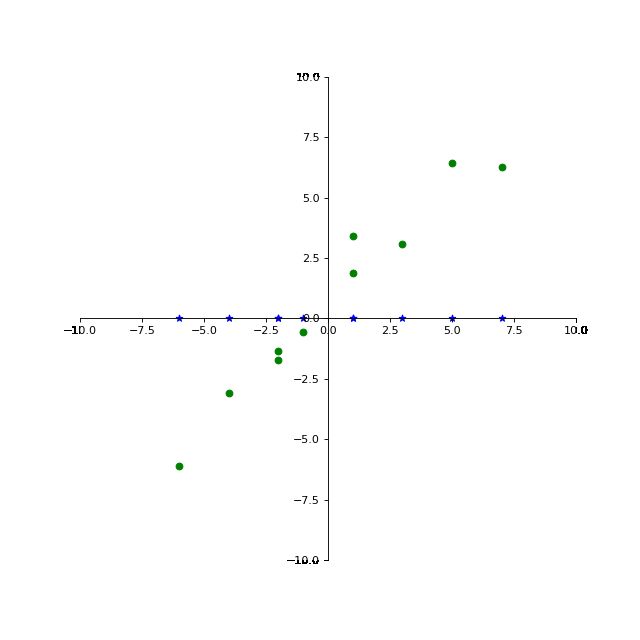
X = [1 7 -4 1 5 -1 3 -2 -6 -2]
Y = [ 1.86379123 6.27582279 -3.08964086 3.39810814 6.43125938 -0.57665254
3.06208316 -1.7341361 -6.09519518 -1.36688637]
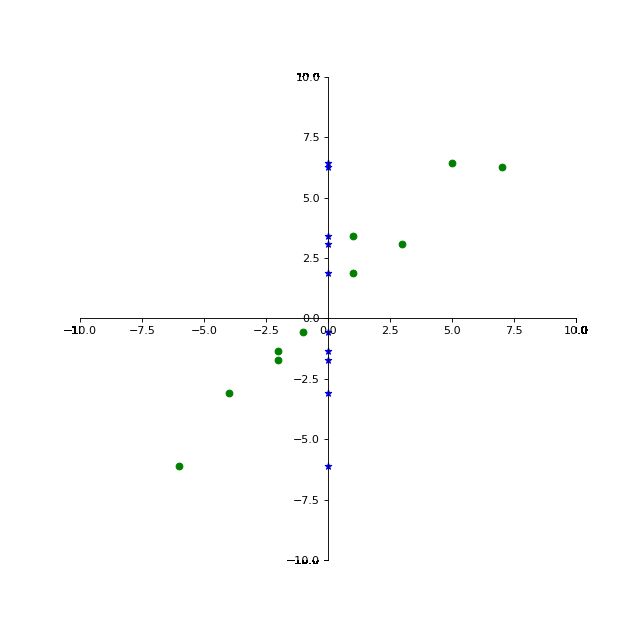
如果我们将其投影至Y轴,则效果如下:
但如果我们将其投影至过原点的一条直线,其效果将变为:
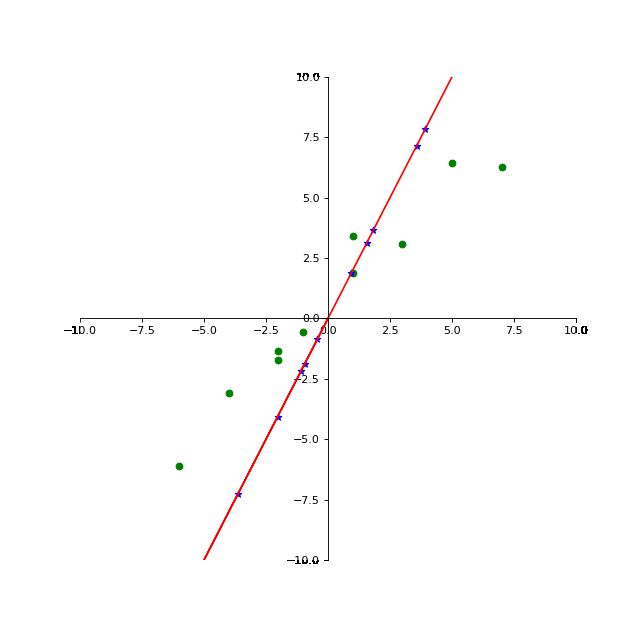
很显然投影至 y = x y=x y=x直线上,更能体现出数据之间的差异性。
如何选择投影方向
1.数据中心化
即所有特征分别减去其各自维度的平均值,其效果就是将所有数据往原点方向整体偏移,处理后的数据平均值为0.
2.求协方差矩阵C
我们以原始特征空间为2维举例: C = [ c o v ( x 1 , x 1 ) c o v ( x 1 , x 2 ) c o v ( x 2 , x 1 ) c o v ( x 2 , x 2 ) ] C= \left[ {\begin{array}{cc} cov(x_1,x_1) & cov(x_1,x_2) \\ cov(x_2,x_1) & cov(x_2,x_2) \\ \end{array} } \right] C=[cov(x1,x1)cov(x2,x1)cov(x1,x2)cov(x2,x2)]
-
C的纬度是 k ∗ k k*k k∗k维的, k k k为特征的数量。
-
对角线上的值分别是 x 1 x_1 x1和 x 2 x_2 x2的方差,非对角线上的是协方差,协方差可以用来描述两个特征之间的相关性,协方差大于0表示 x 1 x_1 x1和 x 2 x_2 x2成正相关,即一个增大,另一个也增大;如果协方差小于0,则说明呈负相关;如果协方差等于0,则说明线性无关。协方差的绝对值越大,相关性越强;反之则越弱
-
其中对于协方差并没有统一的度量值
其中:
c o v ( x , y ) = E [ ( x − E ( x ) ) ( y − E ( y ) ) ] = ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) n \begin{aligned}cov(x,y)&=E[(x-E(x))(y-E(y))]\\&=\frac{\sum\limits_{i=1}^n(x_i-\bar x)(y_i-\bar y)}{n}\end{aligned} cov(x,y)=E[(x−E(x))(y−E(y))]=ni=1∑n(xi−xˉ)(yi−yˉ)
由于中心化后的数据各个维度上的平均值都为0,因此
c o v ( x , y ) = 1 n ∑ i = 1 n x i y i = 1 n x T y \begin{aligned}cov(x,y)&=\frac{1}{n}\sum\limits_{i=1}^nx_iy_i\\&=\frac{1}{n}x^Ty\end{aligned} cov(x,y)=n1i=1∑nxiyi=n1xTy
由此可得: C = 1 n X T X C=\frac{1}{n}X^TX C=n1XTX
- 这里 n n n为样本的数量,X为所有样本的特征构成的矩阵
3.求解协方差矩阵的特征值与特征向量
令 C μ = λ μ C\mu=\lambda\mu Cμ=λμ
就可以解出一组特征值与特征向量 { ( λ 1 , μ 1 ) , ( λ 2 , μ 2 ) . . . ( λ n , μ n ) } \{(\lambda_1,\mu_1),(\lambda_2,\mu_2)...(\lambda_n,\mu_n)\} {(λ1,μ1),(λ2,μ2)...(λn,μn)}
我们将其按照特征值从大到小排列,如果要将数据从 n n n维投影至 k k k维,我们取前 k k k个特征值对应的特征向量,并且将其标准化,使得每个特征向量的模为1,将其从上到下按行排列构成特征矩阵 P P P
P = [ μ 1 μ 2 . . . μ k ] P= \left[ {\begin{array}{cc} \mu_1\\ \mu_2 \\ .\\ .\\ .\\ \mu_k \end{array} } \right] P=⎣⎢⎢⎢⎢⎢⎢⎡μ1μ2...μk⎦⎥⎥⎥⎥⎥⎥⎤
4.将原始特征投影到新的特征空间
我们设投影后的的特征为 Y Y Y:
Y = P X Y=PX Y=PX即为降维后的数据
三、原理分析
对于上述PCA的降维步骤,我们心里一定有一个疑惑,即为什么要用协方差矩阵的特征向量作为投影方向,一开始我们提到过,PCA的目标可以从两方面理解,一个是最大投影方差,还有是最小重构距离,下面将从两方面进行推导。
最大投影方差
对于某一原始的特征 x i x_i xi,其中心化后的值变为 x i − x ˉ i x_i-\bar x_i xi−xˉi。假设我们要向某一基准向量为 u i u_i ui的方向投影,由于 u i u_i ui为基准向量,所以其模为1,即 u i T u i = 1 u_i^Tu_i=1 uiTui=1,我们设两个向量间的夹角为 θ \theta θ,那么其投影后的向量就可以表示为 ∣ x i − x ˉ i ∣ cos θ |x_i-\bar x_i|\cos\theta ∣xi−xˉi∣cosθ,其中投影前的两个向量的内积为 ∣ x i − x ˉ i ∣ ∣ u i ∣ cos θ |x_i-\bar x_i||u_i|\cos\theta ∣xi−xˉi∣∣ui∣cosθ,因此可得投影后的向量就等于两个向量的内积 ( x i − x ˉ i ) T u i (x_i-\bar x_i)^Tu_i (xi−xˉi)Tui。
我们要使投影方差最大,即使得全局投影后的方差最大,投影后全量均值为:
1 n ∑ i = 1 n ( x i − x ˉ i ) T u i = u i ∑ i = 1 n 1 n ( x i − x ˉ i ) T = 0 \frac{1}{n}\sum\limits_{i=1}^n(x_i-\bar x_i)^Tu_i=u_i\sum\limits_{i=1}^n\frac{1}{n}(x_i-\bar x_i)^T=0 n1i=1∑n(xi−xˉi)Tui=uii=1∑nn1(xi−xˉi)T=0
因此投影后的方差为:
J = 1 n ∑ i = 1 n [ ( x i − x ˉ i ) T u i ] 2 = 1 n ∑ i = 1 n u i T ( x i − x ˉ i ) ( x i − x ˉ i ) T u i = u i T ∑ i = 1 n 1 n ( x i − x ˉ i ) ( x i − x ˉ i ) T u i \begin{aligned}J&=\frac{1}{n}\sum\limits_{i=1}^n[(x_i-\bar x_i)^Tu_i]^2\\&=\frac{1}{n}\sum\limits_{i=1}^nu_i^T(x_i-\bar x_i)(x_i-\bar x_i)^Tu_i\\&=u_i^T\sum\limits_{i=1}^n\frac{1}{n}(x_i-\bar x_i)(x_i-\bar x_i)^Tu_i\end{aligned} J=n1i=1∑n[(xi−xˉi)Tui]2=n1i=1∑nuiT(xi−xˉi)(xi−xˉi)Tui=uiTi=1∑nn1(xi−xˉi)(xi−xˉi)Tui
其中 ∑ i = 1 n 1 n ( x i − x ˉ i ) ( x i − x ˉ i ) T \sum\limits_{i=1}^n\frac{1}{n}(x_i-\bar x_i)(x_i-\bar x_i)^T i=1∑nn1(xi−xˉi)(xi−xˉi)T就是中心化后矩阵的协方差矩阵,我们设其为 S S S,因此可以得到:
L = arg max μ i T S u i s . t . u i T u i = 1 \begin{aligned}&L = \argmax\mu_i^TSu_i\\&s.t.\quad u_i^Tu_i=1\end{aligned} L=argmaxμiTSuis.t.uiTui=1
这就变成了一个简单的带约束优化问题,我们将其转化为拉格朗日形式可以得到:
L ( μ i , λ ) = μ i T S μ i + λ ( 1 − μ i T μ i ) L(\mu_i,\lambda)=\mu_i^TS\mu_i+\lambda(1-\mu_i^T\mu_i) L(μi,λ)=μiTSμi+λ(1−μiTμi)
我们对 u i u_i ui求偏导令其等于0得:
∂ L ( μ i , λ ) ∂ μ i = 2 S μ i − 2 λ μ i = 0 \frac{\partial L(\mu_i,\lambda)}{\partial \mu_i}=2S\mu_i-2\lambda\mu_i=0 ∂μi∂L(μi,λ)=2Sμi−2λμi=0
因此可得:
S μ i = λ μ i S\mu_i=\lambda\mu_i Sμi=λμi
所以这里的 λ \lambda λ就可以等同为协方差矩阵的特征值, μ i \mu_i μi为对应的特征向量
我们将其带入 L L L可得 L = arg max μ i T λ μ i L=\argmax \mu_i^T\lambda\mu_i L=argmaxμiTλμi
由于这里 λ \lambda λ是一个实数,因此可以得到: L = arg max λ μ i T μ i = arg max λ L=\argmax \lambda\mu_i^T\mu_i=\argmax\lambda L=argmaxλμiTμi=argmaxλ
所以在进行降维时,优先选取特征值大的特征向量
最小重构代价
重构代价的含义就是将首先将原始空间的向量进行重构,转化成由一组线性无关的向量所构成的向量 x i x_i xi,其与投影后的数据 x ^ i \hat x_i x^i的距离就是重构代价。我们的目的是使得 x i − x ^ i x_i-\hat x_i xi−x^i的距离最小,至于向量间的距离,我们可以用内积来度量。可得: q<p
J = 1 n ∑ i = 1 n ∣ ∣ x i − x ^ i ∣ ∣ 2 J=\frac{1}{n}\sum\limits_{i=1}^n||x_i-\hat x_i||^2 J=n1i=1∑n∣∣xi−x^i∣∣2
我们假设重构后的特征空间为 p p p维,降维后的特征空间为 q q q维( q < p q
降维后的 x ^ i \hat x_i x^i可以表示为:
x ^ i = ∑ k = 1 q ( x i T μ k ) μ k \hat x_i=\sum\limits_{k=1}^q(x_i^T\mu_k)\mu_k x^i=k=1∑q(xiTμk)μk
因此我们可以得到:
J = 1 n ∑ i = 1 n ∣ ∣ ∑ k = q + 1 p ( x i T μ k ) μ k ∣ ∣ 2 = 1 n ∑ i = 1 n ∑ k = q + 1 p ( x i T μ k ) 2 \begin{aligned}J&=\frac{1}{n}\sum\limits_{i=1}^n||\sum\limits_{k=q+1}^p(x_i^T\mu_k)\mu_k||^2\\&=\frac{1}{n}\sum\limits_{i=1}^n\sum\limits_{k=q+1}^p(x_i^T\mu_k)^2\end{aligned} J=n1i=1∑n∣∣k=q+1∑p(xiTμk)μk∣∣2=n1i=1∑nk=q+1∑p(xiTμk)2
这里我们将 x i x_i xi替换成中心化后的点 x i − x ˉ i x_i-\bar x_i xi−xˉi可得:
J = 1 n ∑ i = 1 n ∑ k = q + 1 p [ ( x i − x ˉ i ) T μ k ] 2 = ∑ k = q + 1 p ∑ i = 1 n 1 n [ ( x i − x ˉ i ) T μ k ] 2 \begin{aligned}J&=\frac{1}{n}\sum\limits_{i=1}^n\sum\limits_{k=q+1}^p[(x_i-\bar x_i)^T\mu_k]^2\\&=\sum\limits_{k=q+1}^p\sum\limits_{i=1}^n\frac{1}{n}[(x_i-\bar x_i)^T\mu_k]^2\end{aligned} J=n1i=1∑nk=q+1∑p[(xi−xˉi)Tμk]2=k=q+1∑pi=1∑nn1[(xi−xˉi)Tμk]2
跟最大投影方差中的推导过程类似,我们可以得到:
J = ∑ k = q + 1 p μ k T S μ k J=\sum\limits_{k=q+1}^p\mu_k^TS\mu_k J=k=q+1∑pμkTSμk
其中 S S S为均值化后的协方差矩阵,于是我们可以构造优化问题:
L = arg min ∑ k = q + 1 p μ k T S μ k s . t . μ k T μ k = 1 \begin{aligned}&L=\argmin\sum\limits_{k=q+1}^p\mu_k^TS\mu_k\\&s.t.\quad \mu_k^T\mu_k=1\end{aligned} L=argmink=q+1∑pμkTSμks.t.μkTμk=1
同样构造拉格朗日函数后我们可以得到:
L = arg min ∑ k = q + 1 p λ k L=\argmin\sum\limits_{k=q+1}^p\lambda_k L=argmink=q+1∑pλk
因此在舍弃维度时,优先舍弃特征值较小的
四、SVD与PCA的关系
我们假设经过中心化后的样本为 X X X,前面我们已经推导过,此时的协方差矩阵可以表达为 S = 1 n X T X S=\frac{1}{n}X^TX S=n1XTX
假设我们对 X X X进行奇异值分解为:
X = U Σ V T X=UΣV^T X=UΣVT
其中 U U U和 V V V都是酉矩阵,满足 U T U = I U^TU=I UTU=I以及 V T V = I V^TV=I VTV=I, Σ Σ Σ为对角阵,其对角线上的值为所有奇异值
那么 S S S就可以表示为:
S = 1 n V Σ U T U Σ V T = 1 n V Σ 2 V T \begin{aligned}S&=\frac{1}{n}VΣU^TUΣV^T\\&=\frac{1}{n}VΣ^2V^T\end{aligned} S=n1VΣUTUΣVT=n1VΣ2VT
因此,在数据量较大,不方便直接求解协方差矩阵的情况,我们可以对中心化后的矩阵进行奇异值分解来代替计算