华为开源预训练语言模型「哪吒、TinyBERT」可直接下载使用
近日,华为诺亚方舟实验室的NLP团队开源了两个重要的预训练语言模型-哪吒和TinyBERT, 可以直接下载,预先训练和微调这两个模型。
该项目是诺亚方舟实验室用于开放各种预训练模型的源代码的项目。当前有两个,并且不排除将来会添加更多模型。

Nezha是基于BERT优化和改进的预训练语言模型。中文使用的语料库是Wikipedia和Baike and News,而Google的中文语料库仅使用Wikipedia。与中文一样,英语的Nezha也使用Wikipedia和BookCorpus。
哪吒在培训过程中使用了华为云来启用多卡多机培训。当然,此版本的哪吒与华为版本不同,可以在通用GPU上进行训练。此外,哪吒还使用了Nvidia的混合精度训练方法,该方法在项目开源时也已公开。
开发背景
预先训练的语言模型实质上是神经网络语言模型。
它主要具有两个特征:
- 可以使用大规模的未标记纯文本语料库进行训练,并且可以用于各种下游NLP任务。 每个性能指标都得到了极大的提高,可以解决各种下游任务。
- 该解决方案经过统一和简化,成为一个集中且固定的微调框架。
有两种通用类型的预训练语言模型:
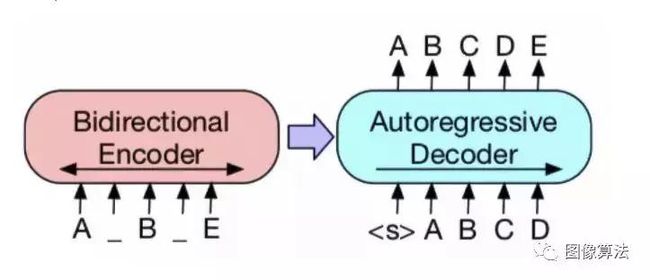
- 一种是编码器,用于自然语言理解。输入全文以了解自然语言。
- 另一个是解码器,它被解码并用于自然语言生成。在没有生成内容的情况下,两种类型的模型有所不同。

预训练模型的关系图
该图列出了诸如BERT,GPT,XLNet,ERNIE之类的模型及其关系,并绘制了一系列相关论文。该列表主要将预训练模型分为三个部分,包括:模型,知识提炼和模型压缩。根据此分类,TinyBERT模型可以归类为“知识蒸馏和模型压缩”部分。NEZHA被归类为“模型”部分。
根据研究结果,最近的模型集中在数据和计算能力上。与早期的ResNet(可视模型)模型参数相比,数据显示GPT1为100M,BERT大为340M,GPT2为1.5BN,GPT-2 8B为8.3BN。

预训练语言模型的结果
在模型方面,他们选择在内部复制Google Bert-base和Bert-large的实验;使用BERT代码,实现了OpenAI GPT-2模型;实现了基于GPU的多卡多机并行训练,训练过程为优化和提高训练效率,我们最终得到了“多中文NLP任务”预训练模型哪吒。
功能相对位置编码
位置编码有两种类型:函数型和参数型。函数公式可以通过定义函数直接计算。参数公式中的位置编码涉及两个概念,一个是距离,另一个是尺寸。其中,文字嵌入一般有几百个维度,每个维度都有一个值,位置码的值由位置和维度两个参数决定。
哪吒预训练模型采用函数相对位置编码,其输出和注意得分的计算涉及到它们相对位置的正弦函数。这种灵感来源于变压器的绝对位置编码,相对位置编码解决了变压器中由于每个字之间的距离未知而引起的一系列资源占用问题。

位置编码模型
具体来说,Transformer首先只考虑绝对位置编码,而且它是功能性的;后来,BERT的建议使用了参数,参数训练受接收语句长度的影响。对于512,如果只训练128个句子,则无法获得128到520之间的位置参数,因此必须训练较长的语料库来确定该部分的参数。
在哪吒模型中,距离和维数是由正弦函数导出的,在模型训练过程中是固定的。换言之,位置码的每个维度对应一个正弦,不同维度的正弦函数具有不同的波长,选择一个固定的正弦函数可以使模型具有更强的可扩展性,即当遇到较长的序列时仍然可以工作。函数式相对位置编码公式,如下图所示:
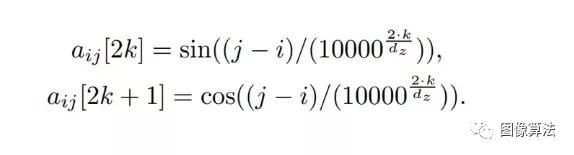
全词覆盖
当前的神经网络模型在语言模型和机器翻译任务中都使用词汇表;在Softmax中,每个单词都必须进行比较。对于每个操作,必须在词汇表中比较所有单词。通常,一个词汇包含数万个单词,机器翻译往往达到6万到7万个单词。因此,词汇是很大一部分语言模型操作的瓶颈。
哪吒预先训练的模型使用全词覆盖(WWM)策略。当一个汉字被覆盖时,属于同一个汉字的其他汉字被覆盖在一起。该策略比BERT中的随机覆盖训练(即每个符号或汉字被随机屏蔽)更有效。
BERT 中的随机覆盖
混合精度训练与LAMB优化器
在哪吒模型的预训练中,研究人员使用了混合精确训练技术。这项技术可以将训练速度提高2-3倍,同时也降低了模型的空间消耗,从而可以利用更大的批量。
传统的深度神经网络训练采用FP32(单精度浮点格式)表示训练中涉及的所有变量(包括模型参数和梯度);而混合精度训练则采用多精度训练。具体来说,它侧重于保证模型中权重(称为主权重)的单精度复制,即在每次训练迭代中,主权重四舍五入为FP16(即半精度浮点格式),权重、激活和梯度向前和向后传递;最后,渐变将转换为FP32格式,主权重将使用FP32渐变进行更新。
LAMB优化器是为深度神经网络的大规模同步分布式训练而设计的。虽然大、小批量DNN训练是加快DNN训练的有效方法,但如果不仔细调整学习率的调度,当批量处理的规模超过一定阈值时,模型的性能可能会受到很大影响。
LAMB优化器不需要手动调整学习速率,而是使用通用的自适应策略。优化器通过使用非常大的批处理大小(在实验中高达30k以上)来加速BERT的训练,而不会导致性能损失,甚至在许多任务中获得最新的性能。值得注意的是,伯特的训练时间最终从3天显著减少到76分钟。

实验结果
实验通过微调各种自然语言理解(NLU)任务,测试了预训练模型的性能,并进行了NEZHA模型和最先进的汉语预训练语言模型:Google BERT(中文版)、BERT-WWM和ERNIE比较(详细参数见论文),最终结果如下:
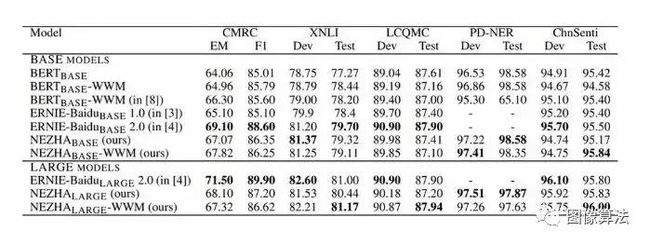
可以看出,论文或源码数据集下载地址:关注“图像算法”微信公众号 回复“哪吒”,哪吒在大多数情况下都取得了较好的成绩,特别是在PD-NER任务下,哪吒达到了最多97.87分。另一个更光明的模式是ERNIE Baidu 2.0,它有超过NEZHA的趋势。对于这种情况,笔者还解释说,由于实验设置或微调方法的不同,比较可能并不完全公平。其他模型的新版本发布后,他们将对其进行评估,并在相同设置下更新此报表。