python 相关性检验怎么计算p值_收藏 | 大神教你用Python预测未来:一文看懂时间序列...
 (由Python大本营付费下载自视觉中国) 作者 | Leandro Rabelo
(由Python大本营付费下载自视觉中国) 作者 | Leandro Rabelo
译者 | 李洁
整理 | Lemonbit
出品 | Python数据之道
本文内容较长,较为详细的阐述了进行时间序列预测的步骤,有些内容可能暂时用不到或者看不懂,但不要紧,知道有这么一个概念,后续碰到的时候,继续深入学习以及使用就可以。
一文弄懂时间序列预测的基本原理
我们被随处可见的模式所包围,人们可以注意到四季与天气的关系模式,以交通量计算的交通高峰期的模式,你的心跳或者是股票市场和某些产品的销售周期。
分析时间序列数据对于发现这些模式和预测未来非常有用。有几种方法可以创建这类预测,在本文中,我将介绍最基本且最传统的方法概念。
所有代码都是用 Python 编写的,并且在 GitHub 上可以看到所有的信息。
https://nbviewer.jupyter.org/github/leandrovrabelo/tsmodels/blob/master/notebooks/english/Basic Principles for Time Series Forecasting.ipynb
那么让我们开始谈谈分析时间序列的初始条件:
1
平稳序列
平稳时间序列是指统计特性,如均值、方差和自相关系数,随时间相对恒定的序列。因此,非平稳序列是统计特性随时间变化的序列。
在开始任何预测建模之前,都有必要验证这些统计属性是否是常量,我将一一解释下面的每个点:
- 常数均值
- 常数方差
- 自相关
常数均值
一个平稳序列在时间上具有一个相对稳定的均值,这个值没有减少或者增加的趋势。围绕常数均值的小的变化,使我们更容易推测未来。在某些情况下,相对于平均值的变量比较小,使用它可以很好地预测未来。下图显示了变量与该常数平均值相对于时间变化的关系:

在这种情况下,如果序列不是平稳的,对未来的预测将是无效的,因为平均值周围的变量会显著偏离,如下图所示:

在上图中,我们可以明显看到上升的趋势,均值正在逐渐上升。在这种情况下,如果使用均值进行未来值的预测,误差将非常大,因为预测价格会总是低于实际价格。
常数方差
当序列的方差为常数时,我们知道均值和标准差之间存在一种关系。当方差不为常数时(如下图所示),预测在某些时期可能会有较大的误差,而这些时期是不可预测的。可以预测到,随着时间的推移直到未来,方差会保持不稳定。
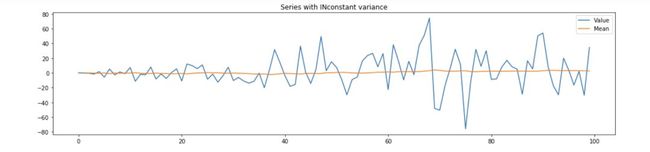
为了减小方差效应,可以采用对数变换。在本例中,也可以使用指数变换,如 Box-Cox 方法,或者使用膨胀率调整。
自相关序列
当两个变量在时间上的标准差有相似的变化时,你可以说这些变量是相关的。例如,体重会随着心脏疾病而增加,体重越大,心脏问题的发生率就越大。在这种情况下,相关性是正的,图形应该是这样的:

负相关的情况类似于这样:对工作安全措施的投入越多,工作相关的事故数量就越少。
下面是几个相关级别的散点图的例子:

当谈到自相关时,意思是某些先前时期与当前时期存在相关性,这种相关性是滞后的。例如,在以小时为单位的测量值序列中,今天 12:00 的温度与 24 小时前的 12:00 的温度非常相似。如果你比较 24 小时内的温度变化,就会存在自相关,在本例中,我们将与第 24 小时前的时间存在自相关关系。
自相关是使用单个变量创建预测的一种情况,因为如果没有相关性,就不能使用过去的值来预测未来;当有多个变量时,则可以验证因变量和独立变量的滞后之间是否存在相关性。
如果一个序列不存在自相关关系,那么它就是随机且不可预测的,做预测的最佳方法通常是使用前一天的值。我将在下面使用更详细的图表来解释。
从这里开始我将分析 Esalq 上的每周含水乙醇价格(这是巴西谈判含水乙醇的价格参考),数据可以在这里(https://www.cepea.esalq.usp.br/br/indicador/etanol.aspx)下载。
价格单位是巴西雷亚尔每立方米(BRL/m3)。
在开始任何分析之前,要将数据划分为训练集和测试集。
划分训练集和测试集数据
当我们要创建时序预测模型时,将数据划分为两部分至关重要:
训练集:这些数据将是定义模型系数/参数的主要依据;
测试集:这些数据将被分离且对模型不可见,用于测试模型是否有效(通常将这些值与模型结果进行比较,最后测量平均误差)。
测试集的大小通常约为总样本的20%,尽管这个百分比取决于你拥有的样本大小以及你希望提前多少时间进行预测。理想情况下,测试集应至少与所需预测的最大范围相同。
与其他如分类和回归等不受时间影响的预测方法不同,在时间序列中,不可以将训练和测试数据从数据中随机抽样取出,我们必须遵循序列的时间标准,训练数据应该始终是在测试数据之前。
在本例中,我们有Esalq 含水乙醇的 856 周的价格数据,使用前 700 周的数据作为训练集,后 156 周(3年,18%)的数据用作测试集:

从现在开始,我们只使用训练集来做研究,测试集仅用于验证我们的预测。
每一个时间序列可以分为三个部分:趋势、季节性和残差,残差是将前两部分从序列中去除后剩下的部分,使用这种分割方法之后:

显然,该序列具有上升趋势,在每一年的年底到年初之间达到峰值,在4月和9月之间达到最低值(此时在巴西中南部开始甘蔗的压榨)。
我们仍然建议使用统计测试来确认序列是否是平稳的,这里将使用两个测试:Dickey-Fuller 测试和 KPSS 测试。
首先,我们将使用 Dickey-Fuller 检验,我将使用 5% 的基础 P 值,也就是说,如果 P 值低于 5% 这意味着这个序列在统计上是平稳的。
此外,还有模型的统计检验,可以将检验值与 1%、5%、10% 的临界值进行比较,如果统计检验低于选定的某个临界值,就认为序列是平稳的:

在本例中,Dickey-Fuller 检验结果表明序列不是平稳的( P 值 36%,临界值 5% 小于统计检验)。
现在我们要用 KPSS 检验分析序列,与 Dickey-Fuller 检验不同,KPSS 检验已经假设序列是平稳的,只有当 P 值小于 5% 或统计检验小于某个临界值时,序列才不是平稳的:
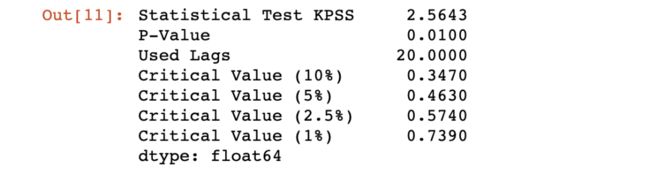
KPSS 检验证实了 Dickey-Fuller 检验的正确性,同时也表明该序列不是平稳的,因为 P 值为 1%,统计检验高于任何临界值。
接下来,我将演示如何将序列转换为平稳状态。
2
将序列转换为平稳状态
差分
差分法用来移除趋势信号,也可以用来减少方差,它只是 T 周期的值与前一个 T-1 周期值的差值。
为了更容易理解,下面我们只用一小部分的乙醇价格,以便更好地可视化,可以看到从 2005 年 5 月开始价格上涨,直到 2006 年 5 月中旬,价格每周都在上涨,这就累积了一个上升的趋势,这种情况下,属于非平稳序列。

当进行一阶微分时(如下图),我们去除了序列的累积效应,并且仅显示了整个系列中时段 T 相对于时段 T-1 的变化,因此如果 3 天前的价格为 800 BRL 且已涨到 850.00 BRL,差价将是 50.00 BRL,如果今天的价格是 860.00 BRL,那么差价将是 - 10.00 BRL。
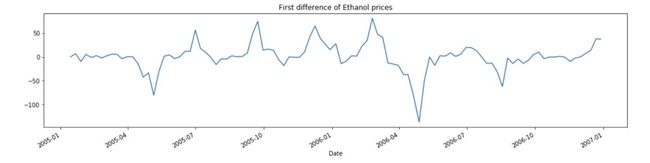
通常只需要一阶微分就足够将序列转换为平稳状态,但如果需要,可以应用二阶微分,在这种情况下,将对一阶微分的值进行求导(几乎没有二阶以上微分的情况)。
同样的例子,要进行二次微分,我们必须取 T 时刻减去 T-1 时刻的微分:2.9 BRL -5.5 BRL = - 2.6 BRL 等等。

我们来做一下 Dickey-Fuller 测试,看看这个序列是否会在一阶微分后是平稳的:

在这种情况下,我们确定该序列是平稳的,P 值为零,并且当我们比较统计检验的值时,它远远低于临界值。
在下一个例子中,我们将尝试调整通货膨胀率将一个序列转换到平稳状态。
膨胀率调整
价格是相对于交易时间的,2002 年乙醇的价格是 680.00 BRL,如果现在产品的价格是这个价格,很多工厂肯定会倒闭,因为这个价格非常低。
为了让序列平稳,我将基于当前值使用巴西 IPCA 索引(巴西的 CPI 指数)调整整个序列,从训练区间的结尾(2016年4月)到研究的开始,数据的来源是 IBGE 网站。

现在我们来看序列如何能变平稳以及是否变平稳。

如图所示,上升趋势已经消失,只剩下季节性振荡, Dickey-Fuller 测试也证实了这个序列现在是稳定的。
如果好奇,可以参阅下面的图表,其中调整后的价格与原始系列的通货膨胀率相对应。
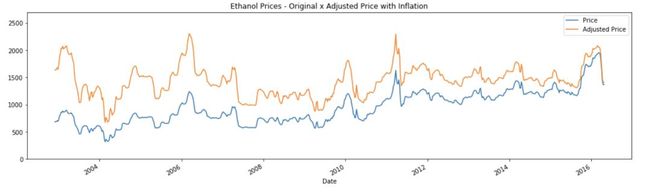
减小方差
对数变换
对数变换通常用于将指数增长的序列转换为具有更趋于线性增长的序列,在本例中,我们将使用自然对数(Natural Logarithm,NL),其底数为 2.718 ,这种对数类型在经济模型中被广泛使用。
转换成 NL 值的差值近似等于原始序列值的百分比变化,作为降低不同价格序列的方差的基础是很有效的,如下例:
如果我们有一个产品在 2000 年价格上涨,从 50.00 BRL 到 52.50 BRL,几年后(2019年),价格已经是 100.00 BRL,已经上涨到 105.00 BRL,价格之间的绝对差分别是 2.50 BRL 和 5.00 BRL,但两者的百分比差为 5% 。
当我们对这些价格中使用 NL 时,我们得到:NL (52.50) - NL(50.00) = 3.96 - 3.912 = 0.048 或 4.8%,同样地,在第二个价格序列中使用 LN 时,我们得到:NL (105) - NL(100) = 4.654-4.605 = 0.049 或 4.9% 。
在这个例子中,我们可以通过把几乎所有的东西都放到相同的基上来减少差异值。
下面还是同一个例子:
1price1 = np.log(52.5) - np.log(50)2price2 = np.log(105) - np.log(100)3printf('The percentage variation of the first example is {round(price1*100,1)} and the second is {round(price2*100,1)}')

原始序列与 NL 序列变换的对比图:

Box-Cox 变换(指数变换)
Box-Cox 转换也是一种转换序列的方法,lambda(λ)的值是用于转换序列的参数。
简而言之,这个函数是几个指数变换函数的结合,我们需要找到转换序列的 lambda 的最佳值,使其分布更接近正态高斯分布。使用此转换的一个条件是序列只有正值,公式为:

接下来我将绘制原始序列及其分布图,然后用 lambda 最佳值绘制新的转换序列及其分布图,为了找到 lambda 的值,我们将使用库 Scipy 的 boxcox 函数生成转换的序列和理想 lambda 值:

下面是一个交互式图表,在图中可以更改 lambda 值和检查更改:
此工具通常用于提高模型的性能,因为它使模型更趋于正态分布,记住在完成模型的预测后,必须根据以下公式反转转换到原始的基数:

寻找相关时滞
为了便于预测,具有单一变量的序列必须具有自相关性,即,当前时段必须是能够基于较早的时段(滞后)而解释的。
由于这个序列每周为一周期,1 年大约 52 周,我将使用 60 的滞后期的自相关函数来验证当前周期与这些滞后的相关性。

通过对上述自相关图的分析,似乎所有的滞后都可以用来为未来事件创建预测,因为它们的正相关接近 1 ,而且都在置信区间之外,但这一特征属于非平稳序列。
另一个非常重要的函数是部分自相关函数,其中消除了先前的滞后对当前区间的影响,只保留了当前区间滞后的影响来分析,例如:第四个滞后的偏自相关将消除第一、第二和第三个滞后的影响。
部分自相关图如下:

可以看到,几乎没有滞后对当前周期有影响,但是正如前面所演示的,没有微分的序列不是平稳的,我们现在用一阶微分的序列绘制这两个函数来展示原理:

自相关曲线变化显著,表明该序列仅在第一个滞后期具有显著相关,在第 26 个滞后(半年)左右具有负相关的季节效应。
为了做出预测,我们必须注意一个找到相关的滞后现象的非常重要的细节,重要的是这种关联背后的原因,因为如果没有逻辑上的原因,就有可能是偶然的,当包含更多的数据时,这种关联就会消失。
另一个重点是自相关和部分自相关图对异常值非常敏感,因此分析时间序列本身并与两个自相关图进行对比非常重要。
在这个例子中,第一个滞后与当前周期具有高度相关性,因为前一周的价格历史上没有显著变化,在相同的情况下,第 26 个滞后呈现负相关,表明与当前时期相反的趋势,可能原因是一年内不同时期供需不同。
随着膨胀率调整后的序列已经趋于平稳,我们将使用它来创建我们的预测,下图是调整后序列的自相关和部分自相关图:

我们将只使用前两个滞后作为自回归序列的预测因子。
想要了解更多信息的话,杜克大学教授 Robert Nau 的网站是与此主题相关的最佳网站之一。(http://people.duke.edu/~rnau/411home.htm)
3
模型评价指标
为了分析预测值是否接近当前值,必须对误差进行测量,此种情况下的误差(或残差)基本上是 Yreal-YpredYreal-Ypred (这个暂时不知道怎么翻译, real 真实值, pred 预测值)。
对训练数据中的错误进行评估以验证模型是否具有良好的确定性,然后通过检查测试数据中的误差(模型未“看到”的数据)来验证模型。
当将训练数据与测试数据进行对比时,检查误差对于验证你的模型是否过拟合或欠拟合非常重要。
以下是一些用于评估时间序列模型的关键指标:
平均预测误差——偏差(bias)
它只是被评估序列的平均误差,值可以是正的也可以是负的。该指标表明,模型倾向于预测实际值以上(负误差)还是实际值以下(正误差),因此也可以说平均预测误差是模型的偏差。
MAE——平均绝对误差
这个指标与上面提到的预测的平均误差非常相似,唯一的区别是将误差的负值转化为正值,然后计算平均值。
这个指标在时间序列中被广泛使用,因为在一些情况下,负误差可以抵消正误差,使人误以为模型是准确的,而在用 MAE 的情况下不会发生,因为这个指标显示预测距离实际值有多远,不管数值大还是小,示例如下:
1a = np.array([1,2,3,4,5]) 2b = np.array([5,4,3,2,1]) 3 4error = a - b 5 6MFE = error.mean() 7MAE = np.abs(error).mean() 8 9print(f'The error of each model value looks like this: {error}')10print(f'The MFE error was {MFE}, the MAE error was {MAE}')
与 MAE 和 MFE 不同,MSE 值是平方单位,而不是模型单位。
RMSE——均方根误差
这个指标只是 MSE 的平方根,使误差返回到模型的度量单位(BRL/m3),因为它对时间序列在平方过程中产生的较大误差更为敏感而非常有用。
MAPE——平均绝对百分误差
这是另一个可用的有趣的指标,它通常在管理报告中使用,因为误差是以百分比度量的,所以产品 X 的错误可以与产品 Y 的误差进行比较。
该指标的计算取误差的绝对值除以当前价格,然后计算平均值:

我们来创建一个函数,用几个评估指标来评估训练数据和测试数据的误差:
1#Libraries to create the function: 2from math import sqrt 3from sklearn.metrics import mean_squared_error,mean_absolute_error, mean_absolute_error 4 5def check_error(orig, pred, name_col='', index_name=''): 6 bias = np.mean(orig - pred) 7 mse = mean_squared_error(orig, pred) 8 rmse = sqrt(mean_squared_error(orig, pred)) 9 mae = mean_absolute_error(orig, pred)10 mape = np.mean(np.abs((orig - pred) / orig)) * 10011 error_group = [bias, mse, rmse, mae, mape]12 serie = pd.DataFrame(error_group, index=['BIAS','MSE','RMSE','MAE', 'MAPE'], columns=[name_col])13 serie.index.name = index_name14 return serie
残差与预测值(散点图)
分析这个图是非常重要的,因为在这个图中我们可以检查模式,它可以告诉我们是否需要对模型进行一些修改,理想的情况是误差沿着预测序列线性分布。
残差的QQ图(散点图)
https://en.wikipedia.org/wiki/Q–Q_plot
总的来说这是一个显示了残差在理论上应该如何分布的图形,遵循高斯分布,而不是实际情况。
残差自相关(序列图)
如果没有置信区间的值,或者说模型不包含信息。
我们需要创建另一个函数来绘制这些图:
1def plot_error(data, figsize=(18,8)): 2 # Creating the column error 3 data['Error'] = data.iloc[:,0] -data.iloc[:,1] 4 5 plt.figure(figsize=figsize) 6 ax1 = plt.subplot2grid((2,2), (0,0)) 7 ax2 = plt.subplot2grid((2,2), (0,1)) 8 ax3 = plt.subplot2grid((2,2), (1,0)) 9 ax4 = plt.subplot2grid((2,2), (1,1))10 #Plotting actual and predicted values1112 ax1.plot(data.iloc[:,0:2])13 ax1.legend(['Real','Pred'])14 ax1.set_title('Real Value vs Prediction')15 # Error vs Predicted value1617 ax2.scatter(data.iloc[:,1], data.iloc[:,2])18 ax2.set_xlabel('Predicted Values')19 ax2.set_ylabel('Residual')20 ax2.set_title('Residual vs Predicted Values')2122 ## Residual QQ Plot23 sm.graphics.qqplot(data.iloc[:,2], line='r', ax=ax3)2425 # Autocorrelation Plot of residual26 plot_acf(data.iloc[:,2], lags=60, zero=False, ax=ax4)27 plt.tight_layout()28 plt.show()
与实际值相比,误差往往会增加。
许多人还使用这种方法作为 基线(baseline),试图用更复杂的模型来改进。
下面我们将使用训练数据和测试数据来进行模拟:

QQ 图显示了有一些比理论上要大些(包括正负值)的残差,这些是所谓的异常值,但在第一,第六和第七个滞后中仍然存在明显的自相关,这可以用于改进模型。
同样地,我们现在将在测试数据中进行预测。预测序列的第一个值将是训练数据的最后一个值,然后这些值将按照测试的当前值逐步更新,依此类推:

RMSE 和 MAE 的误差与训练数据相似,QQ 图与残差更符合理论值,可能是由于与训练数据相比样本值较少。
在对比残差与预测值的图表中,我们注意到当价格上涨时,误差绝对值有增加的趋势,可能用对数调整会减少误差的扩大并完成残差相关图,表明由于第一个滞后有很强的相关性,因此仍有改进的空间,可能添加基于第一个滞后的回归来改进预测。下一个模型是简单平均值:
简单平均
另一种预测方法是使用序列平均值,通常当数值在平均值附近振荡时,具有常数的方差,没有上升或下降趋势时,这种预测形式是好的,但是也能使用更好的方法,其中可以使用季节模式进行预测。
此模型使用数据首端直到分析的前一个时期的平均值,并且按天扩展到数据结束,最后,趋势是一条直线,我们现在将此模型与第一个模型的误差进行比较:

在测试数据中,我将继续使用训练数据一开始的均值,并展开添加到测试数据上:

简单均值模型无法捕获序列的相关信息,如真实值和预测值图中所示,也可以在相关性和残差和预测图中看到。
简单滑动平均:
滑动平均是针对给定周期(例如 5 天)计算的平均值,它是滑动的并始终使用此特定时段进行计算,在这种情况下,我们将始终使用过去 5 天的平均值来预测下一天的值。

误差低于简单平均,但仍高于简单模型,以下是测试模型:

与训练数据相似,滑动平均模型优于简单平均模型,但尚未比简单模型基础有所增益。
预测具有 2 个时滞的自相关性,并且相对于预测值有很大的方差误差。
指数滑动平均:
上述简单滑动平均模型具有同等地处理最后 X 个观测值并完全忽略所有先前观测值的特性。直观地说,过去的数据应该逐渐打折,例如,理论上最近的观测结果应该比第二近的更重要,而第二近的观测应该比第三近的数据更重要,等等, 指数滑动平均(Exponential Moving Average,EMM)模型就是这样做的。
由于 α(alpha)是一个常数,其值介于 0 和 1 之间,因此我们将使用以下公式计算预测值:
![]()
如果预测的第一个值是相应的当前值,其他值将更新为实际值与前一个时段的预测之差的 α 倍。当α为零时,我们根据第一个预测值得到一个常数,当 α 为 1 时,我们有一个简单方法的模型,因为结果是前一个实际周期的值。
下面是几个 α 值的图表:
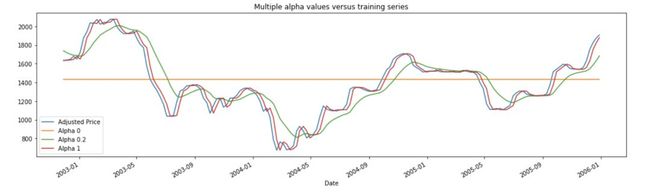
EMM 预测中的平均数据周期为 1 /α。例如,当 α= 0.5 时,滞后相当于 2 个周期; 当 α= 0.2 时,滞后是 5 个周期; 当 α= 0.1 时,滞后是 10 个周期,依此类推。
在这个模型中,我们将任意选用 α 值为 0.5 ,而你可以通过网格搜索算法查找在训练集和验证集中都中减少了错误的 α,数据大概应是这样:

这个模型的误差与滑动平均的误差相似,但是我们需要在测试集对模型进行验证:

在验证数据中,目前为止的误差在我们已经训练过的模型中排名第二,而残差图的特征与 5 天滑动平均模型的特征非常相似。
自回归
自回归模型基本上是一个具有显著相关滞后的线性回归,首先要绘制自相关图和部分自相关图来验证是否存在相关关系。
下面是训练序列的自相关图和部分自相关图,显示了自回归模型的特征为具有 2 个时滞的显著相关性:

接下来我们将根据训练数据创建模型,得到模型的系数后,将其乘以测试数据将要执行的值:

这个模型与我们所训练的其他模型相比,误差最小,现在我们用它的系数对训练数据进行逐步预测:

注意,在测试数据中,误差不会保持稳定,甚至会比简单模型更差,可以看到图中的预测值几乎总是低于当前值,偏差测量显示实际值比预测值高 50.19 BRL, 也许在训练模型中调整一些参数,这种差异会减小。
要改进这些模型,你可以应用多个转换,例如本文中介绍的转换,也可以添加外部变量作为预测源,但是,这已然超出本文内容了。
4
结束语
每个时间序列模型都有自己的特点,应该分别单独分析,这样我们就可以提取尽可能多的信息来做出好的预测,减少未来的不确定性。
检验平稳度、转换数据、在训练数据中建立模型、验证测试数据、检验残差是建立良好时间序列预测的关键步骤。
也可以看看本文原作者的有关ARIMA模型的文章。
https://www.kaggle.com/leandrovrabelo/climate-change-forecast-sarima-model
原文来源: https://towardsdatascience.com/basic-principles-to-create-a-time-series-forecast-6ae002d177a4
译者简介::李洁,北京师范大学香港浸会大学联合学院 数据科学系助教,香港科技大学电信学硕士。
(*本文为Python大本营转载文章,转载请联系原作者。原标题:不会时间序列预测?不要紧,大神来教你)◆
精彩推荐
◆
【结果提交倒计时】PV,UV流量预测算法大赛,结果提交截止时间为 9月20日 ,还没有提交的小伙伴抓紧时间了~~9月25日公布初赛成绩。 最新排行榜请点击 阅读原文 查看。 推荐阅读
推荐阅读
Python微信远程控制摄像头-拍摄女朋友坐电脑前聊天时表情
5大必知的图算法,附Python代码实现
吐血整理!140种Python标准库、第三方库和外部工具都有了
如何用爬虫技术帮助孩子秒到心仪的幼儿园(基础篇)
Python传奇:30年崛起之路
2019年最新华为、BAT、美团、头条、滴滴面试题目及答案汇总
阿里巴巴杨群:高并发场景下Python的性能挑战