Python中时间的一些常用操作
import time
# 从格林威治时间到现在,单位秒
print('系统时间戳:', time.time())
print('本地时间按格式转成str:', time.strftime('%Y-%m-%d %X', time.localtime()))
# 无参的localtime返回time.struct_time格式的时间,是本地时区的时间
print('无参localtime:', time.localtime())
print('本时区时间转成时间戳:', time.mktime(time.localtime()))
# 将时间戳转换为能读懂的时间
print('时间戳转时间:', time.strftime('%Y-%m-%d %X', time.localtime(time.time())))
运行结果:
系统时间戳: 1542188096.1592166
本地时间按格式转成str: 2018-11-14 17:34:56
无参localtime: time.struct_time(tm_year=2018, tm_mon=11, tm_mday=14, tm_hour=17, tm_min=34, tm_sec=56, tm_wday=2, tm_yday=318, tm_isdst=0)
本时区时间转成时间戳: 1542188096.0
时间戳转时间: 2018-11-14 17:34:56
Pandas时间序列(DatetimeIndex)与时序数据
时间序列在Series对象中且作为索引存在时,就构成了时序数据。
import datetime
import numpy as np
import pandas as pd
# pd.date_range()函数用于创建一个Pandas时间序列DatetimeIndex
# start参数(也是第一个参数)传入一个str格式的开始时间,也可以传入一个datetime对象
# 这里用datetime.datetime()创建了一个datetime对象,只用了前三个参数也就是年月日
# pd.date_range()函数可以指明end表示时间序列的结尾时间
# 这里用periods参数指明序列中要生成的时间的个数,freq='D'指定为每天(Day)生成一个时间
dti = pd.date_range(start=datetime.datetime(2018, 11, 14), periods=18, freq='D')
print(dti, '\n', '*' * 40, sep='')
# 将时间序列放在Series对象中作为索引,这里freq='W'表示隔一周生成一个
s_dti = pd.Series(np.arange(6), index=pd.date_range('2018/11/4', periods=6, freq='W'))
print(s_dti.head(), '\n', '*' * 40, sep='')
# 取时序数据中指定时间的内容
print(s_dti['2018-11-25'], '\n', '*' * 40, sep='')
# 取第二个索引对应的时间的年月日
print(s_dti.index[2].year, s_dti.index[2].month, s_dti.index[2].day, '\n', '*' * 40, sep='')
运行结果:
DatetimeIndex(['2018-11-14', '2018-11-15', '2018-11-16', '2018-11-17',
'2018-11-18', '2018-11-19', '2018-11-20', '2018-11-21',
'2018-11-22', '2018-11-23', '2018-11-24', '2018-11-25',
'2018-11-26', '2018-11-27', '2018-11-28', '2018-11-29',
'2018-11-30', '2018-12-01'],
dtype='datetime64[ns]', freq='D')
****************************************
2018-11-04 0
2018-11-11 1
2018-11-18 2
2018-11-25 3
2018-12-02 4
Freq: W-SUN, dtype: int32
****************************************
3
****************************************
20181118
****************************************
杭州天气的时序处理
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
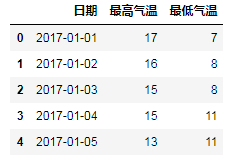
df = pd.read_csv('E:/Data/practice/hz_weather.csv')
df = df[['日期', '最高气温', '最低气温']]
# print(df.head())

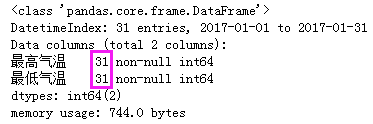
print(type(df.日期)) #print(type(df.日期.values)) # # 修改日期格式 # 注意,df.日期得到的是Series对象,df.日期.values得到的是ndarray多维数组 # pd.to_datetime()函数将输入解析成时间对象的格式并返回 # format参数指定解析的方式 # 当输入列表形式的值时,返回DatetimeIndex;当输入Series时,返回Series;当输入常量时,返回Timestamp print(type(pd.to_datetime(df.日期.values, format="%Y-%m-%d"))) # print(type(pd.to_datetime(df.日期, format="%Y-%m-%d"))) # df.日期 = pd.to_datetime(df.日期.values, format="%Y-%m-%d") # print(df.head())
# 将日期设置为索引
df = df.set_index('日期')
# 取出第0个索引值对应的日期
print(df.index[0]) # 2017-01-01 00:00:00
# DatetimeIndex里存的是一个个的Timestamp,查看一下类型
print(type(df.index[0])) #
# print(df.info())

# 提取1月份的温度数据 df_jan = df[(df.index >= "2017-1-1") & (df.index < "2017-2-1")] # 或用这种方式也可以 df_jan = df["2017-1-1":"2017-1-31"] # print(df_jan.info())
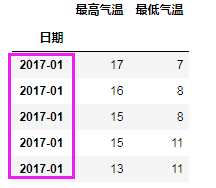
# 只取到月份
df_m = df.to_period('M')
# print(df_m.head())
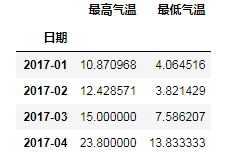
# 利用上面的只取到月份,对level=0(即索引层级)做聚合就可以求月内的平均值等 s_m_mean = df_m.groupby(level=0).mean() # print(s_m_mean.head())
# 绘制[最高温度]和[最低温度]两个指标随着索引[时间]变化的图 fig, ax = plt.subplots(1, 1, figsize=(12, 4)) df.plot(ax=ax) plt.show()
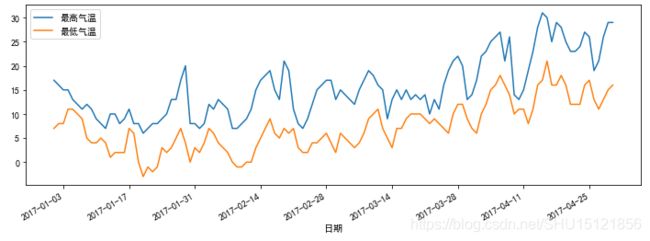
附:matplotlib中文支持

到此这篇关于python Pandas时序数据处理 的文章就介绍到这了,更多相关Pandas 时序数据 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!