AI = “Automated Inspiration(灵感自动化)”
全文共4581字,预计学习时长14分钟

来源:Pexels
在19世纪,医生可能会让情绪波动的病人服用水银,让哮喘病患者吃砒霜,甚至可能不会在手术前洗手。当然,他们并没有什么恶意——他们只是不知道怎么做才更好。
这些早期的医生在他们的笔记本上潦草地写下了有价值的数据,但是每个医生不过都是大拼图中的一个部分。没有能够分享和分析信息的现代工具,也没有能够理解这些数据的科学,因此就没有什么能阻止迷信取代科学与事实。
从那时起,人类在技术上已经取得了长足的进步,但是今天机器学习(ML)和人工智能(AI)的繁荣并不是与过去的决裂。这是人类本能的延续,使人类可以理解周围的世界,从而做出更明智的决策。其实,我们只是拥有了更先进的技术。
如今,人工智能的繁荣并不是与过去的决裂,只是拥有了更先进的技术。
古往今来,人们可以把这种模式看作是数据集的革命,而不是数据点的革命。其中的差别是显著的,因为是数据集帮助塑造了现代世界。

文字的发明
早至5000多年前,苏美尔(现伊拉克地区)的抄写员就开始用笔在粘土板上书写文字。就是在那个时候,第一个书写系统得以发明,随之出现的还有第一种数据存储和共享技术。

世界上第一个数据存储和共享技术的例子——苏美尔人的泥板文书。这种书写方式不仅数据容量很小,而且检索起来异常困难。
如果你感慨于人工智能优于人类的能力,那就想想文具所带来的超常记忆力。虽然现在人们常常会认为写字没什么稀奇的,但是可靠的数据集存储能力意味着人们迈向更高智能之路的第一步。
如果你感慨于人工智能优于人类的能力,那就想想文具带来的超常记忆力。
不幸的是,在各种电子产品真正出现以前,如果先人们要从泥板书写等诸如此类的早期书写系统中去检索信息,那会是项极其费力的工作。比如,计算字数并不是一件轻而易举的事情,因为人们必须在大脑中对每个字进行处理。因此,早期的数据分析非常费时间,所以当时的人们也只会记录那些相对重要的事情。在某个王国,虽然官方可能会分析其黄金税收,但只有“勇者”才敢对此做出自己理性的分析。比如在医学方面,数千年的传统只是鼓励人们顺其自然。
分析学的兴起
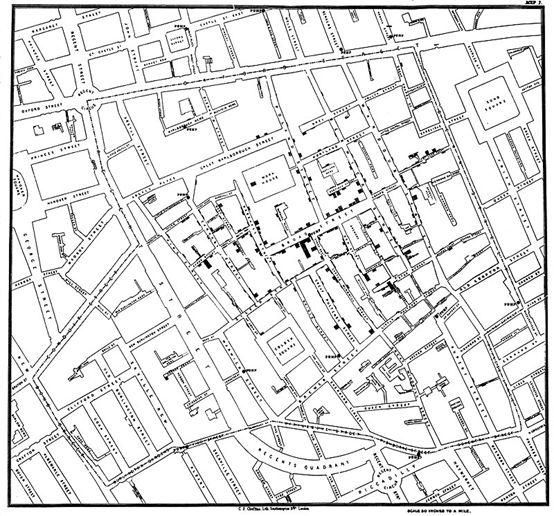
约翰·斯诺绘制的地图,显示了1854年伦敦爆发的霍乱病例群。
幸运的是,总有人立于历史的潮头。例如,在1858年伦敦霍乱爆发期间,约翰·斯诺绘制的死亡情况地图就启发了当时的医学界人士,让他们重新考虑这种疾病的来源,不再迷信地认为是瘴气(一种有毒气体)引起的,而是开始仔细观察饮用水。

弗罗伦斯·南丁格尔,分析师(1820-1910)
大家可能都知道“提灯女神”弗洛伦斯·南丁格尔是一名有富有同情心的护士,但鲜为人知的是,她同时也是一名分析学先驱。在克里米亚战争期间,南丁格尔发明的信息图表拯救了许多人的生命。通过这种图表,人们发现医院糟糕的卫生状况是致死的主要原因,并因此要求政府重视卫生设施。
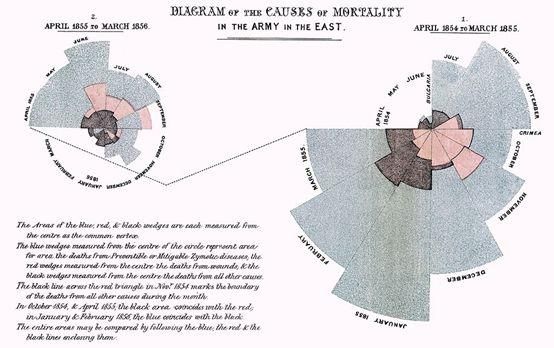
上图所示为弗洛伦斯·南丁格尔发明的极区图,显示了可预防疾病(蓝色)致死人数,因伤(红色)致死人数,以及其他原因(黑色)导致的死亡人数。
当信息的价值在越来越多的领域得到体现时,单一数据集的时代也随之开启,而这也使得“计算师(Computer)”职业得以出现。最初的“Computer”并不是当今家喻户晓的电脑,而是一种人类职业,其从业者手动执行计算并处理数据以获取其价值。

此照片拍摄于20世纪50年代,图中所有人都是职业“计算师”,工作于超音速压力隧道。
数据的美妙之处就在于,它能让人们从中产生深刻的见解。如同弗洛伦斯·南丁格尔和约翰·斯诺一样,通过分析信息,人们可以受到启发并提出新的问题。简而言之,分析学就是通过分析探索来提出假设,创建模型。
分析学的缺点
不幸的是,如果没有第二个数据集,人们就无法得知由此产生的观点是否站得住脚。除了某些特定的数据点之外,在其它情况下该观点还行之有效吗?无从得知。欢迎来到20世纪的分析学世界。
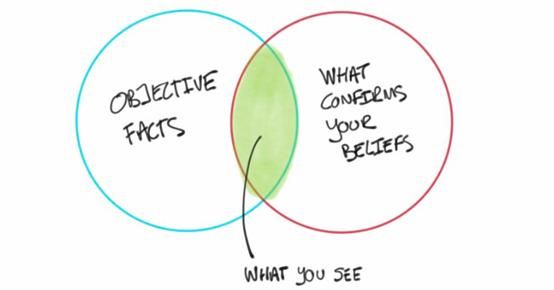
该图示由保罗·J绘制而成,原用于笔者一篇关于数据驱动决策中的确认偏差的文章。
通常人们的研究或发现并不是万无一失的,因为各种无意识的偏见(如 确认偏误)无法避免——当人们看到最明显的点时,常常会因此而错过其它同样重要的地方。人们也许会认为已经看到了所有需要看的东西,但实际上才刚刚触及皮毛。由于人类的注意力和记忆力远没有想象中的那么好,所以探索性数据集常常是一种狒狒陷阱 (baboon trap )。
分析学是关于灵感和探索的,但是超越数据的观点不应该被认真对待。
如果要在实验数据之外检验某观点是否依旧可行,那么就不能再使用原先的数据。例如,有人曾在薯片中隐约看见了猫王的脸。虽然这个薯片可能看起来像猫王,但并不能以此断定大多数薯片皆是如此。要知道某观点是否站得住脚,就不仅仅要看那些激发观点的例子,而且还必须在从未见过的新薯片上测试它们。
从数据集到数据分割
在20世纪早期,人们希望能够在不确定的情况下做出更好的决定,这一愿望导致了一个平行领域的诞生:统计学。如果一个现象也适用于除当前数据集之外的数据集,统计学家会帮助测试这种行为是否明智。

“统计学之父”罗纳德·费希尔 (1890–1962)
一个著名的例子来自罗纳德·费希尔,他编撰了世界上第一本统计学教科书。当年,费希尔的朋友声称自己能尝出在茶中是先加的牛奶还是水,为了回应这一说法,费希尔做出了一个假设并进行了相关实验。费希尔本希望能证明朋友是错的,但是数据得出的结论却与预期相反。
统计的严格性要求人们在采取行动之前先发号施令;分析学则更像是一场事后诸葛的游戏。
致命弱点
分析学和统计学有一个主要的致命弱点:如果在假设生成和假设检验中使用相同的数据点,那么就是在作弊。如果选择用数据来代替灵感,则必须从别处获得灵感。在大多数情况下,灵感来源于努力思考。换句话说,坐在杂物间里沉思,仔细地构思统计问题,阐明所有的假设,然后就有机会测试自己对世界的心智模式是否真的成立。
不幸的是,要用数学的方式详细说明整个直觉,并对其进行测试,需要进行艰苦训练。你需要集中精力。但至少现在有了一个合理的方法来检查自己的印象是否值得付诸行动。欢迎来到20世纪后期的 统计学世界。
数据集革命
统计的严格性要求人们在采取行动之前先发号施令;分析学则更像是一场事后诸葛的游戏。这些学科几乎是完全不兼容的。直到下一次重大革命——数据分割的出现,才改变了这一切。

数据分割是一个简单的想法,但对像笔者这样的数据科学家来说,这堪称最深刻的想法之一。如果只有一个数据集,必须在分析(不可测试的灵感)和统计(严格的结论)之间进行选择。黑客吗?把数据集分成两部分,这样就可以鱼与熊掌兼得了!
双数据集时代用两种不同类型的数据专家之间的协同工作取代了分析-统计 的紧张关系。分析师使用一个数据集来构建问题,然后统计学家使用另一个数据集来给出严格的答案。
把你的数据集分成两部分,这样就可以鱼与熊掌兼得了!
这种奢侈品有着沉重的价格标签:数量。如果你一直在努力为数据集收集足够的信息,那么分割说起来容易做起来难。双数据集时代是一种非常前沿的发展,它与更好的处理硬件、更低的存储成本以及通过互联网共享收集信息的能力齐头并进。
事实上,迎来双数据集时代的技术革新迅速进入了下一个阶段,一个自动化灵感的三数据集时代。还有一个更熟悉的词:机器学习。
作为一次性命题的测试
有没有想过为什么统计学家在涉及到严谨的数据时会变得焦虑不安?在计划问题之前查看数据集会破坏其作为统计严谨性来源的纯粹性。如果你问错了问题,或者问得很愚蠢,那就没有第二次机会了。
即使你正在考虑进行多重比较校正——即允许每个数据集有多个假设的统计咒语——程序也只有在提前计划好所有假设的情况下才有效。用测试数据集检验20个问题是不被允许的,反复放大一个闪亮的结果,还假装事不关己。
测试仍然是一个一次性的命题——不允许迭代地向解决方案爬行。
为了使严格的方法有效,必须提前规划,如果问题不止一个,使用一些“充满歉意”的数学(计划好多个假设),然后同时执行一次测试。不能多次打开该测试数据集。
第三个数据集的奢华
既然只有一次机会,怎么知道分析的哪个“洞察力”最值得测试呢?如果有第三个数据集,就可以用它来激发测试灵感。这种筛选过程称为验证,这是机器学习的核心。
验证是机器学习的核心——它能自动激发灵感。
一旦可以自由地把所有的东西扔向验证墙,看看有什么东西卡住了,每个人都可能想出一个解决方案:经验丰富的分析师、实习生,甚至是与业务问题无关的算法。无论哪种解决方案在验证中效果最好,都会成为合适的统计测试的候选方案。这个过程就强化了自动灵感的能力。

来源:Pexels
AI = Automated inspiration(灵感自动化)
这就是为什么机器学习是数据集的革命,而不仅仅是数据。这取决于是否有足够的数据进行三方拆分。
人工智能(AI)在这幅图中是什么位置呢?使用深度神经网络的机器学习在专业领域被称为深度学习,但它还有一个固定的昵称:人工智能。尽管人工智能曾经有不同的含义,但今天人们通常把它等同于深度学习。
在完成许多复杂任务时,深度学习网络的表现常常优于低级的机器学习算法,因而广受关注。然而,它们通常需要更多的训练数据,并且处理要求超出了普通的笔记本电脑。这就是为什么现代人工智能的崛起是一个云的故事;云用户可以租用别人的数据中心,而不是致力于构建自己的深度学习平台,从而让人工智能成为先试后买的东西。
现代人工智能的崛起是一个云的故事,因为云让人工智能成为一个先试后买的东西。
有了这个拼图,就有了专业的完整补充:机器学习/人工智能、分析学和统计学。涵盖所有这些的涵盖性术语叫做数据科学,即使数据有用的学科。
灵感的未来
现代数据科学是三个数据集时代的产物,但许多行业通常会产生过多的数据。那么,未来有可能会出现四个数据集吗?
如果你刚刚训练的模型得到了一个较低的验证分数,那么下一步该怎么办?如果像大多数人一样,你会立即想要知道为什么!不幸的是,没有数据集可以问。你可能想在验证数据集中进行搜索,但不幸的是,调试破坏了有效筛选模型的能力。
通过对验证数据集进行分析,可以有效地将三个数据集变成两个。你没有寻求帮助,而是不知不觉地倒退了一个时代!

来源:Pexels
解决方案并非是已使用的三个数据集。为了解锁更智能的训练迭代和超参数调试,你会想要加入到前沿:四个数据集的时代。
最前沿的技术是用四种数据分割来助力发展。
如果其他三个数据集给人们带来了灵感、迭代和严格的测试,那么第四个数据集则会加速这一过程,通过高级分析技术缩短人工智能开发周期,这些技术旨在为每一轮尝试什么方法提供线索。通过采用四种数据分割,人类将能够共享数据带来的福利!
未来可期。