神经网络相关的概念和术语
目录
模型训练
指标
损失
激活函数
优化器
正则化
层
其他
模型训练
编译:compile
拟合:fit
过拟合:overfit
欠拟合:underfit
随机初始化:radom initialization
前向传播:foward pass
小批量随机梯度下降:mini-batch stochastic gradient descent,SGD
训练后的量化(post training quantizated)
训练中引入量化(quantization aware training)
权重初始化方案:weight-initialization scheme
优化方案:optimization scheme
目标函数:objective function
反向传播:backpropagation,backward pass,也叫反式微分,reverse-mode differentiation
训练循环:training loop
超参数:hyperparameter
K折验证:K-fold validation
乱序重复K折验证:iterated K-fold validation with shuffling
预训练网络:pretrained network
特征提取:feature extraction
微调模型:fine-tuning
Hebbian学习规则
与BP算法一样,Hebbian学习规则也是一种参数更新的方式。该学习规则:将一个神经元的输入与输出信息进行对比,对该神经元的输入权重参数进行更新。该学习规则使每个神经元独自作战。一个神经元的参数更新,仅仅与它自己的输入与输出数据有关,不考虑整个网络的全局情况。
Hebbian学习规则通常使用双极性激活函数,即激活函数的取值范围是[-1,1],使得输入与输出同号(+或-)时,加大权重,否则,降低权重。
因此,通常,Hebbian学习规则用当前神经元的输入与输出的乘积更新自己的权重。
![]()
其中:![]() 是第
是第 个神经元的输出,
个神经元的输出, 是神经元的第
是神经元的第 个输入。
个输入。 是神经元与第个输入数据之间的权重。
是神经元与第个输入数据之间的权重。
指标
在训练和测试过程中需要监控的指标:metric
精确率:precision
召回率:recall
ROC:接收者操作特征曲线,receiver operating characteristic curve
AUC:接收者操作特征曲线下面积,area under the receiver operating characteristic curve
TP —— True Positive 是指某(些)个正样本被预测判定为正;此种情况可以称作判断为真的正确情况。
TN —— True Negative是指某(些)个负样本被预测判定为负;此种情况可以称作判断为假的正确情况。
FP ——False Positive 是指某(些)个负样本被模型预测为正;此种情况可以称作判断为真的错误情况,或称为误报。
FN——False Negative是指某(些)个正样本被模型预测为负;此种情况可以称作判断为假的错误情况,或称为漏报。
损失
预测误差:prediction error,或损失值,loss value
损失函数:loss function
交叉熵:crossentropy,来自于信息论领域,用于衡量概率分布之间的距离
二元交叉熵:binary crossentropy
分类交叉熵:categorical crossentropy
均方误差:mean-squared error,MSE,也叫L2模损失函数:L2-norm Loss Function
联结主义时序分类:CTC,connectionist temporal classification,也叫连接时序分类
平均绝对误差:MAE
总变差损失:total variation loss
重构损失:reconstruction loss
正则化损失:regularization loss
L1模损失函数:L1-norm Loss Function
回归损失函数:Bounding Box Regression Loss
光滑L1损失函数:SmoothL1Loss
KL散度损失函数:KLDLoss
损失函数缩放:Loss Scaling
缩放因子:Scaling Factor
铰链损失函数:Hinge Loss
激活函数
激活函数:activation function
relu:rectified linear unit,整流线性单元
sigmoid:输出一个0-1范围内的概率值
softmax: 输出多个概率,其和为1
tanh:tanh和 sigmoid 相似,都属于饱和激活函数,区别在于输出值范围由 (0,1) 变为了 (-1,1),可以把 tanh 函数看做是 sigmoid 向下平移和拉伸后的结果。
优化器
优化器:optimizer
Momentum:动量
动量优化:初始时刻动量为0,t时刻的动量等于t-1时刻动量乘以一个系数,加上权重梯度乘以学习率,并用这个动量更新权重
AdaGrad:把历史的权重梯度的分量平方求和,并用这个平方和更新权重
指数移动平均:Exponential Moving Average
RMSProp:引入了梯度平方(又称速度,Velocity)的指数移动平均,用于求梯度在一定时长内的平均。
Adam:整合了动量和速度
正则化
正则化:regularization
权重正则化:weight regularization
L1正则化:L1 regularization
L2正则化:L2 regularization,也叫权重衰减,weight decay
dropout,正则化方法之一
层
层:layer
密集连接:全连接
密集连接层:densely connected layer,也叫全连接层,fully connected layer或密集层,dense layer
循环层:recurrent layer
权重:weight
参数化:parameterize
参数:parameter
可训练参数:trainable parameter
隐藏单元:hidden unit
堆叠循环层:stacking recurrent layer
双向循环层:bidirectional recurrent layer
卷积层:Convolution Layer,Conv Layer
深度可分离卷积层:depthwise separable convolution layer
输入层:Input Layer
隐藏层:Hidden Layer
输出层:Output Layer
归一化层:Normalization Layer,包括批次归一化,Batch Normalization,组归一化,Group Normalization,实例归一化,Instance Normalization,层归一化,Layer Normalization,局部响应归一化,Local Response Normalization
池化层:Pooling Layer,包括最大池化,Max Pooling,平均池化,Average Pooling,乘幂平均池化,分数池化,Fractional Pooling,自适应池化,Adaptive Pooling,反池化,Unpooling
丢弃层:Dropout Layer
因果卷积层:Causal Convolution Layer
其他
神经网络:neural network
人工神经网络:Artificial Neural Network,ANN
感知机:Perceptron
多层感知机:Multi-layer Perceptron,MLP
深度信念网络:Deep Belief Network,DBN
限制玻尔兹曼机:Restricted Boltzmann Machine,RBM
自编码器:Autoencoder
卷积神经网络:convnet,Convolutional Neural Networks, CNN
神经网络机器翻译模型:Neural Machine Translation,NMT
LeNet,一种卷积神经网络
特征图:feature map
输出特征图:output feature map
过滤器:filter
响应图:response map
滑动:slide
卷积核:convolution kernel
卷积核的感受野:Receptive Field
步幅:stride
填充:padding
步进卷积:strided convolution
转置卷积:Transposed Convolution,又称为反卷积,Deconvolution
扩张卷积:Dilated Convolution,又称空洞卷积,ATrous Convolution
最大池化:max-pooling
unpooling
Unpooling是在CNN中常用的来表示max pooling的逆操作。
鉴于max pooling不可逆,因此使用近似的方式来反转得到max pooling操作之前的原始情况。
简单来说,记住做max pooling的时候的最大item的位置,比如一个3x3的矩阵,max pooling的size为2x2,stride为1,反卷积记住其位置,其余位置至为0就行:
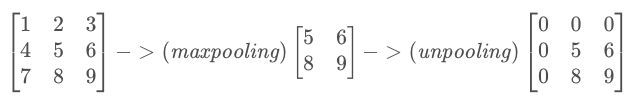
卷积基:convolutional base
循环神经网络:recurrent neural network,RNN
状态:state
环:loop
时间步:timestep
初始状态:initial state
双向RNN:bidirectional RNN
残差连接:residual connection
恒等残差连接:identity residual connection
线性残差连接:linear residual connection
1*1卷积:逐点卷积,pointwise convolution
Xception:极端Inception,extreme Inception,一种卷积神经网络
自标准化神经网络:self-normalizing neural network
字符级的神经语言模型:character-level neural language model
生成式对抗网络:GAN,generative adversarial network
生成器网络:generator network
判别器网络:discriminator network
变分自编码器:VAE,variational autoencoder
卷积神将网络的计算公式为:
N=(W-F+2P)/S+1
其中N:输出大小
W:输入大小
F:卷积核大小
P:填充值的大小
S:步长大小
FCN:Fully Convolutional Networks,全卷积网络
CNN输入图像的尺寸
经典的CNN输入图像的尺寸,是224×224、227×227、256×256和299×299,但也可以是其他尺寸。
VGG16,VGG19和ResNet均接受224×224输入图像,而Inception V3和Xception需要299×299像素输入
BERT:Bidirectional Encoder Representations from Transfomers
宽深模型:Wide & Deep Model
因果卷积模块:Causal Convolution
AmoebaNet:采用进化算法来做神经网络搜索得到的神经网络
深度可分离卷积
正常卷积核是对3个通道同时做卷积。也就是说,3个通道,在一次卷积后,输出一个数。
深度可分离卷积分为两步:
- 第一步用三个卷积对三个通道分别做卷积,这样在一次卷积后,输出3个数。
- 这输出的三个数,再通过一个1x1x3的卷积核(pointwise核),得到一个数。
所以深度可分离卷积其实是通过两次卷积实现的。
卷积的权重(Weight/Kernel/Filter)的数据格式一般不同于Tensor或Activation数据,有其特定的排布方式。
权重/卷积核/过滤器(Weight/Kernel/Filter)中有下面维度:
- I - Input Channels输入通道
- H - Filter Height卷积核高度
- W - Filter Width卷积核宽度
- O - Output Channels输出通道
TensorFlow的卷积conv2d的权重格式是HWIO,也就在tf.nn.conv2d里filters定义的:
