图像修复论文阅读Image Inpainting with Learnable Bidirectional Attention Maps
Image Inpainting with Learnable Bidirectional Attention Maps
Abstract
大多数基于卷积网络(CNN)的修复方法采用标准的卷积方法对有效像素和空洞进行不可区分的处理,使其仅限于处理不规则的空洞,更容易产生色差和模糊的修复结果。部分卷积被提出用来解决这一问题,但它采用手工特征重归一化,并且只考虑前向掩码更新。本文提出了一种可学习的注意力图模块,用于端到端的特征重归一化和掩码更新的学习,能够有效地适应不规则孔洞和卷积层的传播。此外,引入了可学习的反向注意图,使U-Net的解码器专注于填充不规则的空洞,而不是同时重构空洞和已知区域,从而得到了可学习的双向注意图。定性和定量实验表明,我们的方法在生成更清晰、更连贯和视觉上可信的修复结果方面表现得比最先进的方法更好。源代码和预先培训的模型可在以下网址获得:https://github.com/Vious/LBAM_inpainting/。
1 Intorduction
图像修复[3]是一种具有代表性的低层视觉任务,其目标是填充图像中的空洞,具有许多现实应用,如分散目标的去除、遮挡区域的填充等。然而,对于图像中给定的孔,可能存在多个可能的解,即可以用与周围已知区域一致的任何看似合理的假设来填充这些孔。而且孔洞可能是复杂和不规则的图案,进一步增加了图像修复的难度。传统的基于范例的方法[2,18,32],例如PatchMatch[2],通过从已知区域搜索并复制相似的面片来逐渐填充孔洞。尽管基于样本的方法在生成细节纹理方面是有效的,但它们在捕获高级语义方面仍然有限,并且可能无法生成复杂和非重复的结构(参见图1©)。
近年来,深度卷积网络(CNNs)在图像修复中的应用取得了长足的进展[10,20]。基于CNN的方法得益于强大的表征能力和大规模的训练,能够有效地实现语义上合理结果的生成。对抗性损失[8]也被用来改善结果的感知质量和自然性。尽管如此,大多数现有的基于CNN的方法通常采用标准卷积,无法区分有效像素和空洞。因此,它们在处理不规则孔方面受到限制,并且更有可能产生具有颜色差异和模糊的修复结果。作为补救措施,已经引入了几种后处理技术[10,34],但仍然不足以解决伪影(参见图1(D))。基于CNN的方法也与基于样本的方法相结合,以显式地合并孔洞的掩模,以更好地恢复结构和增强细节[26,33,36]。在这些方法中,掩模被用来引导编码器特征从已知区域传播到孔。然而,复制和增强操作大大增加了计算成本,并且仅部署在一个编解码层。因此,它们在填充矩形孔洞方面做得更好,而在处理不规则孔洞方面表现不佳(参见图1(E))。
为了更好地处理不规则孔并抑制颜色差异和模糊,提出了部分卷积(PConv)[17]。在每个PConv层中,使用掩码卷积使输出仅以未掩码的输入为条件,并引入特征重新归一化来缩放卷积输出。进一步提出了一种掩码更新规则来更新下一层的掩码,使得PConv在处理不规则孔洞时非常有效。尽管如此,PConv采用了硬0-1掩码和手工制作的特征重新归一化通过绝对信任所有填充的中间特征。此外,部分卷积仅前向掩码更新,并简单地将所有掩码用于解码器特征。

在本文中,我们更进一步,提出了可学习的双向注意力图模块,用于U-Net[22]体系结构的编码器和解码器上的特征的重新归一化。首先,我们无偏见地重温了PConv,并证明可以安全地避免掩码卷积,并且特征重新归一化可以解释为硬0-1掩码引导的重新归一化。为了克服硬0-1掩码和手工掩码更新的局限性,我们提出了一种可学习的注意力图模块,用于学习特征重归一化和模板更新。通过端到端的训练,可学习的注意力图能有效地适应不规则的孔洞和卷积层的传播。
此外,PConv在解码器功能上简单地使用了全一掩模,使得解码器应该同时出现洞和已知区域的幻觉。注意,已知区域的编码器特征将被连接起来,解码器自然只需要专注于孔的修复。因此,我们进一步引入了可学习的反向注意图,使得U-Net的解码器只专注于填补空洞,从而得到了可学习的双向注意图。与PConv相比,经验性地部署可学习的双向注意力图有利于网络训练,使得包含对抗性损失以提高结果的视觉质量是可行的。
在Paris SteetView[6]和Places[40]数据集上进行了定性和定量实验,以评估我们提出的方法。结果表明,我们提出的方法在生成更清晰、更连贯和视觉上可信的修复结果方面表现良好。从图1(F)(G)看,与PConv相比,我们的方法在生成清晰的语义结构和逼真的纹理方面更有效。综上所述,这项工作的主要贡献有三个方面:
a、提出了一种用于图像修复的可学习注意力图模块。与PConv相比,可学习的注意力图更能适应任意不规则的孔洞和卷积层的传播。
b、正向注意力图和反向注意力图结合在一起构成了可学习的双向注意力图,进一步提高了结果的视觉质量。
c、在两个数据集上的实验和真实世界的物体去除实验表明,我们的方法在生成整形、更连贯和视觉上的结果上比最先进的方法有更好的表现。
2 Related Work
在这一部分中,我们简要介绍了相关工作,特别是基于样本的方法所采用的传播过程以及基于CNN的修复方法的网络结构。
2.1 Exemplar-based Inpainting
大多数基于样本的修复方法都是从已知区域搜索并粘贴,从外到内逐渐填充孔洞[2,4,18,32],其结果高度依赖于传播过程。一般说来,通过先填充结构,再填充其他缺失区域可以获得更好的修复效果。为了指导补丁处理顺序,引入了补丁优先级[15,29]测度作为置信度和数据项的乘积。虽然置信项通常定义为输入图片中已知像素的比率,但是已经提出了几种形式的数据项。特别是Criminisi等人[4]提出了一种基于梯度的数据术语,用于填充优先级较高的线性结构。Xu和Sun[32]假设结构块在图像中是稀疏分布的,并提出了一种基于稀疏性的数据项。Le Meuret al等人[18]采用结构张量的特征值差异[5]作为结构补丁的指标。
2.2 Deep CNN-based Inpainting
早期基于CNN的方法[14,21,30]被建议用于处理带有小孔和细孔的图像。在过去的几年里,深度神经网络受到了人们的极大关注,并在填充大孔洞方面表现出了良好的性能。

Phatak等人[20]采用了编解码器网络(即上下文编码器),并考虑了重构和对抗性损失,以更好地恢复语义结构。Iizuka等人[10]结合了全局和局部鉴别器,既能再现语义上合理的结构,又能再现局部真实的细节。Wang等人。[28]提出了一种结合信心驱动的重建损失和隐式多样化MRF(ID-MRF)项的生成式多列CNN。多阶段方法也已被研究,以减轻训练深度修复网络的难度。张等人。[37]提出了一种渐进式产生式网络(PGN)来填补多阶段的空洞,而LSTM则用来开发阶段间的依赖关系。Nazeri等人的研究成果。[19]提出了一种两阶段模型EdgeConnect,该模型首先预测显著的边缘,然后由边缘引导生成修复结果。相反,熊等人[31]针对结构推理和内容生成的关系,提出了前景感知修复,包括轮廓检测、轮廓补全和图像补全三个阶段。为了将基于样本的方法和基于CNN的方法结合起来,Yang 等人[34]提出了多尺度神经块合成方法(MNPs),通过结合整体内容和局部纹理约束的联合优化来优化上下文编码器的结果。进一步开发了其他两阶段前馈模型,例如上下文关注[26]和补丁交换[36],以克服MNP的高计算成本,同时显式地利用已知区域的图像特征。同时,严等人[33]将U-Net修改为单阶段网络,即shift-net,以利用编码器特征从已知区域的移位来更好地再现似是而非的语义和详细内容。最近,郑等人[39]引入了增强的短期+长期注意力层,提出了一种具有两条并行路径的多元修复概率框架。
大多数现有的基于CNN的修复方法通常不太适合处理不规则的孔。为了解决这个问题,刘等人[17]提出了一种部分卷积(PConv)层,包括掩码卷积、特征重归一化和掩码更新三个步骤。Yu等人[35]提供了门控卷积,其通过考虑损坏的图像、掩模和用户草图来学习通道式软掩码。然而,PConv采用手工制作的特征重整化,只考虑前向掩码更新,在处理颜色差异和模糊方面仍然有限(见图1(D))。
3 Proposed Method
在这一部分中,我们首先回顾PConv,然后介绍我们的可学的习双向注意力图。随后,给出了该方法的网络结构和学习目标。
3.1 Revisiting Partial Convolution
PConv[17]层通常包括三个步骤,即(i)掩码卷积、(ii)特征重新归一化和(iii)掩码更新。进一步设W为卷积滤波,b为其偏置。首先,我们引入卷积掩模Mc=M⊗k1/9,其中⊗表示卷积算子,k1/9表示每个元素1/9的3×3卷积滤波器。PConv的过程可以表示为:
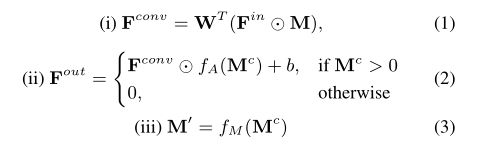
其中,A=FA(Mc)表示注意图,M’=fM(Mc)表示更新的掩码。我们进一步将注意力图和更新掩码的激活函数定义为:

来自等式(1)∼(5)和图2(A)中,PConv也可以解释为掩码和图2(A)之间的一种特殊的相互作用模型和卷积特征图。然而,PConv采用了手工制作的卷积滤波器k1/9以及手工制作的激活函数FA(Mc)和Fm(Mc),从而为进一步改进提供了一些回旋余地。此外,fM(Mc)的不可微特性也增加了端到端学习的难度。据我们所知,将对抗性损失与PConv结合训练U-Net仍然是一个困难的问题。此外,PConv只考虑掩码及其对编码器特性的更新。在解码器功能上,简单的采用全一掩码,使得PConv仅限于填充空洞。
3.2 Learnable Attention Maps
无偏置卷积层在U网中已被广泛采用,用于图像到图像的转换[11]和图像修复[33]。当偏置被去除时,它可以很容易地从方程(2)中看到,更新孔中的卷积特征为零。因此,等式(1)中的掩码卷积等效地重写为标准卷积:
![]()
然后,在等式(2)中对特征进行重新归一化可以解释为卷积特征和注意力图的元素乘积:
![]()
即使手工制作的卷积滤波器k1/9是固定的,并且不适合该掩模。更新掩模的激活函数绝对信任区域Mc>0中的修复结果,但更明智的做法是,对Mc较高的地区赋予更高的信心。为了克服上述局限性,我们从三个方面提出了可学习注意力图,它从三个方面对PConv进行了无偏见的概括。首先,为了使掩模能够适应不规则孔洞和分层传播,我们用分层的、可学习的卷积滤波器Km代替了k1/9。其次,代替硬0-1掩码更新,我们将更新掩码的激活函数修改为:![]()
其中α≥0是一个超参数,我们将α设置为0.8。可以看出,当α=0时,GM(Mc)退化为Fm(Mc)。第三,我们引入了一种非对称高斯变形形式作为注意力图的激活函数:

在a、µ、γl和γr缺少可学习参数的情况下,我们将它们初始化为a=1.1,µ=2.0,γl=1.0,γr=1.0,并以端到端的方式学习它们。综上所述,可学习注意图采用等式。(6)步骤(I),下两步公式如下:

图2(B)说明了可学习注意图的相互作用模型。与PConv相比,我们的可学习注意力图更加灵活,可以端到端地训练,使其能够有效地适应不规则的孔洞和卷积层的传播。
3.3 Learnable Bidirectional Attention Maps
当将PConv与U-Net结合用于修复时,该方法[17]仅更新掩模以及用于编码器特征的卷积层。然而,解码器功能通常采用全一掩码。因此,应该使用第(l+1)层编码器特征和第(L−l−1)层解码器特征两者来幻觉已知区域和孔中的第(L−l)层解码器特征。实际上,第l层编码器特征将与第(L−l)层译码特征串联在一起,我们只能专注于孔中第(L−l)层译码特征的生成。

我们进一步将可学习的反向注意力图引入到解码器的特征中。用Mc e表示编码器特征Fin e的卷积掩码。设Mc d=Md⊗kMd是解码器特征Fin d的卷积掩码。可学习反向注意图的前两个步骤可以表示为:
![]()
其中,We和Wd是卷积滤波器。我们将Ga(Mcd)定义为反向注意力图。然后,更新掩码Mc_Di并将其部署到先前的解码层:
![]()
图2©说明了反向注意力图的相互作用模型。与前向注意力图不同,它同时考虑了编码器特征(掩码)和解码器特征(掩码)。此外,反向注意力图中的更新掩码被应用于前一解码器层,而正向注意力图中的更新掩码被应用于下一编码层。
通过将正向和反向注意力图与U-net相结合,图3显示了完全可学习的双向注意力图。给定一幅带有不规则孔洞的输入图像,我们使用Min表示二进制掩模,其中1表示有效像素,0表示孔洞中的像素。从图3开始,前向注意力图将Min作为第一层编码器特征重新归一化的输入掩码,并逐步更新并应用到下一编码层。相反,反向注意力图以1−Min作为输入,对解码特征的最后一层(即第L层)进行重新归一化,并逐渐更新并将掩码应用到前一层解码器层。得益于端到端的学习,我们的可学习双向注意图(LBAM)在处理不规则洞时更有效。反向注意力图的引入使得解码器只专注于填充不规则的空洞,这也有助于修复性能。我们的LBAM还有利于网络训练,使得利用对抗性损失来提高视觉质量是可行的。
3.4 Model Architecture
我们通过去除瓶颈层并结合双向注意图来修改14层的U-Net体系结构11。特别地,前向注意力层应用于编码器的前六层,而反向注意力层应用于后六层解码器。对于所有的U-Net层和正向和反向关注层,我们使用了核大小为4×4、步长为2、填充为1的卷积滤波器,并且不使用偏置参数。在U-Net主干网中,对重新归一化后的特征进行批归一化和leaky RELU非线性处理,在最后一层卷积后立即展开tanh非线性。
3.5 Loss Functions
为了更好地恢复纹理细节和语义,我们综合了像素重构损失、感知损失[12]、样式损失[7]和对抗性损失[8]来训练LBAM。
Pixel Reconstruction Loss.用Iin表示带孔的输入图像,用Mini表示二进制掩模区域,用Ig表示地面真实图像。我们的LBAM的输出可以定义为IOUT=Φ(Iin,Min;Θ),其中Θ表示要学习的模型参数。我们采用输出图像的ℓ1范数误差作为像素重建损失:
![]()
Perceptual Loss. ℓ1范数损失仅限于捕捉高级语义,与人类对图像质量的感知不一致。为了缓解这一问题,我们引入了在ImageNet[23]上预先训练的VGG-16网络[25]上定义的感知损失Lpert:
![]()
其中PI(·)是第i个池层的特征地图。在我们的实施中,我们使用预先培训的VGG-16的Pool-1、Pool-2和Pool-3层。
Style Loss.为了更好地恢复细节纹理,我们进一步采用了VGG-16汇聚层特征图上定义的样式损失。类似于[17],我们从特征地图的每一层构造一个Gram矩阵。假设特征图PI(I)的大小为Hi×Wi×Ci。然后,可以将样式损失定义为:

Adversarial Loss.对抗性损失[8]已广泛应用于图像生成[24,27,38]和底层视觉[16]中,以提高生成图像的视觉质量。为了提高GaN的训练稳定性,Arjovskite等人[1]利用Wasserstein距离来度量生成图像和真实图像之间的分布差异,以及Gulrajani等人[9]进一步引入梯度惩罚来加强鉴别器中的Lipschitz约束。在[9]之后,我们将对抗性损失表示为:

其中D(·)表示鉴别器。I是通过随机选择因子的线性插值从Ig和Iout中获得的,在我们的实验中,λ被设置为10。我们经验发现,当包含对抗性损失时,很难训练PConv模型。幸运的是,结合可学习的注意力图有助于训练,使得在对抗性损失下学习LBAM成为可能。
Model Objective. 考虑到上述损失函数,我们的LBAM的模型目标可以表示为:![]()
其中,λ1、λ2、λ3和λ4是权衡的参数。在我们的实现中,我们经验地设置了λ1=1、λ2=0.1、λ3=0.0 5和λ4=120。
4. Experiments
在巴黎街景[6]和Places(Places365-Standard)[40]这两个数据集上对我们的LBAM算法进行了实验,这两个数据集在图像修复文献[20,33,34,36]中得到了广泛的应用。对于巴黎街景,我们使用其原始拆分,14,900张图像用于培训,100张图像用于测试。在我们的实验中,随机选择100幅图像并从训练集中移除,以形成我们的验证集。至于地点,我们从365个类别中随机选择10个类别,并使用原始训练集中每个类别的所有5000张图像来构成我们的5万张图像的训练集。此外,我们将每类1000幅图像中的原始验证集分成两个相等且互不重叠的500幅图像集,分别用于验证和测试。我们的LBAM处理256×256图像所需的∼时间为70ms,速度提高了5倍比上下文关注[36]和∼快3倍于全局和局部(GL)[10]。
在我们的实验中,所有的图像都被调整了大小,其中最小的高度或宽度是350,然后随机裁剪到256×256的大小。训练过程中采用翻转等数据增强。我们生成了18,000个随机形状的面具,并从[17]中生成了12,000个面具用于训练和测试。我们的模型使用Adma算法[13]进行了优化,初始学习率为1E−4,β=0.5。训练过程在500个历元后结束,并且最小批大小为48。所有实验都是在配备4个并行NVIDIA GTX 1080Ti GPU的PC上进行的。
4.1 Comparison with State-of-the-arts
我们的LBAM与四种最先进的方法进行了比较,即全局和局部[10]、PatchMatch[2]、上下文注意[36]和PConv[17]。
Evaluation on Paris StreetView and Places. 图4和图5显示了我们的LBAM和竞争方法的结果。GLOBAL&LOCAL[10]在处理不规则孔方面受到限制,会产生许不匹配比且毫无意义的纹理。PatchMatch[2]在恢复复杂结构方面表现不佳,结果与周围环境不一致。对于一些复杂和不规则的孔,上下文注意[36]仍然会产生模糊的结果,并且可能产生不需要的伪影。PConv[17]在处理不规则孔时是有效的,但在某些区域仍然不可避免地会出现过度平滑的结果。相比之下,我们的LBAM表现很好,生成了视觉上更合理的结果,具有精细的细节和逼真的纹理。
Quantitative Evaluation. 我们还在掩模比为(0.1,0.2),(0.2,0.3),(0.3,0.4)和(0.4,0.5)的位置[40]上与竞争的LBAM方法进行了定量比较。从表1可以看出,我们的LBAM在PSNR、SSIM和平均ℓ1损耗方面表现良好,特别是当掩模比大于0.3时。

Object Removal from Real-world Images. 使用基于位置训练的模型,我们进一步评估了LBAM在现实世界目标移除任务中的性能。图6显示了我们的LBAM、上下文注意[36]和PConv[17]的结果。我们使用轮廓形状或矩形边界框来遮罩对象区域。与同类方法相比,我们的LBAM能够同时利用全局语义和局部纹理产生逼真和连贯的内容。
User Study. 此外,还对巴黎街景和主观视觉质量评价场所进行了用户研究。我们从覆盖着不同不规则孔洞的测试集中随机选取了30幅图像,修复结果由PatchMatch[2]、Global&Local[10]、Context Attendence[36]、PConv[17]和我们的算法生成。我们邀请了33名志愿者投票选出视觉上最合理的修复结果,评价标准包括与周围环境的一致性、语义结构和精细性细节。


对于每个测试图像,5个修复结果被随机排列并与输入图像一起呈现给用户。我们的LBAM有63.2%的机会赢得最有利的结果,大大超过了PConv17,PatchMatch2,上下文关注度36和Global&Local10。
4.2 Ablation Studies
消融研究是为了比较几种LBAM变体在巴黎街景上的性能,即(I)我们的(完整):完整的LBAM模型,(ii)我们的(未学习):LBAM模型,其中掩码卷积滤波器的所有元素都设为1/16,因为滤波器的大小为4×4,并且我们采用公式中定义的激活函数(4)和Eqn.(5),(iii)我们的(前向):没有反向注意图的LBAM模型,(iv)我们的(w/o Ladv):无(w/o)对手损失的LBAM模型,V)我们的(Sigmoid/LReLU/RELU/3×3):LBAM模型使用Sigmoid/LeakyReLU/REU作为激活函数或3×3滤波器进行掩码更新。
图7显示了我们的(未学习的)来自第一编码器层和第13解码器层的特征的可视化,我们的(前向更新)和我们的(全部)。对于我们的(未学到的),模糊和伪影可以从图9(B)中观察到。我们的(前向更新)有利于减少伪影和噪声,但解码器会同时对孔和已知区域产生幻觉,并产生一些模糊效果(参见图9©)。相比之下,我们的(Full)在生成语义结构和详细纹理方面是有效的(见图9(D)),解码器主要关注生成孔(见图7(G))。表2给出了LBAM变体在巴黎街景上的定量结果,我们的性能增益(FULL)可以用(1)可学习的注意力图,(2)反向注意力图,和(3)适当的激活函数来解释。

Mask Updating. 图8显示了来自不同层的更新遮罩的可视化。从第一层到第三层,编码器的掩模逐渐更新,以减小孔洞的大小。类似地,从第13层到第11层,解码器的掩码逐渐更新,以减小已知区域的大小。
Effect of Adversarial Loss. 表2还给出了有/无Ladv的定量结果。虽然我们的(无Ladv)改善了PSNR和SSIM,但Ladv的使用通常有利于修复结果的视觉质量。定性的结果在附录中给出。
5. Conclusion
提出了一种用于图像修复的可学习双向注意图(LBAM)。通过引入可学习的注意力图,我们的LBAM能够有效地适应不规则的孔洞和卷积层的传播。此外,还提出了反向注意力图,使U-Net的解码器只专注于空洞的填充。实验表明,我们的LBAM在生成更清晰、更连贯和更精细的结果方面表现优于最先进的水平。