卷积神经网络入门
目录
前言
一、卷积是什么?
二、池化是什么?
三、卷积神经网络
4、ResNet18识别草书实战
4.1数据展示
4.2导入的库
4.3数据预处理部分
4.4切割数据集并定义数据加载器
4.5训练网络
4.6可视化损失函数、精度变化
总结
前言
近年来,卷积神经网络(Convolutional neural networks,CNN)已在图像理解领域得到了广泛的应用。而且作者最近再想试着用CNN来搞图像修复,所以先浅学了一下。
学习代码的过程中实践是必不可缺的,所以作者跟着《Python机器学习算法与实战》(作者孙玉林、余本国)这本书亲手码了一遍代码实战了一下,来分享一下我学习到的经验。先声明:文章不用于盈利,只是记录学习过程,方便以后复习。
一、卷积是什么?
卷积是一种数学运算,它是将两个函数通过一定的方式结合起来得到第三个函数的过程。在图像处理、语音识别、自然语言处理、计算机视觉等领域中,卷积经常被用来进行特征提取和模式识别。卷积就是重复下图的步骤,将卷积核在图像上移动,然后计算内积(其实可以理解成一个提取特征的过程)。经过卷积会发现特征矩阵会变小。
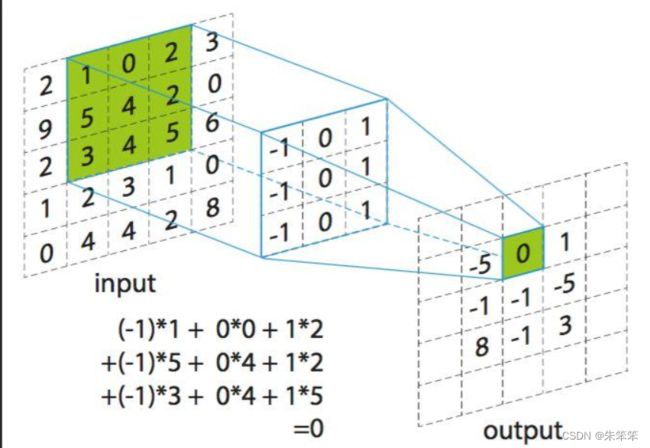
当然卷积神经网络中关于卷积有几个重要的参数:
1.卷积核大小:定义了卷积核的宽度和高度,一般来说都是正方形。
2.步长:定义了卷积核在输入数据上滑动的步幅。
3.填充:是在输入数据周围添加额外像素,用于保证输出特征图大小与输入特征图大小一致。
二、池化是什么?
池化操作是将输入数据按照一定的方式缩小尺寸的过程。通常的池化方式有最大池化和平均池化两种。最大池化将输入数据的每个子区域(例如2x2的矩形)替换为该区域中的最大值,而平均池化则替换为平均值。池化操作通常被用于减少特征图的空间分辨率,仅保留最显著的特征,减少计算成本。

从上图可以明显看出两者的区别,最大池化就是取范围内的特征最大值,然后平均池化则是求2*2矩阵中的特征值的平均值。 如右下角红色部分(11+6+12+7)/4 = 9。
三、卷积神经网络
卷积神经网络(Convolutional Neural Network, CNN)是一类特殊的神经网络,主要应用于图像识别、语音识别、自然语言处理等领域。CNN的核心是卷积操作,通过多次卷积和池化操作来提取特征,最终通过全连接层进行分类或预测。
CNN通常包含以下几种层:
-
卷积层:卷积层是CNN的核心,其中包含多个卷积核,通过对输入图像进行卷积操作,提取图像的特征。卷积层通常包括ReLU激活函数用于增强非线性表达能力。
-
池化层:池化层通常紧跟在卷积层之后,通过对卷积层输出进行池化操作,减少特征图的空间分辨率,从而减小计算成本,并在一定程度上防止过拟合。
-
批正则化层:这是一个可选的层,用于缓解卷积层训练过程中的梯度消失和梯度爆炸问题,以及提高模型的收敛速度。
-
全连接层:全连接层将卷积层或池化层的输出进行展开,并连接到输出层,用于进行分类或预测。全连接层通常包括softmax激活函数,将输出映射到类别概率上。
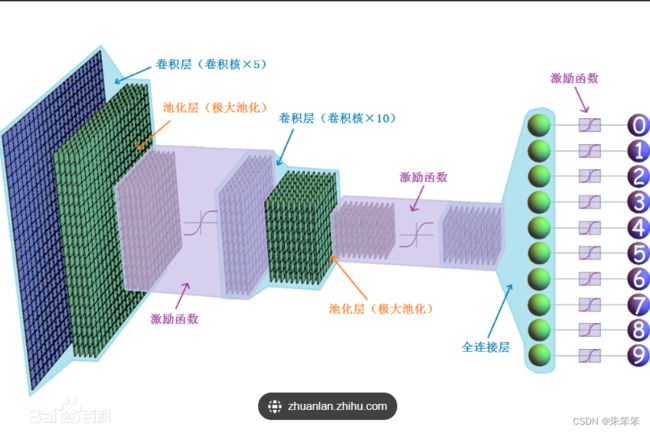
CNN在图像处理任务中表现出色,它可以自动学习并提取图像的特征,包括边缘、纹理、形状等,而不需要手工设计特征。因此,在许多视觉任务中,CNN已经超越了人类的表现。
下面简单呈现一下网络结构:网上找的比较容易理解。
4、ResNet18识别草书实战
本部分用ResNet18这个网络实现识别草书。
4.1数据展示


4.2导入的库
import matplotlib
matplotlib.rcParams['axes.unicode_minus']=False
import seaborn as sns
sns.set(font= "Kaiti",style="ticks",font_scale=1.4)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt#绘图
from mpl_toolkits.mplot3d import Axes3D#3D绘图
import os#文件操作
from PIL import Image#图像处理
from sklearn.preprocessing import LabelEncoder#标签编码
from sklearn.model_selection import train_test_split#划分数据集
import torch#pytorch
import torch.nn as nn#神经网络模块
import torch.nn.functional as F#激活函数
from torch.optim import SGD,Adam#SGD随机梯度下降法,Adam自适应梯度下降法
import torch.utils.data as Data#数据加载器
from torchvision import models#pytorch自带的经典模型
from torchvision import transforms#数据预处理
import time#计时器4.3数据预处理部分
## 先读取一个文件夹中的图像进行数据探索
filename = "草书均多余50/爱"
imagename = os.listdir(filename)#读取文件夹中所有的图像名字
print("图像数量:",len(imagename))
## 读取所有的图像,并可视化出其中的60张图像
plt.figure(figsize = (14,8))
for ii,imname in zip(range(60),imagename):#zip()函数将两个列表打包成元组的列表ii,iname分别为元组的两个元素
print(imname)
plt.subplot(6,10,ii+1)
img = Image.open(filename + "/" + imname)
plt.imshow(img)
plt.axis("off")
plt.title(img.size,size = 10)
plt.tight_layout()
plt.show()
## 可以发现图像数据的尺寸、背景等内容都不一样,而且有些图像的下不还带有水印等情况
看到数据部分有一些水印,然后下面有显示的尺寸也不一样,所以要做一个标准化处理
## 定义一个对单张图像进行处理的操作
def SingleImageProcess(im):
width,high = im.size
## 裁去水印
cuthigh = round(high / 12)#裁去高度的1/12
im = im.crop((0,0,width,high-cuthigh))#crop()函数裁剪图像
im = im.convert("L") ## 转化为灰度图像
## 尺寸转化为128*128
im = im.resize((128,128), Image.ANTIALIAS)
return im
## 定义一个读取单个文件夹图像的程序
def readimages(filedir,filename):
filealldir = filedir + "/" + filename
imfiles = os.listdir(filealldir) # 索取所有的图像文件名称
## 过滤掉隐藏文件
imfiles = [imf for imf in imfiles if not imf.startswith('.')]#startswith()方法用于检查字符串是否是以指定子字符串开头
imnum = len(imfiles) # 图像的数量
imgs = [] # 图像保存为列表
imlab = [filename] * imnum # 图像的标签
## 读取图像
for name in imfiles:
imdir = filealldir + "/" + name
img = Image.open(imdir)
## 对每张图像进行预处理
img = SingleImageProcess(img)
imgs.append(np.array(img))
return imgs,np.array(imlab)
## 定义一个读取所有子文件夹图像的函数
def readallimages(filedir):
imagename = os.listdir(filedir)
## 过滤掉隐藏文件
imagename = [imf for imf in imagename if not imf.startswith('.')]
imgs = [] # 使用列表保存所有图像数据
labs = [] # 使用列表保存所有图像标签
## 读取单个文件夹的数据
for filename in imagename:
onefileimages, onefilelabs = readimages(filedir,filename)
imgs.append(onefileimages) # 数组拼接
labs.append(onefilelabs)
return imgs,labs
## 调用所定义的函数,读取所有数据
filename = "草书均多余50"
allfileimages, allfilelabs = readallimages(filename)
## 数据转化为数组
allfileimages = np.concatenate(allfileimages)
allfilelabs = np.concatenate(allfilelabs,axis = 0)
print(allfileimages.shape)
print(allfilelabs.shape)输出结果如下:
im = im.resize((128,128), Image.ANTIALIAS)
(9083, 128, 128) (9083,)总体来说图片已经达到我们预期了。
下面的代码展示处理后的部分内容:
## 对标签进编码
LE = LabelEncoder().fit(allfilelabs)
imagelab =LE.transform(allfilelabs)
## 可视化其中的部分图像用于查看
imagex = allfileimages / 225.0#归一化,目的是为了使得图像的像素值在0-1之间
## 随机选择一些样本进行可视化
np.random.seed(123)
index = np.random.permutation(len(imagelab))[0:100]
plt.figure(figsize = (10,9))
for ii,ind in enumerate(index):
plt.subplot(10,10,ii+1)
img = imagex[ind,...]
plt.imshow(img,cmap = plt.cm.gray)
plt.axis("off")
plt.subplots_adjust(wspace=0.05,hspace=0.05)
plt.show()
4.4切割数据集并定义数据加载器
我们采用的test_size为0.25 然后是6812张图片当训练集,2271张图片为测试集,同时每张图片拥有自己的标签。
## 数据切分为训练集和测试集
X_train_im,X_test_im,y_train_im,y_test_im = train_test_split(
imagex,imagelab,test_size = 0.25,random_state = 2)
## 将数据转化为Pytorch可以使用的张量
train_xt = torch.from_numpy(X_train_im.astype(np.float32))
train_xt = train_xt.unsqueeze(1) # 添加一个颜色通道
train_yt = torch.from_numpy(y_train_im.astype(np.int64))
test_xt = torch.from_numpy(X_test_im.astype(np.float32))
test_xt = test_xt.unsqueeze(1)
test_yt = torch.from_numpy(y_test_im.astype(np.int64))
print(train_xt.shape)
print(train_yt.shape)
print(test_xt.shape)
print(test_yt.shape)
## 构建数据加载器
BATCH_SIZE = 64 # 每个Batch使用的图像数量
## 定义一个训练数据加载器
train_data = Data.TensorDataset(train_xt,train_yt)
train_loader = Data.DataLoader(
dataset = train_data, ## 使用的数据集
batch_size=BATCH_SIZE, ## 批处理样本大小
shuffle = True, ## 每次迭代前打乱数据
num_workers = 0,
)
## 定义一个测试数据加载器
test_data = Data.TensorDataset(test_xt,test_yt)
test_loader = Data.DataLoader(
dataset = test_data, ## 使用的数据集
batch_size=BATCH_SIZE, ## 批处理样本大小
shuffle = False, ## 每次迭代前不打乱数据
num_workers = 0,
)
## 查看一个batch的图像的尺寸
for step, (b_x, b_y) in enumerate(train_loader):
if step > 0:
break
## 输出训练图像的尺寸和标签的尺寸,都是torch格式的数据
print(b_x.shape)
print(b_y.shape)4.5训练网络
先加载训练模型,然后修改里面的一些参数
resnet18 = models.resnet18(pretrained=True)#加载预训练模型
resnet18.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3,bias=False)#修改输入通道数1,输出通道数64,卷积核大小7*7,步长2,填充3
resnet18.fc = nn.Sequential(nn.Linear(512,91),nn.Softmax(dim = 1))#修改全连接层的输出为91,添加一个softmax层的意义是将输出转化为概率
resnet18网络的具体参数如下,反正一定要让参数调好,根据你传入的图片来不然就会报错。

训练过程函数
## 定义网络的训练过程函数
def train_CNNNet(model,traindataloader, testdataloader,criterion, optimizer,num_epochs=25):#变量分别表示模型,训练数据,测试数据,损失函数,优化器,迭代次数
## 保存训练和测试过程中的损失和预测精度
train_loss_all = []#训练集损失
train_acc_all = []#训练集精度
test_loss_all = []#测试集损失
test_acc_all = []#测试集精度
for epoch in range(num_epochs):#num_epochs为迭代次数
print('-' * 10)
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
# 每个epoch有两个阶段,训练阶段和测试阶段
train_loss = 0.0
train_corrects = 0
train_num = 0
test_loss = 0.0
test_corrects = 0
test_num = 0
model.train() ## 设置模型为训练模式
for step,(b_x,b_y) in enumerate(traindataloader):#step表示第几个batch,b_x表示图像数据,b_y表示标签
# b_x = b_x.to(device)#将数据移动到GPU上
# b_y = b_y.to(device)
output = model(b_x)
pre_lab = torch.argmax(output,1)
loss = criterion(output, b_y) # 计算损失
optimizer.zero_grad() # 梯度归零
loss.backward() # 损失后项传播
optimizer.step() # 优化参数
train_loss += loss.item() * b_x.size(0)
train_corrects += torch.sum(pre_lab == b_y.data)
train_num += b_x.size(0)
## 计算一个epoch在训练集上的损失和精度
train_loss_all.append(train_loss / train_num)
train_acc_all.append(train_corrects.double().item()/train_num)
print('{} Train Loss: {:.4f} Train Acc: {:.4f}'.format(
epoch, train_loss_all[-1], train_acc_all[-1]))
## 计算一个epoch的训练后在测试集上的损失和精度
model.eval() ## 设置模型为训练模式评估模式
for step,(b_x,b_y) in enumerate(testdataloader):
# b_x = b_x.to(device)
# b_y = b_y.to(device)
output = model(b_x)
pre_lab = torch.argmax(output,1)
loss = criterion(output, b_y)
test_loss += loss.item() * b_x.size(0)
test_corrects += torch.sum(pre_lab == b_y.data)
test_num += b_x.size(0)
## 计算一个epoch在测试集上的损失和精度
test_loss_all.append(test_loss / test_num)
test_acc_all.append(test_corrects.double().item()/test_num)
print('{} Test Loss: {:.4f} Test Acc: {:.4f}'.format(
epoch, test_loss_all[-1], test_acc_all[-1]))
## 输出相关训练过程的数值
train_process = pd.DataFrame(
data={"epoch":range(num_epochs),
"train_loss_all":train_loss_all,
"train_acc_all":train_acc_all,
"test_loss_all":test_loss_all,
"test_acc_all":test_acc_all})
return model,train_process然后是主函数 :
## 定义计算设备
device = torch.device("cuda:2" if torch.cuda.is_available() else "cpu")
## 训练网络时没经过一定的epoch改变学习率的大小
train_promodel = [] ## 网络训练过程
LR = [0.0005,0.0001]#学习率
loss_func = nn.CrossEntropyLoss() # 交叉熵损失函数
EachEpoch = [20,20] # 每隔EachEpoch次训练更新一次学习率
## 训练
for ii,lri in enumerate(LR):
# 定义优化器
print("======学习率为:",lri,"======")
optimizer1 = torch.optim.Adam(resnet18.parameters(),lr=lri)
resnet18,train_process = train_CNNNet(
resnet18,train_loader,test_loader,loss_func,
optimizer1, num_epochs=EachEpoch[ii])
## 保存训练过程
train_promodel.append(train_process)
## 组合查看训练过程数据表
mytrain_promodel = pd.concat(train_promodel) 这里作者训练了2小时,因为c盘很满且cuda核cudnn没配好用不了gpu(哭死)。
训练结果如下:

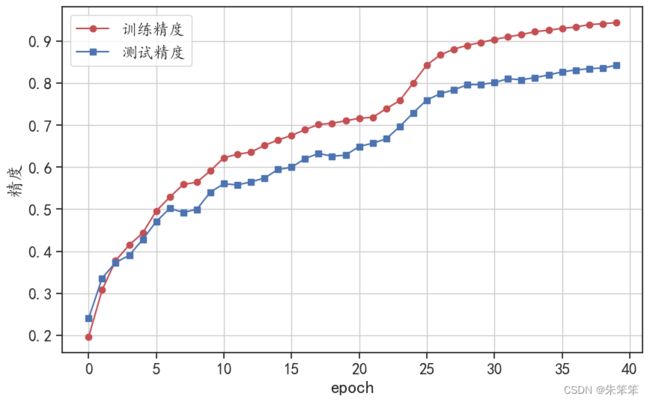
总体来说测试姐最后的精度有0.8424还不错
4.6可视化损失函数、精度变化
## 可视化训练过程和测试过程的损失函数变化情况
plotlen = mytrain_promodel.shape[0]#shape[0]表示行数,plotlen表示训练过程的迭代次数,mytrain_promodel.shape[0]表示训练过程的迭代次数
print(plotlen)#输出训练过程的迭代次数
plt.figure(figsize=(10,6))
plt.plot(np.arange(plotlen),mytrain_promodel.train_loss_all,
"r-o",label = "训练损失")
plt.plot(np.arange(plotlen),mytrain_promodel.test_loss_all,
"k-s",label = "测试损失")
plt.legend()
plt.grid()
plt.xlabel("Epoch number")
plt.ylabel("损失")
plt.show()
## 可视化训练过程和测试过程的预测精度变化情况
plt.figure(figsize=(10,6))
plt.plot(np.arange(plotlen),mytrain_promodel.train_acc_all,
"r-o",label = "训练精度")
plt.plot(np.arange(plotlen),mytrain_promodel.test_acc_all,
"b-s",label = "测试精度")
plt.xlabel("epoch")
plt.ylabel("精度")
plt.legend()
plt.grid()
plt.show()

总结
总体来说卷积神经网络还是很值得我们去学习的,最后的全连接层可做分类可做回归。作者也在尝试寻找一些深度学习模型做一下简单的图像修复问题。不过在学习过程中,是十分痛苦的,这部分的内容十分抽象,而且难以用语言去解释。
作者还会继续深入学习这方面知识的,估计最近会很忙,作者也会抽空来写写博客的。然后感谢各位的观看与支持。希望下一篇博客是我自己亲手调出的图像修复卷积神经网络。
