【NA】函数最佳逼近(一)
- 【问题描述】对于给定的函数 f f f,要求在一个简单函数类 B B B (例如多项式函数类、三角函数类)中寻找一个函数 s s s 来近似 f f f,使误差在某种度量(例如绝对值误差、平方误差)下达到最小。由此求出的函数 s ( x ) s(x) s(x) 称为 f ( x ) f(x) f(x) 的最佳逼近函数,这样的问题称为最佳逼近问题。若 f ( x ) f(x) f(x) 是连续变量的函数,称 s ( x ) s(x) s(x) 为函数逼近;若由 f ( x ) f(x) f(x) 的离散数据求出 s ( x ) s(x) s(x),称为数据拟合。
- 我们可以看到,在上面的描述中有两个关键点:①简单函数类;②误差度量标准。前者决定了构造出的函数空间,后者决定了衡量逼近质量的标准。不同的函数空间构造以及度量准则形成了不同的数值逼近方法。
- 在最佳逼近问题中,如果使用内积诱导范数来度量误差,那么该最佳逼近问题本质上是内积空间中的正交投影问题。
正片开始
- 正交投影.
-
- 正交投影定理.
- 正规方程法.
- Machine Learning.
- 误差估计.
- 实值连续函数.
-
- Hilbert矩阵.
正交投影.
- 设 { x i ∣ i = 1 , 2 , . . . , n } \{x_i|i=1,2,...,n\} {xi∣i=1,2,...,n} 是内积空间 U U U 中的 n n n 个线性无关元素,张成一个 n n n 维线性子空间 M = s p a n { x 1 , x 2 , . . . , x n } = { y ∣ y = ∑ i = 1 n α i x i } M=span\{x_1,x_2,...,x_n\}=\{y|y=\sum^n_{i=1}\alpha_ix_i\} M=span{x1,x2,...,xn}={y∣y=∑i=1nαixi}.
- 若对于 ∀ x ∈ U , ∃ x ∗ = ∑ i = 1 n α ∗ x i ∈ M \forall x \in U,\exist x^*=\sum^n_{i=1}\alpha^*x_i\in M ∀x∈U,∃x∗=∑i=1nα∗xi∈M 使得 ∣ ∣ x − x ∗ ∣ ∣ = m i n y ∈ M ∣ ∣ x − y ∣ ∣ ||x-x^*||=min_{y\in M}||x-y|| ∣∣x−x∗∣∣=miny∈M∣∣x−y∣∣,则称 x ∗ x^* x∗ 是 x x x 在 M M M 中的最佳逼近元,这里的范数 ∣ ∣ ● ∣ ∣ ||●|| ∣∣●∣∣ 是内积 ( ● , ● ) (●,●) (●,●) 诱导出的范数。
正交投影定理.
- 若 M M M 是内积空间 U U U 中完备的线性子空间,那么对于 ∀ x ∈ U \forall x \in U ∀x∈U,在 M M M 中存在唯一的正交投影 x ∗ x^* x∗,即 x ∗ ∈ M , x − x ∗ ∈ M ⊥ x^*\in M,x-x^*\in M^{\bot} x∗∈M,x−x∗∈M⊥;并且 x ∗ x^* x∗ 是 x x x 在 M M M 中的最佳逼近元,即 ∣ ∣ x − x ∗ ∣ ∣ = m i n y ∈ M ∣ ∣ x − y ∣ ∣ ||x-x^*||=min_{y\in M}||x-y|| ∣∣x−x∗∣∣=miny∈M∣∣x−y∣∣.
- 该定理表明,内积空间中的任意元素在完备线性子空间中存在唯一的正交投影,并且该正交投影也是最佳逼近元。于是采取内积诱导范数衡量误差的最佳逼近问题等价于内积空间中的正交投影问题。
正规方程法.
- 依据正交投影定理,我们仅需求解出正交投影就能解决一类特殊的最佳逼近问题。
- 正交投影 x ∗ x^* x∗ 满足以下两点 x ∗ ∈ M ; x − x ∗ ∈ M ⊥ x^*\in M;x-x^*\in M^{\bot} x∗∈M;x−x∗∈M⊥,等价形式为 ① x ∗ = ∑ i = 1 n α i ∗ x i ; ② ( x − x ∗ , x j ) = 0 , j = 1 , 2 , . . . , n ①x^*=\sum^n_{i=1}\alpha_i^*x_i;②(x-x^*,x_j)=0,j=1,2,...,n ①x∗=∑i=1nαi∗xi;②(x−x∗,xj)=0,j=1,2,...,n.
- 将①代入②得到 ( x − ∑ i = 1 n α i ∗ x i , x j ) = 0 , j = 1 , 2 , . . . , n (x-\sum^n_{i=1}\alpha_i^*x_i,x_j)=0,j=1,2,...,n (x−∑i=1nαi∗xi,xj)=0,j=1,2,...,n,其中 x j x_j xj 代表完备线性子空间中的线性无关元素。根据内积性质可得 ∑ i = 1 n α i ∗ ( x i , x j ) = ( x , x j ) , j = 1 , 2 , . . . , n \sum^n_{i=1}\alpha_i^*(x_i,x_j)=(x,x_j),j=1,2,...,n ∑i=1nαi∗(xi,xj)=(x,xj),j=1,2,...,n.
- 转化为矩阵表示:

- 上面的线性方程组称为正规方程组Normal Equations,简记为 A α ∗ = b A\alpha^*=b Aα∗=b. 显然系数矩阵 A A A 是共轭对称矩阵,而 x i ∣ i = 1 , 2 , . . . , n x_i|i=1,2,...,n xi∣i=1,2,...,n 是线性无关组,所以 A A A 非奇异矩阵,正规方程组存在唯一解 α ∗ \alpha^* α∗,对应着 x x x 在 M M M 中有唯一的最佳逼近元 x ∗ = ∑ i = 1 n α i ∗ x i x^*=\sum^n_{i=1}\alpha^*_ix_i x∗=∑i=1nαi∗xi.
- 当线性空间 M M M 的这组无关向量正交时,即 ( x i , x j ) = 0 ∣ i ≠ j (x_i,x_j)=0|i≠j (xi,xj)=0∣i=j,此时 A A A 为对角矩阵,系数 α i ∗ = ( x , x i ) ( x i , x i ) , i = 1 , 2 , . . . , n \alpha^*_i=\frac{(x,x_i)}{(x_i,x_i)},i=1,2,...,n αi∗=(xi,xi)(x,xi),i=1,2,...,n;如果条件更强烈, { x i ∣ i = 1 , 2 , . . . , n } \{x_i|i=1,2,...,n\} {xi∣i=1,2,...,n} 是一组规范正交系,那么 α i ∗ = ( x , x i ) \alpha_i^*=(x,x_i) αi∗=(x,xi).
Machine Learning.
- 回忆机器学习中的线性回归问题 Y = X θ + b ; y ∈ R m , X ∈ R m × n , θ ∈ R n , b ∈ R n Y=X\theta+b;y\in R^m,X\in R^{m×n},\theta \in R^n,b\in R^n Y=Xθ+b;y∈Rm,X∈Rm×n,θ∈Rn,b∈Rn,给定数据集 ( X , Y ) = { ( x ( i ) , y ( i ) ) ∣ i = 1 , 2 , . . . , m } (X,Y)=\{(x^{(i)},y^{(i)})|i=1,2,...,m\} (X,Y)={(x(i),y(i))∣i=1,2,...,m},我们需要拟合出参数 θ , b . \theta,b. θ,b.
- 上面的线性回归问题也可以写为线性方程组的矩阵形式:

- 我们的目的是寻找使得平方误差最小的参数 θ \theta θ,等价于求解 θ ∗ = a r g m a x θ ∣ ∣ y − X θ ∣ ∣ 2 = a r g m a x θ ( y − X θ ) T ( y − X θ ) . \theta^*=argmax_{\theta}||y-X\theta||^2=argmax_{\theta}(y-X\theta)^T(y-X\theta). θ∗=argmaxθ∣∣y−Xθ∣∣2=argmaxθ(y−Xθ)T(y−Xθ). 对参数 θ \theta θ 求偏导数并令其为0,最终解得 θ ∗ = ( X T X ) − 1 X T y . \theta^*=(X^TX)^{-1}X^Ty. θ∗=(XTX)−1XTy.
误差估计.
- 我们得到的最佳逼近元为 x ∗ x^* x∗,记误差 δ = x − x ∗ \delta=x-x^* δ=x−x∗,那么 ∣ ∣ δ ∣ ∣ 2 = ∣ ∣ x − x ∗ ∣ ∣ 2 = ( x − x ∗ , x − x ∗ ) = ( x − x ∗ , x ) − ( x − x ∗ , x ∗ ) = ( x − x ∗ , x ) = ( x , x ) − ∑ i = 1 n α i ∗ ( x i , x ) ||\delta||^2=||x-x^*||^2=(x-x^*,x-x^*)=(x-x^*,x)-(x-x^*,x^*)=(x-x^*,x)=(x,x)-\sum^n_{i=1}\alpha_i^*(x_i,x) ∣∣δ∣∣2=∣∣x−x∗∣∣2=(x−x∗,x−x∗)=(x−x∗,x)−(x−x∗,x∗)=(x−x∗,x)=(x,x)−∑i=1nαi∗(xi,x).
- 另一方面由于 x = x ∗ + δ x=x^*+\delta x=x∗+δ,所以 ∣ ∣ x ∣ ∣ 2 = ( x , x ) = ( x ∗ + δ , x ∗ + δ ) = ( x ∗ , x ∗ ) + ( δ , δ ) + ( x ∗ , δ ) + ( δ , x ∗ ) = ∣ ∣ x ∗ ∣ ∣ + ∣ ∣ δ ∣ ∣ 2 ||x||^2=(x,x)=(x^*+\delta,x^*+\delta)=(x^*,x^*)+(\delta,\delta)+(x^*,\delta)+(\delta,x^*)=||x^*||+||\delta||^2 ∣∣x∣∣2=(x,x)=(x∗+δ,x∗+δ)=(x∗,x∗)+(δ,δ)+(x∗,δ)+(δ,x∗)=∣∣x∗∣∣+∣∣δ∣∣2.
- 综合上述两式,有 ∣ ∣ x ∗ ∣ ∣ 2 = ( x ∗ , x ∗ ) = ∑ i = 1 n α i ∗ ( x i , x ) = ( x ∗ , x ) ||x^*||^2=(x^*,x^*)=\sum^n_{i=1}\alpha_i^*(x_i,x)=(x^*,x) ∣∣x∗∣∣2=(x∗,x∗)=∑i=1nαi∗(xi,x)=(x∗,x). 以二维向量空间直观理解,即 ( x ∗ , x ) = ∣ ∣ x ∗ ∣ ∣ ⋅ ∣ ∣ x ∣ ∣ ⋅ c o s < x ∗ , x > = ∣ ∣ x ∗ ∣ ∣ 2 (x^*,x)=||x^*||·||x||·cos
实值连续函数.
- 上部分中讨论了以平方误差(2范数)为标准的最佳逼近问题,转化为内积空间中的正交投影问题求解。对于实值连续函数的逼近问题而言,上部分中的讨论就不再适用。因此我们需要定义新的内积——函数加权内积: ( f , g ) = ∫ a b ρ ( x ) f ( x ) g ( x ) d x . (f,g)=\int_a^b\rho(x)f(x)g(x)dx. (f,g)=∫abρ(x)f(x)g(x)dx.
- 以及由此内积诱导出的函数加权2范数: ∣ ∣ f ∣ ∣ 2 = ∫ a b ρ ( x ) f 2 ( x ) d x . ||f||_2=\int_a^b\rho(x)f^2(x)dx. ∣∣f∣∣2=∫abρ(x)f2(x)dx.
- 其中的 ρ ( x ) \rho(x) ρ(x) 称为权函数,常见使用的权函数为 ρ ( x ) = 1 \rho(x)=1 ρ(x)=1. 权函数需要满足下面三条性质: ① ρ ( x ) ≥ 0 , x ∈ [ a , b ] ; ② ∫ a b x k ρ ( x ) d x < ∞ , k = 0 , 1 , 2 , . . . ; ③ ∀ h ( x ) ∈ C [ a , b ] , h ( x ) ≥ 0 , ∫ a b h ( x ) ρ ( x ) d x = 0 ⇒ h ( x ) ≡ 0. \\①\rho(x)≥0,x\in[a,b];\\②\int_a^bx^k\rho(x)dx<∞,k=0,1,2,...;\\③\forall h(x)\in C[a,b],h(x)≥0,\int_a^bh(x)\rho(x)dx=0\Rightarrow h(x)≡0. ①ρ(x)≥0,x∈[a,b];②∫abxkρ(x)dx<∞,k=0,1,2,...;③∀h(x)∈C[a,b],h(x)≥0,∫abh(x)ρ(x)dx=0⇒h(x)≡0.
- 设 { ϕ i ( x ) ∣ i = 0 , 1 , . . . , n } \{\phi_i(x)|i=0,1,...,n\} {ϕi(x)∣i=0,1,...,n} 是 C [ a , b ] C[a,b] C[a,b] 中的 n + 1 n+1 n+1 个线性无关函数,张成线性子空间 M = s p a n { ϕ 0 ( x ) , ϕ 1 ( x ) , . . . , ϕ n ( x ) } ⊂ C [ a , b ] . M=span\{\phi_0(x),\phi_1(x),...,\phi_n(x)\}\subset C[a,b]. M=span{ϕ0(x),ϕ1(x),...,ϕn(x)}⊂C[a,b]. 若对于 f ( x ) ∈ C [ a , b ] f(x)\in C[a,b] f(x)∈C[a,b],存在 s ∗ ( x ) = ∑ i = 0 n α i ∗ ϕ i ( x ) ∈ M s^*(x)=\sum^n_{i=0}\alpha^*_i\phi_i(x)\in M s∗(x)=∑i=0nαi∗ϕi(x)∈M 使得 ∣ ∣ f ( x ) − s ∗ ( x ) ∣ ∣ 2 = m i n s ( x ) ∈ M ∣ ∣ f ( x ) − s ( x ) ∣ ∣ 2 . ||f(x)-s^*(x)||_2=min_{s(x)\in M}||f(x)-s(x)||_2. ∣∣f(x)−s∗(x)∣∣2=mins(x)∈M∣∣f(x)−s(x)∣∣2. 那么 s ∗ ( x ) s^*(x) s∗(x) 称为 f ( x ) f(x) f(x) 在空间 M M M 中带权函数 ρ ( x ) \rho(x) ρ(x) 的最佳平方逼近函数。
若误差度量采用2-范数,则最佳逼近问题称为最佳平方逼近;若采用 ∞ ∞ ∞-范数,则称为最佳一致逼近。
- 在完备的子空间 M M M 中,最优解 s ∗ ( x ) = ∑ i = 0 n α i ∗ ϕ i ( x ) s^*(x)=\sum^n_{i=0}\alpha^*_i\phi_i(x) s∗(x)=∑i=0nαi∗ϕi(x) 唯一存在,其中系数 α i ∗ ∣ i = 0 , 1 , . . . , n \alpha_i^*|i=0,1,...,n αi∗∣i=0,1,...,n 是如下正规方程组的解:
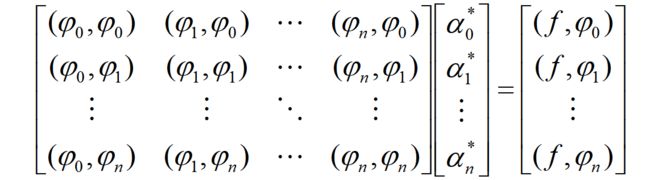
- 在前面的插值问题中,由于多项式函数计算简单的优势,我们常采取多项式函数作为插值基函数。在函数逼近中也是如此,常取 M = s p a n { 1 , x , x 2 , . . . , x n } = { x k ∣ k = 0 , 1 , . . . , n } M=span\{1,x,x^2,...,x^n\}=\{x^k|k=0,1,...,n\} M=span{1,x,x2,...,xn}={xk∣k=0,1,...,n},此时得到的 s ∗ ( x ) s^*(x) s∗(x) 称为最佳平方逼近多项式,可以视为最佳平方逼近函数中的一类。
Hilbert矩阵.
- 考虑上部分最后提到的完备线性子空间 M = { x k ∣ k = 0 , 1 , . . . , n } M=\{x^k|k=0,1,...,n\} M={xk∣k=0,1,...,n},在区间 [ 0 , 1 ] [0,1] [0,1] 中写出正规方程组,发现其系数矩阵为 n − 1 n-1 n−1 阶Hilbert矩阵。
- 推导如下: ( ϕ i , ϕ j ) = ∫ 0 1 x i x j d x = ( i + j + 1 ) − 1 (\phi_i,\phi_j)=\int_0^1x^ix^jdx=(i+j+1)^{-1} (ϕi,ϕj)=∫01xixjdx=(i+j+1)−1,因此其系数矩阵如下所示:
- 当 n n n 较大时,该系数矩阵病态程度很高,导致整个线性方程组数值解不稳定。为了解决这一问题,我们希望在空间 M M M 中寻找一组正交多项式基,高效地得到最佳逼近函数 s ∗ ( x ) s^*(x) s∗(x) 中的系数,从而避免病态方程组求解问题。