thinkphp6-学习记录-应用手册
thinkphp6
-
- ThinkPHP6-开发学习整理 TP6 框架源码下载
-
-
- 项目目录
- 框架测试
-
- 安装
- 重点介绍
- TP6的架构详述-依赖注入
- 容器与系统服务和门面
- 中间件
- 事件触发监听
- 路由器详解
- 数据库
-
- 主要特性:
- 连接数据库
-
- 配置文件
- 连接参数
- 切换连接
- 模型类定义
- 配置参数参考
- 断线重连
- 分布式数据库
-
- 分布式支持
- 读写分离
- 主库读取
- 查询构造器
-
- 查询数据
-
- 查询单个数据
- 查询数据集
- 值和列查询
- 数据分批处理
- 游标查询
- 添加数据
-
- 添加一条数据
- 添加多条数据
- 更新数据
-
- 自增/自减
- 删除数据
- 查询表达式
-
- 等于(=)
- 不等于(<>)
- 大于(>)
- 小于(<)
- 小于等于(<=)
- [NOT] LIKE: 同sql的LIKE
- [NOT] BETWEEN :同sql的[not] between
- [NOT] IN: 同sql的[not] in
- [NOT] NULL :
- EXP:表达式
- 模型
-
- 模型字段
-
- 字段类型
- 废弃字段
- 获取数据
- 模型赋值
- 严格区分字段大小写
- 模型数据转驼峰
- 新增
-
- 添加一条数据
- 获取自增ID
- 批量增加数据
- 静态方法
- 更新
-
- 查找并更新
- 批量更新数据
- 直接更新(静态方法)
- 自动识别
- 删除
-
- 删除当前模型
- 根据主键删除
- 条件删除
- 查询
-
- 获取单个数据
- 获取多个数据
- 自定义数据集对象
- 使用查询构造器
- 获取某个字段或者某个列的值
- 动态查询
- 聚合查询
- 数据分批处理
- 使用游标查询
composer update topthink/framework
ThinkPHP6-开发学习整理 TP6 框架源码下载
打开Composer官网:https://www.phpcomposer.com/
https://packagist.org/
输入搜索关键字: topthink, 在下面会列出与ThinkPHP框架相关的组件包

composer create-project topthink/think

// 打开终端,执行指令:
composer create-project topthink/think tp6 6.0.*-dev
/**
* 指令中各个参数的解释:
* `create-project`: 是composer中的项目创建命令
* `topthink/think`: ThinkPHP的组件包
* `tp6`: 是当前的项目目录(如果没有创建, 该命令会自动创建的)
* `6.0.*-dev`: 要下载的版本标签
*/


项目目录

框架测试
这里使用框架内置的 think 命令测试
该命令会启动一个本地的临时Web服务器,
功能与 php -S localhost:8000 是一样的
创建本地服务器, 启动框架
php think run


安装



















重点介绍






TP6的架构详述-依赖注入
































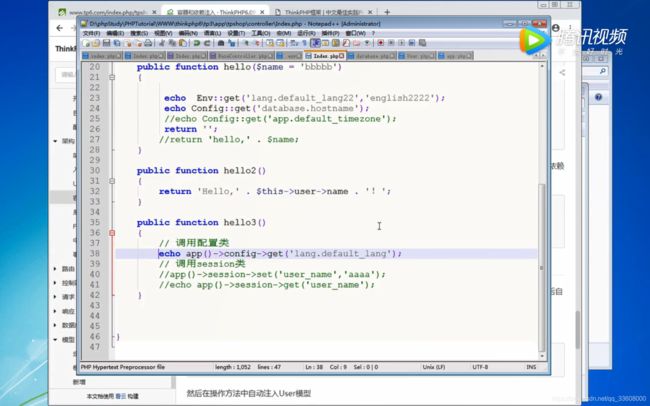






容器与系统服务和门面


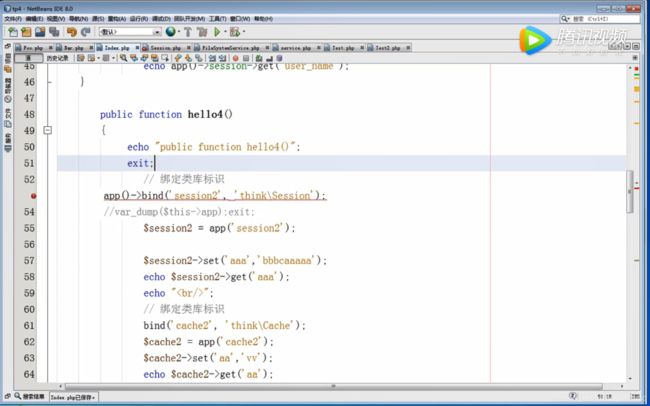






























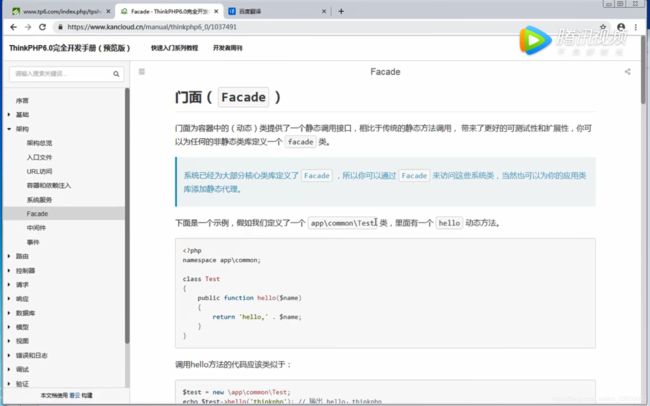


















中间件




















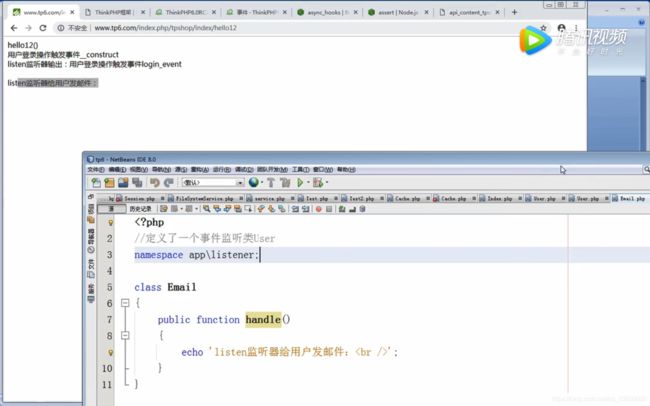
事件触发监听








路由器详解








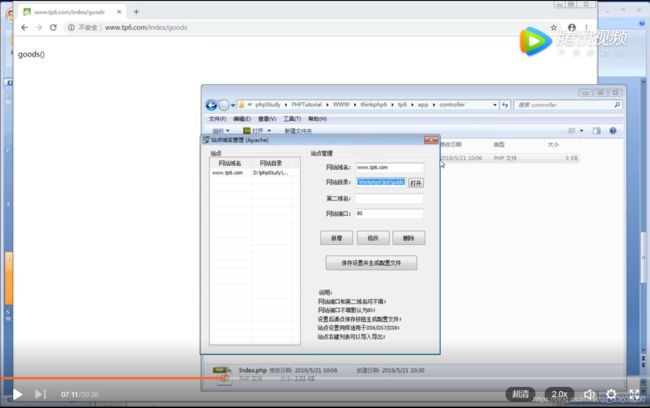
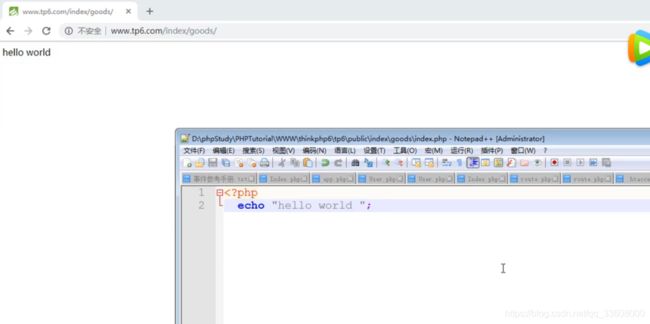















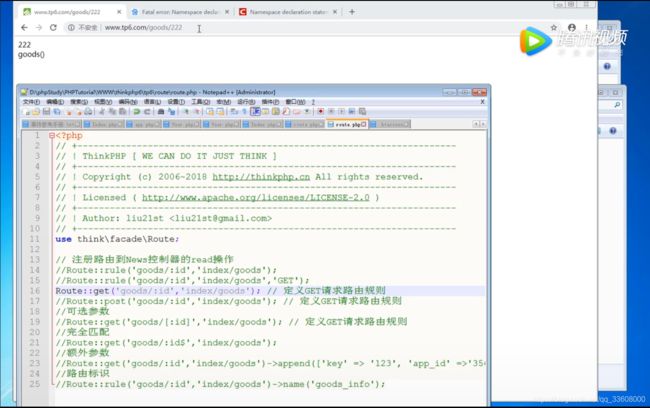











数据库
新版的数据库和模型操作已经独立为ThinkORM库,默认安装应用的时候会自动安装,如果你不需要使用该ORM库的话,可以单独卸载topthink/think-orm后安装其它的ORM库。
主要特性:
基于PDO和PHP强类型实现
支持原生查询和查询构造器
自动参数绑定和预查询
简洁易用的查询功能
强大灵活的模型用法
支持预载入关联查询和延迟关联查询
支持多数据库及动态切换
支持MongoDb
支持分布式及事务
支持断点重连
支持JSON查询
支持数据库日志
支持PSR-16缓存及PSR-3日志规范
要使用Db类必须使用门面方式(think\facade\Db)调用
连接数据库
如果应用需要使用数据库,必须配置数据库连接信息,数据库的配置文件有多种定义方式。
配置文件
在全局或者应用配置目录(不清楚配置目录位置的话参考配置章节)下面的database.php中(后面统称为数据库配置文件)配置下面的数据库参数:
return [
'default' => 'mysql',
'connections' => [
'mysql' => [
// 数据库类型
'type' => 'mysql',
// 服务器地址
'hostname' => '127.0.0.1',
// 数据库名
'database' => 'thinkphp',
// 数据库用户名
'username' => 'root',
// 数据库密码
'password' => '',
// 数据库连接端口
'hostport' => '',
// 数据库连接参数
'params' => [],
// 数据库编码默认采用utf8
'charset' => 'utf8',
// 数据库表前缀
'prefix' => 'think_',
],
],
];
新版采用多类型的方式配置,方便切换数据库。
default配置用于设置默认使用的数据库连接配置。
connections配置具体的数据库连接信息,default配置参数定义的连接配置必须要存在。
ype参数用于指定数据库类型
type 数据库
mysql MySQL
sqlite SqLite
pgsql PostgreSQL
sqlsrv SqlServer
mongo MongoDb
oracle Oracle
每个应用可以设置 独立的数据库连接参数,通常直接更改default参数即可:
return [
'default' => 'admin',
];
连接参数
可以针对不同的连接需要添加数据库的连接参数(具体的连接参数可以参考PHP手册),内置采用的参数包括如下:
PDO::ATTR_CASE => PDO::CASE_NATURAL,
PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION,
PDO::ATTR_ORACLE_NULLS => PDO::NULL_NATURAL,
PDO::ATTR_STRINGIFY_FETCHES => false,
PDO::ATTR_EMULATE_PREPARES => false,
在数据库配置文件中设置的params参数中的连接配置将会和内置的设置参数合并,如果需要使用长连接,并且返回数据库的小写列名,可以在数据库配置文件中增加下面的定义:
'params' => [
\PDO::ATTR_PERSISTENT => true,
\PDO::ATTR_CASE => \PDO::CASE_LOWER,
],
你可以在params参数里面配置任何PDO支持的连接参数。
切换连接
我们可以在数据库配置文件中定义多个连接信息
return [
'default' => 'mysql',
'connections' => [
'mysql' => [
// 数据库类型
'type' => 'mysql',
// 服务器地址
'hostname' => '127.0.0.1',
// 数据库名
'database' => 'thinkphp',
// 数据库用户名
'username' => 'root',
// 数据库密码
'password' => '',
// 数据库连接端口
'hostport' => '',
// 数据库连接参数
'params' => [],
// 数据库编码默认采用utf8
'charset' => 'utf8',
// 数据库表前缀
'prefix' => 'think_',
],
'demo' => [
// 数据库类型
'type' => 'mysql',
// 服务器地址
'hostname' => '127.0.0.1',
// 数据库名
'database' => 'demo',
// 数据库用户名
'username' => 'root',
// 数据库密码
'password' => '',
// 数据库连接端口
'hostport' => '',
// 数据库连接参数
'params' => [],
// 数据库编码默认采用utf8
'charset' => 'utf8',
// 数据库表前缀
'prefix' => 'think_',
],
],
];
我们可以调用Db::connect方法动态配置数据库连接信息,例如:
\think\facade\Db::connect('demo')
->table('user')
->find();
connect方法必须在查询的最开始调用,而且必须紧跟着调用查询方法,否则可能会导致部分查询失效或者依然使用默认的数据库连接。
动态连接数据库的connect方法仅对当次查询有效。
这种方式的动态连接和切换数据库比较方便,经常用于多数据库连接的应用需求。
模型类定义
如果某个模型类里面定义了connection属性的话,则该模型操作的时候会自动按照给定的数据库配置进行连接,而不是配置文件中设置的默认连接信息,例如:
<?php
namespace app\index\model;
use think\Model;
class User extends Model
{
protected $connection = 'demo';
}
需要注意的是,ThinkPHP的数据库连接是惰性的,所以并不是在实例化的时候就连接数据库,而是在有实际的数据操作的时候才会去连接数据库。
配置参数参考
下面是默认支持的数据库连接信息:
参数名 描述 默认值
type 数据库类型 无
hostname 数据库地址 127.0.0.1
database 数据库名称 无
username 数据库用户名 无
password 数据库密码 无
hostport 数据库端口号 无
dsn 数据库连接dsn信息 无
params 数据库连接参数 空
charset 数据库编码 utf8
prefix 数据库的表前缀 无
deploy 数据库部署方式:0 集中式(单一服务器),1 分布式(主从服务器) 0
rw_separate 数据库读写是否分离 主从式有效 false
master_num 读写分离后 主服务器数量 1
slave_no 指定从服务器序号 无
fields_strict 是否严格检查字段是否存在 true
fields_cache 是否开启字段缓存 false
trigger_sql 是否开启SQL监听 true
auto_timestamp 自动写入时间戳字段 false
query 指定查询对象 think\db\Query
常用数据库连接参数(params)可以参考PHP在线手册http://php.net/manual/zh/pdo.constants.php中的以PDO::ATTR_开头的常量。
如果同时定义了 参数化数据库连接信息 和 dsn信息,则会优先使用dsn信息。
如果是使用pgsql数据库驱动的话,请先导入 thinkphp/library/think/db/connector/pgsql.sql文件到数据库执行。
断线重连
如果你使用的是长连接或者命令行,在超出一定时间后,数据库连接会断开,这个时候你需要开启断线重连才能确保应用不中断。
在数据库连接配置中设置:
// 开启断线重连
'break_reconnect' => true,
开启后,系统会自动判断数据库断线并 尝试重新连接。大多数情况下都能自动识别,如果在一些特殊的情况下或者某些数据库驱动的断线标识错误还没有定义,支持配置下面的信息:
// 断线标识字符串
'break_match_str' => [
'error with',
],
在 break_match_str配置中加入你的数据库错误信息关键词。
分布式数据库
分布式支持
数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数:
return [
'default' => 'mysql',
'connections' => [
'mysql' => [
// 启用分布式数据库
'deploy' => 1,
// 数据库类型
'type' => 'mysql',
// 服务器地址
'hostname' => '192.168.1.1,192.168.1.2',
// 数据库名
'database' => 'demo',
// 数据库用户名
'username' => 'root',
// 数据库密码
'password' => '',
// 数据库连接端口
'hostport' => '',
],
],
];
启用分布式数据库后,hostname参数是关键,hostname的个数决定了分布式数据库的数量,默认情况下第一个地址就是主服务器。
主从服务器支持设置不同的连接参数,包括:
连接参数
username
password
hostport
database
dsn
charset
如果主从服务器的上述参数一致的话,只需要设置一个,对于不同的参数,可以分别设置,例如:
return [
'default' => 'mysql',
'connections' => [
'mysql' => [
// 启用分布式数据库
'deploy' => 1,
// 数据库类型
'type' => 'mysql',
// 服务器地址
'hostname' => '192.168.1.1,192.168.1.2,192.168.1.3',
// 数据库名
'database' => 'demo',
// 数据库用户名
'username' => 'root,slave,slave',
// 数据库密码
'password' => '123456',
// 数据库连接端口
'hostport' => '',
// 数据库字符集
'charset' => 'utf8',
],
],
];
- 记住,要么相同,要么每个都要设置。
分布式的数据库参数支持使用数组定义(通常为了避免多个账号和密码的误解析),例如:
return [
'default' => 'mysql',
'connections' => [
'mysql' => [
// 启用分布式数据库
'deploy' => 1,
// 数据库类型
'type' => 'mysql',
// 服务器地址
'hostname' =>[ '192.168.1.1','192.168.1.2','192.168.1.3'],
// 数据库名
'database' => 'demo',
// 数据库用户名
'username' => 'root,slave,slave',
// 数据库密码
'password' => ['123456','abc,def','hello']
// 数据库连接端口
'hostport' => '',
// 数据库字符集
'charset' => 'utf8',
],
],
];
读写分离
还可以设置分布式数据库的读写是否分离,默认的情况下读写不分离,也就是每台服务器都可以进行读写操作,对于主从式数据库而言,需要设置读写分离,通过下面的设置就可以:
'rw_separate' => true,
在读写分离的情况下,默认第一个数据库配置是主服务器的配置信息,负责写入数据,如果设置了master_num参数,则可以支持多个主服务器写入(每次随机连接其中一个主服务器)。
其它的地址都是从数据库,负责读取数据,数量不限制。每次连接从服务器并且进行读取操作的时候,系统会随机进行在从服务器中选择。
同一个数据库连接的每次请求只会连接一次主服务器和从服务器,如果某次请求的从服务器连接不上,会自动切换到主服务器进行查询操作。
如果不希望随机读取,或者某种情况下其它从服务器暂时不可用,还可以设置slave_no 指定固定服务器进行读操作 ,slave_no指定的序号表示hostname中数据库地址的序号,从0开始。
调用查询类或者模型的CURD操作的话,系统会自动判断当前执行的方法是读操作还是写操作并自动连接主从服务器,如果你用的是原生SQL,那么需要注意系统的默认规则:
写操作必须用数据库的execute方法,读操作必须用数据库的query方法,否则会发生主从读写错乱的情况。
发生下列情况的话,会自动连接主服务器:
使用了数据库的写操作方法(execute/insert/update/delete以及衍生方法);
如果调用了数据库事务方法的话,会自动连接主服务器;
从服务器连接失败,会自动连接主服务器;
调用了查询构造器的lock方法;
调用了查询构造器的master/readMaster方法
主从数据库的数据同步工作不在框架实现,需要数据库考虑自身的同步或者复制机制。如果在大数据量或者特殊的情况下写入数据后可能会存在同步延迟的情况,可以调用master()方法进行主库查询操作。
在实际生产环境中,很多云主机的数据库分布式实现机制和本地开发会有所区别,但通常会采下面用两种方式:
第一种:提供了写IP和读IP(一般是虚拟IP),进行数据库的读写分离操作;
第二种:始终保持同一个IP连接数据库,内部会进行读写分离IP调度(阿里云就是采用该方式)。
主库读取
有些情况下,需要直接从主库读取数据,例如刚写入数据之后,从库数据还没来得及同步完成,你可以使用
Db::name('user')
->where('id', 1)
->update(['name' => 'thinkphp']);
Db::name('user')
->master(true)
->find(1);
不过,实际情况远比这个要复杂,因为你并不清楚后续的方法里面是否还存在相关查询操作,这个时候我们可以配置开启数据库的read_master配置参数。
// 开启自动主库读取
‘read_master’ => true,
开启后,一旦我们对某个数据表进行了写操作,那么当前请求的后续所有对该表的查询都会使用主库读取。
查询构造器
查询数据
查询单个数据
查询单个数据使用find方法:
// table方法必须指定完整的数据表名
Db::table('think_user')->where('id', 1)->find();
最终生成的SQL语句可能是:
SELECT * FROM `think_user` WHERE `id` = 1 LIMIT 1
find方法查询结果不存在,返回 null,否则返回结果数组
如果希望查询数据不存在的时候返回空数组,可以使用
// table方法必须指定完整的数据表名
Db::table('think_user')->where('id', 1)->findOrEmpty();
如果希望在没有找到数据后抛出异常可以使用
Db::table('think_user')->where('id', 1)->findOrFail();
如果没有查找到数据,则会抛出一个think\db\exception\DataNotFoundException异常。
如果没有任何的查询条件 并且也没有调用order方法的话 ,find查询不会返回任何结果。
查询数据集
查询多个数据(数据集)使用select方法:
Db::table('think_user')->where('status', 1)->select();
最终生成的SQL语句可能是:
SELECT * FROM `think_user` WHERE `status` = 1
select 方法查询结果是一个数据集对象,如果需要转换为数组可以使用
Db::table('think_user')->where('status', 1)->select()->toArray();
如果希望在没有查找到数据后抛出异常可以使用
Db::table('think_user')->where('status',1)->selectOrFail();
如果没有查找到数据,同样也会抛出一个think\db\exception\DataNotFoundException异常。
如果设置了数据表前缀参数的话,可以使用
Db::name('user')->where('id', 1)->find();
Db::name('user')->where('status', 1)->select();
如果你的数据表没有设置表前缀的话,那么name和table方法效果一致。
在find和select方法之前可以使用所有的链式操作(参考链式操作章节)方法。
值和列查询
查询某个字段的值可以用
// 返回某个字段的值
Db::table('think_user')->where('id', 1)->value('name');
value 方法查询结果不存在,返回 null
查询某一列的值可以用
// 返回数组
Db::table('think_user')->where('status',1)->column('name');
// 指定id字段的值作为索引
Db::table('think_user')->where('status',1)->column('name', 'id');
如果要返回完整数据,并且添加一个索引值的话,可以使用
// 指定id字段的值作为索引 返回所有数据
Db::table('think_user')->where('status',1)->column('*','id');
column方法查询结果不存在,返回空数组
数据分批处理
如果你需要处理成千上百条数据库记录,可以考虑使用chunk方法,该方法一次获取结果集的一小块,然后填充每一小块数据到要处理的闭包,该方法在编写处理大量数据库记录的时候非常有用。
比如,我们可以全部用户表数据进行分批处理,每次处理 100 个用户记录:
Db::table('think_user')->chunk(100, function($users) {
foreach ($users as $user) {
//
}
});
你可以通过从闭包函数中返回false来中止对后续数据集的处理:
Db::table('think_user')->chunk(100, function($users) {
foreach ($users as $user) {
// 处理结果集...
if($user->status==0){
return false;
}
}
});
也支持在chunk方法之前调用其它的查询方法,例如:
Db::table('think_user')
->where('score','>',80)
->chunk(100, function($users) {
foreach ($users as $user) {
//
}
});
chunk方法的处理默认是根据主键查询,支持指定字段,例如:
Db::table('think_user')->chunk(100, function($users) {
// 处理结果集...
return false;
},'create_time');
并且支持指定处理数据的顺序。
Db::table('think_user')->chunk(100, function($users) {
// 处理结果集...
return false;
},'create_time', 'desc');
chunk方法一般用于命令行操作批处理数据库的数据,不适合WEB访问处理大量数据,很容易导致超时。
游标查询
如果你需要处理大量的数据,可以使用新版提供的游标查询功能,该查询方式利用了PHP的生成器特性,可以大幅减少大量数据查询的内存开销问题。
$cursor = Db::table('user')->where('status', 1)->cursor();
foreach($cursor as $user){
echo $user['name'];
}
cursor方法返回的是一个生成器对象,user变量是数据表的一条数据(数组)。
添加数据
添加一条数据
可以使用save方法统一写入数据,自动判断是新增还是更新数据(以写入数据中是否存在主键数据为依据)。
$data = ['foo' => 'bar', 'bar' => 'foo'];
Db::name('user')->save($data);
或者使用 insert 方法向数据库提交数据
$data = ['foo' => 'bar', 'bar' => 'foo'];
Db::name('user')->insert($data);
insert 方法添加数据成功返回添加成功的条数,通常情况返回 1
如果你的数据表里面没有foo或者bar字段,那么就会抛出异常。
如果不希望抛出异常,可以使用下面的方法:
$data = ['foo' => 'bar', 'bar' => 'foo'];
Db::name('user')->strict(false)->insert($data);
- 不存在字段的值将会直接抛弃。
如果是mysql数据库,支持replace写入,例如:
$data = ['foo' => 'bar', 'bar' => 'foo'];
Db::name('user')->replace()->insert($data);
添加数据后如果需要返回新增数据的自增主键,可以使用insertGetId方法新增数据并返回主键值:
$userId = Db::name('user')->insertGetId($data);
insertGetId 方法添加数据成功返回添加数据的自增主键
添加多条数据
添加多条数据直接向 Db 类的 insertAll 方法传入需要添加的数据(通常是二维数组)即可。
$data = [
['foo' => 'bar', 'bar' => 'foo'],
['foo' => 'bar1', 'bar' => 'foo1'],
['foo' => 'bar2', 'bar' => 'foo2']
];
Db::name('user')->insertAll($data);
insertAll方法添加数据成功返回添加成功的条数
如果是mysql数据库,支持replace写入,例如:
$data = [
['foo' => 'bar', 'bar' => 'foo'],
['foo' => 'bar1', 'bar' => 'foo1'],
['foo' => 'bar2', 'bar' => 'foo2']
];
Db::name('user')->replace()->insertAll($data);
确保要批量添加的数据字段是一致的
如果批量插入的数据比较多,可以指定分批插入,使用limit方法指定每次插入的数量限制。
$data = [
['foo' => 'bar', 'bar' => 'foo'],
['foo' => 'bar1', 'bar' => 'foo1'],
['foo' => 'bar2', 'bar' => 'foo2']
...
];
// 分批写入 每次最多100条数据
Db::name('user')
->limit(100)
->insertAll($data);
更新数据
可以使用save方法更新数据
Db::name('user')
->save(['id' => 1, 'name' => 'thinkphp']);
或者使用update方法。
Db::name('user')
->where('id', 1)
->update(['name' => 'thinkphp']);
实际生成的SQL语句可能是:
UPDATE `think_user` SET `name`='thinkphp' WHERE `id` = 1
update方法返回影响数据的条数,没修改任何数据返回 0
支持使用data方法传入要更新的数据
Db::name('user')
->where('id', 1)
->data(['name' => 'thinkphp'])
->update();
- 如果update方法和data方法同时传入更新数据,则
以update方法为准。
如果数据中包含主键,可以直接使用:
Db::name('user')
->update(['name' => 'thinkphp','id' => 1]);
实际生成的SQL语句和前面用法是一样的:
UPDATE `think_user` SET `name`='thinkphp' WHERE `id` = 1
如果要更新的数据需要使用SQL函数或者其它字段,可以使用下面的方式:
Db::name('user')
->where('id',1)
->exp('name','UPPER(name)')
->update();
实际生成的SQL语句:
UPDATE `think_user` SET `name` = UPPER(name) WHERE `id` = 1
支持使用raw方法进行数据更新。
Db::name('user')
->where('id', 1)
->update([
'name' => Db::raw('UPPER(name)'),
'score' => Db::raw('score-3'),
'read_time' => Db::raw('read_time+1')
]);
自增/自减
可以使用inc/dec方法自增或自减一个字段的值( 如不加第二个参数,默认步长为1)。
// score 字段加 1
Db::table('think_user')
->where('id', 1)
->inc('score')
->update();
// score 字段加 5
Db::table('think_user')
->where('id', 1)
->inc('score', 5)
->update();
// score 字段减 1
Db::table('think_user')
->where('id', 1)
->dec('score')
->update();
// score 字段减 5
Db::table('think_user')
->where('id', 1)
->dec('score', 5)
->update();
最终生成的SQL语句可能是:
UPDATE `think_user` SET `score` = `score` + 1 WHERE `id` = 1
UPDATE `think_user` SET `score` = `score` + 5 WHERE `id` = 1
UPDATE `think_user` SET `score` = `score` - 1 WHERE `id` = 1
UPDATE `think_user` SET `score` = `score` - 5 WHERE `id` = 1
删除数据
// 根据主键删除
Db::table('think_user')->delete(1);
Db::table('think_user')->delete([1,2,3]);
// 条件删除
Db::table('think_user')->where('id',1)->delete();
Db::table('think_user')->where('id','<',10)->delete();
最终生成的SQL语句可能是:
DELETE FROM `think_user` WHERE `id` = 1
DELETE FROM `think_user` WHERE `id` IN (1,2,3)
DELETE FROM `think_user` WHERE `id` = 1
DELETE FROM `think_user` WHERE `id` < 10
delete方法返回影响数据的条数,没有删除返回 0
如果不带任何条件调用delete方法会提示错误,如果你确实需要删除所有数据,可以使用
// 无条件删除所有数据
Db::name('user')->delete(true);
最终生成的SQL语句是(删除了表的所有数据):
DELETE FROM `think_user`
一般情况下,业务数据不建议真实删除数据,系统提供了软删除机制(模型中使用软删除更为方便)。
// 软删除数据 使用delete_time字段标记删除
Db::name('user')
->where('id', 1)
->useSoftDelete('delete_time',time())
->delete();
实际生成的SQL语句可能如下(执行的是UPDATE操作):
UPDATE `think_user` SET `delete_time` = '1515745214' WHERE `id` = 1
useSoftDelete方法表示使用软删除,并且指定软删除字段为delete_time,写入数据为当前的时间戳。
查询表达式
查询表达式支持大部分的SQL查询语法,也是ThinkPHP查询语言的精髓,查询表达式的使用格式:
where('字段名','查询表达式','查询条件');
除了where方法外,还可以支持whereOr,用法是一样的。为了更加方便查询,大多数的查询表达式都提供了快捷查询方法。
表达式不分大小写,支持的查询表达式有下面几种:
表达式 含义 快捷查询方法
= 等于
<> 不等于
> 大于
>= 大于等于
< 小于
<= 小于等于
[NOT] LIKE 模糊查询 whereLike/whereNotLike
[NOT] BETWEEN (不在)区间查询 whereBetween/whereNotBetween
[NOT] IN (不在)IN 查询 whereIn/whereNotIn
[NOT] NULL 查询字段是否(不)是NULL whereNull/whereNotNull
[NOT] EXISTS EXISTS查询 whereExists/whereNotExists
[NOT] REGEXP 正则(不)匹配查询(仅支持Mysql)
[NOT] BETWEEN TIME 时间区间比较 whereBetweenTime
> TIME 大于某个时间 whereTime
< TIME 小于某个时间 whereTime
>= TIME 大于等于某个时间 whereTime
<= TIME 小于等于某个时间 whereTime
EXP 表达式查询,支持SQL语法 whereExp
find in set FIND_IN_SET查询 whereFindInSet
- 表达式查询的用法示例如下:
等于(=)
例如:
Db::name('user')->where('id','=',100)->select();
和下面的查询等效
Db::name('user')->where('id',100)->select();
最终生成的SQL语句是:
SELECT * FROM `think_user` WHERE `id` = 100
不等于(<>)
例如:
Db::name('user')->where('id','<>',100)->select();
最终生成的SQL语句是:
SELECT * FROM `think_user` WHERE `id` <> 100
大于(>)
例如:
Db::name('user')->where('id','>',100)->select();
最终生成的SQL语句是:
SELECT * FROM `think_user` WHERE `id` > 100
大于等于(>=)
例如:
Db::name('user')->where('id','>=',100)->select();
最终生成的SQL语句是:
SELECT * FROM `think_user` WHERE `id` >= 100
小于(<)
例如:
Db::name('user')->where('id', '<', 100)->select();
最终生成的SQL语句是:
SELECT * FROM `think_user` WHERE `id` < 100
小于等于(<=)
例如:
Db::name('user')->where('id', '<=', 100)->select();
最终生成的SQL语句是:
SELECT * FROM `think_user` WHERE `id` <= 100
[NOT] LIKE: 同sql的LIKE
例如:
Db::name('user')->where('name', 'like', 'thinkphp%')->select();
最终生成的SQL语句是:
SELECT * FROM `think_user` WHERE `name` LIKE 'thinkphp%'
like查询支持使用数组
Db::name('user')->where('name', 'like', ['%think','php%'],'OR')->select();
实际生成的SQL语句为:
SELECT * FROM `think_user` WHERE (`name` LIKE '%think' OR `name` LIKE 'php%')
为了更加方便,应该直接使用whereLike方法
Db::name('user')->whereLike('name','thinkphp%')->select();
Db::name('user')->whereNotLike('name','thinkphp%')->select();
[NOT] BETWEEN :同sql的[not] between
查询条件支持字符串或者数组,例如:
Db::name('user')->where('id','between','1,8')->select();
和下面的等效:
Db::name('user')->where('id','between',[1,8])->select();
最终生成的SQL语句都是:
SELECT * FROM `think_user` WHERE `id` BETWEEN 1 AND 8
或者使用快捷查询方法:
Db::name('user')->whereBetween('id','1,8')->select();
Db::name('user')->whereNotBetween('id','1,8')->select();
[NOT] IN: 同sql的[not] in
查询条件支持字符串或者数组,例如:
Db::name('user')->where('id','in','1,5,8')->select();
和下面的等效:
Db::name('user')->where('id','in',[1,5,8])->select();
最终的SQL语句为:
SELECT * FROM `think_user` WHERE `id` IN (1,5,8)
或者使用快捷查询方法:
Db::name('user')->whereIn('id','1,5,8')->select();
Db::name('user')->whereNotIn('id','1,5,8')->select();
- [NOT] IN查询支持使用闭包方式
[NOT] NULL :
查询字段是否(不)是Null,例如:
Db::name('user')->where('name', null)
->where('email','null')
->where('name','not null')
->select();
实际生成的SQL语句为:
SELECT * FROM `think_user` WHERE `name` IS NULL AND `email` IS NULL AND `name` IS NOT NULL
如果你需要查询一个字段的值为字符串null或者not null,应该使用:
Db::name('user')->where('title','=', 'null')
->where('name','=', 'not null')
->select();
推荐的方式是使用whereNull和whereNotNull方法查询。
Db::name('user')->whereNull('name')
->whereNull('email')
->whereNotNull('name')
->select();
EXP:表达式
支持更复杂的查询情况 例如:
Db::name('user')->where('id','in','1,3,8')->select();
可以改成:
Db::name('user')->where('id','exp',' IN (1,3,8) ')->select();
exp查询的条件不会被当成字符串,所以后面的查询条件可以使用任何SQL支持的语法,包括使用函数和字段名称。
推荐使用whereExp方法查询
Db::name('user')->whereExp('id', 'IN (1,3,8) ')->select();
模型
模型字段
模型的数据字段和对应数据表的字段是对应的,
默认会自动获取(包括字段类型),但自动获取会导致增加一次查询,
因此你可以在模型中明确定义字段信息避免多一次查询的开销。
<?php
namespace app\model;
use think\Model;
class User extends Model
{
// 设置字段信息
protected $schema = [
'id' => 'int',
'name' => 'string',
'status' => 'int',
'score' => 'float',
'create_time' => 'datetime',
'update_time' => 'datetime',
];
}
字段类型的定义可以使用PHP类型或者数据库的字段类型都可以,
字段类型定义的作用主要用于查询的参数自动绑定类型。
时间字段尽量采用实际的数据库类型定义,便于时间查询的字段自动识别。
如果是json类型直接定义为json即可。
如果你没有定义schema属性的话,可以在部署完成后运行如下指令。
php think optimize:schema
运行后会 自动生成数据表的字段信息缓存。使用命令行缓存的优势是Db类的查询仍然有效。
需要在数据库配置中设置fields_cache为true才能生成缓存。
字段类型
schema属性一旦定义,就必须定义完整的数据表字段类型。
如果你只希望对某个字段定义需要自动转换的类型,可以使用type属性,例如:
<?php
namespace app\model;
use think\Model;
class User extends Model
{
// 设置字段自动转换类型
protected $type = [
'score' => 'float',
];
}
type属性定义的不一定是实际的字段,也有可能是你的字段别名。
废弃字段
如果因为历史遗留问题 ,你的数据表存在很多的废弃字段,你可以在模型里面定义这些不再使用的字段。
<?php
namespace app\model;
use think\Model;
class User extends Model
{
// 设置废弃字段
protected $disuse = [ 'status', 'type' ];
}
在查询和写入的时候会忽略定义的status和type废弃字段。
获取数据
在模型外部获取数据的方法如下
$user = User::find(1);
echo $user->create_time;
echo $user->name;
由于模型类实现了ArrayAccess接口,所以可以当成数组使用。
$user = User::find(1);
echo $user['create_time'];
echo $user['name'];
如果你是在模型内部获取数据的话,需要改成:
$user = $this->find(1);
echo $user->getAttr('create_time');
echo $user->getAttr('name');
否则可能会出现意想不到的错误。
模型赋值
可以使用下面的代码给模型对象赋值
$user = new User();
$user->name = 'thinkphp';
$user->score = 100;
该方式赋值会自动执行模型的修改器,如果不希望执行修改器操作,可以使用
$data['name'] = 'thinkphp';
$data['score'] = 100;
$user = new User($data);
或者使用
$user = new User();
$data['name'] = 'thinkphp';
$data['score'] = 100;
$user->data($data);
data方法支持使用修改器
$user = new User();
$data['name'] = 'thinkphp';
$data['score'] = 100;
$user->data($data, true);
如果需要对数据进行过滤,可以使用
$user = new User();
$data['name'] = 'thinkphp';
$data['score'] = 100;
$user->data($data, true, ['name','score']);
表示只设置data数组的name和score数据。
- 注意:data方法会清空调用前设置的数据
以追加数据的方式赋值:
$user = new User();
$user->group_id = 1;
$data['name'] = 'thinkphp';
$data['score'] = 100;
$user->appendData($data); // 如果调用 data ,则清空group_id字段数据
可以通过传入第二个参数 true 来使用修改器 ,比如:appendData($data,true)
严格区分字段大小写
默认情况下,你的模型数据名称和数据表字段应该保持严格一致,也就是说区分大小写。
$user = User::find(1);
echo $user->create_time; // 正确
echo $user->createTime; // 错误
严格区分字段大小写的情况下,如果你的数据表字段是大写,模型获取的时候也必须使用大写。
如果你希望在获取模型数据的时候不区分大小写(前提是数据表的字段命名必须规范,即小写+下划线),
可以设置模型的strict属性。
<?php
namespace app\model;
use think\Model;
class User extends Model
{
// 模型数据不区分大小写
protected $strict = false,
}
你现在可以使用
$user = User::find(1);
// 下面两种方式都有效
echo $user->createTime;
echo $user->create_time;
模型数据转驼峰
V6.0.4+版本开始,可以设置convertNameToCamel属性使得模型数据返回驼峰方式命名
(前提也是数据表的字段命名必须规范,即小写+下划线)。
<?php
namespace app\model;
use think\Model;
class User extends Model
{
// 数据转换为驼峰命名
protected $convertNameToCamel = true,
}
然后在模型输出的时候可以直接使用驼峰命名的方式获取。
$user = User::find(1);
$data = $user->toArray();
echo $data['createTime']; // 正确
echo $user['create_time']; // 错误
新增
模型数据的新增和数据库的新增数据有所区别,
数据库的新增只是单纯的写入给定的数据,
而模型的数据写入会包含修改器、自动完成以及模型事件等环节.
添加一条数据
第一种是实例化模型对象后赋值并保存:
$user = new User;
$user->name = 'thinkphp';
$user->email = '[email protected]';
$user->save();
save方法成功会返回true,并且只有当before_insert事件返回false的时候返回false,
一旦有错误就会抛出异常。所以无需判断返回类型。
也可以直接传入数据到save方法批量赋值:
$user = new User;
$user->save([
'name' => 'thinkphp',
'email' => '[email protected]'
]);
默认只会写入数据表已有的字段过滤非数据表字段的数据,如果你通过外部提交赋值给模型,并且希望指定某些字段写入,可以使用:
$user = new User;
// post数组中只有name和email字段会写入
$user->allowField(['name','email'])->save($_POST);
最佳 是模型数据赋值之前就进行数据过滤,例如:
$user = new User;
// 过滤post数组中的非数据表字段数据
$data = Request::only(['name','email']);
$user->save($data);
save方法新增数据返回的是写入的记录数(通常是1),而不是自增主键值。
- Replace写入
save方法可以支持replace写入。
$user = new User;
$user->name = 'thinkphp';
$user->email = '[email protected]';
$user->replace()->save();
获取自增ID
如果要获取新增数据的自增ID,可以使用下面的方式:
$user = new User;
$user->name = 'thinkphp';
$user->email = '[email protected]';
$user->save();
// 获取自增ID
echo $user->id;
这里其实是获取模型的主键,如果你的主键不是id,而是user_id的话,其实获取自增ID就变成这样:
$user = new User;
$user->name = 'thinkphp';
$user->email = '[email protected]';
$user->save();
// 获取自增ID
echo $user->user_id;
不要在同一个实例里面多次新增数据,如果确实需要多次新增,可以使用后面的静态方法处理。
批量增加数据
支持批量新增,可以使用:
$user = new User;
$list = [
['name'=>'thinkphp','email'=>'[email protected]'],
['name'=>'onethink','email'=>'[email protected]']
];
$user->saveAll($list);
saveAll方法新增数据返回的是包含新增模型(带自增ID)的数据集对象。
saveAll方法新增数据默认会自动识别数据是需要新增还是更新操作,当数据中存在主键的时候会认为是更新操作。
静态方法
还可以直接静态调用create方法创建并写入:
$user = User::create([
'name' => 'thinkphp',
'email' => '[email protected]'
]);
echo $user->name;
echo $user->email;
echo $user->id; // 获取自增ID
和save方法不同的是,create方法返回的是当前模型的对象实例。
create方法默认会过滤不是数据表的字段信息,可以在第二个参数可以传入允许写入的字段列表,例如:
// 只允许写入name和email字段的数据
$user = User::create([
'name' => 'thinkphp',
'email' => '[email protected]'
], ['name', 'email']);
echo $user->name;
echo $user->email;
echo $user->id; // 获取自增ID
支持replace操作,使用下面的方法:
$user = User::create([
'name' => 'thinkphp',
'email' => '[email protected]'
], ['name','email'], true);
- 新增数据的最佳实践原则:使用
create方法新增数据,使用saveAll批量新增数据。
更新
更新操作同样也会经过修改器、自动完成以及模型事件等处理,并不等同于数据库的数据更新.
而且更新方法和新增方法使用的是同一个方法,通常系统会自动判断需要新增还是更新数据。
查找并更新
取出数据后,更改字段内容后使用save方法更新数据。这种方式是最佳的更新方式。
$user = User::find(1);
$user->name = 'thinkphp';
$user->email = '[email protected]';
$user->save();
对于复杂的查询条件,也可以使用查询构造器来查询数据并更新.
$user = User::where('status',1)
->where('name','liuchen')
->find();
$user->name = 'thinkphp';
$user->email = '[email protected]';
$user->save();
save方法更新数据,只会更新变化的数据,对于没有变化的数据是不会进行重新更新的。
需要强制更新数据,可以使用下面的方法:
$user = User::find(1);
$user->name = 'thinkphp';
$user->email = '[email protected]';
$user->force()->save();
无论你的修改后的数据是否和之前一样都会强制更新该字段的值。
要执行SQL函数更新,可以使用下面的方法
$user = User::find(1);
$user->name = 'thinkphp';
$user->email = '[email protected]';
$user->score = Db::raw('score+1');
$user->save();
批量更新数据
可以使用saveAll方法批量更新数据,只需要在批量更新的数据中包含主键即可,例如:
$user = new User;
$list = [
['id'=>1, 'name'=>'thinkphp', 'email'=>'[email protected]'],
['id'=>2, 'name'=>'onethink', 'email'=>'[email protected]']
];
$user->saveAll($list);
批量更新方法返回的是一个数据集对象。
- 批量更新仅能根据主键值进行更新,其它情况请自行处理。
直接更新(静态方法)
使用模型的静态update方法更新:
User::update(['name' => 'thinkphp'], ['id' => 1]);
模型的update方法返回模型的对象实例
如果你的第一个参数中包含主键数据,可以无需传入第二个参数(更新条件)
User::update(['name' => 'thinkphp', 'id' => 1]);
如果你需要只允许更新指定字段,可以使用
User::update(['name' => 'thinkphp', 'email' => '[email protected]'], ['id' => 1], ['name']);
上面的代码只会更新name字段的数据。
自动识别
我们已经看到,模型的新增和更新方法都是save方法,系统有一套默认的规则来识别当前的数据需要更新还是新增。
实例化模型后调用save方法表示新增;
查询数据后调用save方法表示更新;
不要在一个模型实例里面做多次更新,会导致部分重复数据不再更新,
正确的方式应该是先查询后更新或者使用模型类的update方法更新。
不要调用save方法进行多次数据写入。
- 最佳实践
更新的最佳实践原则是:
如果需要使用模型事件,那么就先查询后更新,如果不需要使用事件或者不查询直接更新,
直接使用静态的Update方法进行条件更新,
如非必要,尽量不要使用批量更新。
删除
模型的删除和数据库的删除方法区别在于,模型的删除会包含模型的事件处理。
删除当前模型
删除模型数据,可以在查询后调用delete方法。
$user = User::find(1);
$user->delete();
delete方法返回布尔值
根据主键删除
或者直接调用静态方法(根据主键删除)
User::destroy(1);
// 支持批量删除多个数据
User::destroy([1,2,3]);
当destroy方法传入空值(包括空字符串和空数组)的时候不会做任何的数据删除操作,但传入0则是有效的
条件删除
还支持使用闭包删除,例如:
User::destroy(function($query){
$query->where('id','>',10);
});
或者通过数据库类的查询条件删除
User::where('id','>',10)->delete();
直接调用数据库的delete方法的话无法调用模型事件。
- 最佳实践
删除的最佳实践原则是:
如果删除当前模型数据,用delete方法,
如果需要直接删除数据,使用destroy静态方法。
查询
模型查询和数据库查询方法的区别主要在于,
模型中的查询的数据在获取的时候会经过获取器的处理,以及更加对象化的获取方式。
模型查询除了使用自身的查询方法外,一样可以使用数据库的查询构造器,返回的都是模型对象实例。
但如果直接调用查询对象的方法,IDE可能无法完成自动提示。
获取单个数据
获取单个数据的方法包括:
// 取出主键为1的数据
$user = User::find(1);
echo $user->name;
// 使用查询构造器查询满足条件的数据
$user = User::where('name', 'thinkphp')->find();
echo $user->name;
模型使用find方法查询,如果数据不存在返回Null,否则返回当前模型的对象实例。
如果希望查询数据不存在则返回一个空模型,可以使用。
$user = User::findOrEmpty(1);
你可以用isEmpty方法来判断当前是否为一个空模型。
$user = User::where('name', 'thinkphp')->findOrEmpty();
if (!$user->isEmpty()) {
echo $user->name;
}
如果你是在模型内部获取数据,请不要使用$this->name的方式来获取数据,请使用$this->getAttr('name') 替代。
获取多个数据
取出多个数据:
// 根据主键获取多个数据
$list = User::select([1,2,3]);
// 对数据集进行遍历操作
foreach($list as $key=>$user){
echo $user->name;
}
要更多的查询支持,一样可以使用查询构造器:
// 使用查询构造器查询
$list = User::where('status', 1)->limit(3)->order('id', 'asc')->select();
foreach($list as $key=>$user){
echo $user->name;
}
查询构造器方式的查询可以支持更多的连贯操作,包括排序、数量限制等。
自定义数据集对象
模型的select方法返回的是一个包含多个模型实例的数据集对象(默认为\think\model\Collection),
支持在模型中单独设置查询数据集的返回对象的名称,例如:
<?php
namespace app\index\model;
use think\Model;
class User extends Model
{
// 设置返回数据集的对象名
protected $resultSetType = '\app\common\Collection';
}
resultSetType属性用于设置自定义的数据集使用的类名,该类应当继承系统的think\model\Collection类。
使用查询构造器
在模型中仍然可以调用数据库的链式操作和查询方法,可以充分利用数据库的查询构造器的优势。
例如:
User::where('id',10)->find();
User::where('status',1)->order('id desc')->select();
User::where('status',1)->limit(10)->select();
使用查询构造器直接使用静态方法调用即可,无需先实例化模型。
获取某个字段或者某个列的值
// 获取某个用户的积分
User::where('id',10)->value('score');
// 获取某个列的所有值
User::where('status',1)->column('name');
// 以id为索引
User::where('status',1)->column('name','id');
value和column方法返回的不再是一个模型对象实例,而是纯粹的值或者某个列的数组。
动态查询
支持数据库的动态查询方法,例如:
// 根据name字段查询用户
$user = User::getByName('thinkphp');
// 根据email字段查询用户
$user = User::getByEmail('[email protected]');
聚合查询
同样在模型中也可以调用数据库的聚合方法查询,例如:
User::count();
User::where('status','>',0)->count();
User::where('status',1)->avg('score');
User::max('score');
注意,如果你的字段不是数字类型,是使用max/min的时候,需要加上第二个参数。
User::max('name', false);
数据分批处理
模型也可以支持对返回的数据分批处理,这在处理大量数据的时候非常有用,例如:
User::chunk(100, function ($users) {
foreach($users as $user){
// 处理user模型对象
}
});
使用游标查询
模型也可以使用数据库的cursor方法进行游标查询,返回生成器对象
foreach(User::where('status', 1)->cursor() as $user){
echo $user->name;
}
user变量是一个模型对象实例。
- 最佳实践
模型查询的最佳实践原则是:
在模型外部使用静态方法进行查询,
内部使用动态方法查询,包括使用数据库的查询构造器。