CNN LeNet-5 AlexNet VGG简介
1.LeNet-5
LeNet与94年提出,是最早的CNN结构之一,由Lecun, Bengio等大神共同提出。
而LeNet5则是Yann Lecun等大神在经过多次研究后提出的网络结构,现在一般提到的LeNet就是指LeNet5。
先贴一张经典的LeNet5网络结构图。

从图上可以看出,LeNet-5包含5层(将卷积层与池化层看成一层,如果将卷积层与池化层区分对待则是7层),名字里的5就是由此而来。
其网络结构为:
输入,卷积层C1, 子采样层S2(subsampling/pooling),卷积层C3, 子采样层S4, 卷积层C5, 全连接层F6, 最后的输出层softmax。
LeNet5的输入是32321的灰色图片。因为不是彩色图片,所以channel的维度为1。
以卷积层C1为例,我们分析一下训练网络需要的参数
输入是3232的灰色图片,kernel size是55,步长为1,而且无填充,filter的数量是6个。
1.没有padding,生成的feature map长宽都为32-5+1=28,所以feature map的大小为2828
2.filter的参数个数为(55+1)6 = 156,其中55是kernel的尺寸,1为bias参数,6表示有6个filter。
3.最终的连接数为 1562828=122304。其中,156为filter的参数个数,28*28表示feature map的尺寸。
LeNet的网络设计较为简单,处理复杂数据的能力有限,现在已经较少在实际中使用。
2.划时代的AlexNet
AlexNet可以说在整个深度学习的发展过程中都占有非常重要的地位。2012年,AlexNet在当时的ImageNet图像分类比赛中,将top5的错误率比上年下降了十个百分点,并且最终结果远远超过了第二名。
paper是由多伦多大学的Alex Krizhevsky,Ilya Sutskever,Geoffrey E. Hinton联合发表。特意找了下paper的原文,重温一下当年划时代的经典巨作,现在将原文的Abstract粘贴一下,也就能大致了解AlexNet的核心思想。
We trained a large, deep convolutional neural network
to classify the 1.2 million high-resolution images
in the ImageNet LSVRC-2010 contest into the 1000 different classes.
On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0%
which is considerably better than the previous state-of-the-art.
The neural network,
which has 60 million parameters and 650,000 neurons,
consists of five convolutional layers, some of which are followed by max-pooling layers,
and three fully-connected layers with a final 1000-way softmax.
To make training faster,
we used non-saturating neurons and a very efficient GPU implementation of the convolution operation.
To reduce overfitting in the fully-connected layers
we employed a recently-developed regularization method called “dropout”
that proved to be very effective.
We also entered a variant of this model in the ILSVRC-2012 competition
and achieved a winning top-5 test error rate of 15.3%,
compared to 26.2% achieved by the second-best entry.
把上面的Abstract翻译一下:
1.训练了一个大型的CNN将ImageNet LSVRC-2010中的120w张高分辨率图像分成1000类。
2.top1与top5的错误率为37.5%与17.0%,效果远远超过了之前。
3.该网络又6000w个参数,65w个神经元,有5个卷积层,一些最大池化层,还有三个全连接层,最后接的是softmax层。
4.使用了relu激活函数与GPU来实现。
5.使用了dropout来控制全连接层的过拟合。
6.AlexNet在 ILSVRC-2012 比赛中top5的错误率是15.3%,第二名为26.2%。
通过上面的Abstract介绍,我们就不难看出AlexNet做出的开创性工作:
1.网络非常大。
2.训练的数据量也非常大。
3.使用了relu非线性激活函数。
4.提出了dropout防止过拟合。
5.使用GPU加速训练
再贴一张原文中的网络结构图
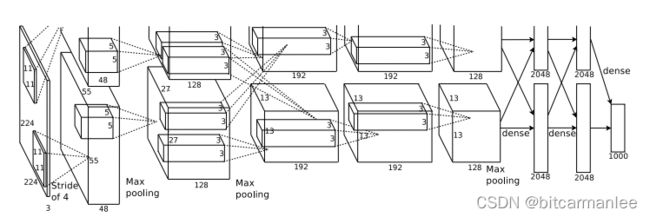
从AlexNet以后,深度学习,大规模神经网络的发展就开始进入了快车道。
3.VGG
VGG是Oxford Visual Geometry Group团队的工作,其在ILSVRC 2014上进行了运行,主要是说明增加网络的深度能够在一定程度上提升网络最终的性能。VGG有VGG16与VGG19,网络结构相差不大,主要是网络深度的不同。
同样把VGG原始paper中的Abstract贴出来
In this work we investigate the effect of the convolutional network depth on its
accuracy in the large-scale image recognition setting. Our main contribution is
a thorough evaluation of networks of increasing depth using an architecture with
very small (3×3) convolution filters, which shows that a significant improvement
on the prior-art configurations can be achieved by pushing the depth to 16–19
weight layers. These findings were the basis of our ImageNet Challenge 2014
submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations
generalise well to other datasets, where they achieve state-of-the-art results. We
have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
从上面的简介不难看出,VGG最大的特点之一就是卷积核小,使用了多个3*3较小卷积核的卷积层代替一个卷积核较大的卷积层,这样可以减少参数,同时相当于进行了更多的非线性映射,可以增加网络的学习能力。
原文中提到的网络结构如下
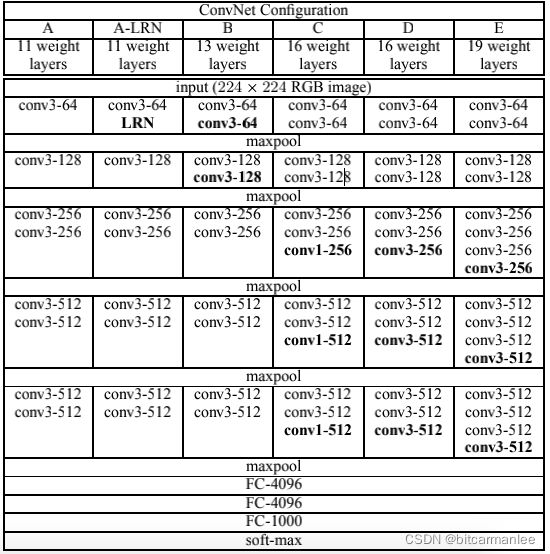
paper中分别使用了A、A-LRN、B、C、D、E这6种网络结构进行测试。而这六种网络结构相似,都是由5层卷积层、3层全连接层组成,其中区别在于每个卷积层的子层数量不同,从A至E依次增加(子层数量从1到4),总的网络深度从11层到19层,表格中的卷积层参数表示为“conv感受野大小-通道数”,例如con3-128,表示使用3x3的卷积核,通道数为128。
其中,网络D就是VGG16, 网络E是VGG19。