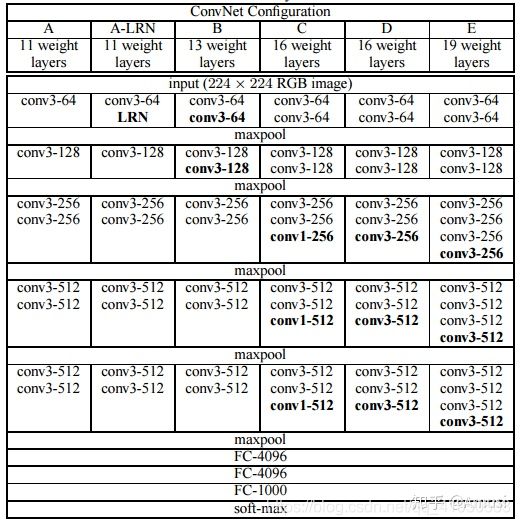
传统骨干网比较LeNet AlexNet VGG Inception
LeNet
LeNet(
(conv): Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(1): Sigmoid()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): Sigmoid()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=256, out_features=120, bias=True)
(1): Sigmoid()
(2): Linear(in_features=120, out_features=84, bias=True)
(3): Sigmoid()
(4): Linear(in_features=84, out_features=10, bias=True)
)
)
首先输入图像是单通道的28*28大小的图像,用矩阵表示就是[1,28,28]
第一个卷积层conv1所用的卷积核尺寸为5*5,滑动步长为1,卷积核数目为20,那么 经过该层后图像尺寸变为24,28-5+1=24,输出矩阵为[20,24,24]。
第一个池化层pool核尺寸为2*2,步长2,这是没有重叠的max pooling,池化操作后, 图像尺寸减半,变为12×12,输出矩阵为[20,12,12]。
第二个卷积层conv2的卷积核尺寸为5*5,步长1,卷积核数目为50,卷积后图像尺寸 变为8,这是因为12-5+1=8,输出矩阵为[50,8,8].
第二个池化层pool2核尺寸为2*2,步长2,这是没有重叠的max pooling,池化操作 后,图像尺寸减半,变为4×4,输出矩阵为[50,4,4]。
pool2后面接全连接层fc1,神经元数目为500,再接relu激活函数。
再接fc2,神经元个数为10,得到10维的特征向量,用于10个数字的分类训练,送入 softmaxt分类,得到分类结果的概率output。

AlexNet
AlexNet(
(conv): Sequential(
(0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU()
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU()
(10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=6400, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU()
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
第一个卷积层
输入的图片大小为:224*224*3(或者是227\*227*3)
第一个卷积层为:11*11*96即尺寸为11*11,有96个卷积核,步长为4,卷积层后跟ReLU,因此输出的尺寸为 224/4=56,去掉边缘为55,因此其输出的每个feature map 为 55*55\*96,同时后面跟LRN层,尺寸不变.
最大池化层,核大小为3*3,步长为2,因此feature map的大小为:27*27*96.
第二层卷积层
输入的tensor为27*27*96
卷积和的大小为: 5*5*256,步长为1,尺寸不会改变,同样紧跟ReLU,和LRN层.
最大池化层,和大小为3*3,步长为2,因此feature map为:13*13*256
第三层至第五层卷积层
输入的tensor为13*13*256
第三层卷积为 3*3*384,步长为1,加上ReLU
第四层卷积为 3*3*384,步长为1,加上ReLU
第五层卷积为 3*3*256,步长为1,加上ReLU
第五层后跟最大池化层,核大小3*3,步长为2,因此feature map:6*6*256
第六层至第八层全连接层
FC : 4096 + ReLU
FC:4096 + ReLU
FC: 1000 最后一层为softmax为1000类的概率值.
AlexNet在LeNet的基础上增加了3个卷积层

VGG
Sequential(
(vgg_block_1): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_2): Sequential(
(0): Conv2d(8, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_3): Sequential(
(0): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_4): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(vgg_block_5): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): FlattenLayer()
(1): Linear(in_features=3136, out_features=512, bias=True)
(2): ReLU()
(3): Dropout(p=0.5)
(4): Linear(in_features=512, out_features=512, bias=True)
(5): ReLU()
(6): Dropout(p=0.5)
(7): Linear(in_features=512, out_features=10, bias=True)
)
)
确实前面层的尺寸大,能够获得更大的感受野,从而为后面层提供更多信息,但是核越大就意味着计算量越大,所以,有可能这还不如取较小的核,而多加几层。
VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
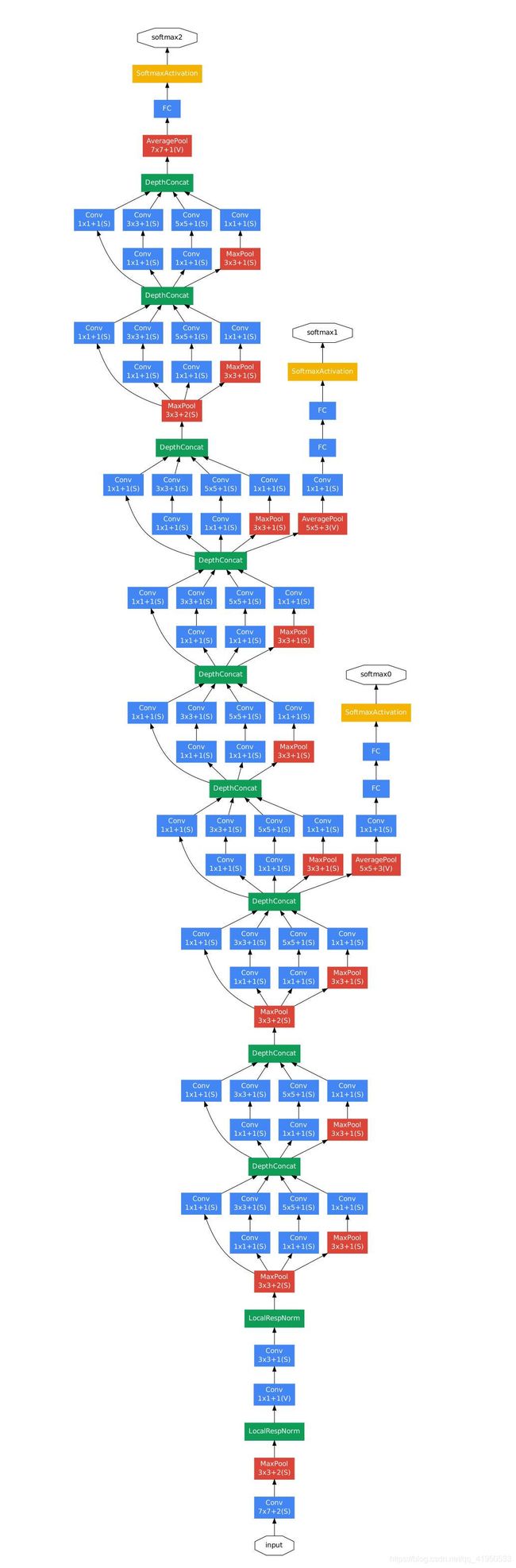
inception v1(GoogleNet)
和ResNet一样,构造了一个船新的结构:Inception结构:首先通过1x1卷积来降低通道数把信息聚集一下,再进行不同尺度的特征提取以及池化,得到多个尺度的信息,最后将特征进行叠加输出。之前的网络目的是把网络变得更深,谷歌网络出来之后又有了一个新的方向,要把网络变得更宽
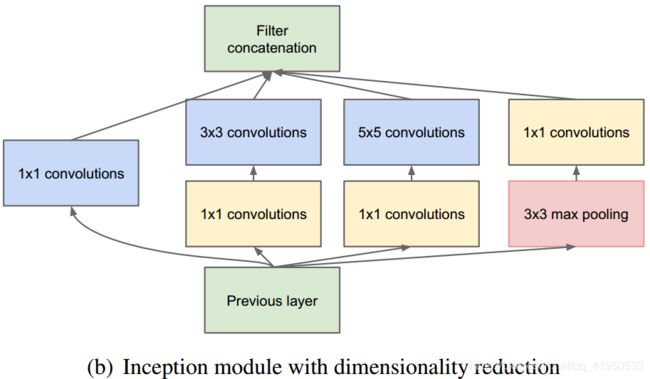
相应的在3x3卷积和5x5卷积前面、3x3池化后面添加1x1卷积,将信息聚集且可以有效减少参数量(称为瓶颈层也是类似于resnet里面的概念);
谷歌网络还有一个特点就是辅助分类器,它可以在反向传播的时候防止梯度消失或者爆炸
inception v2
用多个小尺寸卷积核替换大尺寸卷积核
