Python自动化办公小程序:实现报表自动化和自动发送到目的邮箱
项目背景
作为数据分析师,我们需要经常制作统计分析图表。但是报表太多的时候往往需要花费我们大部分时间去制作报表。这耽误了我们利用大量的时间去进行数据分析。但是作为数据分析师我们应该尽可能去挖掘表格图表数据背后隐藏关联信息,而不是简单的统计表格制作图表再发送报表。既然报表的工作不可免除,那我们应该如何利用我们所学的技术去更好的处理工作呢?这就需要我们制作一个Python小程序让它自己去实现,这样我们就有更多的时间去做数据分析。我们把让程序自己运行的这个过程称为自动化。
一、报表自动化目的
1.节省时间,提高效率
自动化总是能够很好的节省时间,提高我们的工作效率。让我们的程序编程尽可能的降低每个功能实现代码的耦合性,更好的维护代码。这样我们会节省很多时间让我们有空去做更多有价值有意义的工作。
2.减少错误
编码实现效果正确无误的话是是可以一直沿用的,如果是人为来操作的话反而可能会犯一些错误。交给固定的程序来做更加让人放心,需求变更时仅修改部分代码即可解决问题。
二、报表自动化范围
首先我们需要根据业务需求来制定我们所需要的报表,并不是每个报表都需要进行自动化的,一些复杂二次开发的指标数据要实现自动化编程的比较复杂的,而且可能会隐藏着各种BUG。所以我们需要对我们工作所要用到的报表的特性进行归纳,以下是我们需要综合考虑的几个方面:
1.频率
对于一些业务上经常需要用到的表,这些表我们可能要纳入自动化程序的范围。例如客户信息清单、销售额流量报表、业务流失报表、环比同比报表等。


这些使用频率较高的报表,都很有必要进行自动化。对于那些偶尔需要使用的报表,或者是二次开发指标,需要复制统计的报表,这些报表就没必要实现自动化了。
2.开发时间
这就相当于成本和利率一样,若是有些报表自动化实现困难,还超过了我们普通统计分析所需要的时间,就没必要去实现自动化。所以开始自动化工作的时候要衡量一下开发脚本所耗费的时间和人工做表所耗费的时间哪个更短了。当然我会提供一套实现方案,但是仅对一些常用简单的报表。
3.流程
对于我们报表每个过程和步骤,每个公司都有所不同,我们需要根据业务场景去编码实现各个步骤功能。所以我们制作的流程应该是符合业务逻辑的,制作的程序也应该是符合逻辑的。

三、实现步骤
首先我们需要知道我们需要什么指标;在上期数据分析基础文章一文速览-数据分析基础以及常规流程有解释,这里再列出来:
- 指标
- 总体概览指标
反映某一数据指标的整体大小
- 对比性指标
- 同比
相邻时间段内某一共同时间点上指标的对比
- 环比
相邻时间段内的指标直接作差
- 同比
- 集中趋势指标
- 平均数/加权平均数
- 众数
- 中位数
- 离散程度指标
- 全距(极差)
最大界减最小界
- 四分位数
- 方差
- 标准差
- 全距(极差)
- 相关性指标
- r
- 总体概览指标

我们拿一个简单的报表来进行模拟实现:
第一步:读取数据源文件
首先我们要了解我们的数据是从哪里来的,也就是数据源。我们最终的数据处理都是转化为DataFrame来进行分析的,所以需要对数据源进行转化为DataFrame形式:
import pandas as pd
import json
import pymysql
from sqlalchemy import create_engine
# 打开数据库连接
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='xxxx',
charset = 'utf8'
)
engine=create_engine('mysql+pymysql://root:xxxx@localhost/mysql?charset=utf8')
def read_excel(file):
df_excel=pd.read_excel(file)
return df_excel
def read_json(file):
with open(file,'r')as json_f:
df_json=pd.read_json(json_f)
return df_json
def read_sql(table):
sql_cmd ='SELECT * FROM %s'%table
df_sql=pd.read_sql(sql_cmd,engine)
return df_sql
def read_csv(file):
df_csv=pd.read_csv(file)
return df_csv以上代码均通过测试可以正常使用,但是pandas的read函数针对不同的形式的文件读取,其read函数参数也有不同的含义,需要直接根据表格的形式来调整,想要更详细的完善这一步的可以去看看我的两篇关于read函数的文章:
Pandas中read_excel函数参数使用详解+实例代码
Pandas处理JSON文件read_json()一文详解+代码展示
其他read函数将会在文章写完之后后续补上,除了read_sql需要连接数据库之外,其他的都是比较简单的。
第二步:DataFrame计算
我们以用户信息为例:

我们需要统计的指标为:
#指标说明
单表图:
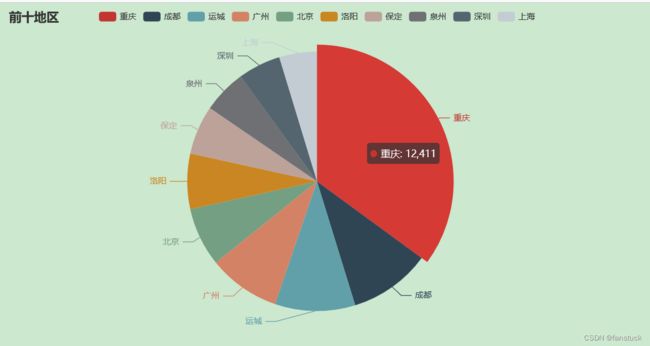
前十个产品受众最多的地区
产品的受众地区:
#将城市空值的一行删除
df=df[df['city_num'].notna()]
#删除error
df=df.drop(df[df['city_num']=='error'].index)
#统计
df = df.city_num.value_counts()
我们仅获取前10名的城市就好了,封装为饼图:
def pie_chart(df):
#将城市空值的一行删除
df=df[df['city_num'].notna()]
#删除error
df=df.drop(df[df['city_num']=='error'].index)
#统计
df = df.city_num.value_counts()
df.head(10).plot.pie(subplots=True,figsize=(5, 6),autopct='%.2f%%',radius = 1.2,startangle = 250,legend=False)
pie_chart(read_csv('user_info.csv')) 
将图表保存起来:
plt.savefig('fig_cat.png')要是你觉得matplotlib的图片不太美观的话,你也可以换成echarts的图片,会更加好看一些:
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
pie.render_notebook()
封装后就可以直接使用了:
def echart_pie(user_df):
user_df=user_df[user_df['city_num'].notna()]
user_df=user_df.drop(user_df[user_df['city_num']=='error'].index)
user_df = user_df.city_num.value_counts()
name=user_df.head(10).index.tolist()
value=user_df.head(10).values.tolist()
words=list(zip(list(name),list(value)))
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
return pie.render_notebook()
user_df=read_csv('user_info.csv')
echart_pie(user_df)可以进行保存,可惜不是动图:
from snapshot_selenium import snapshot
make_snapshot(snapshot,echart_pie(user_df).render(),"test.png")保存为网页的形式就可以自动加载JS进行渲染了:
echart_pie(user_df).render('problem.html')
os.system('problem.html')
第三步:自动发送邮件
做出来的一系列报表一般都要发给别人看的,对于一些每天需要发送到指定邮箱或者需要发送多封报表的可以使用Python来自动发送邮箱。
在Python发送邮件主要借助到smtplib和email这个两个模块。
smtplib:主要用来建立和断开与服务器连接的工作。
email:主要用来设置一些些与邮件本身相关的内容。
不同种类的邮箱服务器连接地址不一样,大家根据自己平常使用的邮箱设置相应的服务器进行连接。这里博主用网易邮箱展示:
首先需要开启POP3/SMTP/IMAP服务:

之后便可以根据授权码使用python登入了。
import smtplib
from email import encoders
from email.header import Header
from email.utils import parseaddr,formataddr
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
#发件人邮箱
asender="[email protected]"
#收件人邮箱
areceiver="[email protected]"
#抄送人邮箱
acc="[email protected]"
#邮箱主题
asubject="谢谢关注"
#发件人地址
from_addr="[email protected]"
#邮箱授权码
password="####"
#邮件设置
msg=MIMEMultipart()
msg['Subject']=asubject
msg['to']=areceiver
msg['Cc']=acc
msg['from']="fanstuck"
#邮件正文
body="你好,欢迎关注fanstuck,您的关注就是我继续创作的动力!"
msg.attach(MIMEText(body,'plain','utf-8'))
#添加附件
htmlFile = 'C:/Users/10799/problem.html'
html = MIMEApplication(open(htmlFile , 'rb').read())
html.add_header('Content-Disposition', 'attachment', filename='html')
msg.attach(html)
#设置邮箱服务器地址和接口
smtp_server="smtp.163.com"
server = smtplib.SMTP(smtp_server,25)
server.set_debuglevel(1)
#登录邮箱
server.login(from_addr,password)
#发生邮箱
server.sendmail(from_addr,areceiver.split(',')+acc.split(','),msg.as_string())
#断开服务器连接
server.quit()运行测试:

下载文件:
 完全没问题
完全没问题
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见
参阅:
浅谈几种常用的报表
Python数据分析