pytorch系统学习
经过网络后的输出图片形状的计算公式:
- 第一种情况:如果stride值为0的话,输入形状是n_h x n_w,卷积核窗口是k_h x k_w,那么输出形状是(n_h - k_h +1) x (n_w - k_w +1)。如果这时有p_h值的话,那么公式就是(n_h - k_h +2×p_h+1) x (n_w - k_w+2 * p_w +1)。
- 第二种情况:如果stride值不为0的话,下面的计算公式中如果有padding=(2,2)的话,那么p_h=p_w=4,因为对于w而言,是左边增加padding值2且右边对称位置也是增加padding值2,所以总的p_w=4。当在高上步幅为s_h时,在宽上步幅为s_w时,输出形状为:[floor(n_h - k_h + p_h +s_h )/ s_h] x [floor(n_w - k_w + p_w + s_w)/s_w](floor表示向下取整)
- 小tip:如果步幅为s,填充为s/2,假设s/2为整数,卷积核的高和宽为2s,转置卷积核将输入的高和宽分别放大s倍。
自定义层
- 使用Module自定义层,从而可以被重复调用。
不含有模型参数的自定义层
- 下面例子中,CenteredLayer类通过继承Module类自定义了一个将输入减掉均值后输出的层,并且将层的计算定义在了forward函数里面,这个层里不含有模型参数。
import torch
import torchvision
from torchvision import models
from torch import nn
class CenteredLayer(nn.Module):
def __init__(self,**kwargs):
super(CenteredLayer,self).__init__(**kwargs)
def forward(self,x):
return x - x.mean()
- 第二步,实例化这个层,然后做前向计算。
layer = CenteredLayer()
layer(torch.tensor([1,2,3,4,5],dtype=torch.float))
- 第三步,用它来构造更复杂的模型。
net = nn.Sequential(nn.Linear(8,128),CenteredLayer())
- 第四步,打印自定义层各个输出的均值,因为均值是浮点型,所以它的值是一个很接近0的数值。
y = net(torch.rand(4,8))
y.mean().item()
含模型参数的自定义层
- 可以自定义含有模型参数的自定义层,其中模型参数是可以通过训练来学到的。
- Parameter类是Tensor的子类,如果一个Tensor是Parameter,那么它会自动被添加到模型的参数列表里,所以在自定义含有参数模型的层时,应该将参数定义为Parameter。除了直接定义成Parameter类外,还可以使用ParameterList和ParameterDict分别定义参数的列表和字典。
- ParameterList接收一个Parameter实例的列表作为输入,然后得到一个参数列表,使用的时候可以用索引来访问某个参数,另外也可以使用append和extend在列表后面新增参数。
class MyDense(nn.Module):
def __init__(self):
super(MyDense,self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(4,4)) for i in range(3)])
self.params.append(nn.Parameter(torch.randn(4,1)))
def forward(self,x):
for i in range(len(self.params)):
x = torch.mm(x,self.params[i])
return x
net = MyDense()
print(net)
- ParameterDict接收一个Parameter实例的字典作为输入然后得到一个参数字典,然后可以按照字典的规则使用。使用update()新增参数,使用keys()返回所有键值,使用items()返回所有键值对等。
class MyDictDense(nn.Module):
def __init__(self):
super(MyDictDense,self).__init__()
self.params = nn.ParameterDict({
'linear1':nn.Parameter(torvh.randn(4,4)),
'linear2':nn.Parameter(torch.randn(4,1))
})
self.params.update({'linear3':nn.Parameter(torch.randn(4,2))})
def forward(self,x,choice='linear1'):
return torch.mm(x,self.params[choice])
net = MyDictDense()
print(net)
- 然后就可以利用传入的键值来进行不同的前向传播。
x = torch.ones(1,4)
print(net(x,'linear1'))
print(net(x,'linear2'))
print(net(x,'linear3'))
- 也可以使用自定义层构造模型,和pytorch的其他层在使用上是一样的。
net = nn.Sequential(
MyDictDense(),
MyDense(),
)
print(net)
print(net(x))
读取和存储
- 需要把训练好的模型部署到很多不同的设备。这时可以把内存中训练好的模型参数存储在硬盘上供后续使用。
读写Tensor
- 可以直接使用save函数和load函数分别存储和读取Tensor,save使用python的pickle实用程序将对象序列化,然后将序列化的对象保存到disk。使用save可以保存各种对象,包括模型、张量和字典等。而load使用pickle unpickle工具将pickle的对象文件反序列化为内存。
- 下面的例子创建了Tensor变量x,并且将它存储在x.pt文件里面。
x=torch.ones(3)
torch.save(x,'x.pt')
- 第二步将数据从存储的文件读回内存。
x2 = torch.load('x.pt')
print(x2)
state_dict
- Module的可学习参数,即权重和偏差,通过model.parameters()访问,state_dict是一个从参数名称影射到参数Tensor的字典对象。
class MLP(nn.Module):
def __init__(self):
super(MLP,self).__init__()
self.hidden = nn.Linear(3,2)
self.act = nn.ReLU()
self.output = nn.Linear(2,1)
def forward(self,x):
a = self.act(self.hidden(x))
return self.output(a)
net = MLP()
net.state_dict()
- 只有具有可学习参数的层,如卷积层、线性层等才有state_dict中的条目,优化器optim也有一个state_dict,其中包含优化器状态以及所使用到的超参数的信息。
optimizer = torch.optim.SGD(net.parameters(),lr=0.001,momentum=0.9)
optimizer.state_dict()
保存和加载模型
- pytorch中保存和加载训练模型有两种方式:
- 方式一:仅仅保存和加载模型参数state_dict
- 方式二:保存和加载整个模型
方式一:保存和加载state_dict
保存:
torch.save(model.state_dict(),PATH)#推荐的文件后缀是pt或者pth
加载
model = TheModelClass(*args,**kwargs)
model.load_state_dict(torch.load(PATH))
保存和加载整个模型
保存
torch.save(model,PATH)
加载
model = torch.load(PATH)
总结
- 利用save和load函数可以很方便的读写Tensor
- 通过save函数和load_state_dict函数可以方便读写模型的参数。
GPU计算
- 通过nvidia-smi命令查看显卡信息。
- 默认下,pytorch会将数据创建在内存,然后利用cpu来计算。
- 使用.cuda()可以将CPU上的Tensor转换(复制)到GPU上,用.cuda(i)来表示第i块GPU及相应的显存。
- 用Tensor的.device属性来查看该Tensor所在的设备。
- 如果是对在GPU上的数据进行计算,那么结果还是存放在GPU上。
- 存储在不同位置上的数据是不可以直接计算的,即存放在CPU上的数据不可以直接与存放在GPU上的数据运算,位于不同GPU上的数据也是不能直接计算的。
- 和Tensor类似,模型也是可以通过.cuda转换到GPU上。
- 而且也是要保证模型输入的Tensor和模型都在同一个设备上。
二维卷积层
- 虽然卷积层得名于卷积运算,但是在卷积层中使用更加直观的互相关运算,二维卷积层中,一个二维输入数组和一个二维核数组通过互相关运算输出一个二维数组。
- 二维互相关运算:卷积窗口从输入数组的最左上方开始,按照从左往右、从上往下的顺序,依次在输入数组上滑动,当卷积窗口滑动到某一位置时,窗口中的输入子数组与核数组按照元素相乘并且求和,得到输出数组中相应位置的元素。
- 二维卷积层将输入和卷积核做互相关运算,并且加上一个标量偏差得到输出,卷积层的模型参数包括了卷积核和偏差。在训练模型的时候,通常先对卷积核随机初始化,然后不断迭代卷积核和偏差。
- 下面是一个卷积层的简单应用,检测图像中物体的边缘,即找到像素变化的位置。
- 第一步:首先构造一张高为6像素和宽为8像素的图像。图像的中间4列是黑(值为0),其余为白(值为1)。
x = torch.ones(6,8)
x[:,2:6] = 0#表示所有行,第2列到第五列,不包括第6列
print(x)
- 第二步:构造一个高和宽为1和2的卷积核K。当它与输入做互相关运算。
k = torch.tensor([[1,-1]])#所以是1行2列
- 第三步:将输入x和设计的卷积核k做互相关运算,将从白到黑的边缘和从黑到白的边缘分别检测为了1和-1,其余部分的输出为0
x = torch.ones(6,8)
x[:,2:6] = 0
# print(x)
k = torch.tensor([[1,-1]],dtype=torch.float)
def corr2d(x,k):
h,w = k.shape
y = torch.zeros((x.shape[0]-h+1,x.shape[1]-w+1))
for i in range(y.shape[0]):
for j in range(y.shape[1]):
y[i,j]=(x[i:i+h,j:j+w]*k).sum()
return y
y = corr2d(x,k)
print(y)
- 由上面这个卷积核的简单应用例子可以看出:卷积层可以通过重复使用卷积核有效的表征局部空间。
- 下面再举一个例子,是通过数据来学习核数组。它使用物体边缘检测中的输入数据x和输出数据y来学习我们构造的核数组k。
- 第一步:首先构造一个卷积层,其卷积核将被初始化成随机数组。接下来在每一次迭代中,使用平方误差来比较y和卷积层的输出,计算梯度来更新权重。
- 在进行第一步之前补充的一个准备操作:基于corr2d函数来实现一个自定义的二维卷积层。在构造函数__init__里,声明weight和bias两个模型参数。前向计算函数forward则直接调用corr2d函数再加上偏差。
#补充操作里的实现代码
class Conv2D(nn.Module):
def __init__(self,kernel_size):
super(Conv2D,self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self,x):
return corr2d(x,self.weight)+self.bias
#下面是第一步操作中的实现代码
#构造一个核数组形状是(1,2)的二维卷积层
conv2D = Conv2D(kernel_size=(1,2))
step = 20
lr = 0.01
for i in range(step):
y_hat = conv2D(x)
l = ((y_hat-y)**2).sum()
l.backward()
#梯度下降
conv2D.weight.data -= lr*conv2D.weight.grad
conv2D.bias.data -= lr*conv2D.bias.grad
#梯度清零
conv2D.weight.grad.fill_(0)
conv2D.bias.grad.fill_(0)
if (i+1)%5 == 0:
print('Step %d,loss %.3f' %(i+1,l.item()))
- 第二步:看一下学习到的卷积核的参数
print('weight:',conv2D.weight.data)
print('bias:',conv2D.bias.data)
- 可以看到学习到的卷积核的权重参数与之前在第一个例子识别图像边缘例子中定义的核数组k很接近,学习到的偏置参数接近0。
互相关运算与卷积运算
- 卷积运算与互相关运算类似,为了得到卷积运算的输出,只需要将核数组左右翻转并且上下翻转。再与输入数组做互相关运算。
- 深度学习中,核数组都是学习出来的,卷积层无论使用互相关运算或者是卷积运算都不影响模型预测时的输出。所以卷积层能使用互相关运算替代卷积运算。
特征图与感受野
- 二维卷积层输出的二维数组可以看做是输入在空间维度(宽和高)上某一级的表征,也叫特征图。
- 影响元素x的前向计算的所有可能输入区域(可能大于输入的实际尺寸)叫做x的感受野。
- 可以通过更深的卷积神经网络使得特征图中单个元素的感受野变得广阔,从而捕捉输入上更大尺寸的特征。
填充和歩幅
- 之前讲的例子中利用3x3的输入图片和2x2的卷积核得到了2x2的输出。
- 规律是:输入形状是n_h x n_w,卷积核窗口是k_h x k_w,那么输出形状是(n_h - k_h +1) x (n_w - k_w +1)。
- 填充padding指的是在高和宽的两侧填充元素,一般是元素0。
- 一般情况下设置p_h=k_h -1和p_w = k_w -1来使得输入和输出具有相同的高和宽。这样会方便在构造网络时推测每个层的输出形状。
- 卷积神经网络经常使用奇数高宽的卷积核,如1/3/5/7等。
- 如果卷积核在输入图像上滑动时,如果输入图像的元素无法填满窗口,那么是没有结果输出的。
- 规律:下面的计算公式中如果有padding=(2,2)的话,那么p_h=p_w=4,因为对于w而言,是左边增加padding值2且右边对称位置也是增加padding值2,所以总的p_w=4。当在高上步幅为s_h时,在宽上步幅为s_w时,输出形状为:[floor(n_h - k_h + p_h +s_h )/ s_h] x [floor(n_w - k_w + p_w + s_w)/s_w],上面的规律公式中,如果有:输入图像的高和宽能分别被高和宽上的步幅整除的话,且有p_h = k_h -1和p_w = k_w -1,那么输出形状是(n_h/s_h) x (n_w/s_w)。
- 上面公式中的n_h表示输入图片的高,k_h表示卷积核的高,p表示picture,k表示kernel。p_h表示在高上的填充padding值。s_h表示在高上的步幅值。
- 填充可以增加输出的高和宽,这常用来使得输出与输入具有相同的高和宽。
- 步幅可以减小输出的高和宽,例如输出的高和宽仅仅为输入的高和宽的1/n,n为大于1的整数。
多输入通道和多输出通道
- 彩色图像在高和宽2个维度外还有RGB 3个颜色通道。所以彩色图片可以表示成3 x h x w的多维数组。将值为3的这一维称为通道维。
- 当输入数据含有多通道时,需要构造一个输入通道数与输入数据相同的卷积核,从而能够与含有多通道的输入数据做互相关运算。
- 由于输入图像和卷积核都有c_i个通道,c表示channel。可以在各个通道上对输入的二维数组和卷积核的二维核数组做互相关运算。再将这c_i个互相关运算的二维输出按照通道相加,得到一个二维数组,即为含有多个通道的输入数据与多输入通道的卷积核做二维互相关运算的输出。
- 当输入通道有多个时,因为对各个通道的结果做了累加,所以不论输入通道数是多少,输出通道数总是1。
- 对于多输出通道,其中第一个通道的结果与之前输入数组x与多输入通道、单输出通道核的计算结果一致。
- 如果希望得到含有多个通道的输出,那么为每个输出通道分别创建核数组,将它们在输出通道维上联结。在做互相关运算时,每个输出通道上的结果由卷积核在该输出通道上的核数组与整个输入数组计算而来。
1 x 1卷积核
- 窗口形状为1x1的多通道卷积层,称为1x1卷积层。因为使用了最小窗口,1x1卷积失去了卷积层可以识别高和宽维度上相邻元素构成的模式的功能。1x1卷积的主要计算发生在通道维上。输入和输出具有相同的高和宽,输出中的每个元素来自输入中在高和宽上相同位置的元素在不同通道间的按权重累加。假设将通道维当做特征维,将高和宽维度上的元素当做数据样本,那么1x1卷积层的作用与全连接层等价。
- 在很多模型里将1x1卷积层当做保持高和宽维度形状不变的全连接层使用,可以通过调整网络层间的通道数来控制模复杂度。也就是说1x1卷积层通常用来调整网络层之间的通道数,并且控制模型的复杂度。
- 使用多通道可以扩展卷积层的模型参数。
池化层
- 在二维卷积层里介绍的图像物体边缘检测应用中,构造卷积核从而精确地找到了像素变化的位置。设任意二维数组x的i行j列的元素为X[i,j],如果构造的卷积核输出Y[i,j]=1,那么说明输出中X[i,j]和X[i,j+1]数值不一样。也就是可能意味着物体边缘通过这两个元素之间,但是实际图像里,感兴趣的物体不会总是出现在固定位置上,即使连续拍摄同一个物体也极有可能出现像素位置上的偏移。这就会导致同一个边缘对应的输出可能出现在卷积输出Y中的不同位置,进而对后面的模式识别造成不便。
- 池化层pooling的作用就是为了缓解卷积层对位置的过度敏感性。
- 二维最大池化层和平均池化层。同卷积层一样,池化层对输入数据的一个固定窗口中的元素计算输出,不同于卷积层里计算输入和核的互相关性,池化层直接计算池化窗口内元素的最大值或者平均值。
- 再次回到上面提到的例子,将卷积层的输出作为2x2最大池化层的输入,设该卷积层输入是X,池化层输出为Y,无论是X[i,j]和X[i,j+1]值不同,还是X[i,j+1]和X[i,j+2]值不同,池化层输出均有Y[i,j]=1,也就是说,使用2x2最大池化层时,只要卷积层识别的模式在高和宽上移动不超过一个元素,依然可以将它检测出来。
- 同卷积层一样,池化层也可以在输入的高和宽两侧的填充并调整窗口的移动步幅来改变输出形状。
- 在处理多通道输入数据时,池化层对每个通道分别池化,而不是像卷积层那样将各通道的输入按照通道相加,这意味着池化层的输出通道数与输入通道数一样。
卷积神经网络LeNet
- 一个简单的例子:构造一个含有单隐藏层的多层感知机模型对数据集中的图像分类,每张图像高和宽都是28像素,将图像中的像素逐行进行展开,得到长度为784的向量,并且输入到全连接层,但是这种分类方法具有局限性。
(1)局限性一:图像在同一列邻近的像素在这个向量中可能相距较远,它们构成的模式可能难以被模型识别。
(2)局限二:对于大尺寸的输入图像,使用全连接层容易造成模型过大。 - 对于上面的两个局限性,卷积层尝试解决这两个问题,一方面,卷积层保留输入形状,使得图像的像素在高和宽两个方向上的相关性均可以被有效识别。另一方面,卷积层通过滑动窗口将同一卷积核与不同位置的输入重复计算,从而避免参数尺寸过大。
- LeNet是最早期的卷积神经网络,LeNet分为卷积层块和全连接层块两部分。
- 卷积层块的基本单位是卷积层后接最大池化层,卷积层用来识别图像里的空间模式,如线条和物体局部,之后的最大池化层则用来降低卷积层对位置的敏感性。卷积层块由两个这样的基本单位重复堆叠形成。
- 在卷积层块中,每个卷积都使用5x5的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道是6个。第二个卷积层输出通道数是16个。
- 这是因为第二个卷积层比第一个卷积层的输入的高和宽要小,所以增加输出通道使得两个卷积层的参数尺寸类似。
- 卷积层块的两个最大池化层的窗口形状均为2x2,且步幅为2,由于池化窗口与步幅形状相同,池化窗口在输入上每次滑动所覆盖的区域并不重叠。
- 卷积层块的输出形状为×批量大小,通道,高,宽)。当卷积层块的输出传入全连接层块时,全连接层块会将小批量中每个样本变平。即全连接层的输入形状会变成二维,其中第一维是小批量中的样本,第二维是每个样本变平后的向量表示,且向量长度为通道、高、宽的乘积。
- 全连接层块含有3个全连接层,它们输出个数分别为120、84、10.其中10是输出的类别个数。
- 神经网络可以直接基于图像的原始像素进行分类,这种称为端到端的方法可以节省很多中间步骤。
- 使用较干净的数据集和较有效的特征甚至比机器学习模型的选择对图像分类结果影响更大。
- 输入的逐级表示由多层模型中的参数决定,而这些参数都是学习出来的。
AlexNet
- AlexNet使用了8层卷积神经网络。它首次证明了学习到的特征可以超越手工设计的特征。
- AlexNet与LeNet的设计理念很相似,但是也有显著区别。
- 区别一:与相对较小的LeNet相比,AlexNet包含8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层。下面详细介绍这些层的设计。
(1)AlexNet第一层中的卷积窗口形状是11 x 11,因为ImageNet中绝大多数图像的高和宽均比MNIST图像的高和宽大10倍以上,ImageNet图像的物体占用更多像素,所以需要更大的卷积窗口来捕获物体。
(2)第二层中的卷积窗口形状减小到5x5,之后全部采用3x3卷积核。
(3)第一、第二和第五个卷积层之后都是用了窗口形状为3x3、步幅为2的最大池化层。
(4)AlexNet使用的卷积通道数也大于LeNet中的卷积通道数数十倍。
(5)接着最后一个卷积层的是两个输出个数为4096的全连接层。这两个巨大的全连接层带来了将近1GB的模型参数。 - 区别二:AlexNet将sigmoid激活函数改成了更加简单的ReLU激活函数。原因有以下两个:
(1)原因一:ReLU激活函数的计算更加简单。例如它没有sigmoid激活函数中的求幂运算。
(2)原因二:ReLU激活函数在不同的参数初始化方法下使得模型更容易训练。这是由于当sigmoid激活函数输出接近0或者1时,这些区域的梯度几乎为0,从而造成反向传播无法继续更新部分模型参数,而ReLU激活函数在正区间的梯度恒为1。因此若模型参数初始化不当,sigmoid函数极有可能在正区间得到几乎为0的梯度,从而令模型无法得到有效训练。 - 区别三:AlexNet通过丢弃法来控制全连接层的模型复杂度,而LeNet没有使用丢弃法。
- 区别四:AlexNet引入了大量的图像增广,如翻转、裁剪和颜色变化,从而扩大数据集来缓解过拟合。
- AlexNet网络的输入图像为224x224
- AlexNet跟LeNet结构类似,但是使用了更多的卷积层和更大的参数空间来拟合大规模数据集,AlexNet是浅层神经网络和深层神经网络的分界线。
使用重复元素的网络VGG
- AlexNet在LeNet的基础上增加了3个卷积层,但是AlexNet网络在网络的卷积窗口、输出通道数目、构造顺序上都做了调整。
- AlexNet指明了深度卷积网络可以取得较好的结果,但是没有提供简单的规则指导后来研究者如何设计新网络。
- VGG提出了可以通过重复使用简单的基础块来构建深度模型的思路。
- VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为3的卷积层后接上一个步幅为2、窗口形状为2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。
- 对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核优于采用大的卷积核,因为可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。在VGG中,使用3个3x3的卷积核来代替7x7卷积核,使用2个3x3卷积核来代替5x5卷积核,这样做的目的是在保证具有相同感受野的条件下,提升了网络的深度,一定程度上提升了神经网络的效果。
- 与AlexNet和LeNet一样,VGG网络由卷积层模块后接全连接层模块构成。
- 卷积层模块中串接数个vgg_block,其超参数由变量conv_arch定义。该变量指定了每个VGG块里卷积层个数和输入输出通道数。全连接模块和AlexNet一样。
- 下面构造一个VGG网络,有5个卷积块,前2块使用单卷积层,后3块使用双卷积层。第一块的输入输出通道分别为1(因为后面要使用的Fashion-MNIST数据的通道数为1)和64,之后每次对输出通道数翻倍,直到变成512.因为这个网络使用了8个卷积层和3个全连接层,所以被叫做VGG-11。
import time
import torch
from torch import nn,optim
import sys
from d2lzh_pytorch import *
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#定义vgg块
def vgg_block(num_convs,in_channels,out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1))
else:
blk.append(nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2,stride=2))#这里会使得宽高减半
return nn.Sequential(*blk)
#构造VGG-11
conv_arch = ((1,1,64),(1,64,128),(2,128,256),(2,256,512),(2,512,512))
#经过5个vgg_block,宽高会减半5次,变成224/32=7
fc_features = 512*7*7 #c*w*h
fc_hidden_units = 4096#取任意值
#实现VGG-11
def vgg(conv_arch,fc_features,fc_hidden_units=4096):
net = nn.Sequential()
#卷积层部分
for i,(num_convs,in_channels,out_channels) in enumerate(conv_arch):
#每经过一个vgg_block都会使得宽高减半
net.add_module('vgg_block_'+str(i+1),vgg_block(num_convs,in_channels,out_channels))
#全连接层部分
net.add_module('fc',nn.Sequential(d2l.FlattenLayer(),
nn.Linear(fc_features,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units,fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_ubits,10)
))
return net
#下面构造一个高宽都是224的单通道数据样本来观察每一层的输出形状
net = vgg(conv_arch,fc_features,fc_hidden_units)
X = torch.rand(1,1,224,224)
#named_children获取一级子模块及其名字,names_modules会返回所有子模块,包括子模块的子模块
for name,blk in net.named_children():
X = blk()
print(name,'output shape:',X.shape)
'''
输出结果如下:
vgg_block_1 output shape:torch.Size([1,64,112,112])
vgg_block_2 output shape:torch.Size([1,128,56,56])
vgg_block_3 output shape:torch.Size([1,256,28,28])
vgg_block_5 output shape:torch.Size([1,512,7,7])
fc output shape:torch.Size([1,10])
每次将输入的高和宽减半,直到最终高和宽变成7后传入全连接层。
与此同时,输出通道数每次翻倍,直到变成512.因为每个卷积层的窗口大小一样。
所以每层的模型参数尺寸和计算复杂度与输入高、输入宽、输入通道数和输出通道数的乘积成正比。
VGG这种高和宽减半以及通道翻倍的设计使得多数卷积层都有相同的模型参数尺寸和计算复杂度。
'''
网络中的网络NiN
- LeNet AlexNet VGG在设计上的共同之处在于:先是以卷积层构成的模块充分抽取空间特征,再以全连接层构成的模块来输出分类结果。
- AlexNet和VGG对LeNet的改进在于如何对这两个模块加宽(增加通道数)和加深。
- NiN提出另一种思路:即串联多个由卷积层和全连接层构成的小网络来构建一个深层网络。
- 卷积层的输入和输出通常是四位数组 (样本数目、通道数目、高、宽 ),而全连接层的输入和输出通常是二维数组(样本数目、特征数目)。
- 如果要在全连接层后接上卷积层,那么需要将全连接层的输出变化成四维。
- 1x1卷积层可以看成全连接层,其中空间维度(高和宽)上的每个元素相当于样本,通道相当于特征。因此NiN使用1x1卷积层来替代全连接层,从而使得空间信息能自然地传递到后面的层中。
- NiN块是NiN中的基础块,它由一个卷积层加两个充当全连接层的1x1卷积层串联而成。其中第一个卷积层的超参数可以自行设置,第二和第三个卷积层的超参数一般是固定的。
import time
import torch
from torch import nn,optim
import sys
from d2lzh_pytorch import *
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def nin_block(in_channels,out_channels,kernel_size,stride,padding):
blk = nn.Sequential(nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_szie=1),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU())
return blk
- NiN与AlexNet的卷积层设定有类似的地方:NiN使用卷积窗口形状分别为11x11和5x5和3x3的卷积层,相应的输出通道数也与AlexNet中的一致。每个NiN块后接一个步幅为2、窗口形状为3x3的最大池化层。
- 除了使用NiN块以后,NiN还有一个设计与AlexNet显著不同:NiN去掉AlexNet最后的3个全连接层,取而代之的是NiN使用输出通道数等于标签类别数的NiN块,然后使用全局平均池化层对每个通道中所有元素平均并直接用于分类。这里的全局平均池化层即窗口形状等于输入空间维形状的平均池化层。NiN的这个设计的好处是可以显著减小模型参数尺寸,从而缓解过拟合。但是这个设计有时会造成获得有效模型的训练时间增加。
import time
import torch
from torch import nn,optim
import sys
from d2lzh_pytorch import *
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def nin_block(in_channels,out_channels,kernel_size,stride,padding):
blk = nn.Sequential(nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_szie=1),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU())
return blk
class GloabalAvgPool2d(nn.Module):
#全局平均池化层可以通过将池化窗口形状设置为输入的高或者宽来实现
def __init__(self):
super(GlobalAvgPool2d,self).__init__()
def forward(self,x):
return F.avg_pool2d(x,kernel_size=x.size()[2:])
net = nn.SEquential(
nin_block(1,96,kernel_size=11,stride=4,padding=0),
nn.MaxPool2d(kernel_size=3,stride=2),
nin_block(96,256,kernel_size=5,stride=1,padding=2),
nn.MaxPool2d(kernel_size=3,stride=2),
nin_block(256,384,kernel_size=3,stride=1,padding=1),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Dropout(0.5),
#标签类别数是10
nin_block(384,10,kernel_size=3,stride=1,padding=1),
GlobalAvgPool2d(),
#将四维的输出转成二维的输出,其形状是(批量大小,10)
d2l.FlattenLayer()
)
#构建一个数据样本来查看每一层的输出形状
X = torch.rand(1,1,224,224)
for name,blk in net.named_children():
X = blk(X)
print(name,'output shape:',X.shape)
'''
输出结果是:
0 output shape:torch.Size([1,96,54,54])
1 output shape:torch.Size([1,96,26,26])
2 output shape:torch.Size([1,256,26,26])
3 output shape:torch.Size([1,256,12,12])
4 output shape:torch.Size([1,384,12,12])
5 output shape:torch.Size([1,384,5,5])
6 output shape:torch.Size([1,384,5,5])
7 output shape:torch.Size([1,10,5,5])
8 output shape:torch.Size([1,10,1,1])
9 output shape:torch.Size([1,10])
'''
- NiN重复使用由卷积层和代替全连接层的1x1卷积层构成的NiN块来构建深层网络。
- NiN去除了容易造成过拟合的全连接输出层,而是将其替换为输出通道数等于标签类别数的NiN块和全局平均池化层。
- NiN的以上设计思想影响了后面一系列卷积神经网络的设计。
含并行联结的网络GoogLeNet
- GoogLeNet吸收了NiN中网络串联网络的思想。
- GoogLeNet中的基础卷积块叫做Inception块。Inception块里有4条并行的线路,前3条线路使用的窗口大小分别是1x1,3x3,5x5的卷积层来抽取不同空间尺寸下的信息。其中中间2个线路会对输入先做1x1卷积来减少输入通道数,以降低模型复杂度、第4条线路使用3x3最大池化层,后接1x1卷积层来改变通道数。4条线路都使用了合适的填充来使得输入与输出的高和宽一致。最后将每条线路的输出在通道维上连接,并输入到接下来的层。
- Inception块中可以自定义的超参数是每个层的输出通道数,以此来控制模型复杂度。
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
import sys
from d2lzh_pytorch import *
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Inception(nn.Module):
#c1 c2 c3 c4是每条线路里的输出通道数
def __init__(self,in_c,c1,c2,c3,c4):
super(Inception,self).__init__()
#线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_c,c1,kernel_size=1)
#线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_c,c2[0],kernrl_size=1)
self.p2_2 = nn.Conv2d(c2[0],c2[1],kernrl_size=3,padding=1)
#线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_c,c3[0],kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0],c3[1],kernel_size=5,padding=1)
#线路4,3x3最大池化层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3,stride=1,padding=1)
self.p4_2 = nn.Conv2d(in_c,c4,kernrl_size=1)
def forward(self,x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1,p2,p3,p4),dim=1)#在通道维上连结输出
- GoogLeNet和VGG一样,在主体卷积部分中使用5个模块(block)。每个模块之间使用步幅为2的3x3最大池化层来减小输出高宽。第一模块使用一个64通道的7x7卷积层。第一个模块对应Inception中的第一条线路。
b1 = nn.Sequential(nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
- 第二个模块使用2个卷积层,首先是64通道的1x1卷积层,然后是将通道增大3倍的3x3卷积层。第二个模块对应Inception块中的第二条线路。
b2 = nn.Sequential(nn.Conv2d(64,64,kernel_size=1),
nn.Conv2d(64,192,kernel_size=3,padding=1),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
- 第三模块串联2个完整的Inception块,第一个Inception块的输出通道数为64+128+32+32=256,其中4条线路的输出通道数比例为64:128:32:32=2;4:1:1,其中第2第3条线路先分别将输入通道数减小至96/192=1/2,16/192=1/12,然后再接上第2层卷积层。
- 第2个Inception模块输出通道数增加至128+192+96+64=480,每条线路的输出通道数之比为128:192:96:64=4:6:3:2,其中第2第3条线路先分别将输入通道数减小到128/256=1/2,32/256=1/8。
b3 = nn.Sequential(Inception(192,64,(96,128),(16,32),32),
Inception(256,128,(128,192),(32,96),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
- 第4模块更加复杂,它串联了5个Inception块,其输出通道数分别为192+208+48+64=512,160+224+64+64=512,128+256+64+64=512,112+288+64+64=528,256+320+128+128=832.这些线路的通道数分配和第三模块中的类似。首先含3x3卷积层的第二条线路输出最多通道,其次是仅含1x1卷积层的第一条线路输出第二多的通道数目,之后是含5x5卷积层的第三条线路和含3x3最大池化层的第四条线路输出第三多的通道数目。其中第二、第三条线路都会按比例减小通道数,这些比例在各个Inception块中都略有不同。
b4 = nn.Sequential(Inception(480,192,(96,208),(16,48),64),
Inception(512,160,(112,224),(24,64),64),
Inception(512,128,(128,256),(24,64),64),
Inception(512,112,(144,288),(32,64),64),
Inception(528,256,(160,320),(32,128),128),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1))
- 第五模块有输出通道数为256+320+128+128=832,384+384+128+128=1024的两个Inception块。其中每条线路的通道数的分配思路和第三、第四模块中的思路一致。只是在具体数值上的差异。第五模块的后面紧跟输出层,该模块同NiN一样使用全局平均池化层来将每个通道的高和宽变为1,最后将输出变为二维数组后,再接上一个输出个数为标签类别数的全连接层。
b5 = nn.Sequential(Inception(832,256,(160,320),(32,128),128),
Inception(832,384,(192,384),(48,128),128),
d2l.GlobalAvgPool2d())
net = nn.Sequential(b1,b2,b3,b4,b5,
d2l.FlattenLayer(),
nn.Linear(1024,10))
- GoogLeNet的计算复杂而且不如VGG那样便于修改通道数,所以下面将输入的高和宽从224降低到96来简化计算。下面的代码实现展示各个模块之间的输出的形状变化。
net = nn.Sequential(b1,b2,b3,b4,b5,d2l.FlattenLayer(),nn.Linear(1024,10))
X = torch.rand(1,1,96,96)
for blk in net.children():
X = blk(X)
print('output shape:',X.shape)
- Inception块相当于一个有4条线路的子网络,它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用1x1卷积层减少通道数从而降低模型复杂度。
- GoogLeNet将多个设计精细的Inception块和其他层串联起来,其中Inception块的通道数分配之比是在ImageNet数据集上通过大量实验得到的。
Sequential(
(0): Sequential(
(0): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(1): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(64, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(2): Sequential(
(0): Inception(
(p1_1): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1))
(p2_1): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1))
(p2_2): Conv2d(96, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(p3_1): Conv2d(192, 16, kernel_size=(1, 1), stride=(1, 1))
(p3_2): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(p4_1): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(p4_2): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1))
)
(1): Inception(
(p1_1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(p2_1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(p2_2): Conv2d(128, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(p3_1): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))
(p3_2): Conv2d(32, 96, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(p4_1): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(p4_2): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
)
(2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(3): Sequential(
(0): Inception(
(p1_1): Conv2d(480, 192, kernel_size=(1, 1), stride=(1, 1))
(p2_1): Conv2d(480, 96, kernel_size=(1, 1), stride=(1, 1))
(p2_2): Conv2d(96, 208, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(p3_1): Conv2d(480, 16, kernel_size=(1, 1), stride=(1, 1))
(p3_2): Conv2d(16, 48, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(p4_1): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(p4_2): Conv2d(480, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1): Inception(
(p1_1): Conv2d(512, 160, kernel_size=(1, 1), stride=(1, 1))
(p2_1): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1))
(p2_2): Conv2d(112, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(p3_1): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1))
(p3_2): Conv2d(24, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(p4_1): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(p4_2): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
)
(2): Inception(
(p1_1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(p2_1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(p2_2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(p3_1): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1))
(p3_2): Conv2d(24, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(p4_1): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(p4_2): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
)
(3): Inception(
(p1_1): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1))
(p2_1): Conv2d(512, 144, kernel_size=(1, 1), stride=(1, 1))
(p2_2): Conv2d(144, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(p3_1): Conv2d(512, 32, kernel_size=(1, 1), stride=(1, 1))
(p3_2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(p4_1): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(p4_2): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
)
(4): Inception(
(p1_1): Conv2d(528, 256, kernel_size=(1, 1), stride=(1, 1))
(p2_1): Conv2d(528, 160, kernel_size=(1, 1), stride=(1, 1))
(p2_2): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(p3_1): Conv2d(528, 32, kernel_size=(1, 1), stride=(1, 1))
(p3_2): Conv2d(32, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(p4_1): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(p4_2): Conv2d(528, 128, kernel_size=(1, 1), stride=(1, 1))
)
(5): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(4): Sequential(
(0): Inception(
(p1_1): Conv2d(832, 256, kernel_size=(1, 1), stride=(1, 1))
(p2_1): Conv2d(832, 160, kernel_size=(1, 1), stride=(1, 1))
(p2_2): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(p3_1): Conv2d(832, 32, kernel_size=(1, 1), stride=(1, 1))
(p3_2): Conv2d(32, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(p4_1): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(p4_2): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1))
)
(1): Inception(
(p1_1): Conv2d(832, 384, kernel_size=(1, 1), stride=(1, 1))
(p2_1): Conv2d(832, 192, kernel_size=(1, 1), stride=(1, 1))
(p2_2): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(p3_1): Conv2d(832, 48, kernel_size=(1, 1), stride=(1, 1))
(p3_2): Conv2d(48, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(p4_1): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(p4_2): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1))
)
(2): GlobalAvgPool2d()
)
(5): FlattenLayer()
(6): Linear(in_features=1024, out_features=10, bias=True)
)
output shape: torch.Size([1, 64, 24, 24])
output shape: torch.Size([1, 192, 12, 12])
output shape: torch.Size([1, 480, 6, 6])
output shape: torch.Size([1, 832, 3, 3])
output shape: torch.Size([1, 1024, 1, 1])
output shape: torch.Size([1, 1024])
output shape: torch.Size([1, 10])
批量归一化
- batch normalization层,能让较深的神经网络的训练变得更加容易。对输入数据进行标准化处理后,处理后的任意一个特征在数据集中所有样本上的均值为0,标准差为1,标准化处理输入数据使得各个特征的分布相近,这使得更容易训练出有效的模型。
- 数据标准化预处理对于浅层网络足够有效看,随着模型训练的进行,当每层中参数更新时,靠近输出层的输出较难出现剧烈变化,但是对于深层神经网络来说,即使输入数据已经做了标准化,训练中模型参数的更新依然很容易造成靠近输出层输出的剧烈变化,这种计算数值的不稳定性通常使得难以训练出有效的深度模型。
- 为了应对这个问题,训练模型时,批量归一化利用小批量上的均值和标准差,不断调整神经网络的中间输出,从而使得整个神经网络在各层的中间输出的数值更加稳定。
- 批量归一化和残差神经网络为训练和设计深度模型提供了两类思路。
- 对全连接层和卷积层做批量归一化的方法稍有不同。
对全连接层做批量归一化
- 将批量归一化置于全连接层中的仿射变换和激活函数之间。
对卷积层做批量归一化
- 对卷积层来说,批量归一化发生在卷积计算之后、应用激活函数之前。
- 如果卷积计算输出多个通道,需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数,并均为标量。
预测时的批量归一化
- 使用批量归一化训练时,可以将批量设置得数值大一些,从而使批量内样本的均值和方差的计算都比较准确。
- 将训练好的模型用于预测时,希望模型对于任意输入都有确定的输出。因此,单个样本的输出不应该取决于批量归一化所需要的随机小批量中的均值和方差。一种常用的方法是通过移动平均估算整个训练数据集的样本均值和方差,并且在预测时使用它们得到确定的输出。
- 所以批量归一化层和丢弃层一样,在训练模式和预测模式下的计算结果是不一样的。
从零实现批量归一化
import time
import torch
from torch import nn, optim
import torch.nn.functional as F
from d2lzh_pytorch import *
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def batch_norm(
is_training,
X,
gamma,
beta,
moving_mean,
moving_var,
eps,
momentum):
# 判断当前模式是训练模式还是预测模式
if not is_training:
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上axis=1的均值和方差,因为这里是计算axis=1上的均值和方差,
# 所以下面运算的时候都只用到了dim=0,dim=2,dim=3,因为总共四个维度。这里需要保持X的形状,
# 所以keepdim赋值为True。以便后面做广播运算
mean = X.mean(
dim=0,
keepdim=True).mean(
dim=2,
keepdim=True).mean(
dim=3,
keepdim=True)
var = ((X - mean)**2).mean(dim=0, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
# 训练模式下用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 拉伸参数和偏移参数
return Y, moving_mean, moving_var
- 下面自定义一个BatchNorm层,它保存参与求梯度和迭代的拉伸参数gamma和偏移参数beta,同时也维护平均得到的均值和方差,以便能够在预测模型时被使用。
- BatchNorm实例所需指定的num_features参数对于全连接层来说为输出个数。
- BatchNorm实例所需指定的num_features参数对于卷积层来说是输出通道数。
- BatchNorm实例所需指定的num_dims参数对于全连接层和卷积层来说分别是2和4.
class BatchNorm(nn.Module):
def __init__(self, num_features, num_dims):
super(BatchNorm, self).__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸参数和偏移参数,分别初始化为0和1
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 不参与求梯度和迭代的变量,全在内存上初始化为0
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.zeros(shape)
def forward(self, X):
# 如果X不在内存上,将moxing_mean和moving_var复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var,Module实例的training属性默认为true,调用.eval()设置为false
Y, self.moving_mean, self.moving_var = batch_norm(
self.training, X, self.gamma, self.beta, self.moving_mean, self.moving_var, eps=1e-5, momentum=0.9)
return Y
使用批量归一化层的LeNet
- 在所有的卷积层后且激活层前加入批量归一化
- 在所有的全连接层后且激活层前加入批量归一化
net = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels,out_channels,kernel_size
BatchNorm(6, num_dims=4), # 因为接在卷积层后所以BN层维数为4,第一个参数是卷积层的输出通道数
nn.Sigmoid(), # 注意,里面定义的每一层后面都加上了逗号
nn.MaxPool2d(2, 2),
# kernel_size,stride
nn.Conv2d(6, 16, 5),
BatchNorm(16, num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(2, 2),
d2l.FlattenLayer(),
nn.Linear(16 * 4 * 4, 120),
BatchNorm(120, num_dims=2),
nn.Sigmoid(),
nn.Linear(120, 84),
BatchNorm(84, num_dims=2),
nn.Sigmoid(),
nn.Linear(84, 10)
)
- 训练修改后的模型
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(
net,
train_iter,
test_iter,
batch_size,
optimizer,
device,
num_epochs)
- 查看第一个批量归一化层学习到的拉伸参数gamma和偏移参数beta
print(net)
#可以从输出的net网络结构知道第一个批量归一化层位于net[1]
print(net[1].gamma.view((-1,))) # 将参数写成一行
print(net[1].beta.view((-1,)))
print(net[1].gamma)
Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(1): BatchNorm()
(2): Sigmoid()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(5): BatchNorm()
(6): Sigmoid()
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): FlattenLayer()
(9): Linear(in_features=256, out_features=120, bias=True)
(10): BatchNorm()
(11): Sigmoid()
(12): Linear(in_features=120, out_features=84, bias=True)
(13): BatchNorm()
(14): Sigmoid()
(15): Linear(in_features=84, out_features=10, bias=True)
)
tensor([1.0703, 1.2678, 0.9472, 1.0295, 1.1669, 1.0209], device='cuda:0',
grad_fn=)
tensor([ 0.3542, 0.3791, -0.5505, -0.3212, 0.2804, -0.0223], device='cuda:0',
grad_fn=)
tensor([[[[1.0703]],
[[1.2678]],
[[0.9472]],
[[1.0295]],
[[1.1669]],
[[1.0209]]]], device='cuda:0',requires_grad=True)
简洁实现批量归一化层
- 与之前定义的BatchNorm类相比,pytorch中nn模块定义的BatchNorm1d和BatchNorm2d类使用起来更简单。BatchNorm1d用于全连接层,BatchNorm2d用于卷积层。都需要指定输入的num_features参数值。
- 下面代码实现基于pytorch的使用了批量归一化的LeNet
#使用pytorch定义好的类来实现含有批量归一化的LeNet,而不是像上面自定义的BatchNorm层
net = nn.Sequential(
#输入第一层卷积层的输入图片是(256,1,28,28),因为batch_size=256,通道数目值为1,因为灰度图片,高宽都是28
nn.Conv2d(1,6,5),#in_channels,out_channels,kernel_size,经过第一层卷积后,输出图片(256,6,24,24),通道数是卷积层的输出通道值,28-5+1=24
nn.BatchNorm2d(6),#BatchNorm2d用于卷积层,卷积层的输出通道是6,这里由于是使用的pytorch定义好的批量归一化层,所以要有前缀nn.,而之前是没有nn.的
nn.Sigmoid(),
nn.MaxPool2d(2,2),#kernel_size,stride,经过最大池化层后输出图片成(256,6,12,12),因为(24-2+2)/2=12
nn.Conv2d(6,16,5),#输出图片为(256,16,8,8),因为12-5+1=8
nn.BatchNorm2d(16),
nn.Sigmoid(),
nn.MaxPool2d(2,2),#输出图片为(256,16,4,4),因为(8-2+2)/2=4
d2l.FlattenLayer(),
nn.Linear(16*4*4,120),#展开后所以全连接层的输入是16*4*4
nn.BatchNorm1d(120),
nn.Sigmoid(),
nn.Linear(120,84),
nn.BatchNorm1d(84),
nn.Sigmoid(),
nn.Linear(84,10)#期望输出的类别是10类
)
- 在模型训练时,批量归一化利用小批量上的均值和标准差,不断调整神经网络的中间输出,从而使得整个神经网络在各层的中间输出的数值更稳定。
- 对全连接层和卷积层做批量归一化的方法稍有不同。
- 批量归一化和丢弃层一样,在训练模式和预测模式的计算结果是不一样的。
- pytorch提供了BatchNorm类方便调用。
残差网络ResNet
- 对神经网络模型添加新的层,充分训练后的模型是否会有效降低训练误差。
- 理论上原模型解的空间是新模型解的空间的子空间。
- 如果能将新添加的层训练成恒等映射,那么新模型和原模型将同样有效。
- 新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。
- 在实践中,添加过多的层后,训练误差往往还会上升。
- 即使利用批量归一化带来数值稳定性使得训练深层模型变得容易,但是第五点所说的问题还是存在。
- 解决办法就是何凯明提出的残差网络ResNet。
- 残差网络深刻影响了后来的深度神经网络的设计。
- 在残差块中,输入可以通过跨层的数据线路更快地向前传播。
- 残差映射在实际中比较容易优化。恒等映射是期望学出的理想映射。
- 只需要将加权运算(如仿射)的权重和偏差参数学成0,那么就能够实现恒等映射。
- 实际中,当理想映射极接近恒等映射时,残差映射也易于捕捉恒等映射的细微波动。
- ResNet沿用了VGG全3x3卷积层的设计,残差块里首先有2个相同输出通道数的3x3卷积层。每个卷积层后接一个批量归一化层和ReLU激活函数,然后将输入跳过这两个卷积运算后直接加在最后的ReLU激活函数前。
- 这样的设计要求两个卷积层的输出与输入形状一致,从而可以相加。
- 如果想改变通道数,就需要引入一个额外的1x1卷积层来将输入变换成需要的形状后再相加。
- 下面的代码是残差块的实现,可以设定输出通道数、是否使用额外的1x1卷积层来修改通道数以及卷积层的步幅。
# coding=utf-8
# /usr/bin/env python
'''
Author: syy
date: 19-9-24 上午11:29
'''
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
from d2lzh_pytorch import *
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Residual(nn.Module):
def __init__(self,in_channels,out_channels,use_1x1conv=False,stride=1):
super(Residual,self).__init__()
self.conv1 = nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1,stride=stride)
self.conv2 = nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self,X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(Y+X)
- 下面看输入和输出形状一致的情况
blk = Residual(3,3)
X = torch.rand((4,3,6,6))
blk(X).shape#torch.size([4.3.6.6])
- 可以在增加输出通道的同时减半输出的高和宽
blk = Residual(3,6,use_1x1conv=True,stride=2)
blk(X).shape#torch.size([4.6.3.3])
- ResNet的前两层与之前介绍的GoogLeNet中的一样,在输出通道数为64,步幅为2的7x7卷积层后,接步幅为2的3x3的最大池化层。不同在于ResNet每个卷积层后增加的批量归一化层。
net = nn.Sequential(
nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
- GoogLeNet在后面接了4个由Inception块组成的模块,ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。
- 第一个模块的输出通道数同输入通道数一样。由于之前已经使用了步幅为2的最大池化层,所以无需减小高和宽。
- 之后的每个模块都在第一个残差块里将上一个模块的通道数翻倍,并且将高和宽减半。
def resnet_block(in_channels,num_residuals,first_block=False):
if first_block:
assert in_channels == out_channels#第一个模块的通道数与输入通道数一样
blk = []
for i in range(num_residuals):
if i ==0 and not first_block:
blk.append(Residual(in_channels,out_channels,use_1x1conv=True,stride=2))
else:
blk.append(Residual(out_channels,out_channles))
return nn.Sequential(*blk)
- 接着为ResNet加入所有残差块,这里每个模块使用两个残差块。
net.add_module('resnet_block1',resnet_block(64,64,2,first_block=True))
net.add_module('resnet_block2',resnet_block(64,128,2))
net.add_module('resnet_block3',resnet_block(128,256,2))
net.add_module('resnet_block4',resnet_block(256,512,2))
- 最后与GoogLeNet一样,加入全局平均池化层后接上全连接层输出。
net.add_module('global_avg_pool',d2l.GlobalAvgPool2d())#GlobalAvgPool2d的输出:(Batch_size,512,1,1)
net.add_module('fc',nn.Sequential(d2l.FlattenLayer(),nn.Linear(512,10)))
- 每个模块里有4个卷积层,不算1x1卷积层,加上最开始的卷积层和最后的全连接层,总共18层,所以这个模型称为ResNet-18。
- 通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型。例如ResNet-152。
- 虽然ResNet的主体架构跟GoogLeNet类似,但是ResNet结构更简单,修改也方便。
- 输入形态在ResNet不同模块之间的变化
X = torch.rand((1,1,224,224))
for name,layer in net.named_children():
X = layer(X)
print(name,'output shape:\t',X.shape)
- 残差块通过跨层的数据通道从而能够训练出有效的深度神经网络。
# coding=utf-8
# /usr/bin/env python
'''
Author: syy
date: 19-9-24 上午11:29
'''
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
from d2lzh_pytorch import *
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#残差块的实现。通过设定是否使用额外的1x1卷积层来修改通道数,1x1卷积层的作用就是用来修改输入图片的通道数,使得它与残差块输出通道数一致,这样才能做X+Y计算
class Residual(nn.Module):
def __init__(self,in_channels,out_channels,use_1x1conv=False,stride=1):
super(Residual,self).__init__()
self.conv1 = nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1,stride=stride)
self.conv2 = nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1)
if use_1x1conv:#因为后面要计算X+Y,所以需要满足conv1和conv2两个卷积层的输入与输出通道数一致,才能做这个相加运算,如果conv1的输入与输出通道数不一样的话,那么就需要用到1x1卷积层来改变通道数,使得这个加法运算成立
self.conv3 = nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self,X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)#注意不要把X和Y混为一谈,后面第二个例子的代码计算的blk(X).shape是计算的把输入通过conv3后的输出形状
#因为这里要计算X+Y,所以需要满足conv1和conv2两个卷积层的输入与输出通道数一致,才能做这个相加运算,如果conv1的输入与输出通道数不一样的话,那么就需要用到1x1卷积层来改变通道数,使得这个加法运算成立
return F.relu(Y+X)
#这第一个例子满足卷积层的通道数与输入图片通道数一致,所以可以不用1x1卷积,已经满足了X+Y的条件
blk = Residual(3,3)#输入通道和输出通道都为3
X = torch.rand((4,3,6,6))#(样本数,通道数,高,宽)
# print(blk(X).shape)#通过残差块后的输出的形状,torch.size([4.3.6.6])
#这第二个例子输入图片的通道数与卷积网络的输出通道数不一致(卷积网络的输入与输出通道数不一致),所以需要1x1卷积层才能满足X+Y
blk = Residual(3,6,use_1x1conv=True,stride=2)#使用1x1卷积来修改输出图片的通道数,输入图片通道数本来为3,因为stride=2,所以最后通过残差块的输出图片高宽减半
blk(X).shape#torch.size([4.6.3.3])
#ResNet的前两层与GoogLeNet中的一样,在输出通道数64,步幅为2的7x7卷积后接步幅为2的3x3最大池化层,不同在于ResNet在卷积层后接了批量归一化层。
net = nn.Sequential(
nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
#定义模块,resnet_block是模块的总称,前面residual是定义的残差块
def resnet_block(in_channels,out_channels,num_residuals,first_block=False):
#如果是第一个模块
if first_block:
assert in_channels == out_channels#第一个模块的通道数与输入通道数一样,由于之前已经使用了步幅为2的最大池化层,所以这里无需减小高和宽。
blk = []
#每个模块中包含了2个残差块,如果i为0表示是第一个残差块,并且这个序号为1的残差块不位于第一个模块中的话
for i in range(num_residuals):
if i == 0 and not first_block:#除开第一个模块的之后的每个模块都在第一个残差块里(i是残差块的序号,而不是模块的序号,注意区分出模块和残差块是不同的事物,每个模块包含了2个残差块)将上一个模块的通道数翻倍。
blk.append(Residual(in_channels,out_channels,use_1x1conv=True,stride=2))#通过stride=2,将输入图片的宽和高减半
else:#表示除了第一个模块的其他模块中的所有的第二个残差块
blk.append(Residual(out_channels,out_channels))
return nn.Sequential(*blk)
#GoogLeNet是在后面接4个由Inception块组成的模块,而ResNet是使用由残差块组成的4个模块。
#每个模块中的两个残差块是具有相同的输出通道数
#resnet_block1是第一个模块的名字,其中包含两个残差块residual0和residual1,下面总共有4个模块,第二个参数是调用定义的resnet_block()函数
net.add_module('resnet_block1',resnet_block(64,64,2,first_block=True))#第一个模块的输出通道数等于输入通道数,第三个参数表示每个模块中都含有2个残差块
net.add_module('resnet_block2',resnet_block(64,128,2))#每个模块都在第一个残差块里将上一个模块的通道数翻倍,并且将高和宽减半,是通过stride=2实现的。resnet_block是残差块,module是模块。每个模块中包含了2个残差块。
net.add_module('resnet_block3',resnet_block(128,256,2))
net.add_module('resnet_block4',resnet_block(256,512,2))
#最后还要接上全局平均池化层和全连接层,和GoogLeNet一样
net.add_module('global_avg_pool',d2l.GlobalAvgPool2d())#GlobalAvgPool2d的输出:(Batch_size,512,1,1)
net.add_module('fc',nn.Sequential(d2l.FlattenLayer(),nn.Linear(512,10)))
X = torch.rand((1,1,224,224))
for name,layer in net.named_children():
X = layer(X)
print(name,'output shape:\t',X.shape)
#每个模块里有4个卷积层,不算上1x1卷积层,4个模块,故这里有16层了,再加上后面的全局平均池化层和全连接层,故共有18层,所以这个网络称为resnet-18
print(net)
输出结果:
这个name=0就是对应后面输出的net结构中的(0)即在四个模块之前的第一个卷积核为7x7的卷积层。
0 output shape: torch.Size([1, 64, 112, 112])
这个name=1对应的是7x7卷积层后的批量归一化层
1 output shape: torch.Size([1, 64, 112, 112])
这个name=2对应的是归一化层后的激活函数层ReLU()
2 output shape: torch.Size([1, 64, 112, 112])
这个name=3对应的是激活函数层后的最大池化层
3 output shape: torch.Size([1, 64, 56, 56])
第一个模块,包含2个残差块
计算这个模块网络中不含有1x1卷积层时的X的shape时,就是按照这个X通过模块中的每一层这样计算下去得到最终的输出形状
resnet_block1 output shape: torch.Size([1, 64, 56, 56])
第二个模块
对于这种模块网络中含有1x1卷积层的,虽然对于X也是这样通过模块中的每一层网络这样传递下去,由于(从代码可以知道,这时X和Y相当于是两个量,所以可以看成是计算这种情况下的X的shape时,就只用分析其经过1x1卷积后的shape即可,与X经过所有层后的输出结果是等同的),而上面不含有1x1卷积层的情况加,X就是代码中的Y。
resnet_block2 output shape: torch.Size([1, 128, 28, 28])
第三个模块
resnet_block3 output shape: torch.Size([1, 256, 14, 14])
第四个模块
resnet_block4 output shape: torch.Size([1, 512, 7, 7])
四个模块后面的全局平均池化层
global_avg_pool output shape: torch.Size([1, 512, 1, 1])
最后接的全连接层
fc output shape: torch.Size([1, 10])
下面输出的是net结构
Sequential(
(0): Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(resnet_block1): Sequential(
(0): Residual(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(resnet_block2): Sequential(
(0): Residual(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(resnet_block3): Sequential(
(0): Residual(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(resnet_block4): Sequential(
(0): Residual(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): Residual(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(global_avg_pool): GlobalAvgPool2d()
(fc): Sequential(
(0): FlattenLayer()
(1): Linear(in_features=512, out_features=10, bias=True)
)
)
稠密连接网络DenseNet
- ResNet的跨层连接设计引申出了许多工作,其中一个就是稠密连接网络DenseNet。
- DenseNet与ResNe在跨层连接上的主要区别是:ResNet是使用相加。而DenseNet是使用连结。
- DenseNet里模块B的输出不是像ResNet那样和模块A的输出相加,而是在通道维上连结。这样模块A的输出可以直接传入模块B后面的层。这个设计中,模块A直接跟模块B后面的所有层连接在了一起,所以被称为稠密连接。
- DenseNet的主要构建模块是稠密块dense block和过渡层transition layer。稠密块定义了输入和输出是如何连结的,而过渡层是用来控制通道数,使通道数不至于过大。
- DenseNet使用了ResNet改良版的“批量归一化、激活和卷积”结构。在下面代码中的conv_block函数里实现这个改良版的“批量归一化、激活和卷积”结构。
# coding=utf-8
# /usr/bin/env python
'''
Author: syy
date: 19-9-24 下午4:43
'''
import time
import torch
from torch import nn,optim
import torch.nn.functional as F
from d2lzh_pytorch import *
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def conv_block(in_channels,out_channels):
blk = nn.Sequential(nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1))
return blk
#blk是block的缩写
- 稠密块由多个conv_block组成,每块使用相同的输出通道数,但是在前向计算时,将每块的输入和输出在通道维上连结。
class DenseBlock(nn.Module):
def __init__(self,num_convs,in_channels,out_channels):
super(DenseBlock,self).__init__()
net = []
for i in range(num_convs):
in_c = in_channels+i*out_channels
net.append(conv_block(in_c,out_channels))
self.net = nn.ModuleList(net)
self.out_channels = in_channels+num_convs*out_channels#计算输出通道数
def forward(self,X):
for blk in self.net:
Y = blk(X)
X = torch.cat((X,Y),dim=1)#在通道维上将输入和输出连结
return X
- 下面的代码中定义一个有2个输出通道数为10的卷积块,使用通道数为3的输入时,得到通道数为3+2*10=23的输出。卷积块的通道数控制了输出通道数相对于输入通道数的增长,所以被称为增长率。
blk = DenseBlock(2,3,10)
X = torch.rand(4,3,8,8)
Y = blk(X)
Y.shape#torch.size([4,23,8,8])
- 每个稠密块都会带来通道数的增加,使用过多稠密块会带来过于复杂的模型。
- 过渡层用来控制模型复杂度。
- 过渡层通过1x1卷积层来减小通道数,并且使用步幅为2的平均池化层减半高和宽,从而进一步降低模型复杂度。
def transition_block(in_channels,out_channels):
blk = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels,out_channels,kernel_size=1),
nn.AvgPool2d(kernel_size=2,stride=2)
)
return blk
blk = transition_block(23,10)
blk(Y).shape#torch.size([4,10,4,4])
- 下面代码实现DenseNet模型的构造,DenseNet首先使用和ResNet一样的单卷积层和最大池化层。
net = nn.Sequential(
nn.Conv2d(1,64,kernel_size=2,padding=3),#对于Sequential构造网络需要逗号
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
- 类似于ResNet接下来使用4个模块,DenseNet同样类似的是使用4个稠密块。
- 和ResNet一样,可以设置每个稠密块使用多少个卷积层。这里设置使用4个卷积层,与ResNet-18中的每个模块使用4个卷积层一致。
- 稠密块里的卷积鞥通道数(即增长率)设置为32,所以每个稠密块将增加128个通道。4*32=128
- ResNet中使用步幅为2的残差块在每个模块之间减小高和宽。在DenseNet中使用过渡层来减半高和宽,并减半通道数。
num_channels,growth_rate = 64,32#num_channels为当前的通道数
num_convs_in_dense_blocks = [4,4,4,4]
for i,num_convs in enumerate(num_convs_in_dense_blocks):
DB = DenseBlock(num_convs,num_channels,growth_rate)
net.add_module('DenseBlock_%d' %i,DB)
#上一个稠密块的输出通道数
num_channels = DB.out_channels
#在稠密块之间加入通道数减半的过渡层
if i != len(num_convs_in_dense_blocks)-1:
net.add_module('transition_block_%d' % i,transition_block(num_channels,num_channels//2))
num_channels = num_channels//2
- 和ResNet一样,最后接上全局池化层和全连接层来输出
net.add_module('BN',nn.BatchNorm2d(num_channels))
net.add_module('relu',nn.ReLU())
net.add_module('global_avg_pool',d2l.GlobalAvgPool2d())
net.add_module('fc',nn.Sequential(d2l.FlattenLayer(),nn.Linear(num_channels,10)))
- 打印每个子模块的输出维度确保网络无误
X = torch.rand((1,1,96,96))
for name,layer in net.named_children():
X = layer(X)
print(name,'output shape:\t',X.shape)
输出结果如下:
因为X:[1,1,96,96],通过卷积层(96-2+1+6)/1=101,所以输出[1, 64, 101, 101]
0 output shape: torch.Size([1, 64, 101, 101])
通过BN层,BN层的feature_num值也即是第一个参数与输入图片的通道数一致
1 output shape: torch.Size([1, 64, 101, 101])
通过激活函数层
2 output shape: torch.Size([1, 64, 101, 101])
通过最大池化层,(101-3+2+2)/2=51
3 output shape: torch.Size([1, 64, 51, 51])
通过第一个稠密块,在单个稠密块结构中,BN的feature_num值与卷积层的输入通道数值一致。这里经过稠密块后的图片的通道数与以往计算不一样,
不再是通过的最后一层卷积的输出通道数,因为在稠密块中进行了输出通道数与输入通道在通道维上相连结,所以通过的卷积层的输出通道数也是输出
图片通道数的增长率,故64+32*4=192,经过稠密块除了使得通道数增长外,其他没有变化
DenseBlock_0 output shape: torch.Size([1, 192, 51, 51])
经过第一个过渡层,使得通道数以及高宽都减半,通道数减半是因为通过的1x1卷积层发生了作用,而高宽减半是后面通过的stride值为2的平均池化层发生了作用
transition_block_0 output shape: torch.Size([1, 96, 25, 25])
通过第二个稠密块,通道数增加32*4
DenseBlock_1 output shape: torch.Size([1, 224, 25, 25])
经过第二个过渡层,通道数以及高宽减半
transition_block_1 output shape: torch.Size([1, 112, 12, 12])
第三个稠密层,通道数增加32*4
DenseBlock_2 output shape: torch.Size([1, 240, 12, 12])
第三个过渡层,通道数以及高宽减半
transition_block_2 output shape: torch.Size([1, 120, 6, 6])
第三个稠密层,通道数增加32*4
DenseBlock_3 output shape: torch.Size([1, 248, 6, 6])
最后一个稠密层后不再接过渡层,输出图片的通道数与后面接的BN层的feature_num值也即是第一个参数值相等
BN output shape: torch.Size([1, 248, 6, 6])
relu output shape: torch.Size([1, 248, 6, 6])
经过全局平均池化层后高宽都变成1
global_avg_pool output shape: torch.Size([1, 248, 1, 1])
经过全连接层,输出变成两个维度,第一个参数是样本数,第二个参数即输出通道数也即使期望分类的类别数
fc output shape: torch.Size([1, 10])
下面是整个net的结构:
Sequential(
(0): Conv2d(1, 64, kernel_size=(2, 2), stride=(1, 1), padding=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(DenseBlock_0): DenseBlock(
(net): ModuleList(
(0): Sequential(
(0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): Sequential(
(0): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(96, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): Sequential(
(0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): Sequential(
(0): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(160, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(transition_block_0): Sequential(
(0): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1))
(3): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(DenseBlock_1): DenseBlock(
(net): ModuleList(
(0): Sequential(
(0): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(96, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): Sequential(
(0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): Sequential(
(0): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(160, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): Sequential(
(0): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(192, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(transition_block_1): Sequential(
(0): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(224, 112, kernel_size=(1, 1), stride=(1, 1))
(3): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(DenseBlock_2): DenseBlock(
(net): ModuleList(
(0): Sequential(
(0): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(112, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): Sequential(
(0): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(144, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): Sequential(
(0): BatchNorm2d(176, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(176, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): Sequential(
(0): BatchNorm2d(208, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(208, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(transition_block_2): Sequential(
(0): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(240, 120, kernel_size=(1, 1), stride=(1, 1))
(3): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(DenseBlock_3): DenseBlock(
(net): ModuleList(
(0): Sequential(
(0): BatchNorm2d(120, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(120, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): Sequential(
(0): BatchNorm2d(152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(152, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): Sequential(
(0): BatchNorm2d(184, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(184, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): Sequential(
(0): BatchNorm2d(216, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): ReLU()
(2): Conv2d(216, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(BN): BatchNorm2d(248, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(global_avg_pool): GlobalAvgPool2d()
(fc): Sequential(
(0): FlattenLayer()
(1): Linear(in_features=248, out_features=10, bias=True)
)
)
- 在跨层连接上,不同于ResNet中将输入与输出相加,DenseNet在通道维上连结输入与输出。
- DenseNet的主要构建模块是稠密块与过渡层。
优化与深度学习
- 优化为深度学习提供最小化损失函数的方法,本质上优化与深度学习的目标是不一样的。
- 优化算法的目标函数是一个基于训练数据集的损失函数,优化的目标在于降低训练误差。
- 深度学习的目标在于降低泛化误差。
- 为了降低泛化误差除了使用优化算法降低训练误差外,还需要应对过拟合。
- 优化问题有解析解和数值解两类。
- 深度学习中很多目标函数复杂,所以没有解析解。需要基于数值方法的优化算法找到近似解。
- 为得到最小化目标函数的数值解,通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。
- 优化在深度学习中有很多挑战,其中两个是局部最小值和鞍点。
- 深度学习模型的目标函数可能有若干局部最优值。当一个优化问题的数值解在局部最优解附近时,由于目标函数有关解的梯度接近或变成0,最终迭代求得的数值解可能只使得目标函数局部最小化。
- 梯度接近或者变成0的另一种可能是当前解在鞍点附近。
- 在鞍点位置,目标函数可能在x轴方向上是局部最小值而在y轴方向上是局部最大值。
- 假设一个函数的输入为k维向量,输出是标量,那么它的海森矩阵有k个特征值。该函数在梯度为0的位置上可能是局部最小值、局部最大值或者鞍点。
- 当函数的海森矩阵在梯度为0的位置上的特征值全为正,该函数得到局部最小值
- 当函数的海森矩阵在梯度为0的位置上的特征值全为负,该函数得到局部最大值
- 当函数的海森矩阵在梯度为0的位置上的特征值有正有负,该函数得到鞍点。
- 随机理论表示,对于一个大的高斯随机矩阵来说,任一特征值是正或者是负的概率都是0.5。
- 深度学习模型参数通常是高维的,目标函数的鞍点通常比局部最小值常见。
- 找到目标函数全局最优解很难,但是这并非必要。
随机梯度下降
- 深度学习里目标函数通常是训练数据集中有关各个样本的损失函数的平均。
- 随机梯度下降中自变量的迭代轨迹相对于梯度下降中的来说更曲折,这是因为实验所添加的噪声使得模拟的随机梯度的准确度下降。实际中,这些噪声通常指的是训练数据集中的无意义的干扰。
- 当训练数据集样本较多时,梯度下降每次迭代的计算开销很大,所以随机梯度下降更受青睐。
- 随机梯度下降在每次迭代中只随机采样一个样本来计算梯度。
小批量随机梯度下降
- 可以通过重复采样或者不重复采样得到一个小批量中的各个样本。
- 基于随机采样得到的梯度的方差在迭代过程中无法减小,实际中,小批量随机梯度下降的学习率可以在迭代过程中自我衰减,或者每迭代多少次将学习率衰减一次。这样的化,学习率和小批量随机梯度乘积的方差会减小。而梯度下降在迭代过程中一直使用目标函数的真实梯度,无需自我衰减学习率。
- 当批量数目较小时,会导致并行处理和内存使用效率变低。这使得计算同样数目样本的情况下,比使用更大批量值所花时间多。
- 当批量值大时,每个小批量梯度里可能含有更多的冗余信息,为得到更好的解,批量较大时比批量较小时需要计算的样本数目可能更多,例如增大迭代周期数。
- 如果在损失函数里对各个小批量样本的损失求平均,这样的话,优化算法里的梯度就不需要除以批量大小。
- 即使随机梯度下降和梯度下降在一个迭代周期里都处理1500个样本,但是随机梯度下降的一个迭代周期耗时更多。这是因为随机梯度下降在一个迭代周期里做了更多次的自变量迭代,而且单样本的梯度计算难以有效利用矢量计算。
- 小批量随机梯度下降在每个迭代周期的耗时介于梯度下降和随机梯度下降的耗时之间。
- 小批量随机梯度每次随机均匀采样一个小批量的训练样本来计算梯度。
- 实际中小批量随机梯度下降的学习率可以在迭代过程中自我衰减。
动量法
- 梯度下降也叫作最陡下降,梯度代表了目标函数在自变量当前位置上下降最快的方向。
- 但是如果自变量的迭代方向仅仅取决于自变量当前位置,也会带来问题。
- 同一位置上,目标函数在竖直方向上比在水平方向上的斜率的绝对值更大。那么给定学习率,梯度下降迭代自变量时会使得自变量在竖直方向上比在水平方向上移动幅度更大。那么需要一个较小的学习率从而避免自变量在竖直方向上越过目标函数最优解。然而这会造成自变量在水平方向上朝最优解移动变慢。
- 动量法就是为了解决这个问题。在动量法中,自变量在各个方向上的移动幅度不仅取决于当前梯度,还取决于过去的各个梯度在各个方向上是否一致。
- 动量法使用了指数移动加权平均的思想,它将过去时间步的梯度做了加权平均,且权重按照时间步指数衰减。
- 动量法使得相邻时间步的自变量更新在方向上更加一致。
AdaGrad算法
- AdaGrad算法根据自变量在每个维度的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应所有维度的问题。
- 需要注意的是,如果目标函数有关自变量中某个元素的偏导数一直都较大,那么该元素的学习率将下降较快。反之,如果目标函数有关自变量中某个元素的偏导数一直都较小,那么该元素的学习率将下降较慢。自变量中每个元素的学习率在迭代过程中一直在降低或者不变。所以当学习率在迭代早期降低得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。
- AdaGrad算法在迭代过程中不断调整学习率,并且让目标函数自变量中每个元素都分别拥有自己的学习率
- 使用AdaGrad算法时,自变量中每个元素的学习率在迭代过程中一直在降低或者不变。
RMSProp算法
- RMSProp算法是对AdaGrad算法的修改版,针对AdaGrad存在的问题做出了修改。
- 和AdaGrad算法一样,RMSProp算法将目标函数自变量中的每个元素的学习率通过按照元素运算重新调整,然后更新自变量。
- RMSProp算法的状态变量是对平方项的指数加权平均,所以可以看做是最近几个时间步的小批量随机梯度平方项的加权平均。这样的话,自变量每个元素的学习率在迭代过程中就不再一直降低或者不变。这样也就解决了AdaGrad存在的问题。
- RMSProp算法与AdaGrad算法的不同在于,RMSProp算法使用了小批量随机梯度按照元素平方的指数加权移动平均来调整学习率。
Adam算法
- Adam算法在RMSProp算法的基础上对小批量随机梯度也做了指数加权移动平均。
- 所以Adam可以看做是RMSProp与动量法的结合。
- Adam算法使用了偏差修正。
- 和AdaGrad算法、RMSProp算法一样,目标函数自变量中每个元素都分别拥有自己的学习率。
命令式编程和符号式混合编程
- 命令式编程方便,但是它的运行可能很慢。
- 与命令式编程不同,符号式编程是在计算流程完全定义好后才被执行。
- 命令式编程方便,在python里使用命令式编程时,代码直观。命令式编程易调试,因为可以方便获取并打印所有的中间变量。
- pytorch仅仅采用了命令式编程。
图像增广
- 随机改变训练样本可以降低模型对某些属性的依赖,提高模型的泛化能力。
- 对图像不同方式的裁剪,使得感兴趣的物体出现在不同位置,减轻模型对物体出现位置的依赖。池化层也能降低卷积层对目标位置的敏感度。
- 调整亮度、色彩等降低模型对色彩的敏感度。
- 将图像增广应用在实际训练,选择CIFAR-10数据集,而不采用Fashion-MNIST数据集的原因是Fashion-MNIST数据集中物体的位置和尺寸都已经经过了归一化处理。而CIFAR-10数据集中物体的颜色和大小区别更加显著。
- 为了预测时得到确定的结果,通常只将图像增广用在训练样本上,而不在预测时使用含有随机操作的图像增广。
- 使用ToTensor将小批量图像转成PyTorch需要的格式,即形状为(批量大小,通道数,高,宽)、值域在0和1之间且类型为32位浮点数。
微调
- 迁移学习将从源数据集学到的知识迁移到目标数据集上。
- 微调是迁移学习的一种常用技术
- 目标模型复制了源模型上除了输出层外的所有模型设计及其参数,并基于目标数据集微调这些参数,而目标模型的输出层需要从头训练。
- 一般来说,微调参数会使用较小的学习率,而从头训练输出层可以使用较大的学习率。
- ImageNet数据集有超过1000万张图像和1000类的物体。
- Fashion-MNIST训练数据集有6万张图像。
- 平常接触到的数据集规模通常在这两个数据集规模之间。
- 例如想从图像中识别出不同种类的椅子,然后将购买链接推荐给用户。一种方法是:先找出100种常见的椅子,为每种椅子拍摄1000张不同角度的图像,然后在收集到的图像数据集上训练一个分类模型。这个椅子数据集比Fashion-MNIST数据集要大,但是样本数远远不及ImageNet数据集中的样本数,这就可能导致适用于ImageNet数据集的复杂模型在这个椅子数据集上过拟合。同时,数据集数量有限,最终训练得到的模型的精度也可能达不到实用的要求。
- 为了解决上面的问题,一个办法是收集更多数据。但是收集和标注数据是耗费巨大的。
- 另一种解决办法就是迁移学习,将从源数据集学到的知识迁移到目标数据集上。
- 例如虽然ImageNet数据集的图像大多跟椅子无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别椅子也可能同样有效。
- 微调是迁移学习中的常用技术。
- 微调由以下四步组成:
(1)第一步:在源数据集,如ImageNet数据集上预训练一个神经网络模型,即源模型。
(2)第二步:创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。还假设源模型的输出层跟源数据集的标签紧密相关。因此在目标模型中不予采用源模型的输出层。
(3)第三步:为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
(4)第四步:在目标数据集(如椅子数据集)上训练目标模型,将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。 - 当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
- 下面实践一个具体的例子:热狗识别。基于一个小数据集对在ImageNet数据集上训练好的ResNet模型进行微调。该小数据集含有数千张包含热狗和不包含热狗的图像。使用微调得到的模型来识别一张图像中是否包含热狗。
- torchvision中的models包提供了常用的预训练模型。如果希望获得更多的预训练模型,可以使用pretrained-models.pytorch仓库。
- 在使用预训练模型时,一定要和预训练时做同样的预处理,如果使用的是torchvision的models,那就要求:所有的输入图片要用同样的方式归一化,每张输入图片要求shape是(3×HxW),其中高和宽不能少于224,这些输入图片都要加载到范围为[0,1]下,然后再使用mean=[0.485,0.456,0.406]和std=[0.229,0.224,0.225]来归一化。
- 如果使用的是pretrained-models.pytorch仓库,那么阅读README,上面有说如何预处理。
import torch
from torch import nn,optim
from torch.utils.data import Dataset,DataLoader
import torchvision
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torchvision import models
#指定RGB三个通道的均值和方差来将图像通道归一化
normalize = transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
train_augs = transforms.Compose([
transforms.RandomResizedCrop(size=224),#要加上逗号
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
])
test_augs = transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
normalize
])
- 定义和初始化模型,使用在ImageNet数据集上预训练的ResNet-18作为源模型,这里指定pretrained=True来自动下载并架子预训练的模型参数,在第一次使用时需要联网下载模型参数。
- 默认会将预训练好的模型参数下载到home目录下的.torch文件夹。另一种下载更快的方式是:在其源码中找到下载地址直接浏览器输入地址下载。
- 如果使用的是某些模型,可能没有成员变量fc即全连接层,比如models中的VGG预训练模型。
pretrained_net = models.resnet18(pretrained=True)
print(pretrained_net.fc)
#Linear(in_features=512,out_features=1000,bias=True)
#可以通过下面的代码来修改源模型中的全连接层(输出层),在ImageNet中训练有1000个类别,
# 而这里只需要两个类别。修改为目标数据集需要的输出类别数
pretrained_net.fc = nn.Linear(512,2)
- 此时pretrained_net的fc层就被随机初始化了,但是其他层依然保持着预训练得到的参数。
- 由于是在很大的ImageNet数据集上预训练的,所以参数已经足够好。因此一般只需要使用较小的学习率来微调这些参数。而fc层中的随机初始化参数一般需要更大的学习率从头训练。
- pytorch可以方便的对模型的不同部分设置不同的学习参数。在下面代码中将fc的学习率设置为已经预训练过的部分的10倍。
# map() 会根据提供的函数id()对指定序列做映射。
output_params = list(map(id,pretrained_net.fc.parameters()))
# filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。源模型中只要是不在输出层即全连接层中的参数都保留下来
feature_params = filter(lambda p:id(p) not in output_params,pretrained_net.parameters())
lr = 0.01
optimizer = optim.SGD([{'params':feature_params},
{'params':pretrained_net.fc.parameters(),'lr':lr*10}],
lr=lr,weight_decay=0.01)
#定义一个使用微调的训练函数train_fine_tuning
def train_fine_tuning(net,optimizer,batch_size=128,num_epochs=5):
train_iter = DataLoader(ImageFolder(os.path.join(data_dir,'hotdog/train'),transform=train_augs),
batch_size,shuffle=True)
test_iter = DataLoader(ImageFolder(os.path.join(data_dir,'hotdog/test'),transform=test_augs),
batch_size)
loss = torch.nn.CrossEntropyLoss()
d2l.train(train_iter,test_iter,net,loss,optimizer,device,num_epochs)
train_fine_tuning(pretrained_net,optimizer)
- 迁移学习将从源数据集学习到的知识迁移到目标数据集上
- 微调是迁移学习的一种常用技术
- 目标模型复制了源模型上除了输出层外的所有模型设计及其参数,并基于目标数据集微调这些参数。而目标模型的输出层需要从头训练。
- 微调参数会使用较小的学习率,而从头训练输出层可以使用较大学习率。
- 对于定义一个相同模型,但是它所有模型参数都随机初始化为随机值,由于整个模型都需要从头训练,可以使用较大的学习率。微调的模型因为参数初始值更好,往往在相同迭代周期下取得更高的精度。
目标检测
- 目标检测在多个领域中被广泛使用,例如无人驾驶里,需要通过识别拍摄到的视频图像里的车辆、行人、道路和障碍的位置来规划线路。
- 机器人通过目标检测来检测感兴趣的目标。
- 安防领域则需要检测异常目标,如歹徒和子弹等。
- 目标检测算法会在输入图像中采样大量的区域,然后判断这些区域是否包含感兴趣的目标,并调整区域边缘从而更准确的预测目标的真实边界框ground-truth bounding box。
- 不同的模型使用的区域采样方法不同。
- 其中一种区域采样方法是:以每个像素为中心生成多个大小和宽高比不同的边界框,这些边界框称为锚框anchor box。
- 如果一个锚框没有被分配真实边界框,只需要将该锚框的类别设置为背景,类别为背景的锚框通常被称为负类锚框,其余被称为正类锚框。
- 以每个像素为中心,生成多个大小和宽高比不同的锚框
- 交并比是两个边界框相交面积与相并面积之比
- 在训练集中 ,为每个锚框标注两类标签:一是锚框所含目标的类别。二是真实边界框相对锚框的偏移量。
- 预测时,可以使用非极大值抑制来移除相似的预测边界框,从而使得结果简洁。
多尺度目标检测
- 在前面讲到,以输入图像的每个像素为中心生成多个锚框,这些锚框是对输入图像不同区域的采样。但是如果以图像每个像素为中心都生成锚框,很容易生成过多锚框而造成计算量过大。
- 减少锚框的一种方法是:在输入图像中均匀采样一小部分像素。并以采样的像素为中心生成锚框。此外,在不同尺度下,可以生成不同数量和不同大小的锚框。
- 较小目标比较大目标在图像上出现位置的可能性更多。所以当使用较小锚框来检测较小目标时,可以采样较多的区域。当使用较大锚框来检测较大目标时,可以采样较少的区域。
- 卷积神经网络的二维数组输出称为特征图,可以定义特征图的形状来确定任一图像上均匀采样的锚框中心。
- 在特征图上以每个单元(像素)为中心生成锚框,由于锚框中的x和y轴的坐标纸分别已经除以特征图的宽和高,这些值域在0和1之间的值表达了锚框在特征图中的相对位置。
- 由于锚框的中心遍布特征图上的所有单元,锚框的中心在任一图像的空间相对位置一定是均匀分布的。
- 先关注小目标的检测,为了显示时容易区分,令不同中心的锚框不重合,设锚框大小为0.15,特征图的高和宽分别为4,。
- 然后将特征图的高和宽分别减半,并用更大的锚框检测更大的目标。当锚框大小设为0.4时,有些锚框的区域有重合。
- 最后将特征图的高宽进一步减半到1,并将锚框大小增加到0.8,此时锚框中心即图像中心。
- 已经在多个尺度上生成了不同大小的锚框,需要在不同尺度下检测不同大小的目标。
- 在某个尺度下,假设依据c张形状为h x w的特征图生成h x w组不同中心的锚框,且每组的锚框个数为a,。
- 例如,在上面所说的第一个尺度下,依据10(通道数)张形状为4x4的特征图生成16组不同中心的锚框,且每组含有3个锚框。依据真实边界框的类别和位置,每个锚框被标注类别和偏移量。在当前尺度下,目标检测模型需要根据输入图像预测h x w组不同中心的锚框的类别和偏移量。
- 假设上面所说的c张特征图为卷积神经网络根据输入图像做前向计算所得的中间输出。每张特征图上都有h x w个不同的空间位置,那么相同空间位置可以看做含有c个单元。
- 根据感受野定义,特征图在相同空间位置的c个单元在输入图像上的感受野相同,并表征了同一感受野内的输入图像信息。因此可以将特征图在相同空间位置的c个单元变换为以该位置为中心生成的a个锚框的类别和偏移量。本质上,用输入图像在某个感受野区域内的信息来预测输入图像上与该区域位置相近的锚框的类别和偏移量。
- 当不同层的特征图在输入图像上分别拥有不同大小的感受野时,它们将分别用来检测不同大小的目标。
- 例如可以通过设计网络,零较接近输出层的特征图中每个单元拥有更广阔的感受野,从而检测输入图像中更大尺寸的目标。
- 可以在多个尺度下生成不同数量和不同大小的锚框,从而在多个尺度下检测不同大小的目标。
- 特征图的形状能确定任一图像上均匀采样的锚框中心。
- 用输入图像在某个感受野区域内的信息来预测输入图像上与该区域相近的锚框的类别和偏移量。
- 因为特征图本身是经过了卷积降维的,针对特征图每个像素生成锚框的个数也会小鱼针对原始图像每个像素生成的锚框个数,且生成的锚框投射到原图像时,是均匀分布的。
单发多框检测SSD
- 用之前提到的边界框、锚框、多尺度目标检测,基于这些背景构造一个目标检测模型:单发多框检测single shot multibox detection即SSD。这个SSD模型的设计思想和实现细节常适用于其他目标检测模型。
- SSD模型主要是由一个基础网络块和若干个多尺度特征块串联而成。
- 其中基础网络块用来从原始图像中抽取特征。因此一般会选择常用的深度卷积神经网络。
- SSD论文选择了在分类层之前截断的VGG,现在也常用ResNet替代,可以设计基础网络,使得它输出的高和宽较大。这样的话,基于该特征图生成的锚框数量就多,可以用来检测尺寸较小的目标。
- 在模型的设计上,接下来的每个多尺度特征快将上一层提供的特征图的高和宽缩小,如减半。并使得特征图中每个单元在输入图像上的感受野变得广阔。
- 这样的话,越靠近顶部的多尺度特征块输出的特征图越小,故而基于特征图生成的锚框也越少。加上特征图上每个单元感受野越大,因此更适合于检测尺寸较大的目标。
- 由于SSD基于基础网络块和各个多尺度特征块生成不同数量和不同大小的锚框,并通过预测锚框的类别和偏移量(即预测边界框)检测不同大小的目标,因此SSD是一个多尺度的目标检测模型。

类别预测层
- 设目标的类别个数是q,每个锚框的类别个数是q+1,其中类别0表示锚框只包含背景。
- 在某个尺度下,设特征图的高和宽分别为h和w。如果以其中每个单元为中心生成a个锚框,那么需要对hwa个锚框进行分类。如果使用全连接层作为输出,很容易导致模型参数过多,在网络中的网络NiN中使用卷积层的通道来输出类别预测的方法。SSD就是用同样的方法来降低模型复杂度。
- 类别预测层使用一个保持输入高和宽的卷积层。这样的话,输出和输入在特征图宽和高上的空间坐标一一对应。
边界框预测层
- 边界框预测层的设计与类别预测层的设计类似。
- 唯一不同的是,在边界框预测层设计时,需要为每个锚框预测4个偏移量,而不是q+1个类别。
连结多尺度的预测
- SSD根据多个尺度下的特征图生成锚框并且预测类别和偏移量。由于每个尺度上特征图的形状或者是以同一单元为中心生成的锚框个数都可能不同,因此不同尺度的预测输出形状可能不同。
- 通道维包含中心相同的锚框的预测结果。首先将通道维移到最后一维,因为不同尺度下批量大小仍保持不变,可以将预测结果转成二维的(批量大小,高×宽×通道数)的格式,以方便之后在维度1上的连结。
- 这样的话,尽管Y1和Y2形状不同,但是仍然可以将这两个同一批量不同尺度的预测结果连结在一起。
高和宽减半块
- 高和宽减半块串联了两个padding=1的3×3卷积层和步幅为2的2*2最大池化层。
- padding为1的卷积层不改变特征图的形状,后面的池化层直接将特征图的高宽减半。
- 由于12+(3-1)+(3-1)=6,所以输出特征图中每个单元在输入特征图上的感受野形状为66.
- 可以看出,高宽减半块使得输出特征图中每个单元的感受野变得更广阔。
基础网络块
- 基础网络块用来从原始图像中抽取特征。下面构建一个小的基础网络,网络串联3个高宽减半块,并且逐步将通道数翻倍。
SSD完整模型
- SSD一共包含5个模块,每个模块输出的特征图既用来生成锚框,又用来预测这些锚框的类别和偏移量。
- 第一个模块是基础网络块。第二个模块到第四个模块是高宽减半块。第五个模块是使用全局最大池化层将高和宽降低到1.
- 即是说第二到第五模块均为多尺度特征块。
- 下面定义每个模块如何进行前向计算。与之前介绍的卷积神经网络不同,这里不仅返回卷积计算输出的特征图Y,还会返回根据Y生成的当前尺度的锚框,以及基于Y预测的锚框类别和偏移量。
- 上面的步骤创建了一个SSD用于对一个高和宽为256的小批量图像X做前向计算。
- 在之前说过,第一模块输出的特征图的形状是32*32.由于第二到第四个模块都是高宽减半块,第五模块是全局池化层,并且以特征图每个单元为中心生成4个锚框,每个图像在5个尺度下生成的锚框总数是:(32x32+16x16+8x8+4x4+1x1)x4=5444。
定义损失函数和评价函数
- 目标检测有两个损失:一是有关锚框类别的损失。可以用之前图像分类问题里一样的交叉熵损失函数。二是有关正类锚框偏移量的损失。
- 预测偏移量是一个回归问题,但这里不使用前面介绍过的平方损失,而是使用L1范数损失,即预测值与真实值之间差的绝对值。
- 掩码变量bbox_masks令负类锚框和填充锚框不参与损失的计算。最后将有关锚框类别和偏移量的损失相加得到模型的最终损失函数。
- 可以沿用准确率评价分类结果,因为使用了L1范数损失,用平均绝对误差评价边界框的预测结果。
预测
- 在预测时,希望能把图像里面感兴趣的目标检测出来。读取测试图片,将其变换尺寸,然后转成卷积层需要的四维格式。
- 根据锚框和预测偏移量得到预测边界框,并且通过非极大值抑制移除相似的预测边界框。
- 最后将置信度不低于阈值的边界框筛选出来为最终输出。
- SSD是一个多尺度的目标检测模型,该模型基于基础网络块和各个多尺度特征块生成不同数量和不同大小的锚框,并且通过预测锚框的类别和偏移量检测不同大小的目标。
- SSD在训练中根据类别和偏移量的预测和标注值计算损失函数。
改进模型的几点建议
第一个改进方面:针对损失函数
- 针对损失函数,将预测偏移量用到的L1范数损失替换成平滑L1范数损失。它在零点附近使用平方函数从而更加平滑,这是通过一个超参数来控制平滑区域的。
- 当超参数很大时,该损失类似于L1范数损失
- 当超参数较小时,损失函数较平滑
- 可以把损失函数由交叉熵损失换为焦点损失即focal loss。增大其中一个超参数可以有效减小正类预测概率较大时的损失
第二个改进方面:针对训练和预测上
- 当目标在图像中占比小时,模型通常采用较大的输入图像尺寸
- 为锚框标注类别时,通常会产生大量的负类锚框。可以对负类锚框进行采样,从而使得数据类别更加平衡。
- 在损失函数中为有关锚框类别和有关正类锚框偏移量的损失分别赋予不同的权重超参数.
区域卷积神经网络R-CNN系列
- 区域卷积神经网络region-based CNN或者是regions with CNN features,即R-CNN。
- R-CNN是将深度模型应用于目标检测的开创性工作之一。
- R-CNN以及它的一系列改进方法:快速的R-CNN即Fast R-CNN,更快的R-CNN即Faster R-CNN,以及掩码R-CNN即Mask R-CNN。
- R-CNN首先对图像选取若干个提议区域(如锚框也是一种选取方法)。并且标注它们的类别和边界框(如偏移量)。然后用卷积神经网络对每个提议区域做前向计算抽取特征。之后用每个提议区域的特征预测类别和边界框。
- R-CNN模型如下:
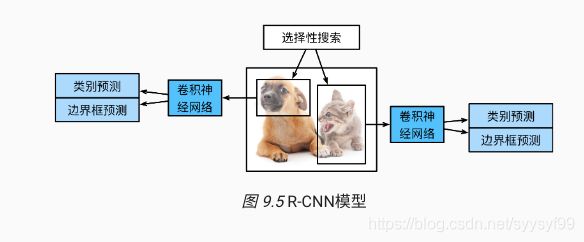
- R-CNN由以下四步组成:
(1)第一步:对输入图像使用选择性搜索selective search来选取多个高质量的提议区域。这些提议区域是在多个尺度下选取的,并且具有不同的形状和大小。每个提议区域将被标注类别和真实边界框。
(2)第二步:选取一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并且通过前向计算输出抽取的提议区域特征。
(3)第三步:将每个提议区域的特征连同其标注的类别作为一个样本,训练多个支持向量机对目标分类。其中每个支持向量机用来判断样本是否属于某一个类别。
(4)第四步:将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。 - R-CNN虽然通过预训练的卷积神经网络有效抽取了图像特征,但是它的主要缺点是速度慢。从一张图像中选出上千个提议区域,对该图像做目标检测将导致上千次的卷积神经网络的前向计算。这个巨大的计算量令R-CNN难以在实际应用中被广泛采用。
Fast R-CNN
- R-CNN的主要性能瓶颈在于需要对每个提议区域独立抽取特征。这些区域通常有大量重叠,独立的特征抽取会导致大量的重复计算。
- Fast R-CNN对R-CNN的一个主要改进在于只对整个图像做卷积神经网络的前向计算。
- Fast R-CNN模型如下图

- Fast R-CNN的主要步骤为如下四步:
(1)与R-CNN相比,Fast R-CNN用来提取特征的卷积神经网络的输入是整个图像,而不是各个提议区域。而且这个网络会参与训练,即更新模型参数,设输入为一张图像,将卷积神经网络的输出的形状记为1 * c * h1 * w1。
(2)假设选择性搜索生成n个提议区域,这些形状各异的提议区域在卷积神经网络的输出上分别标出形状各异的兴趣区域。这些兴趣区域需要抽取形状相同的特征(假设高和宽为h2和w2)以便于连结后输出。Fast R-CNN引入兴趣区域池化层region of interest pooling,RoI池化层,将卷积神经网络的输出和提议区域作为输入,输出连结后的各个提议区域抽取的特征,形状为n * c * h2 * w2。
(3)通过全连接层将输出形状变换为n * d。其中超参数d取决于模型设计。
(4)预测类别时,将全连接层的输出的形状再变换为n * q,并使用softmax回归(q为类别个数)。预测边界框时,将全连接层的输出的形状变换为n * 4。也就是说为每个提议区域预测类别和边界框。 - Fast R-CNN中提出的兴趣区域池化层与之前说过的池化层有所不同。在池化层中,通过设置池化窗口、填充和步幅来控制输出形状。而兴趣区域池化层对每个区域的输出形状是可以直接指定的。
- 例如,指定每个区域输出的高和宽分别为h2和w2,假设某一兴趣区域窗口的高和宽分别为h和w。该窗口将被划分为形状为h2 * w2的子窗口网格。且每个子窗口的大小约为(h/h2) * (w/w2)。任一子窗口的高和宽要取整,其中的最大元素作为该子窗口的输出。因此兴趣区域池化层可以从形状各异的兴趣区域中均抽取出形状相同的特征。
- 例如在下图中,在4x4的输入上选取了左上角的3x3区域作为兴趣区域。对于这个兴趣区域,通过2x2兴趣区域池化层得到一个2x2的输出。
- 4个划分后的子窗口分别含有元素0、1、4、5(其中5最大),2、6(其中6最大),8、9(其中9最大),10。

Faster R-CNN
- Fast R-CNN需要在选择性搜索中生成较多的提议区域,以获得精确的目标检测结果。
- Faster R-CNN提出将选择性搜索替换成区域提议网络region proposed network,从而减少提议区域的生成数量,并且保证目标检测的精度。
- Faster R-CNN模型如下图

- Faster R-CNN与Fast R-CNN相比,只有生成提议区域的方法从选择性搜索变成了区域提议网络,而其余部分保持不变。
- 区域提议网络的计算步骤可分为如下四步:
(1)使用填充为1的3x3卷积层变换卷积神经网络的输出,并且将输出通道数记为c。这样卷积神经网络为图像抽取的特征图中的每个单元均得到一个长度为c的新特征。
(2)以特征图每个单元为中心,生成多个不同大小和宽高比的锚框并标注它们。
(3)用锚框中心单元长度为c的特征分别预测该锚框的二元类别(含目标还是背景)和边界框。
(4)使用非极大抑制,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即兴趣区域池化层所需要的提议区域。 - 区域提议网络作为Faster R-CNN的一部分,是和整个模型一起训练得到的。也就是说,Faster R-CNN的目标函数既包括目标检测中的类别和边界框预测,又包括区域提议网络中锚框的二元类别和边界框预测。最终,区域提议网络能够学习到如何生成高质量的提议区域,从而在减少提议区域数量的情况下也能保证目标检测的精度。
Mask R-CNN
- 如果训练数据还标注了每个目标在图像上的像素级位置,那么Mask R-CNN能有效利用这些详尽的标注信息进一步提升目标检测的精度。
- Mask R-CNN的模型图如下:
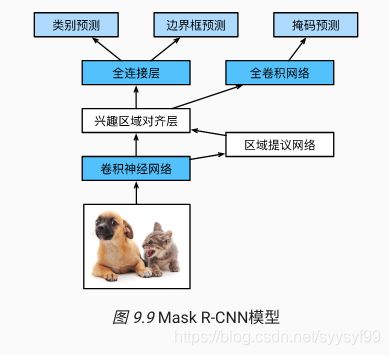
- Mask R-CNN在Faster R-CNN的基础上做了修改,Mask R-CNN将兴趣区域池化层替换成了兴趣区域对齐层,即通过双线性插值bilinear interpolation来保留特征图上的空间信息,从而更适用于像素级预测。
- 兴趣区域对齐层的输出包含了所有兴趣区域的形状相同的特征图,它们既用来预测兴趣区域的类别和边界框,又通过额外的全卷积网络预测目标的像素级位置。
- R-CNN对图像选取若干提议区域,然后用卷积神经网络对每个提议区域做前向计算抽取特征,再用这些特征预测提议区域的类别和边界框。
- Fast R-CNN对R-CNN一个主要改进在于只对整个图像做卷积神经网络的前向计算。它引入兴趣区域池化层,从而令兴趣区域能够抽取出形状相同的特征。
- Faster R-CNN将Fast R-CNN中的选择性搜索替换成区域提议网络,从而减少提议区域的生成数量,并保证目标检测的精度。
- Mask R-CNN在Faster R-CNN的基础上引入一个全卷积神经网络,从而借助目标的像素级位置进一步提升目标检测的精度。
语义分割
- 上面所涉及到目标检测问题时,使用的都是方形边界框来标注和预测图像中的目标。
- 语义分割semantic segmentation。关注的是如何将图像分割成属于不同语义类别的区域。
- 这些语义区域的标注和预测都是像素级的。
- 下图是语义分割中图像有关猫、狗和背景。与目标检测相比,语义分割标注的像素级的边框更加精细。
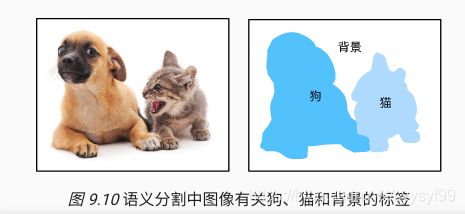
语义分割、图像分割、实例分割
- 计算机视觉领域与语义分割相似的话题是:图像分割image segmentation和实例分割instance segmentation。
- 图像分割将图像分割成若干个组成区域。这类问题的方法通常利用图像中像素之间的相关性。图像分割在训练时不需要有关图像像素的标签,在预测时也无法保证分割出的区域具有希望得到的语义。以上面那个语义分割图为例子,如果是用作图像分割的话,可能会分割成两个区域:一个覆盖以黑色为主的眼睛和嘴巴。另一个覆盖以黄色为主的其余部分身体。
- 实例分割又叫做同时检测并分割simultaneous detection and segmentation。实例分割研究的是如何识别图像中各个目标实例的像素级区域。与语义分割不同,实例分割不仅需要区分语义,还需要区分不同的目标实例。如果图像中有两只狗,实例分割需要区分像素属于这两只狗中的哪一只。
- 语义分割有一个很重要的数据集叫做Pascal VOC。在SegmentationClass路径下包含了标签,标签也是图像格式,其尺寸与它所标注的输入图像的尺寸相同。标签中颜色相同的像素属于同一个语义类别。在标签图像中,白色代表边框,黑色代表背景。其他不同的颜色对应不同的类别。不同于图像分类和目标识别,语义分割的样本标签是一个三维数组。
- 在其他的场景下,通过缩放图像使其符合模型的输入形状。但是在语义分割里,这样做需要将预测的像素类别重新映射回原始尺寸的输入图像,这样的映射是难以做到精确的。尤其是在不同语义的分割区域。
- 为了避免上面的问题,将图像裁剪成固定尺寸而不是缩放。使用图像增广里的随机裁剪,并对输入图像和标签裁剪相同区域。
- 由于数据集中有些图像的尺寸可能小于随机裁剪所指定的输出尺寸,这些样本需要移除。
- 由于语义分割的输入图像和标签在像素上一一对应,所以将图像随机裁剪成固定尺寸而不是缩放。
- 可以基于语义分割对图像中的每个像素进行类别预测。
全卷积网络FCN
- fully convolutional network全卷积网络采用卷积神经网络实现了从图像像素到像素类别的变换。与前面说过的卷积神经网络不同,全卷积神经网络通过转置卷积transposed convolution层将中间层特征图的高和宽变换回输入图像的尺寸,从而令预测结果与输入图像在空间维(高和宽)上一一对应。给定空间维上的位置,通道维的输出即该位置对应像素的类别预测。
- 卷积运算可以通过矩阵乘法来实现。
- 权重矩阵是含有大量0元素的稀疏矩阵,其中的非0元素来自卷积核中的元素。
- 从矩阵乘法的角度描述卷积运算,设输入向量是x,权重矩阵是W,卷积的前向计算函数的实现可以看做将函数输入乘以权重矩阵,并输出向量y=Wx。
- 反向传播需要依据链式法则,卷积的反向传播函数的实现可以看做将函数输入乘以转置后的权重矩阵。
- 转置卷积层正好交换了卷积层的前向计算函数和反向传播函数。
- 转置卷积层的这两个函数可以看做将函数输入向量分别乘以权重矩阵的转置和权重矩阵。
- 转置卷积层可以用来交换卷积层输入和输出的形状。
- 在模型设计中,转置卷积层常用于将较小的特征图变换为更大的特征图。
- 全卷积网络中,当输入是高宽较小的特征图时,转置卷积层可以用来将高宽放大到输入图像的尺寸。
- 下图是全卷积网络模型最基本的设计图

- 全卷积网络先使用卷积神经网络抽取图像特征,然后通过1x1卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。模型输出与输入图像的高和宽相同,并且在空间位置上一一对应,最终输出的通道包含了该空间位置像素的类别预测。
- 下面使用一个基于ImageNet数据集预训练的ResNet-18模型来抽取图像特征,并且将该网络实例记为pretrained_net,该模型成员变量features的最后两层分别是全局最大池化层GlobalAvgPool2D和样本变平层Flatten,而output模块包含了输出用的全连接层。全卷积网络不需要使用这些层。
pretrained_net = model_zoo.vision.resnet18_v2(pretrained=True)
pretrained_net.features[-4:]#输出最后四层
pretrained_net.output
Out[6]:(HybridSequential(
(0):BatchNorm(axis=1,eps=1e-05,momentum=.9,fix_gamma=False,use_global_stats=False,in_channels=512)
(1):Activation(relu)
(2):GlobalAvgPool2D(size=(1,1),stride=(1,1),padding=(0,0),ceil_mode=True,pool_type=avg,layout=NCHW)
(3):Flatten
),Dense(512 -> 1000,linear))
- 下面创建全卷积网络实例net,它复制了pretrained_net实例成员变量features里除了最后两层的所有层以及预训练得到的模型参数
net = nn.HybridSequential()
for layer in pretrained_net.features[:-2]:#除了最后两层的所有层
net.add(layer)
- 给定高和宽分别为320和480的输入,net的前向计算将输入的高和宽减小到原来的1/32。即10和15.
- 接下来通过1x1卷积层将输出通道变换为Pascal VOC2012数据集的类别个数21,最后需要将特征图的高和宽放大32倍,从而变回输入图像的高和宽。
- 根据卷积层输出形状的计算公式,且因为(320-64+16x2+32)/32=10,且(480-64+16x2+32)/32=15,所以构造一个步幅为32的转置卷积层,并且将卷积核的高和宽设置为64,填充padding设置为16.
num_classes = 21
net.add(nn.Conv2D(num_classes,kernel_size=1),
nn.Conv2DTranspose(num_classes,kernel_size=64,padding=16,strides=32))
- 转置卷积层可以放大特征图,在图像处理中,有时需要将图像放大,即上采样upsample。
- 上采样的方法很多,常用的有双线性插值。简单说,就是为了得到输出图像在坐标(x,y)上的像素,先将该坐标映射到输入图像的坐标(x’,y’)。例如根据输入与输出的尺寸之比来映射。映射后的x’和y’通常是实数。然后在输入图像上找到与坐标(x’,y’)最近的4个像素。最后,输出图像在坐标(x,y)上的像素依据输入图像上这4个像素及其与(x’,y’)的相对距离来计算。
- 在全卷积网络中,将转置卷积层初始化为双线性插值的上采样,对于1x1卷积层,采用Xavier随机初始化。
- 这时的损失函数和准确率计算与图像分类中的并没有本质上的不同。只是因为使用转置卷积层的通道来预测像素的类别,所以在SoftmaxCrossEntropyLoss里指定了axis=1(通道维)选项。此外模型基于每个像素的预测类别是否正确来计算准确率。
- 在预测像素类别时,需要将输入图像在各个通道上做标准化,并且转成卷积神经网络所需要的四维输入格式。
- 测试数据集中的图像大小和形状各异,由于模型使用了步幅为32的转置卷积层,当输入图像的高或宽无法被32整除时,转置卷积层输出的高或宽会与输入图像的尺寸有偏差。为了解决这个问题,可以在图像中截取多块高和宽为32的整数倍的矩形区域,并分别对这些区域中的像素做前向计算。这些区域的并集需要完整覆盖输入图像。当一个像素被多个区域所覆盖时,它在不同区域前向计算中转置卷积层输出的平均值可以作为softmax运算的输入,从而预测类别。
- 全卷积网络先使用卷积神经网络抽取图像特征,然后通过1x1卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸,从而输出每个像素的类别。
- 全卷积网络中,可以将转置卷积层初始化为双线性插值的上采样。
样式迁移
- 滤镜可以改变照片的颜色样式,使得风景照更加锐利或者是人像更加美白。单一个滤镜通常只能改变照片的某个方面。
- 如果要照片达到理想样式,经常需要尝试大量不同组合,其复杂程度不亚于模型调参。
- 样式迁移style transfer使用卷积神经网络自动将某图像中的样式应用在另一图像上。
- 需要两张输入图片,一张是内容图片,一张是样式图片。使用神经网络修改内容图片使得其在样式上接近样式图片。
- 下面是基于卷积神经网络的样式迁移办法步骤:
- 第一步:首先初始化合成图像,例如将其初始化为内容图像。
- 该合成图像是样式迁移过程中唯一需要更新的变量,即样式迁移所需迭代的模型参数。
- 第二步:选择一个预训练的卷积神经网络来抽取图像特征,其中的模型参数在训练中无需更新。
- 深度卷积神经网络凭借多个层级逐级抽取图像的特征。可以选择其中某些层的输出作为内容特征或者是样式特征。
- 以下图所示:
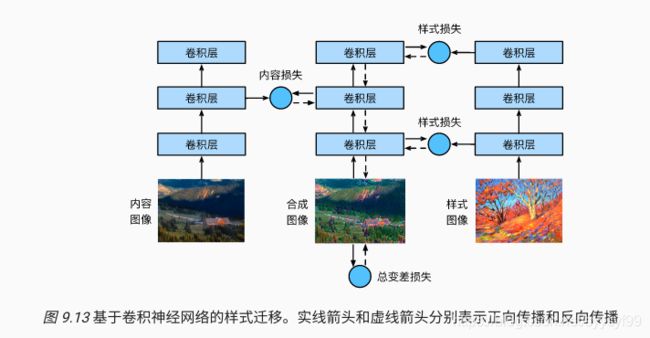
- 上图选取的预训练的神经网络含有3个卷积层,其中第二层输出图像的内容特征,而第一层和第三层的输出被作为图像的样式特征。
- 然后,通过正向传播,图纸的实线箭头方向,沿着这个方向计算样式迁移的损失函数
- 并且通过反向传播,虚线箭头方向来迭代模型参数,即不断更新合成参数。
- 样式迁移常用的损失函数由三部分组成:内容损失使得合成图像与内容图像在内容特征上接近,样式损失使得合成图像与样式图像在样式特征上接近,而总变差损失total variation loss则有助于减少合成图像中的噪点。
- 最后当模型训练结束时,输出样式迁移的模型参数,即得到最终的合成图像。
- 预处理函数对输入图像在RGB三个通道上分别做标准化,并且将结果变换成卷积神经网络接受的输入格式。
- 后处理函数则将输出图像中的像素值还原回标准化之前的值。
- 使用基于ImageNet数据集预训练的VGG-19模型来抽取图像特征
pretrained_net = model_zoo.vision.vgg19(pretrained=True)
- 为了抽取图像的内容特征和样式特征,可以选择VGG网络中某些层的输出。
- 越靠近输入层的输出越容易抽取图像的细节信息,反之越容易抽取图像的全局信息。
- 为了避免合成图像过多保留内容图像的细节,选择VGG较靠近输出的层,也称为内容层,来输出图像的内容特征。
- 从VGG中选择不同层的输出来匹配局部和全局的样式,这些层也叫作样式层。
- VGG网络使用了5个卷积块。这里选择第四个卷积块的最后一个卷积层作为内容层,以及每个卷积块的第一个卷积层作为样式层。这些层的索引可以通过打印pretrained_net实例来获取。
style_layers,content_layers = [0,5,10,19,28],[25]
- 在抽取特征时,只需要用到VGG从输入层到最靠近输出层的内容层或者样式层之间的所有层。
- 下面构建一个新的网络net,只需要保留需要用到的VGG的所有层,使用net来抽取特征。
net = nn.Sequential()
for i in range(max(content_layers+style_layers)+1):
net.add(pretrained_net.features[i])
- 给定输入X,如果简单调用前向计算net(X),只能获得最后一层的输出,由于还需要中间层的输出,因此这里逐层计算,并保留内容层和样式层的输出。
def extract_features(X,content_layers,style_layers):
contents = []
styles = []
for i in range(len(net)):
X = net[i](X)
if i in style_layers:
styles.append(X)
if i in content_layers:
contents.append(X)
return contents,styles
- 下面定义两个函数,其中get_contents函数对内容图像抽取内容特征,而get_styles函数对样式图像抽取样式特征。
- 因为训练时无需改变预训练的VGG的模型参数,所以可以在训练开始之前就提取出内容图像的内容特征,以及样式图像的样式特征。
- 由于合成图像是样式迁移所需迭代的模型参数,只能训练过程中通过调用extract_features函数来抽取合成图像的内容特征和样式特征。
def get_contents(image_shape,ctx):
content_X = preprocess(content_img,image_shape).copyto(ctx)
contents_Y,_ = extract_features(content_X,content_layers,style_layers)
return content_X,contents_Y
def get_styles(image_shape,ctx):
style_X = preprocess(style_img,image_shape).copyto(ctx)
_,styles_Y = extract_features(style_X,content_layers,style_layers)
return style_X,style_Y
- 样式迁移的损失函数由内容损失、样式损失和总变差损失3部分组成。
- 内容损失与线性回归中的损失函数类似,内容损失通过平方误差函数衡量合成图像与内容图像在内容特征上的差异。
- 平方误差函数的两个输入都是extract_features函数计算得到的内容层的输出。
def content_loss(Y_hat,Y):
return (Y_hat - Y).square().mean()
- 样式损失也一样通过平方误差函数衡量合成图像与样式图像在样式上的差异。
- 为了表达样式层输出的样式,先通过extract_features函数计算样式层的输出。
- 假设该输出的样本数为1,通道数为c,高和宽分别为h和w。可以把输出变换成c行hw列的矩阵X。
- 矩阵X可以看成是由c个长度为hw的向量x1,x2,……xc组成的。其中向量xi表示通道i上的样式特征。
- 这些向量的格拉姆矩阵Gram matrix即X(X^T)中i行j列的元素xij即向量xi与向量xj的内积。这个内积值表达了通道i和通道j上样式特征的相关性。
- 用这样的格拉姆矩阵表达样式层输出的样式。
- 当hw值较大时,格拉姆矩阵中的元素容易出现较大的值。
- 格拉姆矩阵的高和宽皆为通道数c。
- 为了让样式损失不受这些值的大小影响,下面定义的gram函数将格拉姆矩阵除以矩阵中元素的个数即chw。
def gram(X):
num_channels,n = X.shape[1], X.size // X.shape[1]#注意这里用的//符号
X = X.reshape((num_channels,n))
#nd在mxnet中定义的
return nd.dot(X, X.T) / (num_channels*n)#这里用的/符号
- 样式损失的平方误差函数的两个格拉姆矩阵输入分别基于合成图像与样式图像的样式层输出。gram_Y是基于样式图像的格拉姆矩阵。
def style_loss(Y_hat,gram_Y):
return (gram(Y_hat)-gram_Y).square().mean()
- 由于学到的合成图像里有大量高频噪点,即有特别亮或者特别暗的颗粒像素。
- 一种常用的降噪方法是总变差降噪total variation denoising。
- 降低总变差损失能够使得邻近的像素值相似。
- 样式迁移的损失函数即内容损失、样式损失和总变差损失的加权和。通过调节这些权值超参数,可以权衡合成图像在保留内容、迁移样式以及降噪三方面的相对重要性。
- 在样式迁移中,合成图像是唯一需要更新的变量。
- 所以可以定义一个简单的模型GeneratedImage,并将合成图像视为模型参数。模型的前向计算只需返回模型参数即可。
class GeneratedImage(nn.Block):
def __init__(self,img_shape,**kwargs):
super(GeneratedImage,self).__init__(**kwargs)
self.weight = self.params.get('weight',shape=img_shape)
def forward(self):
return self.weight.data()
- 下面定义get_inits函数,该函数创建了合成图像的模型实例,并将其初始化为图像X,样式图像在各个样式层的格拉姆矩阵styles_Y_gram将在训练前预先计算好:
def get_inits(X,ctx,lr,styles_Y):
gen_img = GeneratedImage(X.shape)
gen_img.initialize(init.Constant(X),ctx=ctx,force_reinit=True)
trainer = gluon.Trainer(gen_img.collect_params(),'adam',
{'learning_rate':lr})
styles_Y_gram = [gram(Y) for Y in styles_Y]
return gen_img(),styles_Y_gram,trainer
- 在训练模型时,不断抽取合成图像的内容特征和样式特征,并计算损失函数。
- 样式迁移常用的损失函数由三部分组成:内容损失使得合成图像与内容图像在内容特征上接近,样式损失令合成图像与样式图像在样式特征上接近,总变差损失有助于减少合成图像中的噪点。
- 可以通过预训练的卷积神经网络来抽取图像的特征,并且通过最小化损失函数来不断更新合成图像。
- 用格拉姆矩阵表达样式层输出的样式。格拉姆矩阵主要是对不同通道间进行内积操作。格拉姆矩阵表示不同通道上的样式特征的协方差矩阵,表示不同通道上样式特征的相关性分布。
- 扩展:
(1)选择不同的内容和样式层对输出会造成什么影响。
(2)调整损失函数中的权值超参数,输出是否可以保留更多内容或者是减少更多噪点。
(3)替换内容图像和样式图像,怎样创作出更有趣的合成图像。
项目实战
- 在训练集和验证集的并集上训练模型,充分利用所有标注的数据。
- “Xavier”初始化方法是一种很有效的神经网络初始化方法,方法来源于2010年的一篇论文《Understanding the difficulty of training deep feedforward neural networks》。为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等。
- 根据模型在验证集上的表现来选择模型并调节超参数。记录每个迭代周期的训练时间,有助于比较不同模型的时间开销。
- 可以创建ImageFolderDataset实例来读取含原始图像文件的数据集。
- 可以应用卷积神经网络、图像增广和混合式编程来实战图像分类比赛。
- (不一定通用)SGD+momentum进行优化对学习率特别敏感,不如用AdaDelta.
- 如果比赛的数据属于ImageNet数据集的子集,因此可以使用微调的思路,选择在ImageNet完整数据集上预训练的模型来抽取图像特征,以作为自定义小规模输出网络的输入。
- 比赛数据集属于预训练数据集的子集,因此可以直接复用预训练模型在输出层的输入,即抽取的特征。然后,可以将原输出层替换成自定义的可训练的小规模输出网络,如两个串联的全连接层。这里不再训练用于抽取特征的预训练模型,这样既节省训练时间,又省去存储其模型参数的梯度的空间。
- 使用在ImageNet数据集上预训练的模型抽取特征,并仅训练自定义的小规模输出网络,从而以较小的计算和存储开销对ImageNet的子集数据集做分类。
Tensor
- torch.tensor是存储和变换数据的只要工具。Tensor和Numpy的多维数组很像。区别在于Tensor提供GPU计算和自动求梯度等功能,使得Tensor更加适合深度学习。
- tensor是张量,张量可以看成是一个多维数组,标量可以看成是0维张量,向量可以看做1维张量,矩阵可以看作是二维张量。
- view()返回的新tensor与源tensor共享内存,其实就是同一个tensor,所以更改其中一个,另外一个也会跟着改变,也就是说view仅仅是改变了对这个张量的观察角度。
- item()可以将一个标量Tensor转换为一个Python number。
广播机制
- 如果是两个形状不同的Tensor按照元素运算时,涉及到广播机制,即先适当复制元素使得这两个Tensor形状相同后再按照元素运算。
- 索引、view()是不会开辟新内存的,像y=x+y这样的运算是会开辟新内存的。
Tensor和Numpy互换
- 用numpy()和from_numpy()将Tensor和Numpy中的数组互换。这两个函数产生的Tensor和Numpy中的数组共享相同的内存,所以它们之间的转换很快。改变其中一个时另外一个也会改变。
- 将numpy中的array转换为Tensor的方法是torch.tensor(),这个方法会进行数据拷贝,所以会消耗更多的时间和空间,所以返回的Tensor和原来的数据不再共享内存。
- 用.to()可以将Tensor在GPU和CPU上移动。my_tensor=my_tensor.to(torch.device(“cuda”))
自动求梯度
- Tensor是autograde包的核心类,将.requires_grad设置为True。它将开始追踪在其上的所有操作,这样就可以用链式法则进行梯度传播了。完成计算后,可以调用.backward()完成所有的梯度计算,此Tensor的梯度将累积到.grad属性。
- 可以用with torch.no_grad()将不想被追踪的操作代码块包裹起来。在评估模型时常用,因为在评估模型时,并不需要计算可训练参数的梯度。
- Function是另外一个很重要的类,Tensor和Function互相结合就可以构建一个记录有整个计算过程的有向无环图。每个Tensor都有一个.grad_fn属性,这个属性创建该Tensor的Function。也就是说,该Tensor是不是由某些运算得到的,如果是的话,那么grad_fn返回一个与这些运算相关的对象,否则是None。
梯度
- 因为out是一个标量,所以调用backward()时不需要指定求导变量。
- grad在反向传播过程中是累加的,每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需要把梯度清零。
- 如果想要修改tensor的值,但是又不希望被autograde记录,即不去影响到反向传播,所以可以对tensor.data操作。
线性回归
- 回归问题在生活中常见,例如:预测房屋价格、气温、销售额等。
- 线性回归输出是连续值
- 分类问题中输出是离散值。例如:图像分类、垃圾邮件识别、疾病检测等。
- softmax回归适用于分类问题。
- 尽可能使用矢量计算而不要使用for循环。
- 线性回归和softmax回归都是单层神经网络。
- 作为一个单层神经网络,线性回归输出层中的神经元和输入层中各个输入完全连接,所以线性回归的输出层又叫全连接层。
- torch.nn仅仅支持输入一个batch的样本,不支持单个样本输入,如果只有单个样本,可以使用input.unsqueeze(0)来添加一维。
- torch.optim模块提供了很多常用的优化算法比如:SGD/Adam/RMSProp等。
- 可以为不同的子网络设置不同的学习率,这在finetune时经常用到。
- 使用pytorch简洁地实现模型。torch.utils.dta模块提供了有关数据处理的工具。torch.nn模块定义了大量神经网络的层。torch.nn.init模块定义了各种初始化方法,torch.optim模块提供了模型参数初始化的各种方法。
- 线性回归用到平方损失函数。
- softmax回归用到交叉熵损失函数。
softmax回归
- softmax回归和线性回归不同,softmax回归的输出单元从一个变为多个,且引入softmax运算使得输出更适合离散值的预测和训练。
- softmax回归和线性回归一样都是将输入特征与权重做线性叠加。但是区别在于,softmax回归的输出值个数等于标签里的类别数。
- softmax回归和线性回归一样,是一个单层神经网络,由于每个输出的计算都要依赖于所有的输入,softmax回归的输出也是一个全连接层。
交叉熵损失函数
- 交叉熵损失函数适合于衡量两个概率分布的差异。
- 交叉熵只关心对正确类别的预测概率,因为只要其值足够大,就可以确保分类结果正确。但是当遇到一个样本有多个标签时,即类似图像里含有不止一个物体时,并不能这样来简化,也就是对于一张图片中有多个物体的情况时,交叉熵同样是只关心对图像中出现的物体类别的预测概率。
- 只有当一张图片中只有一个标签时,这种情况下才能简化,才存在:最小化交叉熵损失函数等价于最大化训练数据集有标签类别的联合概率预测。
- 在训练好softmax回归模型之后,给定任一样本特征,就可以预测每个类别的概率。通常把预测概率最大的类别作为输出类别。如果它与真实类别标签一致,就说明这次预测正确。
- softmax回归适用于分类问题,使用softmax运算输出类别的概率分布。
torchvision包
- torchvision包是用来构建CV模型的。主要由以下四部分组成:
- 第一部分:torchvision.datasets是一些加载数据的函数及常用数据集接口
- 第二部分:torchvision.models:包含常用的模型结构,含有预训练模型,例如AlexNet/VGG/ResNet等。
- 第三部分: torchvision.transform:常用的图片变换。
- 第四部分:torchvision.utils:其他的一些有用的方法。
- 指定参数transform=transforms.ToTensor()使得所有数据转化为Tensor,如果不进行转化则返回的是PIL图片。
-
transform=transforms.ToTensor()将尺寸为(HxWxC)且数据位于[0,255]的PIL图片或者数据类型为np.uint8的Numpy数组转换为尺寸为(CxHxW)且数据类型为torch.float32且位于[0.0.1.0]的Tensor。
- DataLoader中一个很方便的功能是允许使用多进程来加速数据读取,例如通过参数num_workers来设置多个进程读取数据。如果这个参数值设置为0则表示不用额外的进程来加速读取数据。
- dim=0表示列,dim=1表示行。
- 因为得到的数据形式是:每个batch样本x的形状是(batch_size,1,28,28)。所以首先要用view()将x的形状转换为(batch_size,784)再送入到全连接层。
- pytorch提供的函数往往具有更好的数值稳定性。
- 多层感知器就是含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数变换。多层感知机的层数和各隐藏单元个数都是超参数。
- 多层感知机和softmax回归的实现过程唯一不同的是,多加了一个全连接层作为隐藏层,并且这个隐藏层还是要ReLU函数作为激活函数。
- 在训练深度学习模型时,正向传播和反向传播之间是互相依赖的。一方面正向传播的计算可能依赖于模型参数的当前值,而这些模型参数是在反向传播的梯度计算后通过优化算法迭代的。另一方面,反向传播的梯度计算可能依赖于各变量的当前值,而这些变量的当前值是通过正向传播计算得到的。
- 在模型参数初始化完成后,交替地进行正向传播和反向传播,并且根据传播计算的梯度迭代模型参数,在反向传播中使用到了正向传播中计算得到的中间变量来避免重复计算,那么这个复用也导致正向传播结束后不能立即释放中间变量内存。这也是训练比预测占用更多内存的一个重要原因。这些中间变量的个数大体上与网络层数线性相关,每个变量的大小与批量大小和输入个数也是线性相关的,这是导致深的网络使用较大批量训练时更容易超内存的原因。
- 正向传播沿着从输入层到输出层的顺序,依次计算并存储神经网络的中间变量。
- 反向传播沿着从输出层到输入层的顺序,依次计算并存储神经网络中间变量和参数的梯度。
- pytorch的nn.Module()的模块中参数都默认采取了合理的初始化策略,不同类型的layer采用了不同的恰当的初始化方法。
Module的子类
- Module类是一个通用的部件,Pytorch还实现了继承自Module的可以方便构建模型的类:Sequential/ModuleList/ModuleDict等。
Sequential类
- 当模型的前向计算为简单串联各个层的计算时,Sequential类可以通过更加简单的方式定义模型,这也是Sequential类的目的:它可以接收一个子模块的有序字典OrderedDict或者是一系列子模块作为参数来逐一添加Module的实例,而模型的前向计算就是将这些实例按添加的顺序逐一计算。
ModuleList类
- ModuleList接收一个子模块的列表作为输入,也可以类似List那样进行append和extend操作。
ModuleDict类
- ModuleDict接收一个子模块的字典作为输入,然后也可以类似字典那样进行添加访问操作。
总结:
- 上面介绍的这三种Module的子类来构造网络模型很简单,且不需要定义forward函数,但是直接继承Module类可以极大扩展模型构造的灵活性。
访问模型的参数
- 对于Sequential实例中含模型参数的层,可以通过Module类的parameters()或者names_parameters方法来访问所有参数,以迭代器的形式返回。对于以named_parameters方法来访问参数时,除了返回参数Tensor外还会返回其名字。在返回名字的时候会加上层数的索引作为前缀。
- 使用Sequential类构造的神经网络,可以通过方括号[]来访问网络的任一层。
- torch.nn.parameter.Parameter是Tensor的子类。如果一个Tensor是Parameter,那么它会自动被添加到模型的参数列表里。因为Parameter是Tensor,所以Tensor拥有的属性它都有,比如可以根据data来访问参数数值,用grad来访问参数梯度。
- 若想进行in-place操作,就比方说y加上x,y的值就改变了,就可以用y.add_(x)这样y就直接被改变了。Torch里面所有带““的操作,都是in-place的。例如x.copy(y)
- argmax函数:torch.argmax(input, dim=None, keepdim=False)返回指定维度最大值的序号,也就是变成dim这个维度的最大值的index。
- 构建深度学习模型的基本流程就是:搭建计算图,求得损失函数,然后计算损失函数对模型参数的导数,再利用梯度下降法等方法来更新参数。
- 搭建计算图的过程,称为“正向传播”,是需要自己动手的,因为需要设计模型结构。由损失函数求导的过程,称为“反向传播”,求导是件辛苦事,所以自动求导是各种深度学习框架的基本功能之一,PyTorch也不例外。
pytorch的自动求导过程
- 所有的tensor都有.requires_grad属性,都可设置成自动求导。在定义tensor时,让这个属性为True:
例如:
x = tensor.ones(2,4,requires_grad=True)
- 只要如上这样设置后,后面由x运算得到的其他tensor,都有equires_grad=True属性。可以通过x.requires_grad来查看这个属性。
- 区别tensor.requires_grad和tensor.requires_grad_(),前面是调用变量的属性值,后者是调用内置函数,来改变属性。
自动求导过程的第一步:定义一个计算图(通俗说就是计算步骤)
例如:
x=torch.tensor([[1.,2.,3.],[4.,5.,6.]],requires_grad=True)
y=x+1
z=2*y*y
J=torch.mean(z)
- 要使x支持求导,必须让x为浮点类型,也就上面例子中给x初始值时要加点:“.”
- 上面例子中的计算图如下:

- 例子中x、y、z都是tensor,都是size为(2,3)的矩阵。但是J是对z的每一个元素加起来求平均,所以J是标量。
求导,只能是【标量】对标量,或者【标量】对向量/矩阵求导!
- 所以例子中只能J对x、y、z求导,而z不能对x求导。
- PyTorch求导是调用.backward()方法。直接调用backward(),会计算对计算图叶节点的导数。
- 获取求得的导数,用.grad方法。
上面的例子如下
J.backward()
x.grad
会输出:tensor([[1.3333,2.0000,2.6667],
[3.3333,4.0000,4.6667]])
- 上面例子的总结:构建计算图(正向传播,Forward Propagation)和求导(反向传播,Backward Propagation)的过程就是:

variable和tensor的区别:variable计算时在背景幕布后面一步步默默搭建一个庞大系统叫做计算图,这个图是将所有的计算步骤(节点)都连接起来,最后进行误差反向传播的时候,一次性将所有variable里面的修改幅度(梯度)都计算出来,而tensor没有这个能力。
直接print(variable)只会输出variable形式的数据,很多时候都是用不了的,比如用plt画图,所以需要转换一下,将它变成tensor的形式。
pytorch之神经网络的组件
- PyTorch的torch.nn中包含了各种神经网络层、激活函数、损失函数等的类。通过torch.nn创建对象,搭建网络。
- PyTorch中还有torch.nn.functional,可以通过调用函数的方式,直接搭建网络,而不用像torch.nn一样要先创建对象。
一般情况下,对于像Conv层这种需要定义多个参数的时候,我们采用torch.nn的方式比较方便,而对于参数比较少的,或者不用设置参数的,尤其是一些函数,我们就可以采用torch.nn.functional来定义。一般我们import torch.nn.functional as F,这样后面写起来方便一些。
- 下面是定义模型的其中一种方法
import torch.nn as nn
imort torch.nn.functional as F
def __init__(self):
#调用nn.Module的初始化方法
super(Model,self).__init__()
self.conv1=nn.Conv2d(1,20,5)
self.conv2=nn.Conv2d(20,20,5)
#主要写各层之间通过什么激活函数、池化等来连接
def forward(self,x):
x=F.relu(self.conv1(x))
return F.relu(self.conv2(x))
- 通过上面的方式定义了模型类后,就可以使用nn.Module内置的.parameters()获取模型的参数。后面要更新的就是这些参数。
pytorch常用的神经网络层
第一个:卷积层
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
- 例子:
#16通道进来,64通道出去,kernel为3x3,stride为2
conv1=nn.Conv2d(16,64,32,32)
#100个16通道的32x32数据
output_data=conv1(input_data)
print(output_data.size())
#输出torch.Size([100,64,15,15])
第二个:全连接层
- 举例:
#全连接层,32个特征输入,128个特征输出
#相当于一个有128个神经元的神经网络层
fc1=nn.Linear(32,128)
#100个样本,每个样本有32个特征值
input=torch.randn(100,32)
output=fc1(input)
print(output.size())
#输出torch.Size([100,128])
第三个:池化层
- 举例:最大池化
maxpool=nn.MaxPool2d(2,2)
#下面代码的第一个参数是样本个数,第二个参数:通道数,第三个参数是H,第四个参数是W
input=torch.randn(100,3,64,64)
output=maxpool(input)
print(output.size())
#输出torch.Size([100,3,32,32])
- 也可以采用Function的方式
F.avg_pool2d(input, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True) → Tensor
input=torch.randn(100,3,64,64)
output=F.max_pool2d(input,2,2)
print(output.size())
#输出torch.Size(100,3,32,32])
第四个:BatchNorm
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- BN层的主要作用是,通过对数据进行标准化,来加速神经网络的训练。
唯一必须设置的参数num_features 要等于输入数据(N,C,H,W)中的C,就是Channel数。 - 例子:
input=torch.randn(100,64,128,128)
bn=nn.BatchNorm2d(64)
output=bn(input)
print(output.size())
#输出torch.Size([100,64,128,128])
常用的激活函数
- 采用Function方式,例子:
data=torch.randn(10)
output=F.relu(data)
- 采用CLASS方式
torch.nn.ReLU
torch.nn.Sigmoid
torch.nn.Tanh
torch.nn.Softmax
- 例子:
data=torch.randn(10)
softmax=nn.Softmax()
output=softmax(data)
损失函数
MSE
torch.nn.MSELoss(size_average=None, reduce=None, reduction=’mean’)
Cross-Entropy
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=’mean’)
用法很简单,把预测值(input)和标签值(target)扔进去就行
例子:
loss_f=nn.CrossEntropyLoss()
#batch_size=8,num_classes=3
x=torch.randn(8,3,required_grad=True)
#一组1维的long类型标签
labels=torch.ones(8,dtype=torch.long)
loss=loss_f(x,labels)
loss.backward()
x.grad
对Cross-entropy需要注意,Target(即label)的值有限制,值的大小需要在[0,C-1]之间。比如,有5个类别,C=5,那么标签值必须在[0,4]之间,不能取其他的数字。
Torch中的激励函数
- 常用的是relu/sigmoid/tanh/
import torch
import torch.nn.functional as F#激励函数都在这
y_relu = F.relu(x).data.numpy()
y_sigmoid = F.sigmoid(x).numpy()
y_tanh = F.tanh(x).numpy()
建立一个神经网络
- 建立一个神经网络可以直接使用torch中的体系,先定义所有层的属性(__ init __()),然后再一层层搭建forward(x)层与层的关系链接。
import torch
import torch.nn.functional as F#激励函数都在这里
class Net(torch.nn.Module):#继承torch的Module
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()#继承__init__功能
#定义每层用什么形式
self.hidden = torch.nn.Linear(n_feature,n_hidden)#隐藏层线性输出
self.predict = torch.nn.Linear(n_hidden,n_output)#输出层线性输出
def forward(self,x):#这个同时也是Module中的forward功能
#正向传播输入值,神经网络分析出输出值
x = F.relu(self.hidden(x))#激励函数(隐藏层的线性值)
x = self.predict(x)#输出值,不是预测值,预测值需要另外计算
return x
net = Net(n_feature=1,n_hidden=10,n_output=1)#几个分类类别就几个output
print(net)#net的结构
训练网络
#optimizer是训练的工具
optimizer = torch.optim.SGD(net.parameters(),lr=0.2)#传入net的所有参数,学习率
loss_func = torch.nn.CrossEntropyLoss()#预测值和真实值的误差计算公式,真实值是1D Tensor(batch),预测值是2D Tensor(batch,n_classes)
for t in range(100):
prediction = net(x)#喂给net训练数据x,输出预测值
loss = loss_func(prediction,y)#计算两者的误差
optimizer.zero_grad()#清空上一步的残余更新参数值
loss.backward()#误差反向传播,计算参数更新值
optimizer.step()#将参数更新值施加到net的parameters上
快速搭建神经网络
- 回顾之间搭建神经网络的通用步骤
class Net(torch.nn.Module):
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(n_feature,n_hidden)
self.predict = torch.nn.Linear(n_hidden,n_output)
def forward(self,x):
x = F.relu(self,hidden(x))
x = self.predict(x)
return x
- 用这种方式搭建net1
net1 = Net(1,10,1)
- 上面的第一步用到class继承了一个torch中的神经网络,然后在上面第二步中进行修改,创建了net1。这两步还可以用下面的方式等同替代,而且下面的方法更简单。
net2 = torch.nn.Sequential(
torch.nn.Linear(1,10),
torch.nn.ReLU(),
torch.nn.Linear(10,1)
)
保存网络
第一种方法:
torch.save(net1,'net.pkl')#保存整个网络
第二种方法:
torch.save(net1.state_dict(),'net_params.pkl')#只保存网络中的参数
提取网络
这种方式会提取整个神经网络,网络大时速度慢
def restore_net():
# 提取整个的net1到net2
net2 = torch.load('net.pkl')
prediction = net2(x)
只提取网络参数
这种方式会提取所有的参数,然后放到你的新建网络中
def restore_params():
#新建net3
net3 = torch.nn.Sequential(
torch.nn.Linear(1,10),
torch.nn.ReLU(),
torch.nn.Linear(10,1)
)
#将保存的参数复制到net3
net3.load_state_dict(torch.load('net_params.pkl'))
prediction = net3(x)
批训练
DataLoader
- Torch中提供了一种整理数据结构的帮手DataLoader。能用来包装自己的数据进行批训练。利用DataLoader将自己的numpy array或者其他的数据形式变换成Tensor,然后再放进这个包装器中,使用DataLoader就是帮助来有效迭代数据。
import torch
import torch.utils.data as Data
torch.manual_seed(1)#reproducible
BATCH_SIZE = 5#批训练的数据个数
x = torch.linspace(1,10,10)#x data(torch tensor)
y = torch.linspace(10,1,10)#y data(torch tensor)
#先转换为torch能识别的Dataset
torch_dataset = Data.TensorDataset(data_tensor=x,target_tensor=y)
#把dataset放入DataLoader
loader = Data.DataLoader(
dataset = torch_dataset,#torch TensorDataset format
batch_size = BATCH_SIZE,#mini bacth size
shuffle = True,#打乱数据
num_workers = 2,#多线程来读数据
)
for epoch in range(3):#训练所有整套数据3次
for step,(batch_x,bacth_y)in enumerate(loader):#每一步loader释放一小批数据来学习
#这里是训练的地方
#打印出来一些数据
print('Epoch:',epoch,'|Step:',step,'|batch x:',
batch_x.numpy(),'|batch y:',batch_y.numpy())
#这条print语句就会打印出类似这样的
#Epoch:0|Step:0|batch x:[6. 7. 2. 3. 1.]|batch y:[5. 4. 9. 8. 10.]
由上面代码中注释出的输出模板可以看出,每一步都导出了5个数据学习,每个epoch的导出数据都是先打乱再导出
加速网络训练的几个方法
-
方法一:SGD
思路是:把数据拆分成小批小批的,分批放入网络中训练。每次使用批数据,虽然不能反应整体情况,但是加速了很多,而且也不会丢失太多准确率。 -
方法二:Momentum
思路:大多数除了SGD外的其他加速训练过程的方法都是在更新神经网络参数那一步上动手脚,传统的W的更新是把原始W累加上一个负的学习率乘以校正值(dx),这种方法会让学习过程曲折无比,摇摇晃晃走了很多弯路。所以把它从平地上放到一个斜坡上,只要它往下坡的方向走一点,由于向下的惯性,所以就不一直往下,这样走的弯路会变少。这就是momentum参数更新。
-
方法三:AdaGrad
思路:这种方法是在学习率上动手脚,使得每一个参数更新都有自己独特的学习率,作用和momentum是一样的,是给它一个不好走路的鞋子,这样使得它摇晃走路就会脚疼,这样鞋子成了走弯路的阻力,逼着它走直路。 -
方法四:RMSProp
思路:是把momentum和adagrad方法结合起来。但是并没有把momentum合并完全。 -
方法五:Adam
思路:是在RMSProp方法中没有合并完全的部分合并了,进行了补全。
Optimizer优化器
- 每个优化器优化一个神经网络
- 为了对比优化器,所有给每个优化器创建各自的神经网络,这些神经网络都来自于同一个Net形式
#默认的network形式
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(1,20)#hidden layer
self.predict = torch.nn.Linear(20,1)#output layer
def forward(self,x):
x = F.relu(self.hidden(x))#activation function for hidden layer
x = self.predict(x)#linear output
return x
#为每个优化器创建一个net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD,net_Momentum,net_RMSprop,net_Adam]
- 创建不同的优化器用来训练不同的网络,并且创建一个loss_func来计算误差。
opt_SGD = torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR,alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))
optimizers = [opt_SGD,opt_Momentum,opt_RMSprop,opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[],[],[],[]]#记录training时不同神经网络的loss
- 训练和画loss-steps图(就是loss随着steps变化的图形)
for epoch in range(EPOCH):
print('Epoch:',epoch)
for step,(b_x,b_y)in enumerate(loader):
#对每个优化器,优化属于它的神经网络
for net,opt,l_his in zip(nets,optimizers,losses_his):
output = net(b_x)#get output for every net
loss = loss_func(output,b_y)#compute loss for every net
opt.zero_grad()#clear gradients for next train
loss.backward()#backpropagation,compute gradients
opt.step()#apply gradients
l_his.append(loss.data.numpy())#loss recoder
- 并不是越先进的优化器效果越佳,不同的场合下有不同的适用的优化器,这是需要自行调试的。
搭建CNN模型
- 和以前一样,用一个class来建立CNN模型,建立CNN模型的整体流程是:
- 第一步:卷积Conv2d
- 第二步:激励函数ReLU
- 第三步:最大池化
- 第四步:再来一遍
- 第五步:展开多维的卷积形成的特征图
- 第六步:接入全连接层
- 第七步:输出
这个过程和构建的代码需要好好体会
class CNN(nn.Module):
def __init__(self):
super(CNN.self).__init__()
self.conv1 = nn.Sequential(#input shape(1,28,28)
nn.Conv2d(
in_channels = 1,#input height
out_channel = 16,#n_filters
kernel_size = 5,#filter size
stride = 1,#filter movement/step
padding =2,#如果想要conv2d出来的图片长宽没有变化,padding=(kernel_size-1)/2 当stride=1
),#output shape(16,28,28)
nn.ReLU(),#activation
nn.MaxPool2d(kernel_size=2)#在2x2空间里向下采样,output shape(16,14,14)
)
self.conv2 = nn.Sequential(#input shape(16,14,14)
nn.Conv2d(16,32,5,1,2)#output shape(32,14,14)
nn.ReLU(),#activation
nn.MaxPool2d(2)#output shape(32,7,7)
)
self.out = nn.Linear(32*7*7,10)#fully connected layer,output 10 classes
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0),-1)#展平多维的卷积图形成(batch_size,32*7*7)
output = self.out(x)
return output
cnn = CNN()
print(cnn)#net architecture
#最后会输出这样的结果
CNN (
(conv1): Sequential (
(0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU ()
(2): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))
)
(conv2): Sequential (
(0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU ()
(2): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))
)
(out): Linear (1568 -> 10) 其中1568=32*7*7
)
接着上面搭建网络的代码,下面是训练的代码
- 将x和y都用variable包起来,然后放入cnn中计算output,最后再计算误差。
optimizer = torch.optim.Adam(cnn.parameters(),lr=LR)#optimize all cnn parameters
loss_func = nn.CrossEntropyLoss()#the target label is not one-hotted
#training and testing
for epoch in range(EPOCH):
for step,(b_x,b_y)in enumerate(train_loader):#分配batch data,normalize x when iterate train_loader
output = cnn(b_x)#cnn output
loss = loss_func(output,b_y)#cross entropy loss
optimizer.zero_grad()#clear gradients for this training step
loss.backward()#backpropogation,compute gradients
optimizer.step()#apply gradients
pytorch搭建普通的RNN
class RNN(nn.Module):
def __init__(self):
self.rnn = nn.RNN(#普通的RNN
input_size = 1,
hidden_size = 32.#rnn hidden unit
num_layers = 1,#有几层RNN layers
batch_first = True,#input&output会是以batch size为第一维度的特征集,例如(batch,time_step,input_size)
)
self.out = nn.Linear(32,1)
def forward(self,x,h_state):#因为hidden state是连续的,所以要一直传递这一个state
#x(batch,time_step,input_size)
#h_state(n_layers,batch,hidden_size)
#r_out(batch,time_step,output_size)
r_out,h_state = self.rnn(x,h_state)#h_state也要作为RNN的一个输入
outs = []#保存所以时间点的预测值
for time_step in range(r_out.size(1))#对每一个时间点计算output
outs.append(self.out(r_out[:,time_step,:]))
return torch.stack(outs.dim = 1),h_state
rnn = RNN()
print(rnn)
#输出如下
RNN (
(rnn): RNN(1, 32, batch_first=True)
(out): Linear (32 -> 1)
)
pytorch搭建LSTM RNN循环神经网络
- LSTM RNN是为了解决RNN存在的弊端而产生的,LSTM即long short-term memory长短期记忆
- RNN是在有序的数据上学习的,RNN会像人一样产生对先前数据的记忆,但是一般形式的RNN很健忘,记忆力弱。普通RNN没办法回忆起久远记忆的原因是因为存在梯度爆炸,把RNN撑死(当w值大于1时)或者是存在梯度消失(当w值小于1)。
- LSTM RNN比普通的RNN多出了三个控制器,输入控制,输出控制,忘记控制。参考:视频很形象
- 和构建CNN一样,用一个class来建立RNN模型,构建RNN的流程如下:
- 第一步:(input0, state0) -> LSTM -> (output0, state1);
- 第二步:(input1, state1) -> LSTM -> (output1, state2);
- 第三步:…
- 第四步:(inputN, stateN)-> LSTM -> (outputN, stateN+1);
- 第五步:outputN -> Linear -> prediction.
class RNN(nn.Module):
def __init__(self):
super(RNN,self).__init__()
self.nn = nn.LSTM(
input_size = 28,#图片每行的数据像素点
hidden_size = 64,#rnn hidden unit
num_layers = 1,#有几层RNN layers
batch_first = True,#input&output会是以batch size为第一维度的特征集,例如(batch, time_step, input_size)
)
self.out = nn.Linear(64,10)#输出层
def forward(self,x):
#x shape(batch,time_step,input_size)
#r_out shape (batch,time_step,output_size)
#h_n shape(n_layers,batch,hidden_size) LSTM有两个hidden status,h_n是分线,h_c是主线
#h_c shape (n_layers,batch,hidden_size)
r_out,(h_n,h_c)=self.rnn(x,None)#None表示hidden state会用全0的state
#选取最后一个时间点的r_out输出
#这里r_out[:,-1,:]的值也是h_n的值
out = self.out(r_out[:,-1,:])
return out
rnn = RNN()
print(rnn)
#会输出这样
RNN (
(rnn): LSTM(28, 64, batch_first=True)
(out): Linear (64 -> 10)
)
训练LSTM RNN的过程
- 将图片数据看成一个时间上的连续数据,每一行的像素点都是这个时刻的输入,读完整的一张图片就是从上而下的读完了每行的像素点,然后就可以拿出RNN在最后一步的分析值判断图片是哪一类。
optimizer = torch.optim.Adam(mn.parameters(),lr=LR)#optimize all parameters
loss_func = nn.CrossEntropyLoss()#the target label is not one-hotted
#training and testing
for epoch in range(EPOCH):
for step,(x,b_y)in enumerate(train_loader):#gives batch data
b_x = x.view(-1,28,28)#reshape x to (batch,time_step,input_size)
output = rnn(b_x)#rnn output
loss = loss_func(output,b_y)#cross entropy loss
optimizer.zero_grad()#clear gradients for this training step
loss.backward()#backpropagation,compute gradients
optimizer.step()#apply gradients
非监督学习即自编码autoencoder
- 神经网络要接受大量输入信息,比如输入信息是高清图片时,输入信息量可以达到上千万,让神经网络直接从上千万个信息源中学习是一件吃力事情。所以可以先压缩,提取出原图片中的最具有代表性的信息,缩减输入信息量,再把压缩过后的信息放入神经网络学习。使得学习变轻松。此时自编码发挥作用,通过将原数据(如下图的白色X压缩,然后再解压成黑色X,通过对比黑白色的X,求出预测误差,反向传递,逐步来提升自编码准确性。
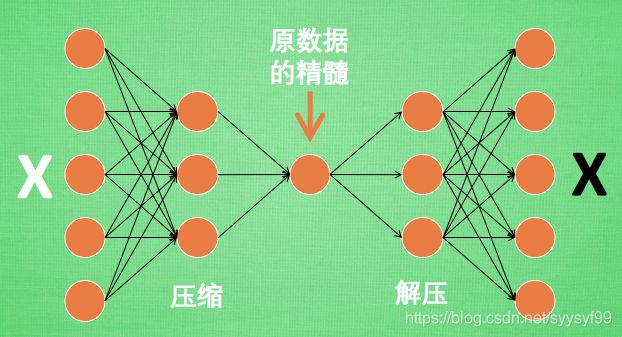
- 上图中自编码中间这一部分就是能总结原数据的精髓,从头到尾,只用到了输入数据X,并没有用到X对应的数据标签,所以自编码是一种非监督学习。真正使用自编码时,只会用到自编码的前半部分。叫做编码器。
- 只需要创建小神经网络学习这个精髓的数据,不仅减少了神经网络的负担,同样达到很好效果。
- 自编码能够像PCA一样给特征属性降维。
- 解码器在训练的时候将精髓信息解压成原始信息,这就提供了解压器的作用,可以认为是一个生成器,类似于GAN。
- 自编码能自动分类数据,也能嵌套在半监督学习的上面,用少量的有标签样本和大量的无标签样本学习。
强化学习网络DQN
- Deep Q Network简称DQN
- 神经网络接受外部的信息,相当于眼睛鼻子嘴巴收集信息,通过大脑加工输出每种动作的值,最后通过强化学习来选择动作。
- 强化学习有一个记忆库用于学习之前的经历,强化学习是一种离线学习法,能学习当前经历的,也能学习过去经历的,甚至是学习别人的经历。所以每次强化学习更新的时候,都可以随机抽取一些之前的经历学习,随机抽取这种做法打乱了经历之间的相关性,使得神经网络更新地更有效率。Fixed Q-targets也是一种打乱相关性的机理,使用fixed Q-targets就会在强化学习中使用两个结构相同但是参数不同的神经网络,预测Q估计的神经网络具备新的参数,而预测Q现实的神经网络使用的参数是很久以前的,有了这两种手段,强化学习才能在游戏中超越人类。
神经网络分为很多种,有普通的前向传播神经网络,有分析图片的CNN卷积神经网络,有分析序列化数据,比如语音的RNN循环神经网络,这些神经网络都是用来输入数据,得到想要的结果,这些神经网络能很好的将数据与结果通过某种关系联系起来。如下图,第一个普通前向传播神经网络,第二个CNN,第三个RNN。

生成对抗网络GAN
- generative adversarial nets
- 这种网络与之前讲过的网络都不同,不像CNN,不像RNN,不像普通前向传播神经网络。GAN不是用来把数据对应上结果的。GAN是凭空捏造结果。GAN只是生成网络中的一种形式。
- GAN的一部分利用没有意义的随机数生成有意义的作品。GAN的另一部分需要找一个新手鉴赏家。可是新手鉴赏家还是个新手,所有你就需要给数据几个标签,然后新手鉴赏家经过几个标签的训练后,慢慢学会怎么区分著名画家的画。新手鉴赏家将从你这里(给了一些标签)学到的分享给新手画家(GAN的一部分),让新手画家画的越来越像名家。这就是GAN的流程。
- 整理GAN的流程:新手画家用随机灵感画画 , 新手鉴赏家会接收一些画作, 但是他不知道这是新手画家画的还是著名画家画的, 他说出他的判断, 你来纠正他的判断, 新手鉴赏家一边学如何判断, 一边告诉新手画家要怎么画才能画得更像著名画家, 新手画家就能学习到如何从自己的灵感画出更像著名画家的画了。
- 下图中,Generator 会根据随机数来生成有意义的数据 , Discriminator 会学习如何判断哪些是真实数据 , 哪些是生成数据, 然后将学习的经验反向传递给 Generator, 让 Generator 能根据随机数生成更像真实数据的数据. 这样训练出来的 Generator 可以有很多用途, 比如最近有人就拿它来生成各种卧室的图片.
- 应用:让图片来做加减法, 戴眼镜的男人 减去 男人 加上 女人, 他居然能生成 戴眼镜的女人的图片. 甚至还能根据你随便画的几笔草图来生成可能是你需要的蓝天白云大草地图片

GAN的pytorch实现
- 需要创建两个神经网络,Generator新手画家和Discriminator新手鉴赏家。简称G和D。
- 下面创建的网络实现G会拿自己的灵感当输入,输出一元二次曲线上的点(G的画)
- 实现:D会接受一幅画作(一元二次曲线),输出这幅画是不是著名画家的画(是著名画家的画的概率)
G = nn.Sequential(#Generator
nn.Linear(N_IDEAS,128)#random ideas (could from normal distribution)
nn.ReLU(),
nn.Linear(128,ART_COMPONENTS),#making a plainting from these random ideas
)
D = nn.Sequential(#Discriminator
nn.Linear(ART_COMPONENTS,128)#receive art work either from the famous artists or a newbie like G
nn.ReLU(),
nn.Linear(128,1),
nn.Sigmoid(),#tell the probability that the art work is made by artist
)
过拟合的解决办法:
- 增加数据量
- L1 L2 regularization等。W为机器需要学习到的各种参数。在过拟合中,W的值往往会变得特别大或者特别小。为了不让W变化太大所以在计算误差时做手脚。原始的误差是预测值减去真实值后差值的平方。所以如果W变得太大,所以就让误差也跟着变大,变成一种惩罚机制。L1 L2正则化就是这样的思想。
- 专门在神经网络上使用的正规化方法:dropout,训练时,随机忽略一些神经元和神经联结,使这个神经网络变得不完整,用一个不完整的神经网络训练一次。第二次再随机忽略一些,变成另一个不完整的神经网络,有了随机drop的规则,那么每次训练的时候,都让每一次预测结果都不会依赖其中某部分特定神经元,类似于:被过度依赖的W值(训练参数值)会变得很大,所以L1 L2正则化的思想就是惩罚这些变得很大的W值,而dropout的思想是从根本上让神经网络没有机会过度依赖。
具有统一规格的数据能够让机器更容易学习到数据中的规律,在输入层的时候,神经网络有可能在初始阶段已经不对那些比较大的x特征范围敏感了,这是很糟糕的,解决办法是对数据做normalization预处理,使得输入的x变化范围不会太大,从而使得输入值能够经过激励函数的敏感部分。但是这个不敏感的问题不仅仅发生在输入层,还在隐藏层中发生,这时的解决办法是batch normalization。batch normalization是把数据分成小批进行随机梯度下降(stochastic gradient descent)。而且在每批数据前向传递时,对每一层normalization处理。batch normalization也可以看成一个层面,在一层层添加神经网络的时候,先有数据x,再添加全连接层,全连接层的计算结果会经过激励函数成为下一层的输入,接着重复之前的操作,batch normalization就被添加到每一个全连接层和激励函数之间。
构建带有BN的神经网络
class Net(nn.Module):
def __init__(self,bacth_normalization=False):
super(Net,self).__init__()
self.do_bn = bacth_normalization
self.fcs = []
self.bns = []
self.bn_input = nn.BatchNorm1d(1,momentum = 0.5)#给input的BN
for i in range(N_HIDDEN):#建层
input_size = 1 if i == 0 else 10
fc = nn.Linear(input_size,10)
setattr(self,'fc%i' % i,fc)#注意pytorch一定要你将层信息转换为class的属性
self._set_init(fc)#参数初始化
self.fcs.append(fc)
if self.do_bn:
bn = nn.BatchNorm1d(10,momentum=0.5)#momentum的作用是平滑化batch mean和stddev
setattr(self,'bn%i' % i,bn)
self.bns.append(bn)
self.predict = nn.Linear(10,1)#output layer
self._set_init(self.predict)#参数初始化
def _set_init(self,layer):#参数初始化
init.normal_(layer.weight,mean=0.,std=.1)
init.constant_(layer.bias,B_INIT)
def forward(self,x):
pre_activation = [x]
if self.do_bn:x=self.bn_input(x)#判断是否要加BN
layer_input = [x]
for i in range(N_HIDDEN):
x = self.fcs[i](x)
pre_activation.append(x)#为之后出图
if self.do_bn:x = self.bns[i](x)#判断之后是否要加BN
x = ACTIVATION(x)
layer_input.append(x)#为之后出图
out = self.predict(x)
return out,layer_input,pre_activation
#建立两个net,一个有BN。一个没有BN
nets = [Net(batch_normalization = False),Net(batch_normalization = True)]