联邦学习和去中心化训练--知识记录
一、知识点:
1、原子操作(atomic operation)指的是由多步操作组成的一个操作。如果该操作不能原子地执行,则要么执行完所有步骤,要么一步也不执行,不可能只执行所有步骤的一个子集。
2、联邦学习为移动设备上的模型共享创造可能,模型训练与云端存储解耦,移动端存储训练数据,并进行模型训练和进化。
联邦学习机理如下:设备下载云端最新的共享模型,本地改进和训练,个性化后的模型被抽取为一个更新文件,将差异部分加密上传云端,在云端和其它设备上传的最新模型差异做平均化更新,以改善共享模型。
网络的上传速度通常比下载速度慢,谷歌开发出一种新颖的算法:“random rotations and quantization”,将上传更新的通信速度提升为原来的100倍。这些算法都聚焦在深度学习的训练上,还针对点击率预测的问题设计出了“high-dimensional sparse convex"模型。
3、差分隐私
差分隐私是用来防范差分攻击的,我们对加入新样本后的结果查询中加入噪声,使得攻击者无法辨别某一样本是否在数据集中,即达到双兔傍地走安能辨我是雄雌的境地。
4、智能合约,类似于实际合同效力,在计算机语言描述和实现,在没有第三方参与的情况下进行合约的触发和执行。
智能合约区别于传统合约:
1)合约的触发与执行合二为一次原子操作
2)去中心化和自动化地合约流程,无须第三方中心机构的介入。
5、横向和纵向联邦学习
横向联邦学习适用于联邦学习的参与方的数据有重叠的数据特征,即数据特征在参与方之间是对齐的,参与方数据样本不同。纵向联邦学习 适用于联邦学习参与方的训练数据有重叠的数据样本,即参与方之间的数据样本对齐的,但数据特征上不同。


二、钱学海团队的研究成果:
1、钱学海认为,分布式训练系统的核心问题是不同计算设备的通信以及由于计算和通讯性能的差异带来的异构性,具体可以看做面临三个方面的挑战,分别是:通信(Communication)、异构性(Heterogeneity)和多因素交互的复杂性 (Complex Trade-offs )。
(1)通信:早期分布式训练是一个中心化结构,每一个worker会把自己计算得到的梯度上传到中心节点,中心节点对all worker 的梯度平均化处理,再传回各个worker。存在中心节点通信瓶颈问题;第二代分布式训练系统结构是Ring-All-Reduce,节点同步环+并行流水线工作机制,通信更加高效,但当每个worker的运行性能差距较大时,系统性能受限于运行效率最低的worker。
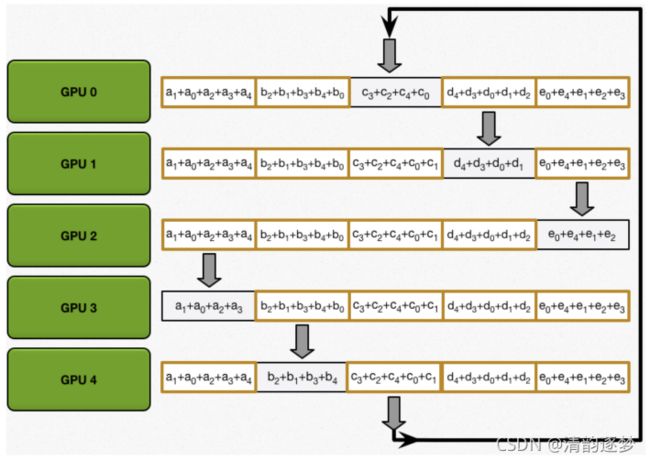
Ring All-Reduce系统结构
(2)异构性:确定异构性(Deterministic heterogeneity)和 动态异构性(Dynamic heterogeneity )。确定异构性是指不同的设备通常有不同的计算能力(比如:采用不同的GPU或 TPU系列),并且设备或节点具有不同的网络通信性能。动态异构性是由资源共享造成的,即同一个设备对不同的应用提供的计算性能不同。分布式训练系统下会产生Slow Worker,被称为Straggler。Straggler问题亦称之为异构性问题,即平台上Worker具有不同的运行性能时,整个系统的性能受限于运行效率最低的Worker。
(3)复杂性:全局考量系统设计,如考虑并行性与通信之间的关系,一般采用Data Parallelism 和 Model Parallelism
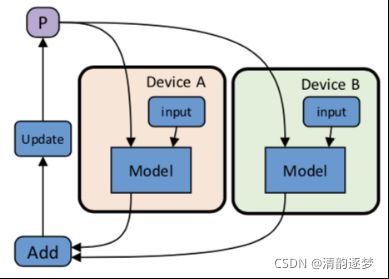
Data Parallelism
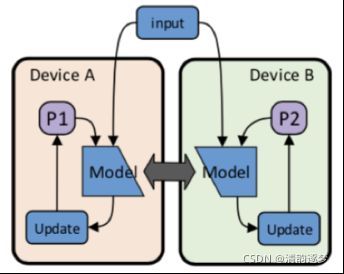
Model Parallelism
2、去中心化的分布式训练
去中心化方法下,可定义任意模式的通信图。提供了一个更灵活的通讯方式。每一个节点的运行过程如下:
根据Min-batch数据和当前的模型进行梯度计算,并更新模型;
把参数发送给“邻居”Worker;
接收其他Worker的参数,并进行Reduce操作;
更新模型参数,进入下一个Iteration。
此训练中的同步是指每个Worker在做Reduce操作时,所有的参数应该出自同一个Iteration。这是在构建去中心化分布式训练系统中独特的一个问题,在PS和Ring All-Reduce中都不存在这样的问题,因为它们有一个非常自然的中心节点或者有一个同步的操作去划分Iteration。

PS和Ring All-Reduce
3、 基于同步算法的去中心化分布式训练
基于队列的同步算法(Queue-based Synchronization),该算法应用于同步算法系统设计中,主要解决两个问题:(1)系统应该能够自适应按需分配资源,而不是持续分配资源(2)Backup Worker是解决异构问题的一种技术,它能够控制同步的松紧程度(Bounding Iteration Gap),但会造成无穷大的Iteration gap
基于队列的同步是指每个Worker有两个队列:Update Queue(UQ), 用来存储邻居发送来的信息,Token Queue(TQ), 用来控制同步。假设在部署协议时,设定Iteration Gap的最大容忍是2,则TQ的Token数最大为2。协议开始执行以后,每一个Worker都可以向其他Worker发送参数更新。Worker要想进入下一个Iteration,必须要从邻居的TQ中获取Token放入自己的TQ当中。如果C要进入下一个Iteration,必须先从TQ_A->C和TQ_B->C中获取token,分别放入TQ_C->A和TQ_C->B中。
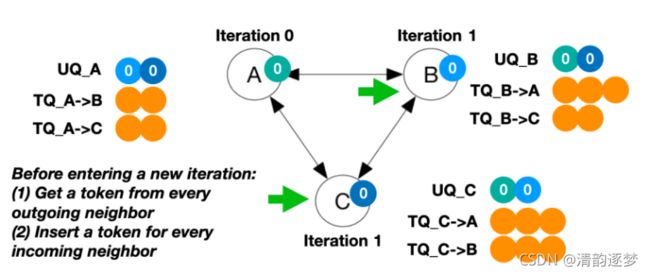
解释上述提到的Backup技术控制Bounding Iteration Gap,设Number of backup = 1,若A出现Slowdown,B和C仍然可继续进行。当B和C进入Iteration(2)之后,由于A仍然在Iteration(0)且A的TQ中已经没有token了,所以B和C也会停止。这样就确定了Iteration gap的边界。这个边界值是由TQ的长度决定的
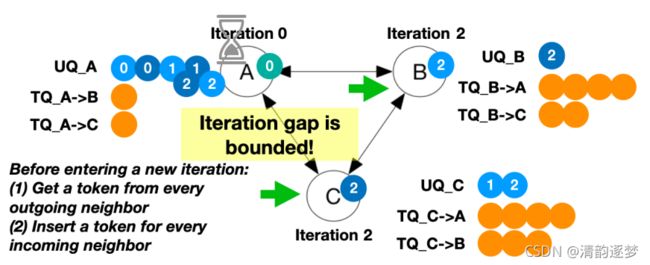
Queue-based Synchronization with backup Worker
4、基于异步算法的去中心化分布式训练
去中心化异步训练算法的代表:深度学习异步去中心化随机梯度下降算法Asynchronous Decentralized Parallel SGD(AD-PSGD),其核心思想是通信的随机性(worker的迭代是随机选择的)以及worker之间进行原子性操作。
原子性操作的两个作用:(1)两个串行操作执行完以后,w(2)的模型更新中也包含w(1)的模型更新,(2)模型的收敛速度会大大提高。
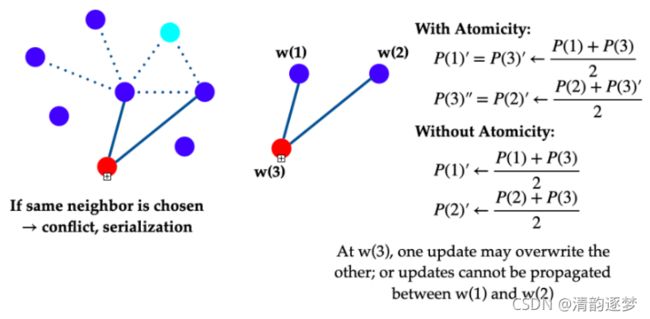
原子性操作也存在弊端,参数大量同步成本,训练过程中,AD-PSGD在不同的数据集上训练的同步开销都比Ring All-Reduce要大。在异构环境下,AD-PSGD的收敛速度比Ring All-Reduce要快;在同构环境下,则相反。
鉴于上述挑战,Partial All-Reduce算法应用于异步算法系统设计中,应运而生,它主要解决两个问题:1)如何让同步操作本身更快;2)如何减少冲突,降低由于串行操作带来的延迟。
概算法的核心思想是worker Group 代替worker 同步,首先,Group Generator 产生不冲突的分组,每个节点一个分组,每个分组内部有一个Head worker进行节点之间的同步,组内同步不需要进行节点之间的通信,避免了网络拥堵的问题。
