详述BERT fine-tune 中文分类实战及预测
这几天在研究bert fine-tune相关的知识,现在基本熟悉了,也踩了一些坑,记录一下,一是总结,二是备忘。
bert 的 finetune 主要存在两类应用场景:分类和阅读理解。因分类较为容易获得样本,以下以分类为例,做模型微调:
环境:python 3.6
tensorflow:1.12(必须>=1.11)
完成中文分类需要有一、bert官方开源的代码,二、bert开源的预训练的中文模型chinese_L-12_H-768_A-12,三、中文分类数据,数据格式为(类别\t句子)
1、模型与代码下载:
1.1 首先clone 官方代码,地址如下:
git clone https://github.com/google-research/bert.git
cd bert
随便放在哪个目录都可以
1.2 bert开源的预训练的中文模型chinese_L-12_H-768_A-12
地址:https://github.com/google-research/bert

2、数据集准备
数据获取地址:data
train.tsv 训练集
dev.tsv 验证集
test.tsv 测试集
第一列为 label,第二列为具体内容,tab 分隔。因模型本身在字符级别做处理,因而无需分词。
tsv文件是类似于csv,只不过分割符号有所区别csv为,,而tsv为\t,即tab键。
注意:链接data中 test为空,我这样处理的:从train.tsv文件中从3个类别分别剪切出来10条数据,放到test里面了,将原来的类型标签全部改成了unknow,然后将后缀改成.tsv,一定要剪切,不然训练集包含了测试集,模型效果就特别好,不准确了。
数据样例:
fashion 衬衫和它一起穿,让你减龄十岁!越活越年轻!太美了!...
houseliving 95㎡简约美式小三居,过精美别致、悠然自得的小日子! 屋主的客...
game 赛季末用他们两天上一段,7.20最强LOL上分英雄推荐! 各位小伙...
3、修改代码
因为是分类问题, 所以我们需要修改run_classifier.py(bert源码文件)
3.1 加入新的处理类
因为我们是做一个分类的任务, 里面自带4个任务的处理类, 其中ColaProcessor是单句分类,和我们的任务较为相近, 所以我们模仿这个类,写一个自己的处理类。
class DemoProcessor(DataProcessor):
"""Processor for the Demo data set."""
def __init__(self):
self.labels = set()
def get_train_examples(self, data_dir):
"""定义训练集的数据,文件名需要根据自己的实际情况修改"""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""定义验证集的数据,文件名需要根据自己的实际情况修改."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""定义测试集的数据,文件名需要根据自己的实际情况修改."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""这里是分类的标签,根据实际情况修改,我这里是3类"""
return ["fashion","houseliving","game"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets.
这个函数是用来把数据处理, 把每一个例子分成3个部分,填入到InputExample的3个参数
text_a 是第一个句子 的文本数据
text_b是第二个句子的文本,但是由于此任务是单句分类, 所以 这里传入为None
guid 是一个二元组 第一个表示此数据是什么数据集类型(train dev test) 第二个表示数据标号。
label 表示句子类别
"""
examples = []
for (i, line) in enumerate(lines):
# Only the test set has a header
if set_type == "test" and i == 0:
continue
guid = "%s-%s" % (set_type, i)
#print(line,i) # 这里可以用来打印调试用,我是通过打印发现错误了的
if set_type == "test":
'''获取测试集 text ,我这里 第一列和第二列分别是 类别 文本 所以根据自己数据集情况添加'''
text_a = tokenization.convert_to_unicode(line[1])
label = "houseliving"
'''测试时候这个label 从自己类别随便选一个,有人说可以随便写,比如label = "0",我测试的时候这样写报错。'''
else:
''' 获取训练/验证集 text ,我这里 第一列和第二列分别是 类别 文本 所以根据自己数据集情况添加'''
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
3.2 处理类注册
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"demo": DemoProcessor
}
我们需要在主函数里把我们的类当做参数选项,给他加个选项, 也就是当参数填demo时,使用的数据处理类是我们自己写的处理类。注意名字一定对应上,不要写错。
4、运行代码
4.1 声明环境变量,当然你也可以不声明,后面执行代码的时候使用绝对路径
export BERT_Chinese_DIR=/path/to/bert/chinese_L-12_H-768_A-12
export Demo_DIR=/path/to/data
注意:我这里是在根目录下创建了path文件夹,在其下创建了/to/bert/,把之前下载的预训练模型文件夹chinese_L-12_H-768_A-12放进去了,把数据集放在了/path/to/data,可以根据实际情况修改上面的环境变量路径。
4.2 运行代码:
python run_classifier.py \
--task_name=demo \
--do_train=true \
--do_eval=true \
--data_dir=$Demo_DIR \
--vocab_file=$BERT_Chinese_DIR/vocab.txt \
--bert_config_file=$BERT_Chinese_DIR/bert_config.json \
--init_checkpoint=$BERT_Chinese_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/Demo_output
task_name 表示我调用的是什么处理类,这里需要修改成我们新的定义的demo,
文件dir 可以自己定义, 如果无定义到会出错, 我这里是有3个文件夹BERT_Chinese_DIR 里面放预训练模型, Demo_DIR放的是数据集,/tmp/Demo_output里面放结果。
4.3 fine-tune结果
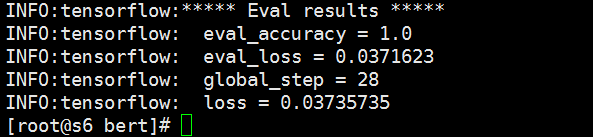
5、使用fine-tune结果预测
5.1 修改参数预测
python run_classifier.py \
--task_name=demo \
--do_predict=true \
--data_dir=$Demo_DIR \
--vocab_file=$BERT_Chinese_DIR/vocab.txt \
--bert_config_file=$BERT_Chinese_DIR/bert_config.json \
--init_checkpoint=/tmp/Demo_output \
--max_seq_length=128 \
--output_dir=/tmp/test_output
把原来训练时的do_train=true ,do_eval=true 删除,改成do_predict=true ,特别需要注意的一点是:init_checkpoint改成自己fine-tune后保存的模型,init_checkpoint=/tmp/Demo_output,这里/tmp/Demo_output是之前执行训练的时候的输出结果路径。
5.2 中文分类测试结果
在测试输出目录里已输出了一个test_results.tsv文件
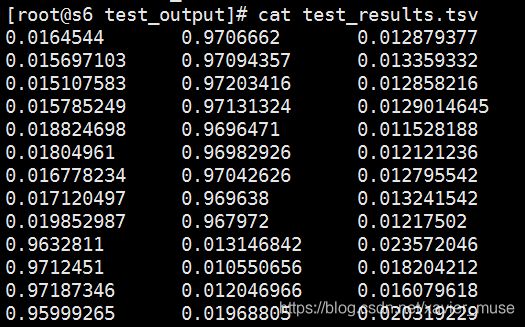
3分类,之前设置的类别对应为[“fashion”,“houseliving”,“game”],每一行代表类别的概率。
参考:
https://www.jianshu.com/p/695e8877eca5
https://blog.csdn.net/qq874455953/article/details/90276116