2021-IEEE论文-深度神经网络在文档图像表格识别中的应用现状及性能分析
2021年5月12日收到,
2021年6月4日接受,
出版日期2021年6月9日,
当前版本日期2021年6月24日。
原论文下载地址
摘要 - Abstract
表格识别的第一阶段是检测文档中的表格区域。随后,在第二阶段识别表格结构,以便从各个单元中提取信息。表格检测和结构识别是表格理解领域的关键问题。然而,由于表格中存在大量的多样性和不对称性,导致了表格分析是一项复杂的任务,因此它是文档图像分析中一个活跃的研究领域。图形处理单元计算能力的最新进展使深度神经网络的性能优于传统的最先进的机器学习方法。表格理解从深度神经网络的最新突破中受益匪浅。然而,对于表检测和表结构识别的深度学习方法还没有统一的描述。本文对利用深度神经网络的现代方法进行了全面分析。此外,它还全面了解了文档图像中表格理解的最新技术和相关挑战。主要的数据集及其复杂性已与定量结果一起阐述。此外,简要概述了可以进一步改进文档图像中的表分析的有希望的方向。
1.引言 - Introduction
自过去十年以来,表格理解已经获得了巨大的吸引力。表格是表示和传递结构化数据的常用方法[1]。随着深度神经网络(DNN)的兴起,各种用于表格检测、分割和识别的数据集已经发表[2],[3]。这使得研究人员能够利用深度神经网络DNN来改善最先进的结果。
以前,表格识别问题一直是用传统方法处理的[4]–[7]。Kieninger和Dengel[8]、Kieninger[9]、Kieninger和Dengel[10]完成了表格分析领域的早期工作之一。除了检测表格区域,他们的系统 T-Recs 还提取表格的结构信息。
后来,机器学习技术被应用于检测表格。其中一位先驱是塞萨里尼等人[11]。他们提出的系统 Tabfinder 将文档转换为MXY树,MXY树是文档的分层表示。它在水平和垂直平行线上搜索一个块区域,然后深度优先搜索处理有噪声的文档图像,得到一个表格区域。e.Silva[12]采用了丰富的隐马尔可夫模型,基于联合概率分布来检测表格区域。
支持向量机(SVM)[13]与一些手工制作的功能一起被用来检测表[14]。Fan和Kim[15]试图通过融合各种分类器来检测表格,这些分类器根据文档的语言和布局信息进行训练。 Tran等人[16]的另一项工作使用感兴趣区域ROI来检测文档图像中的表格。如果 ROI 中的文本块满足特定的规则集,则这些区域将作为表格进一步过滤。
Wang等人[17]进行了全面的研究,不仅关注表检测问题,还关注表分解问题。他们基于概率优化的算法类似于著名的X-Y切割算法[18]。Shigarov等人[19]发布的系统利用单词的边界框来恢复表的结构。由于该系统严重依赖元数据,作者采用PDF文件来执行该实验。
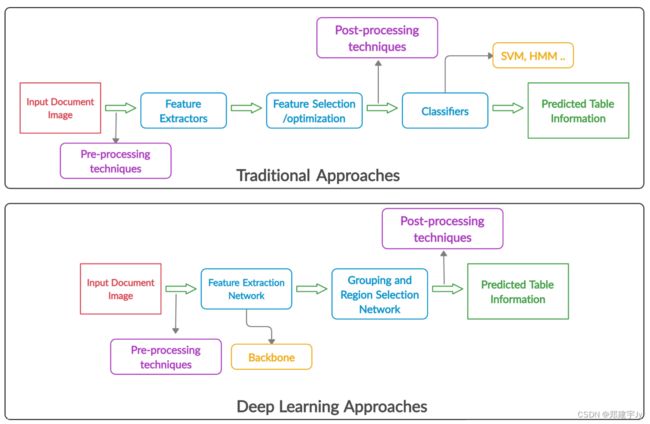
图1:表分析的传统和深度学习方法的传递路径的比较。传统方法中的特征提取主要通过图像处理技术实现,而卷积网络则用于深度学习技术。与传统方法不同,用于表格理解的深度学习方法不依赖于数据,并且具有更好的泛化能力。
图1描述了传统方法和深度学习方法在表格理解过程中的标准传递路径(pipeline)比较。传统的表格识别系统要么在不同的数据集上不够通用,要么需要PDF文件中的额外元数据。在大多数传统方法中,为了提高传统表格识别系统的性能,还采用了穷举前后处理。然而,在深度学习系统中,神经网络主要是卷积神经网络[20] 被用于提取特征,取代了手工提取特征。随后,目标检测或分割网络试图区分在文档图像中进一步分解和识别的表格部分。
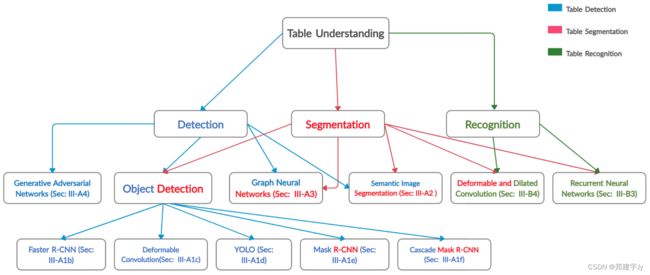
图2:论文中解释的方法的组织。用蓝色书写的概念代表表格检测技术。红色的方法展示了表格分割或表格结构识别方法,而绿色的体系结构描述了表格识别方法,该方法涉及表格中单元格内容的提取。如图所示,一些体系结构已被用于多个表理解任务。
文本文档可分为两类。第一类属于born-digital(原生数字)文档,它不仅包含文本,还包含布局信息等相关元数据。PDF文档就是这样一个例子。第二类文件是使用扫描仪和摄像头等设备获取的。据我们所知,目前还没有一项值得注意的研究将深度学习应用于相机拍摄图像中的表格识别。然而,在文献中,有一种基于启发式的方法[21]适用于摄像机捕获的文档图像。本次调查的范围是评估对扫描文档图像执行表格识别的基于深度学习的方法。
本文的结构如下:第二节讨论了以往在表格理解领域的调查。第三节详细讨论了利用深度学习概念解决表格分析的几种方法。图2解释了上述方法的结构流程。第四节描述了表格分析中公开的数据集。 第五节解释了著名的评估指标,并提供第三节中讨论的所有方法的性能分析。第六节总结了讨论,而第七节强调了各种悬而未决的问题和未来的方向。
2.相关工作 - Related Work

图3:图表分析领域的增长趋势说明。这些数据是通过查阅2015年至2019年关于表格检测和表格识别的年度出版物收集的。
表格分析问题多年来一直是一个公认的问题。图3显示了过去5年中出版物数量的增长趋势。由于这是一篇综述文章,我们想对 table 社区中已有的以前的调查和综述做一些说明。在他的一本书中的文档识别一章中,Dougherty定义了表[22]。在关于文档识别的调查中,Handley[23]阐述了表格识别的任务,并对该领域以前所做的工作进行了精确的解释。后来,Lopresti和Nagy[24]介绍了关于表格理解的调查,他们在调查中讨论了不同类型表格中的异质性。他们还指出了可以利用许多例子进行改进的潜在领域。这项综合调查被转化为表格形式,后来作为一本书出版[25]。
Zanibbi等人[26]提出了详尽的调查,其中包括当时所有最新的材料和最先进的方法。他们将表格识别问题定义为“模型、观察、转换和推理的交互作用”[27]。赫斯特在他的博士论文[28]中定义了表格的解释。e.Silva等人[29]在2006年发表了另一项调查。在评估现有表处理算法的同时,作者提出了自己的端到端表处理方法和评估指标,以解决表结构识别问题。
Embley等人[27]写了一篇综述,阐述了表格处理范式。2014年,Coüasnon和Lemaitre发表了另一篇关于表格识别和表格的评论[30]。该综述简要概述了当时的最新方法。在接下来的一年里,据我们所知,Khusro等人[31]发表了关于检测和提取PDF文档中表格的最新评论。
3.方法论 - Methodologies
如[32]所述,我们还将表格理解问题定义为三个步骤:
A.表格检测:根据文档图像中的边界框检测表格边界。
B.表结构分段:通过分析行和列布局信息来定义表的结构。
C.表格识别:包括表格单元格的结构分段和解析信息。
A. 表格检测 - TABLE DETECTION

图4:表检测的基本流程以及所讨论的方法中使用的方法。为了定位表格边界,文档图像通过各种深度学习架构传递。
从表格中提取信息的第一部分是识别文档图像中的表格边界[33]。图4解释了在许多方法中讨论过的表检测的基本流程。各种深度学习概念已被用于从文档图像中检测表格区域。本节回顾了用于在文档图像中执行表检测的深度学习技术。为了给读者提供方便,我们将这些方法分为离散的深度学习概念。表1总结了所有基于对象检测的表检测方法,而表2强调了应用其他基于深度学习技术的方法的优点和局限性。
根据我们的知识,Hao等人[34]提出了第一种采用深度学习方法解决表格检测任务的方法。除了使用卷积神经网络提取图像特征外,作者还利用PDF元数据应用了一些启发式方法。由于该技术基于PDF文档,而不是依赖文档图像,因此我们决定在性能分析中不包括这项研究。

表1:总结了基于对象检测框架的各种基于深度学习的表格检测方法的优点和局限性。

表2:总结了各种表格检测方法的优点和局限性。本表中的方法基于基于深度学习的概念,而非目标检测算法。粗体的水平线将不同架构的技术分隔开来。
1) 目标检测算法 - OBJECT DETECTION ALGORITHMS
目标检测是深度学习的一个分支,涉及在任何图像或视频帧中检测目标。基于区域的目标检测算法主要分为两步:第一步是生成合适的方案,也称为感兴趣区域。在第二步中,使用卷积神经网络对这些感兴趣的区域进行分类。
a:迁移学习 - TRANSFER LEARNING
迁移学习的概念是对属于不同但相关领域的问题使用预先训练的模型[35]。由于可用标记数据集的数量有限,迁移学习在基于视觉的方法中被过度使用[36]–[39]。出于类似的原因,文档图像分析社区的研究人员也增强了迁移学习的能力,以推进他们的方法[40]–[42]。转移学习的能力帮助研究人员在文档图像中的表格检测和表格结构识别问题上重用预先训练过的网络(在ImageNet[20]或COCO[43]上训练过)。而第3-A1节.b、 3-A1.c和3-A1.f解释了基于迁移学习的表格检测方法,第3-B5节阐述了将迁移学习用于表格结构识别任务的技术。
b: FASTER R-CNN
在将目标检测算法从Fast R-CNN[54]改进为Faster R-CNN[55]后,表格被视为文档图像中的一个对象。Gilani等人[44]对图像采用深度学习方法来检测表格。该技术将图像转换作为一个预处理步骤,然后进行表格检测。在图像变换部分,将二值图像作为输入,在其上分别对图像的蓝色通道、绿色通道和红色通道应用欧氏距离变换[56]、线性距离变换[57]和最大距离变换[58]。后来,吉拉尼等人[44]使用了一种基于区域的物体检测模型,称为Faster R-CNN[55]。其区域生成网络(RPN)的主干网基于ZFNet[59]。他们的方法能够在UNLV数据集[2]上击败最先进的结果。
Schreiber等人[45]利用深度学习的能力对文档图像执行了一项工作。他们的端到端系统 DeepDeSRT 不仅可以检测表格区域,还可以区分表格的结构,这两项任务都是通过应用独特的深度学习技术。
通过使用Faster R-CNN[55]实现了表格检测。他们试验了两种不同的架构作为骨干网络(backbone):Zeiler和Fergus(ZFNet)[59]和deep VGG-16网络[60]。模型是在Pascal VOC[61]数据集上预先训练的。第3-B节解释了结构分割的方法。
随着图形处理单元(GPU)内存的增加,为更大的公共数据集创造了空间,以充分利用GPU的功能。Li等人[62]理解了这一需求,并提出了TableBank,其中包含417K标记的表格及其各自的文档图像。他们还通过使用Faster R-CNN[55]来完成表格检测任务,提出了基线模型。作者还提出了一种结构识别的基线方法,这将在后面的第3-B节中解释。
在ICDAR 2019年会议上提出的另一项研究中,使用Faster R-CNN组合检测表格,并使用定位角点方法进一步改进表格[63]。作者将角定义为围绕表格顶点绘制的大小为80×80的正方形。除了定位表的边界外,还可以使用同样Faster R-CNN模型检测角点。
这些角点在经过各种试探后会进一步细化,就像两个连续的角点位于同一条水平线上一样。在分析角点后,不准确的角点会被过滤并留下来形成一个组。作者认为,大多数情况下,表格边界的不准确是因为与边界的顶部和底部相比,边界的左侧和右侧检测不准确。因此,在本实验中,仅对检测到的表的右侧和左侧进行细化。通过计算表与表之间的并集的交点,首先找到表的相应角点,从而进行细化。随后,通过获取表格边界和相应角点之间的平均值来移动表格的水平点。本文在ICDAR 2017页面对象检测数据集[64]上进行了一项实验,并报告与传统Faster R-CNN方法相比,F-measure增加了2.8%。
c: 可变形卷积 - DEFORMABLE CONVOLUTIONS
Siddiquie等人[46]在2018年提出了另一种方法,这是Schreiber等人[45]的后续工作。他们利用Faster R-CNN模型中的可变形卷积神经网络[65]执行了表格检测任务。作者声称,由于文档中有各种表格布局和比例,可变形卷积的性能超过了传统卷积。他们的DeCNT模型在ICDAR-2013[66]、ICDAR-2017 POD[64]、UNLV[2]和Marmot[3]的数据集上显示了最先进的结果。
Agarwal等人[49]提出了一种称为CDeC-Net(复合可变形级联网络 - Composite Deformable Cascade Network)的方法来检测文档图像中的表格边界。在这项工作中,作者经验性地证明,不需要添加额外的前/后处理技术来获得最先进的表格检测结果。这项工作基于一种新型 cascade Mask R-CNN [67]以及(复合主干 - composite backbone)网,复合主干网是一种双主干网结构(两个ResNeXt-101[68])[69]。在复合主干中,作者用可变形卷积代替传统卷积,以解决检测具有任意布局的表的问题。通过将可变形复合主干和strong Cascade Mask R-CNN相结合,他们提出的系统在表格社区的几个公开数据集上产生了可比的结果。
d: YOLO
YOLO (You Only Look Once) [70] 是一个著名的模型,用于有效地检测现实世界图像中的对象,Huang等人[47]也将其应用于表格检测任务中。YOLO不同于区域建议方法,因为它处理对象检测的任务更像是回归,而不是分类问题。YOLOv3[71]是YOLO[70]的最新增强版,因此用于本实验。为了使预测更精确,将从预测的表格区域中删除空白空白,同时细化嘈杂的页面对象。
e: MASK R-CNN, YOLO, SSD , Retina Net
另一项利用目标检测算法的研究是CasadoGarcía等人[72]发表的“文档图像中表格检测的近域微调优势”。在进行了详尽的评估之后,作者已经证明了当从更近的域进行微调时,表检测的性能有所改善。利用目标检测算法,作者使用了Mask R-CNN[73]、YOLO[74]、SSD[75]和Retina Net[76]。为了进行这个实验,选择了两个基本数据集。第一个数据集是PascalVOC[61],它包含自然风景图像,与表社区中的数据集没有密切关系。第二个基本数据集是TableBank[62],其中有41.7万个标记图像,在第四节-G中作了进一步解释。在这些数据集上对两个单独的模型进行了训练,并在所有ICDAR表格比赛数据集以及其他数据集(如Marmot和UNLV[2])上进行了全面测试,之后在第四节中对这些数据集进行了解释。本文中指出,当使用模型时,平均提高了17%与在真实图像上训练的模型相比,使用更接近域的数据集进行微调。
f: Cascade MASK R-CNN
随着通用空间特征提取网络 - generic spatial feature extraction networks[77]、[78]和目标检测网络[67]、[79]的最新改进,我们看到了表格检测系统的显著改进。Prasad等人[48]发表了CascadeTabNet,这是一种端到端的表检测和结构识别方法。在这项工作中,作者利用 Cascade Mask R-CNN[67](这是一种多级 Mask R-CNN)与HRNet[77]的新型混合作为基础网络。本文利用了[44]提出的类似区域,将转换后的图像输入强级联掩模R-CNN[67],而不是原始文档图像。他们提出的系统能够在ICDAR-2013[66]、ICDAR-2019[80]和TableBank[62]的数据集上实现最先进的结果。
在最近的一项工作中,郑等人[52]发表了一个文档图像中表格检测和结构识别的框架。作者认为,所提出的系统GTE(Global Table Extractor)是一种基于视觉的通用方法,其中可以使用任何对象检测算法。该方法将原始文档图像提供给多个对象检测器,这些检测器同时检测表格和单个单元格,以实现精确的表格检测。借助额外的惩罚损失和预测的细胞边界,进一步细化了目标检测器的预测表。该方法进一步改进了预测的细胞区域,以解决表格结构识别问题,第III-B节对此进行了解释。
2) 语义图像分割 - SEMANTIC IMAGE SEGMENTATION
2018年,Kavasidis等人将深度卷积神经网络、图形模型和显著性特征的概念相结合,用于检测图表和表格[81]。作者认为,检测表格的任务可以作为显著性检测,而不是使用对象检测网络。该模型基于语义图像分割技术。它首先提取显著性特征,然后对每个像素进行分类,无论该像素是否属于感兴趣的区域。为了注意长期依赖性,该模型采用了扩张卷积(dilated convolutions)[82]。最后,生成的显著性映射被传播到全连通条件随机场(CRF)[83],这进一步改进了预测。
a: 全卷积神经网络 - FULLY CONVOLUTIONAL NETWORKS
由深度学习支持的 TableNet 是一种端到端模型,用于检测和识别Paliwal等人[84]提供的文档图像中的表结构。该方法利用了全卷积网络[85]的概念,以预先训练的VGG-19[60]层作为基本网络。作者声称,识别表格区域和结构识别的问题可以类似地共同解决。他们进一步展示了如何利用迁移学习的能力来提高新数据集的性能。
3) 图神经网络 - GRAPH NEURAL NETWORKS
最近,我们看到图形神经网络在表格理解领域的应用正在上升。Riba等人[87]进行了一项实验,在发票文档中使用图形神经网络检测表格。由于发票图像中可用的信息量有限,作者认为图形神经网络更适合检测表格区域。本文还发布了原始RVL-CDIP数据集[89]的标记子集,该数据集可公开获取。
Holeček等人[86]提出了在发票等结构化文档中使用图卷积来理解表格的想法,从而扩展了图神经网络的应用。拟议的研究也在PDF文档上进行,然而,作者声称该模型足够健壮,可以处理其他类型的数据集。本研究将行项目表检测与信息提取相结合,解决了表检测问题。使用行项目方法,任何单词都可以很容易地区分它是否是行项目的一部分。在对所有单词进行分类后,可以有效地检测表格区域,因为与发票中的其他文本区域相比,表格中的行分隔得相当好。
4) 生成对抗网络 - GAN(GENERATIVE ADVERSARIAL NETWORKS)
生成性对抗网络(GAN)[90]也被用来识别表格。所提出的方法[88]确保生成网络不会看到规则表和较少规则表之间的差异,并尝试在这两种情况下提取相同的特征。随后,特征生成器与语义分割模型(如Mask R-CNN[73]或U-net[91])相结合。将基于GAN的特征生成器与Mask R-CNN相结合后,在ICDAR2017 POD数据集上对该方法进行了评估[64]。作者声称,这种方法将有助于解决其他目标检测和分割问题。
B. 表格结构分割 - TABLE STRUCTURAL SEGMENTATION
一旦检测到表的边界,下一步就是识别行和列[29]。在本节中,我们将回顾最近尝试解决表结构分段问题的方法。我们根据深层神经网络的结构对这些方法进行了分类。表3通过强调其优点和局限性总结了这些方法。图6展示了本文讨论的表格结构分割技术的基本流程。
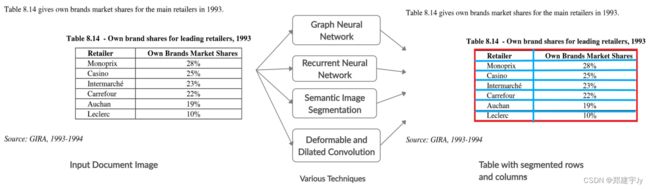
图6:表结构分割的基本流程以及所讨论的方法中使用的方法。为了识别表格的结构,表格图像被赋予各种深层神经结构,而不是文档图像。

表3:总结了各种基于深度学习的表格结构识别方法的优点和局限性。粗体的水平线分隔了不同架构的方法。
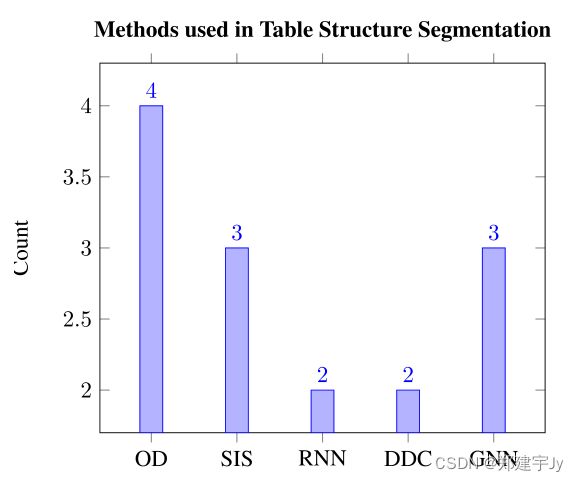
图7:OD表示目标检测,SIS表示语义图像分割,RNN表示递归神经网络,DDC是可变形和扩张卷积的缩写,而GNN是图形神经网络。此图说明了定期利用何种深度学习算法来执行表结构分割。
1) 语义图像分割 - SEMANTIC IMAGE SEGMENTATION
除了表检测之外,TableNet还通过检测各个表中的列来分割表的结构。Paliwal等人【84】使用预先训练好的VGG-19【60】作为基本网络,在解码器执行列检测时充当编码器。作者试图说服读者,由于表检测和结构分割之间的相互依赖性,这两个问题都可以通过使用单个网络有效地解决。
a: 全卷积神经网络 - FULLY CONVOLUTIONAL NETWORKS
为了识别表中的结构,DeepDeSRT的作者们利用了语义分割的概念。他们实现了[85]中提出的完全卷积网络。添加了一个预处理步骤,即垂直拉伸表格中的行,水平拉伸表格中的列,这在结果中提供了宝贵的优势。他们在ICDAR 2013表格结构识别数据集上取得了最新成果【66】。
Siddiqui等人提出了另一篇论文“重新思考文档中表结构识别的语义分割”。就像Schreiber等人[45]一样,他们将结构识别问题表述为语义分割问题。作者使用完全卷积网络[85]分别对行和列进行分段。在假设表格结构一致性的前提下,引入了预测平铺方法,降低了表格结构识别的复杂性。作者使用了FCN编码器和解码器的结构模型,并将预先训练好的模型加载到ImageNet上【93】。给定一幅图像,该模型生成与原始输入图像大小相同的特征。平铺过程对行和列中的特征进行平均,并将H×W×C(高度×宽度×通道)的特征组合为行的H×C和列的W×C。将卷积后的特征扩展为H×W×C,然后通过卷积层得到每个像素的标签。最后,进行后处理以完成最终结果。作者报告了2013年ICDAR数据集[66]的F1成绩为93.42%,IOU为0.5。由于作者对一致性的限制,他们必须对该数据集进行微调,该数据集现已公开,以重现类似的结果。
Fine-tuned ICDAR-13 dataset: https://bit.ly/2NhZHCr
Zou和Ma【94】提出了另一项研究,利用完全卷积网络【85】开发基于图像的表格结构识别方法。与[92]的思想类似,所呈现的工作对表中的行、列和单元格进行分段。连接成分分析用于改进所有表格成分的预测边界【95】。之后,根据行和列分隔符的位置为每个单元格指定行和列编号。此外,自定义启发式算法被应用于优化细胞边界。
2) 图神经网络 - GRAPH NEURAL NETWORKS
到目前为止,在上述大多数方法中,文档图像中的表分割问题都是用分割技术处理的。2019年,卡西姆等人【96】首次利用图形神经网络【97】进行表格识别 。该模型由深度卷积神经网络和图形神经网络组成,前者用于提取图像特征,后者用于控制顶点之间的关系。他们已经公开了拟议工作的来源,以复制或改进所声称的结果。github.com/shahrukhqasim/TIES-2.0
Chi等人于同年提出了另一种由图形神经网络支持的识别表格结构的技术。然而,这种技术是基于PDF文档而非图像的。他们方面值得一提的一个贡献是发布了他们的大规模表结构识别数据集SciTSR,这将在第四节中讨论。
a: 基于距离的权重 - DISTANCE BASED WEIGHTS
ICDAR 2019中提出的另一项分割表格结构的工作是从Xue等人出版的名为ReS2TIM的表格中重建句法结构。该模型的主要目标是回归每个单元的坐标。新方法首先创建一个网络,检测表中每个单元的邻居。本文提出了基于距离的权重,这将有助于网络解决训练中的班级不平衡障碍。实验在中国医学文献数据集【100】和ICDAR 2013表格竞争数据集【66】上进行。
3) 递归神经网络 - RECURRENT NEURAL NETWORKS
到目前为止,我们已经看到卷积神经网络和图神经网络被用于执行表结构提取。Khan等人提出的最新研究【102】试验了双向递归神经网络和选通递归单元(GRU)【103】来提取表格的结构。作者2github。com /shahrukhqasim /TIES-2.0认为卷积神经网络的感受野不足以在一步中捕获行和列的完整信息。根据作者的说法,一对双向GRU的性能更好。一个GRU用于行标识,而另一个GRU用于检测列边界。作者尝试了两种经典的递归神经网络模型,即长-短期记忆(LSTM)[104]和GRU[103],并发现GRU在实验结果中更具优势。最后,作者对UNLV【2】和ICDAR 2013表格比赛的表格结构识别子任务的数据集进行了实验,均超过了之前的最佳结果。作者试图证明,基于GRU的序列模型不仅可以改善结构识别问题,还可以用于表中的信息提取。
除了庞大的数据集之外,TableBank的作者[62]还发布了用于表结构识别的基线模型。图像到标记模型【74】是在TableBank数据集上训练的。为了实现该模型,应用了OpenNMT【105】,这是一个用于神经机器翻译的开源工具包。
4) DEFORMABLE AND DILATED CONVOLUTIONS
与传统卷积一样,可变形卷积和扩张卷积也被用来识别文档图像中的表格结构。
a: 可变形卷积 - DEFORMABLE CONVOLUTIONS
Siddiqui等人[50]宣传了另一个公共的基于图像的表识别数据集,称为TabStructDB。该数据集是使用著名的ICDAR 2017页面对象检测数据集【64】中的图像整理而成,该数据集带有结构信息注释。TabStructDB已在名为DeepTabStR的拟议模型上进行了广泛的评估,该模型可视为[46]的后续工作。作者指出,表格布局存在巨大的多样性,而作为滑动窗口的传统卷积并不是最佳选择。可变形卷积允许网络通过考虑对象的当前位置来调整感受野。因此,作者利用可变形卷积来执行表的结构识别任务。在本研究中,表格分割的练习是作为一个对象检测问题进行的。DeepTabStR中使用了可变形更快的R-CNN,传统的ROI池层被可变形的ROI池层所取代。本研究强调了另一个重要点,即对于布局不一致的表格,在结构分析方面仍有改进的空间。
b: 扩张卷积 - DILATED CONVOLUTIONS
Tensmeyer等人提出了另一种采用扩展卷积SPLERGE(分裂和合并模型)的技术。他们的方法由两个独立的深度学习模型组成,其中第一个模型定义了表格的网格状结构,而第二个模型则确定了单元格是否可以进一步扩展为多行或多列。作者声称在ICDAR 2013年桌面竞赛数据集上取得了最先进的表现【66】。
5) 目标检测算法 - OBJECT DETECTION ALGORITHMS
从目标检测算法的优异结果中得到启发【67】、【73】,表社区的研究人员将表结构识别的任务制定为一个目标检测问题。
Hashmi等人[51]提出了一种引导式表结构识别方法来检测表中的行和列。本文提出,通过结合锚优化方法,可以改进行和列的本地化【106】。在他们提出的工作中,Mask R-CNN【73】被用于优化锚定,以检测行和列的边界。本文报告了TabStructDB[50]和ICDAR-2013表结构识别数据集(由[45]发布)的最新结果。
到目前为止,我们已经讨论了检测表格行和列以检索表的最终结构的方法。与之前的方法相反,Raja等人【53】引入了一种表格结构识别方法,该方法直接回归细胞边界。作者使用Mask R-CNN(73)和在MS-COCO数据集上预先训练的ResNet-101主干网(43)。在他们的目标检测框架中,在区域建议网络中实现了扩展卷积。此外,作者还介绍了线形损失,这也有助于整体损失函数。随后,应用图卷积网络[108]来获得预测单元之间的行和列关系。整个过程以端到端的方式进行培训。本文针对表结构识别任务,对几个公开可用的数据集进行了广泛的评估。
CascadeTabNet中介绍了另一种直接定位表格中细胞边界的方法【48】。在这种方法中,表格图像被提供给级联掩码R-CNN【67】,该掩码预测细胞掩码以及表格的分类为有边界或无边界。随后,对有边界和无边界的表进行单独的后处理,以检索最终的单元边界。
Zheng等人[52]提出的系统GTE是一个端到端的框架,它不仅可以检测表格,还可以识别文档图像中表格的结构。与[48]的方法类似,作者提出了两种不同的细胞检测网络,即:1)表格中的图形化划线。2) 表格中没有图形刻线。将带有表格掩码的完整文档图像传播到分类网络,而不是表格图像。根据预测的类别,图像被传递到适当的细胞网络,以检索最终的细胞边界。
C. 表格识别 - TABLE RECOGNITION
如第三节所述,表格识别的任务包括表格结构提取以及从表格单元格中提取文本。相对而言,在这一特定领域取得的进展较少。在本节中,我们将介绍最近尝试解决表格识别问题的实验。表4通过强调其优点和局限性总结了这些方法。

表4:总结了基于深度学习的方法的优点和局限性,这些方法仅用于扫描文档图像的表格识别任务。
1) 编码器-双解码器 - ENCODER-DUAL-DECODER
最近,Zhong等人[32]提出的基于图像的表格识别研究发表了。在这项研究中,作者提出了一个称为PubTabNet的新数据集,该数据集在第IV-M节中进行了解释。作者试图解决推断表的结构识别及其各自单元格中存在的信息的问题。本文作者分别处理了结构识别和表格识别的任务。他们提出了基于注意的编码器-双解码器(EDD)体系结构。编码器提取基本的空间特征,然后第一个解码器将表格分割成行和列,而另一个解码器尝试识别表格单元的内容。在本研究中,提出了一种新的基于树编辑距离(Tree-EditDistance)的相似度(TEDS)度量来评估细胞内容识别的质量。
2) 编码器-解码器网络 - ENCODER DECODER NETWORK
另一个数据集TABLE2LATEX-450K3最近在ICDAR会议上发布,由arXiv文章组成。除了数据集之外,Deng等人[109]还讨论了端到端表识别中当前面临的挑战,并强调了在该领域使用更大数据集的价值。该数据集的创建者还通过使用带注意机制的编码器-解码器架构,将基线模型(IM2TEX)[110]赋予了上述数据集。IM2TEX模型在OpenNMT上实现【105】。随着未来GPU硬件能力的可能增加,作者声称该数据集将被证明是一个有希望的贡献。
值得一提的是,除了这两种方法外,其他方法【62】、【96】、【111】都提取了单元格内容,以便识别表格边界或表格结构。
4.数据集 - DataSets
深度神经网络的性能与数据集的大小直接相关[45],[46]。在本节中,我们将讨论所有公开的用于处理文档图像中的表检测和表结构识别问题的知名数据集。表5全面解释了用于执行和比较文档图像中表格的检测、结构分割和识别的所有上述数据集。图8展示了来自表社区中一些杰出数据集的样本。
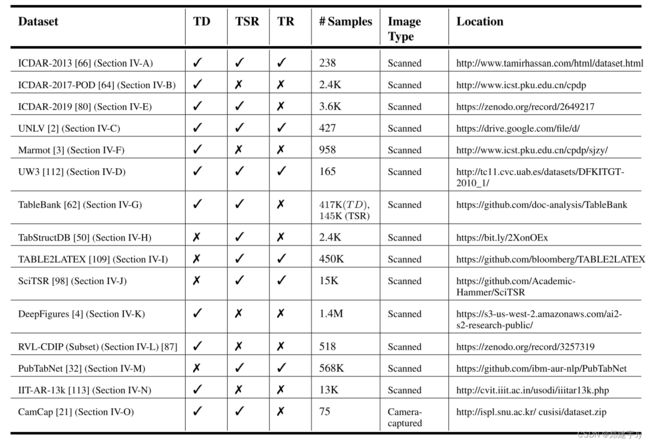
表5:表格数据集。TD表示表格检测,TSR表示表格结构识别,而TR表示表格识别。

图8:样本文档图像取自ICDAR-2013[66]、ICDAR-2017-POD[64]、UNLV[2]和UW3[112]的数据集。红色边界代表表格区域。数据集中样本之间的差异非常明显。
1.ICDAR-2013 微调的ICDAR-13数据集网址
国际文档分析与识别会议(ICDAR)2013[66]是表格社区研究人员中最著名的数据集。该数据集是为2013年ICDAR大会组织的桌上比赛发布的。该数据集具有用于表检测和表识别的注释。数据集由PDF文件组成,这些文件通常被转换成图像,以用于各种方法。数据集包含结构化的表格、图形、图表和文本作为信息。该数据集中共有238张图像,其中128张包含表格。该数据集已被广泛用于比较最先进的方法。如表5所述,该数据集对本文讨论的所有三项表理解任务都有注释。图8(A)显示了该数据集中的两个样本。
2.ICDAR-2017-POD
该数据集[64]也被提议用于2017年ICDAR的页面对象检测(POD)竞赛。该数据集被广泛用于评估表检测方法。该数据集比ICDAR 2013表格数据集大得多。它由2417张图片组成,包括表格、公式和数字。在许多情况下,该数据集被划分为1600个图像(731个表格区域),用于训练,而其余817个图像(350个表格区域)用于测试。该数据集的一对实例如图8(b)所示。该数据集仅包含表5中解释的表格边界信息。
3.UNLV
UNLV数据集[2]是文档图像分析领域公认的数据集。该数据集由来自不同来源的扫描文档图像组成,如财务报告、杂志和具有不同表格布局的研究论文。尽管数据集包含大约10000张图像,但只有427张图像包含表格区域。通常,这427张图像被用于在研究社区进行各种实验。该数据集已用于本文讨论的所有三项表格分析任务。图8(c)展示了该数据集中的几个样本。
4.UW3
UW3[112]是文档图像分析领域研究人员的另一个热门数据集。此数据集包含来自书籍和杂志的扫描文档。大约有1600个扫描文档图像,其中只有165个图像具有表格区域。带注释的表格坐标以XML格式显示。该数据集中的两个样本如图8(d)所示。尽管该数据集的表格区域数量有限,但它对本文讨论的所有三个表格理解问题都有注释。
5.ICDAR-2019
最近,在ICDAR 2019中开展了关于表格检测和识别(cTDaR)[80]的竞赛。在竞赛中,提出了两个新的数据集:现代数据集和历史数据集。现代数据集包含来自科学论文、表格和财务文件的样本。而档案数据集包括手写的会计分类账、火车时刻表、旧书中的简单表格打印等图像。在现代数据集中,用于检测表的规定列车测试分割是600张用于训练的图像,240张用于测试的图像。同样,对于历史数据集,推荐的数据分布为600张用于训练的图像和199张用于测试部分的图像。如表5所示,数据集还包含表格边界和单元格区域注释的信息。这种新颖的数据集在本质上具有挑战性,因为它同时包含现代和历史(存档)文档图像。该数据集将用于评估表格分析方法的稳健性。为了了解多样性,图9中描绘了来自历史和现代数据集的两个样本。

图9:从ICDAR-2019数据集[80]中获取的存档和现代文档图像示例,如第4-E节所述。红色边界代表表格区域。
6.MARMOT 地址
不久前, Marmot 是最大的公开数据集之一,被研究人员广泛用于表格理解领域。该数据集由北京大学计算机科学与技术研究所(Institute of Computer Science and Technology,简称北京大学)提出,后来由方等[3]解释。该数据集由1970年至2011年的中英文会议论文组成,共有2000幅图像。由于具有多样且非常复杂的页面布局,该数据集对于训练网络非常有用。在数据集中,正片和负片的比例大约为1:1。过去曾报道过一些不正确的地面真相注释,Schreiber等人后来对此进行了清理[45]。如表5所述,该数据集具有表格边界的注释,广泛用于训练用于表格检测的深层神经网络。
7. TableBank 地址
2019年初,Li等人[62]意识到表格社区需要大型数据集,并发布了TableBank,该数据集由41.7万张具有表格信息的标记图像组成。该数据集是通过在中的在线可用文档上爬行而收集的.docx格式。该数据集的另一个数据来源是从 arXiv 数据库收集的LaTeX文档该数据集的发布者认为,这一贡献将有助于研究人员利用深度学习和微调方法的力量。作者声称,该数据集可用于表检测和结构识别任务。然而,我们无法在数据集中找到用于结构识别的注释。表5总结了数据集的重要信息。
8.TabStructDB 地址
在2019年的ICDAR会议上,除了表格竞赛[80],其他研究人员还发布了表格分析领域的新数据集。Siddiqui等人[50]发布了一个名为TabStructDB的数据集。由于ICDAR-2017-POD数据集[64]仅包含表格边界的信息,作者利用该数据集,并用结构信息对其进行注释,这些结构信息包括表中各行和列的边界。为了保持一致性,作者还保留了[80]中提到的相同数据集分割。表5总结了有关数据集的重要信息。由于该数据集提供了关于行和列边界的信息,因此便于研究人员将表结构识别任务视为对象检测或语义分割问题。
9.TABLE2LATEX-450K(添加链接描述)
在最近的ICDAR会议上发布的另一个大型数据集是TABLE2LA TEX-450K[109]。该数据集包含45万个带注释的表及其相应的图像。这个庞大的数据集是通过检索1991年至2016年的arXiv文章构建的,所有的LaTeX源文件都是下载的。经过源代码提取和后续细化,得到高质量的标记数据集。如表5所述,数据集包含用于表的结构分段和表单元格内容的注释。除了数据集,出版商还公开了所有预处理脚本。 这个数据集对于解决文档图像中的表结构分割和表识别问题是一个重要贡献,因为它使研究人员能够从头开始训练大规模的深度学习体系结构,这些体系结构可以在相对较小的数据集上进一步精调。
10.SciTSR 地址
SciTSR是Chi等人于2019年发布的另一个数据集[98]。据作者介绍,这是最大的公开数据集之一,用于表结构识别任务。数据集由15000个PDF格式的表格及其注释组成。数据集是通过从arXiv中抓取LaTeX源文件构建的。大约25%的数据集由跨多行或多列的复杂表组成。该数据集具有表结构分段和表识别的注释,如表5所示。由于具有复杂的表格结构,可以利用该数据集改进处理具有复杂布局的表格的结构分割和识别的最先进系统。
11.DeepFigures 下载链接,点击即可下载
据我们所知,DeepFigures[4]是可公开用于执行表检测任务的最大数据集。该数据集包含超过140万个文档及其相应的表格和图形边框。作者利用arXiv和PubMed数据库上的在线科学文章开发数据集。数据集的基本事实以XML格式提供。如表5所示,该数据集仅包含表的边界框。为了充分利用深度神经网络解决表检测问题,可以将这个大规模数据集作为基础数据集,实现更近域的微调技术。
12.RVL-CDIP (SUBSET) 地址
RVL-CDIP(Ryerson Vision Lab Complex Document Information Processing)[89]是文档分析社区中著名的数据集。它包含40万张图像,平均分为16类。Riba等人[87]通过注释其518张发票,利用RVL-CDIP数据集。数据集已公开用于表检测任务。数据集只有表5中提到的表格边界的注释。实际RVL-CDIP数据集的这个子集[89]对于评估专门为发票文档图像设计的表格检测系统是一个重要贡献。
13.PubTabNet 地址
PubTabNet是Zhong等人[32]于2019年12月发布的另一个数据集。PubTabNet是目前最大的公开数据集,包含超过56.8万个图像,每个单元格中都有相应的表和内容结构信息。该数据集是通过从PubMed CentralTM开放存取子集(PMCOA)收集科学文章创建的。该数据集的基本事实格式为HTML,可用于web应用程序。作者们相信,该数据集将提高表格中信息提取系统的性能,他们还计划在未来发布各个表格单元的基本事实。表5总结了数据集的重要信息。与TABLE2LA TEX-450K数据集[109]一起,PubTabNet[32]允许研究人员在表格结构提取或表格识别任务中独立训练深度神经网络的完整参数。
14.IIIT-AR-13K
最近,Mondal等人[113]引入了一个名为IIT-AR-13K的新数据集,为图形页面对象检测社区做出了贡献。作者通过收集以英语和其他语言编写的公开年度报告来生成该数据集。作者声称,这是为解决图形页面对象检测问题而发布的最大的手动注释数据集。除了表格之外,数据集还包括数字、自然图像、徽标和签名的注释。该数据集的发布者为页面对象检测的各种任务提供了训练、验证和测试拆分。对于表格检测,11000个样本用于培训,而2000个和3000个样本分别用于验证和测试。
15.CamCap
CamCap是我们在本次调查中包含的最后一个数据集,由摄像头拍摄的图像组成。该数据集由Seo等人[21]提出。曲面上的图像由11647个单元组成,曲面上的图像由12938个单元组成。图10包含来自该数据集的几个样本,说明了这些挑战。建议的数据集是公开的,可用于表检测和表结构识别任务,如表5所示。为了评估表格检测方法对摄像机捕获的文档图像的鲁棒性,该数据集是一项重要贡献。值得一提的是,卡西姆等人[96]发表了一种从UNLV数据集综合创建相机捕获图像的方法。图11中描绘了合成创建的相机捕获图像的实例。
图10:从CamCap数据集[21]中拍摄的真实摄像头捕获图像示例,详见第IV-O节。红色边界代表表格区域。

图11:通过线性透视变换方法合成创建的相机捕获图像的示例[96]。
5.评价 - Evalution
在本节中,我们将介绍众所周知的评估指标,以及第三节中引用的所有方法的详尽评估比较。
A.评估指标 - EVALUATION METRICS
在阐明性能评估之前,先讨论一下评估指标是用来评估所讨论方法的性能的。
1) 精确度 - PRECISION
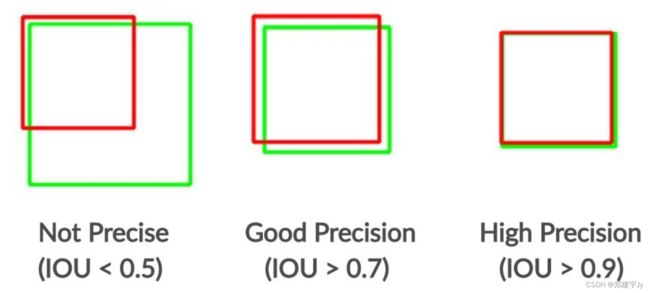
图12:IOU阈值设置为0.5时目标检测问题的精度示例。最左边的情况不会被视为精确,而其他两个预测是精确的,因为它们的IOU值大于0.5。绿色表示基本事实,红色表示预测的边界框。
精确度[114]定义为属于地面真相的预测区域的百分比。图12中解释了不同类型精度的图示。精度公式如下所述:

2) 召回率 - RECALL
召回率[114]计算为预测区域中存在的地面真实区域的百分比。召回公式解释如下:

3) F-分数 - F-MEASURE
F-measure[114]是通过精确性和召回率的调和平均值来计算的。F-度量的公式为:

4) INTERSECTION OVER UNION ( I O U IOU IOU )
I O U IOU IOU [115]是一个重要的评估指标,通常用于确定目标检测算法的性能。它是预测区域与实际地面真值区域重叠程度的度量。其定义如下:

5) BLEU SCORE
BLEU(双语评估替补)[116]是一种用于比较各种机器翻译问题的评估方法。将预测的文本与实际的基本事实进行比较后,计算分数。BLEU度量将预测从0分到1分,其中1是预测文本的最佳分数。
B.表格检测的评估 - EVALUATIONS FOR TABLE DETECTION
表格检测的问题是区分文档图像中的表格区域,并回归分类为表格区域的边界框的坐标。表6说明了第3-A节详细讨论的各种表格检测方法的性能比较。在大多数情况下,表格检测方法的性能是在ICDAR-2013[66]、ICDAR-2017-POD[64]和UNLV[2]数据集上评估的。

表6:检测性能比较。双水平线将在各种数据集上获得的结果进行划分。突出显示了所有相关数据集中的突出结果。对于ICDAR-2019数据集[80],这三种方法都不具有直接可比性,因为它们报告了不同IOU阈值的F-Measure。因此,ICDAR-2019数据集上的结果没有突出显示。
表6还定义了用于计算精度和召回率的联合交集阈值( I O U IOU IOU )。图13解释了关于表检测任务的精确和不精确预测的定义。突出显示了在所有相关数据集中具有最高精确度的结果。值得一提的是,一些方法没有引用 I O U IOU IOU 的阈值;然而,他们将其结果与定义阈值的其他方法进行了比较。因此,我们考虑了这些程序的相同阈值。
图13:关于表格检测任务的精度示例。绿色代表基本事实,而红色代表预测的表格区域。在第一种情况下,预测不是精确的,因为预测的边界框和地面真值之间的IOU小于0.5。右边的表格预测是精确的,因为它涵盖了几乎完整的表格区域。
我们无法纳入Holeček等人[86]提供的文献结果,因为他们没有采用任何标准数据集进行比较,并将其新方法与逻辑回归进行了比较[117]。结果表明,他们的模型已经超过了logistic回归方法。
Qasim等人[96]的另一种方法在第3-A3节中进行了解释,该方法没有使用任何已知的数据集来评估其方法。然而,他们使用[118]和[119]两种类型的图神经网络在合成数据集上测试了他们的方法。除了图形神经网络外,还使用了完全卷积神经网络进行公平比较。经过详尽的评估,图形神经网络和卷积神经网络的融合已经超过了所有其他方法,具有96.9的完美匹配精度。 我们仅使用图形神经网络提供了65.6的完美匹配精度,仍然超过了仅使用完全卷积神经网络的方法的精度。
C.对表格结构分段的评估 - EVALUATIONS FOR TABLE STRUCTURAL SEGMENTATION

图14:关于表格结构分割任务的精度示例。绿色表示ground truth,而红色表示预测的边界框。为简单起见,行和列的检测精度分别显示。所示示例中的IOU阈值被认为是0.5。
表结构分割的任务是根据表的行或列被分隔的准确程度来评估的[45]、[45]、[50]。图14示出了对于行和列检测的任务两者的不精确和精确预测的含义。 表7总结了在ICDAR 2013表格竞赛数据集上执行表格结构分割任务的多种方法的性能比较[66]。
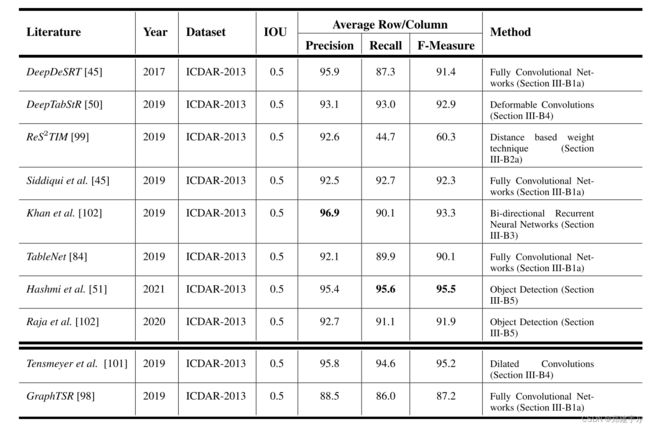
表7:结构分段性能。强调了了突出的成果。最后两行的结果与其他方法没有直接可比性,因为使用的是PDF文件而不是文档图像。

表8:表ICDAR-2019数据集的结构分段性能[80]。为了简洁明了,这些结果在本表中单独列出。
最近,表格结构识别的问题已经在精确预测表格图像中的细胞边界[48]、[52]、[94]上得到了评估。由于与之前的方法[45]、[45]、[50]不同,我们在单独的表8中给出了这些方法的结果。
表中突出显示了精度最高的结果。值得一提的是,除了表7和表8中提到的方法外,还有两种其他方法在第3-B节中讨论。我们无法将其结果纳入表7,因为这些方法既没有在任何标准数据集上进行评估,也没有使用标准评估指标。然而,他们的结果将在下一段中解释。
TableBank的创建者[62]提出了用于表结构分割和表检测的基线模型。为了检验他们在TableBank数据集上的表结构识别基线模型的性能,他们采用了4-gramBLEU分数[116]作为评估指标。结果表明,在Word+Latex数据集上训练他们的图像到文本模型时,BLEU得分为0.7382,并且在所有情况下都具有更好的泛化能力。
D.表格识别的评估 - EVALUATIONS FOR TABLE RECOGNITION
表格识别包括分割表格结构和从单元格中提取信息。在本节中,我们将介绍上文第3-C节讨论的两种方法的评估。
在研究端到端神经科学表格识别的挑战时,作者邓等人[109]在TABLE2LA TEX-450K数据集上测试了他们的图像到文本模型。该模型获得了32.40%的准确匹配精度,BLEU分数为40.33。作者还研究了该模型,该模型能够很好地识别表的结构。已经得出结论,该模型在具有多列(行)的复杂结构的情况下遇到问题。
钟等人[32]的另一项研究也对表格识别任务进行了实验。为了评估观察结果,他们提出了自己的评估指标,称为TEDS,其中相似度是使用Pawlik和Augsten[120]提出的相同树编辑距离计算的。他们的编码器-双解码器(EDD)模型在PubTabNet数据集上以88.3%的TEDS分数击败了所有其他基线模型。
表9总结了这两种方法的结果。值得一提的是,由于这些技术中使用的数据集和评估指标不同,因此所提出的方法无法直接相互比较。

表9:表格识别性能。由于使用了不同的数据集和评估指标,本表中提到的结果不能直接相互比较。
6.结论 - Conclusion
在文档分析领域,表格分析是一个非常重要且得到充分研究的问题。深度学习概念的开发极大地改变了表格理解的问题,并设定了新的标准。在这篇综述性的文章中,我们讨论了一些最近的现代程序,这些程序应用了深度学习的概念来完成从文档图像中的表中提取信息的任务。在第三节中,我们解释了利用深度学习执行表格检测、结构分割和识别的方法。图5和图7分别展示了用于表检测和结构分割的最著名和最不著名的方法。我们在表5中总结了所有公开可用的数据集及其访问信息。在表6、7、8和9中,我们对各种数据集上讨论的方法进行了详尽的性能比较。我们已经讨论过最先进的方法对于已知公开数据集上的表检测,已经取得了近乎完美的结果。一旦检测到表格区域,接下来就要进行表格的结构分割和表格识别。在研究了最近的几种方法之后,我们认为,在这两个领域仍有改进的余地。
7.未来的工作 - Future Work
在分析和比较各种方法时,我们注意到了一些需要强调的方面,以便在未来的工作中加以考虑。对于表检测,最受利用的评估指标之一是IOU[45],[46]。本文讨论的大多数方法都在精确度、召回率和F-测量的基础上,将其方法与之前的最先进方法进行了比较[114]。这三个指标是根据作者确定的特定IOU阈值计算的。我们坚信,IOU的阈值需要标准化,以便进行公正的比较。我们提到的另一个重要因素是,在比较不同的研究方法时,我们发现了另一个关于性能的重要因素。在少数情况下,语义分割被证明在准确性方面优于其他表结构分割方法。然而,关于执行时间的描述并不明显。
到目前为止,传统的方法已经被用来从摄像机捕获的文档图像中检测表格[21]。深度学习方法的力量可以用来改进这一领域最先进的表格分析系统。深度学习利用了巨大的数据集[45]。最近,已经发布了大量公开可用的数据集[32]、[62]、[98],这些数据集不仅为表结构提取提供注释,还为表检测提供注释。我们希望这些当代数据集将得到测试。通过利用各种深度学习概念与最近发布的数据集的融合,可以进一步增强表格分割和识别方法的结果。据我们所知,强化学习[121],[122]尚未在表格分析领域进行研究,但在从文档图像中提取信息方面存在一些工作[123]。尽管如此,对于表格检测和识别来说,这也是一个令人兴奋和有希望的未来方向。
参考文献 - Reference
Reference
[1] S. Sarawagi, ‘‘Information extraction,’’ Databases, vol. 1, no. 3, pp. 261–377, 2007.
[2] A. Shahab, F. Shafait, T. Kieninger, and A. Dengel, ‘‘An open approach towards the benchmarking of table structure recognition systems,’’ in Proc. 8th IAPR Int. Workshop Document Anal. Syst. (DAS), 2010, pp. 113–120.
[3] J. Fang, X. Tao, Z. Tang, R. Qiu, and Y . Liu, ‘‘Dataset, ground-truth and performance metrics for table detection evaluation,’’ in Proc. 10th IAPR Int. Workshop Document Anal. Syst., Mar. 2012, pp. 445–449.
[4] Y .-S. Kim and K.-H. Lee, ‘‘Extracting logical structures from HTML tables,’’ Comput. Standards Interfaces, vol. 30, no. 5, pp. 296–308, Jul. 2008.
[5] H.-H. Chen, S.-C. Tsai, and J.-H. Tsai, ‘‘Mining tables from large scale HTML texts,’’ in Proc. 18th Int. Conf. Comput. Linguistics (COLING), vol. 1, 2000, pp. 166–172.
[6] H. Masuda, S. Tsukamoto, S. Yasutomi, and H. Nakagawa, ‘‘Recognition of HTML table structure,’’ in Proc. 1st Int. Joint Conf. Natural Lang. Process. (IJCNLP), 2004, pp. 183–188.
[7] C.-Y . Tyan, H. K. Huang, and T. Niki, ‘‘Generator for document with html tagged table having data elements which preserve layout relationships of information in bitmap image of original document,’’ U.S. Patent 5 893 127, Apr. 6, 1999.
[8] T. Kieninger and A. Dengel, ‘‘A paper-to-HTML table converting system,’’ in Proc. Document Anal. Sys. (DAS), vol. 98, 1998, pp. 356–365.
[9] T. G. Kieninger, ‘‘Table structure recognition based on robust block segmentation,’’ Document Recognit. V, vol. 3305, pp. 22–32, Apr. 1998.
[10] T. Kieninger and A. Dengel, ‘‘Applying the T-RECS table recognition system to the business letter domain,’’ in Proc. 6th Int. Conf. Document Anal. Recognit., 2001, pp. 518–522.
[11] F. Cesarini, S. Marinai, L. Sarti, and G. Soda, ‘‘Trainable table location in document images,’’ in Proc. Object Recognit. Supported User Interact. Service Robots, vol. 3, 2002, pp. 236–240.
[12] A. C. E. Silva, ‘‘Learning rich hidden Markov models in document analysis: Table location,’’ in Proc. 10th Int. Conf. Document Anal. Recognit., 2009, pp. 843–847.
[13] C. Cortes and V . V apnik, ‘‘Support-vector networks,’’ Mach. Learn., vol. 20, no. 3, pp. 273–297, 1995.
[14] T. Kasar, P . Barlas, S. Adam, C. Chatelain, and T. Paquet, ‘‘Learning to detect tables in scanned document images using line information,’’ in Proc. 12th Int. Conf. Document Anal. Recognit., Aug. 2013, pp. 1185–1189.
[15] M. Fan and D. S. Kim, ‘‘Detecting table region in PDF documents using distant supervision,’’ 2015, arXiv:1506.08891. [Online]. Available: http://arxiv.org/abs/1506.08891
[16] D. N. Tran, T. A. Tran, A. Oh, S. H. Kim, and I. S. Na, ‘‘Table detection from document image using vertical arrangement of text blocks,’’ Int. J. Contents, vol. 11, no. 4, pp. 77–85, Dec. 2015.
[17] Y . Wang, I. T. Phillips, and R. M. Haralick, ‘‘Table structure understanding and its performance evaluation,’’ Pattern Recognit., vol. 37, no. 7, pp. 1479–1497, Jul. 2004.
[18] G. Nagy, ‘‘Hierarchical representation of optically scanned documents,’’ in Proc. 7th Int. Conf. Pattern Recognit., 1984, pp. 347–349.
[19] A. Shigarov, A. Mikhailov, and A. Altaev, ‘‘Configurable table structure recognition in untagged PDF documents,’’ in Proc. ACM Symp. Document Eng., Sep. 2016, pp. 119–122.
[20] A. Krizhevsky, I. Sutskever, and G. E. Hinton, ‘‘ImageNet classification with deep convolutional neural networks,’’ in Proc. Adv. Neural Inf. Process. Syst. (NIPS), vol. 25, Dec. 2012, pp. 1097–1105.
[21] W. Seo, H. I. Koo, and N. I. Cho, ‘‘Junction-based table detection in camera-captured document images,’’ Int. J. Document Anal. Recognit., vol. 18, no. 1, pp. 47–57, Mar. 2015.
[22] E. R. Dougherty, Electronic Imaging Technology, vol. 60. Bellingham, W A, USA: SPIE, 1999.
[23] J. C. Handley, ‘‘Table analysis for multiline cell identification,’’ Document Recognit. Retrieval VIII, vol. 4307, pp. 34–43, Dec. 2000.
[24] D. P . Lopresti and G. Nagy, ‘‘A tabular survey of automated table processing,’’ in Proc. Sel. 3rd Int. Workshop Graph. Recognit. Recent Adv., 1999, pp. 93–120.
[25] D. Lopresti and G. Nagy, ‘‘Automated table processing,’’ in Proc. 3rd Int. Workshop, Graph. Recognit. Recent Adv., no. 1941, 2000, p. 93.
[26] R. Zanibbi, D. Blostein, and J. Cordy, ‘‘A survey of table recognition,’’ Document Anal. Recognit., vol. 7, no. 1, pp. 1–16, Mar. 2004.
[27] D. W. Embley, M. Hurst, D. Lopresti, and G. Nagy, ‘‘Table-processing paradigms: A research survey,’’ Int. J. Document Anal. Recognit., vol. 8, nos. 2–3, pp. 66–86, Jun. 2006.
[28] M. F. Hurst, ‘‘The interpretation of tables in texts,’’ Ph.D. dissertation, Univ. Edinburgh, Edinburgh, U.K., 2000.
[29] A. C. e Silva, A. M. Jorge, and L. Torgo, ‘‘Design of an end-to-end method to extract information from tables,’’ Int. J. Document Anal. Recognit., vol. 8, nos. 2–3, pp. 144–171, Jun. 2006.
[30] B. Coüasnon and A. Lemaitre, ‘‘Recognition of tables and forms,’’ in Handbook of Document Image Processing and Recognition, D. Doermann and K. Tombre, Eds. London, U.K.: Springer, 2014, pp. 647–677.
[31] S. Khusro, A. Latif, and I. Ullah, ‘‘On methods and tools of table detection, extraction and annotation in PDF documents,’’ J. Inf. Sci., vol. 41, no. 1, pp. 41–57, Feb. 2015.
[32] X. Zhong, E. ShafieiBavani, and A. J. Yepes, ‘‘Image-based table recognition: Data, model, and evaluation,’’ 2019, arXiv:1911.10683. [Online]. Available: http://arxiv.org/abs/1911.10683
[33] J. Hu, R. S. Kashi, D. Lopresti, and G. T. Wilfong, ‘‘Evaluating the performance of table processing algorithms,’’ Int. J. Document Anal. Recognit., vol. 4, no. 3, pp. 140–153, Mar. 2002.
[34] L. Hao, L. Gao, X. Yi, and Z. Tang, ‘‘A table detection method for PDF documents based on convolutional neural networks,’’ in Proc. 12th IAPR Workshop Document Anal. Syst. (DAS), Apr. 2016, pp. 287–292.
[35] L. Torrey and J. Shavlik, ‘‘Transfer learning,’’ in Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques. Hershey, PA, USA: IGI Global, 2010, pp. 242–264.
[36] Y . Zhu, Y . Chen, Z. Lu, S. Pan, G.-R. Xue, Y . Y u, and Q. Yang, ‘‘Heterogeneous transfer learning for image classification,’’ in Proc. AAAI Conf. Artif. Intell., 2011, vol. 25, no. 1, pp. 1304–1309.
[37] B. Kulis, K. Saenko, and T. Darrell, ‘‘What you saw is not what you get: Domain adaptation using asymmetric kernel transforms,’’ in Proc. CVPR, Jun. 2011, pp. 1785–1792.
[38] C. Wang and S. Mahadevan, ‘‘Heterogeneous domain adaptation using manifold alignment,’’ in Proc. IJCAI, 2011, vol. 22, no. 1, p. 1541.
[39] W. Li, L. Duan, D. Xu, and I. W. Tsang, ‘‘Learning with augmented features for supervised and semi-supervised heterogeneous domain adaptation,’’ IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 6, pp. 1134–1148, Jun. 2014.
[40] M. Loey, F. Smarandache, and N. E. M. Khalifa, ‘‘Within the lack of chest COVID-19 X-ray dataset: A novel detection model based on GAN and deep transfer learning,’’ Symmetry, vol. 12, no. 4, p. 651, Apr. 2020.
[41] M. Z. Afzal, S. Capobianco, M. I. Malik, S. Marinai, T. M. Breuel, A. Dengel, and M. Liwicki, ‘‘Deepdocclassifier: Document classification with deep convolutional neural network,’’ in Proc. 13th Int. Conf. Document Anal. Recognit. (ICDAR), Aug. 2015, pp. 1111–1115.
[42] A. Das, S. Roy, U. Bhattacharya, and S. K. Parui, ‘‘Document image classification with intra-domain transfer learning and stacked generalization of deep convolutional neural networks,’’ in Proc. 24th Int. Conf. Pattern Recognit. (ICPR), Aug. 2018, pp. 3180–3185.
[43] T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P . Perona, D. Ramanan, P . Dollár, and C. L. Zitnick, ‘‘Microsoft COCO: Common objects in context,’’ in Proc. Eur . Conf. Comput. Vis. Cham, Switzerland: Springer, 2014, pp. 740–755.
[44] A. Gilani, S. R. Qasim, I. Malik, and F. Shafait, ‘‘Table detection using deep learning,’’ in Proc. 14th IAPR Int. Conf. Document Anal. Recognit. (ICDAR), Nov. 2017, pp. 771–776.
[45] S. Schreiber, S. Agne, I. Wolf, A. Dengel, and S. Ahmed, ‘‘DeepDeSRT: Deep learning for detection and structure recognition of tables in document images,’’ in Proc. 14th IAPR Int. Conf. Document Anal. Recognit. (ICDAR), vol. 1, Nov. 2017, pp. 1162–1167.
[46] S. A. Siddiqui, M. I. Malik, S. Agne, A. Dengel, and S. Ahmed, ‘‘DeCNT: Deep deformable CNN for table detection,’’ IEEE Access, vol. 6, pp. 74151–74161, 2018.
[47] Y . Huang, Q. Yan, Y . Li, Y . Chen, X. Wang, L. Gao, and Z. Tang, ‘‘A YOLO-based table detection method,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 813–818.
[48] D. Prasad, A. Gadpal, K. Kapadni, M. Visave, and K. Sultanpure, ‘‘CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents,’’ in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Jun. 2020, pp. 572–573.
[49] M. Agarwal, A. Mondal, and C. V . Jawahar, ‘‘CDeC-Net: Composite deformable cascade network for table detection in document images,’’ 2020, arXiv:2008.10831. [Online]. Available: http://arxiv. org/abs/2008.10831
[50] S. A. Siddiqui, I. A. Fateh, S. T. R. Rizvi, A. Dengel, and S. Ahmed, ‘‘DeepTabStR: Deep learning based table structure recognition,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 1403–1409.
[51] K. A. Hashmi, D. Stricker, M. Liwicki, M. N. Afzal, and M. Z. Afzal, ‘‘Guided table structure recognition through anchor optimization,’’ 2021, arXiv:2104.10538. [Online]. Available: http://arxiv.org/abs/2104.10538
[52] X. Zheng, D. Burdick, L. Popa, X. Zhong, and N. X. R. Wang, ‘‘Global table extractor (GTE): A framework for joint table identification and cell structure recognition using visual context,’’ in Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis., Jan. 2021, pp. 697–706.
[53] S. Raja, A. Mondal, and C. Jawahar, ‘‘Table structure recognition using top-down and bottom-up cues,’’ in Proc. Eur . Conf. Comput. Vis. Cham, Switzerland: Springer, 2020, pp. 70–86.
[54] R. Girshick, ‘‘Fast R-CNN,’’ in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 1440–1448.
[55] S. Ren, K. He, R. Girshick, and J. Sun, ‘‘Faster R-CNN: Towards real-time object detection with region proposal networks,’’ 2015, arXiv:1506.01497. [Online]. Available: http://arxiv.org/abs/1506.01497
[56] H. Breu, J. Gil, D. Kirkpatrick, and M. Werman, ‘‘Linear time Euclidean distance transform algorithms,’’ IEEE Trans. Pattern Anal. Mach. Intell., vol. 17, no. 5, pp. 529–533, May 1995.
[57] R. Fabbri, L. D. F. Costa, J. C. Torelli, and O. M. Bruno, ‘‘2D Euclidean distance transform algorithms: A comparative survey,’’ ACM Comput. Surveys, vol. 40, no. 1, pp. 1–44, Feb. 2008.
[58] I. Ragnemalm, ‘‘The Euclidean distance transform in arbitrary dimensions,’’ Pattern Recognit. Lett., vol. 14, no. 11, pp. 883–888, Nov. 1993.
[59] M. D. Zeiler and R. Fergus, ‘‘Visualizing and understanding convolutional networks,’’ in Proc. Eur . Conf. Comput. Vis. Cham, Switzerland: Springer, 2014, pp. 818–833.
[60] K. Simonyan and A. Zisserman, ‘‘V ery deep convolutional networks for large-scale image recognition,’’ 2014, arXiv:1409.1556. [Online]. Available: http://arxiv.org/abs/1409.1556
[61] M. Everingham, L. V an Gool, C. K. I. Williams, J. Winn, and A. Zisserman, ‘‘The Pascal visual object classes (VOC) challenge,’’ Int. J. Comput. Vis., vol. 88, no. 2, pp. 303–338, Jun. 2010.
[62] M. Li, L. Cui, S. Huang, F. Wei, M. Zhou, and Z. Li, ‘‘TableBank: Table benchmark for image-based table detection and recognition,’’ in Proc. 12th Lang. Resour . Eval. Conf., 2020, pp. 1918–1925.
[63] N. Sun, Y . Zhu, and X. Hu, ‘‘Faster R-CNN based table detection combining corner locating,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 1314–1319.
[64] L. Gao, X. Yi, Z. Jiang, L. Hao, and Z. Tang, ‘‘ICDAR2017 competition on page object detection,’’ in Proc. 14th IAPR Int. Conf. Document Anal. Recognit. (ICDAR), vol. 1, Nov. 2017, pp. 1417–1422.
[65] J. Dai, H. Qi, Y . Xiong, Y . Li, G. Zhang, H. Hu, and Y . Wei, ‘‘Deformable convolutional networks,’’ in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 764–773.
[66] M. Gobel, T. Hassan, E. Oro, and G. Orsi, ‘‘ICDAR 2013 table competition,’’ in Proc. 12th Int. Conf. Document Anal. Recognit., Aug. 2013, pp. 1449–1453.
[67] Z. Cai and N. V asconcelos, ‘‘Cascade R-CNN: Delving into high quality object detection,’’ in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 6154–6162.
[68] S. Xie, R. Girshick, P . Dollár, Z. Tu, and K. He, ‘‘Aggregated residual transformations for deep neural networks,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1492–1500.
[69] Y . Liu, Y . Wang, S. Wang, T. Liang, Q. Zhao, Z. Tang, and H. Ling, ‘‘Cbnet: A novel composite backbone network architecture for object detection,’’ in Proc. AAAI Conf. Artif. Intell., 2020, vol. 34, no. 7, pp. 11653–11660.
[70] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, ‘‘Y ou only look once: Unified, real-time object detection,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 779–788.
[71] J. Redmon and A. Farhadi, ‘‘YOLOv3: An incremental improvement,’’ 2018, arXiv:1804.02767. [Online]. Available: http://arxiv.org/abs/ 1804.02767
[72] Á. Casado-García, C. Domínguez, J. Heras, E. Mata, and V . Pascual, ‘‘The benefits of close-domain fine-tuning for table detection in document images,’’ in Proc. Int. Workshop Document Anal. Syst. Cham, Switzerland: Springer, 2020, pp. 199–215.
[73] K. He, G. Gkioxari, P . Dollár, and R. Girshick, ‘‘Mask R-CNN,’’ in Proc. IEEE Int. Conf. Comput. Vis., Oct. 2017, pp. 2961–2969.
[74] Y . Deng, A. Kanervisto, J. Ling, and A. M. Rush, ‘‘Image-to-markup generation with coarse-to-fine attention,’’ vol. 10, 2016, arXiv:1609.04938. [Online]. Available: http://arxiv.org/abs/1609.04938
[75] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y . Fu, and A. C. Berg, ‘‘SSD: Single shot multibox detector,’’ in Proc. Eur . Conf. Comput. Vis. Cham, Switzerland: Springer, 2016, pp. 21–37.
[76] T.-Y . Lin, P . Goyal, R. Girshick, K. He, and P . Dollár, ‘‘Focal loss for dense object detection,’’ in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2980–2988.
[77] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y . Zhao, D. Liu, Y . Mu, M. Tan, X. Wang, W. Liu, and B. Xiao, ‘‘Deep high-resolution representation learning for visual recognition,’’ IEEE Trans. Pattern Anal. Mach. Intell., early access, Apr. 1, 2020, doi: 10.1109/TPAMI.2020.2983686.
[78] S.-H. Gao, M.-M. Cheng, K. Zhao, X.-Y . Zhang, M.-H. Yang, and P . Torr, ‘‘Res2Net: A new multi-scale backbone architecture,’’ IEEE Trans. Pattern Anal. Mach. Intell., vol. 43, no. 2, pp. 652–662, Feb. 2021.
[79] K. Chen, W. Ouyang, C. C. Loy, D. Lin, J. Pang, J. Wang, Y . Xiong, X. Li, S. Sun, W. Feng, Z. Liu, and J. Shi, ‘‘Hybrid task cascade for instance segmentation,’’ in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 4974–4983.
[80] L. Gao, Y . Huang, H. Déjean, J.-L. Meunier, Q. Yan, Y . Fang, F. Kleber, and E. Lang, ‘‘ICDAR 2019 competition on table detection and recognition (cTDaR),’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 1510–1515.
[81] I. Kavasidis, S. Palazzo, C. Spampinato, C. Pino, D. Giordano, D. Giuffrida, and P . Messina, ‘‘A saliency-based convolutional neural network for table and chart detection in digitized documents,’’ 2018, arXiv:1804.06236. [Online]. Available: http://arxiv.org/abs/1804.06236
[82] F. Y u and V . Koltun, ‘‘Multi-scale context aggregation by dilated convolutions international conference on learning representations (ICLR) 2016,’’ Tech. Rep., 2016.
[83] P . Krähenbühl and V . Koltun, ‘‘Efficient inference in fully connected crfs with Gaussian edge potentials,’’ in Proc. Adv. Neural Inf. Process. Sys., vol. 24, 2011, pp. 109–117.
[84] S. S. Paliwal, V . D, R. Rahul, M. Sharma, and L. Vig, ‘‘TableNet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 128–133.
[85] J. Long, E. Shelhamer, and T. Darrell, ‘‘Fully convolutional networks for semantic segmentation,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2015, pp. 3431–3440.
[86] M. Holecek, A. Hoskovec, P . Baudiš, and P . Klinger, ‘‘Table understanding in structured documents,’’ in Proc. Int. Conf. Document Anal. Recognit. Workshops (ICDARW), Sep. 2019, pp. 158–164.
[87] P . Riba, A. Dutta, L. Goldmann, A. Fornés, O. Ramos, and J. Llados, ‘‘Table detection in invoice documents by graph neural networks,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 122–127.
[88] Y . Li, L. Gao, Z. Tang, Q. Yan, and Y . Huang, ‘‘A GAN-based feature generator for table detection,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 763–768.
[89] A. W. Harley, A. Ufkes, and K. G. Derpanis, ‘‘Evaluation of deep convolutional nets for document image classification and retrieval,’’ in Proc. 13th Int. Conf. Document Anal. Recognit. (ICDAR), Aug. 2015, pp. 991–995.
[90] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, ‘‘Generative adversarial networks,’’ 2014, arXiv:1406.2661. [Online]. Available: http://arxiv. org/abs/1406.2661
[91] O. Ronneberger, P . Fischer, and T. Brox, ‘‘U-net: Convolutional networks for biomedical image segmentation,’’ in Proc. Int. Conf. Med. Image Comput. Compt. Intervent. Cham, Switzerland: Springer, 2015, pp. 234–241.
[92] S. A. Siddiqui, P . I. Khan, A. Dengel, and S. Ahmed, ‘‘Rethinking semantic segmentation for table structure recognition in documents,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 1397–1402.
[93] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, ‘‘ImageNet large scale visual recognition challenge,’’ Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, Dec. 2015.
[94] Y . Zou and J. Ma, ‘‘A deep semantic segmentation model for image-based table structure recognition,’’ in Proc. 15th IEEE Int. Conf. Signal Process. (ICSP), vol. 1, Dec. 2020, pp. 274–280.
[95] M. B. Dillencourt, H. Samet, and M. Tamminen, ‘‘A general approach to connected-component labeling for arbitrary image representations,’’ J. ACM, vol. 39, no. 2, pp. 253–280, Apr. 1992.
[96] S. R. Qasim, H. Mahmood, and F. Shafait, ‘‘Rethinking table recognition using graph neural networks,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 142–147.
[97] F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini, ‘‘The graph neural network model,’’ IEEE Trans. Neural Netw., vol. 20, no. 1, pp. 61–80, Jan. 2009.
[98] Z. Chi, H. Huang, H.-D. Xu, H. Y u, W. Yin, and X.-L. Mao, ‘‘Complicated table structure recognition,’’ 2019, arXiv:1908.04729. [Online]. Available: http://arxiv.org/abs/1908.04729
[99] W. Xue, Q. Li, and D. Tao, ‘‘ReS2TIM: Reconstruct syntactic structures from table images,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 749–755.
[100] W. Xue, Q. Li, Z. Zhang, Y . Zhao, and H. Wang, ‘‘Table analysis and information extraction for medical laboratory reports,’’ in Proc. IEEE 16th Int. Conf Dependable, Autonomic Secure Comput., 16th Int. Conf Pervas. Intell. Comput., 4th Int. Conf Big Data Intell. Comput. Cyber Sci. Technol. Congr . (DASC/PiCom/DataCom/CyberSciTech), Aug. 2018, pp. 193–199.
[101] C. Tensmeyer, V . I. Morariu, B. Price, S. Cohen, and T. Martinez, ‘‘Deep splitting and merging for table structure decomposition,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 114–121.
[102] S. A. Khan, S. M. D. Khalid, M. A. Shahzad, and F. Shafait, ‘‘Table structure extraction with bi-directional gated recurrent unit networks,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 1366–1371.
[103] J. Chung, C. Gulcehre, K. Cho, and Y . Bengio, ‘‘Empirical evaluation of gated recurrent neural networks on sequence modeling,’’ 2014, arXiv:1412.3555. [Online]. Available: http://arxiv.org/abs/1412.3555
[104] S. Hochreiter and J. Schmidhuber, ‘‘Long short-term memory,’’ Neural Comput., vol. 9, no. 8, pp. 1735–1780, 1997.
[105] G. Klein, Y . Kim, Y . Deng, J. Senellart, and A. M. Rush, ‘‘OpenNMT: Open-source toolkit for neural machine translation,’’ 2017, arXiv:1701.02810. [Online]. Available: http://arxiv.org/abs/1701.02810
[106] J. Wang, K. Chen, S. Yang, C. C. Loy, and D. Lin, ‘‘Region proposal by guided anchoring,’’ in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 2965–2974.
[107] F. Y u and V . Koltun, ‘‘Multi-scale context aggregation by dilated convolutions,’’ 2015, arXiv:1511.07122. [Online]. Available: http://arxiv.org/ abs/1511.07122
[108] T. N. Kipf and M. Welling, ‘‘Semi-supervised classification with graph convolutional networks,’’ 2016, arXiv:1609.02907. [Online]. Available: http://arxiv.org/abs/1609.02907
[109] Y . Deng, D. Rosenberg, and G. Mann, ‘‘Challenges in end-to-end neural scientific table recognition,’’ in Proc. Int. Conf. Document Anal. Recognit. (ICDAR), Sep. 2019, pp. 894–901.
[110] Y . Deng, A. Kanervisto, J. Ling, and A. M. Rush, ‘‘Image-to-markup generation with coarse-to-fine attention,’’ in Proc. Int. Conf. Mach. Learn., 2017, pp. 980–989.
[111] S. F. Rashid, A. Akmal, M. Adnan, A. A. Aslam, and A. Dengel, ‘‘Table recognition in heterogeneous documents using machine learning,’’ in Proc. 14th IAPR Int. Conf. Document Anal. Recognit. (ICDAR), vol. 1, Nov. 2017, pp. 777–782.
[112] I. Phillips, ‘‘User’s reference manual for the UW English/technical document image database III,’’ UW-III English/Tech. Document Image Database Manual, Univ. Washington English Document Image Database, Washington, DC, USA, 1996.
[113] A. Mondal, P . Lipps, and C. Jawahar, ‘‘IIIT-AR-13K: A new dataset for graphical object detection in documents,’’ in Proc. Int. Workshop Document Anal. Syst. Cham, Switzerland: Springer, 2020, pp. 216–230.
[114] D. M. W. Powers, ‘‘Evaluation: From precision, recall and Fmeasure to ROC, informedness, markedness and correlation,’’ 2020, arXiv:2010.16061. [Online]. Available: http://arxiv.org/abs/2010.16061
[115] M. B. Blaschko and C. H. Lampert, ‘‘Learning to localize objects with structured output regression,’’ in Proc. Eur . Conf. Comput. Vis. Cham, Switzerland: Springer, 2008, pp. 2–15.
[116] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, ‘‘BLEU: A method for automatic evaluation of machine translation,’’ in Proc. 40th Annu. Meeting Assoc. Comput. Linguistics, 2002, pp. 311–318.
[117] D. G. Kleinbaum, K. Dietz, M. Gail, M. Klein, and M. Klein, Logistic Regression. New Y ork, NY , USA: Springer-V erlag, 2002.
[118] Y . Wang, Y . Sun, Z. Liu, S. E. Sarma, M. M. Bronstein, and J. M. Solomon, ‘‘Dynamic graph CNN for learning on point clouds,’’ ACM Trans. Graph., vol. 38, no. 5, pp. 1–12, Nov. 2019.
[119] S. R. Qasim, J. Kieseler, Y . Iiyama, and M. Pierini, ‘‘Learning representations of irregular particle-detector geometry with distanceweighted graph networks,’’ Eur . Phys. J. C, vol. 79, no. 7, pp. 1–11, Jul. 2019.
[120] M. Pawlik and N. Augsten, ‘‘Tree edit distance: Robust and memoryefficient,’’ Inf. Syst., vol. 56, pp. 157–173, Mar. 2016.
[121] V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. V eness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, and S. Petersen, ‘‘Human-level control through deep reinforcement learning,’’ Nature, vol. 518, pp. 529–533, 2015.
[122] A. G. Barto, ‘‘Reinforcement learning,’’ in Neural Systems for Control. Amsterdam, The Netherlands: Elsevier, 1997, pp. 7–30.
[123] J. Park, E. Lee, Y . Kim, I. Kang, H. I. Koo, and N. I. Cho, ‘‘Multi-lingual optical character recognition system using the reinforcement learning of character segmenter,’’ IEEE Access, vol. 8, pp. 174437–174448, 2020.