语音识别模型CTC,RNN-T,Neural Transducer,MoCha学习笔记
语音识别模型进化史以下4篇文章结合之前的LAS是深度学习在语音识别邻域的重要尝试
• Connectionist Temporal Classification (CTC)[Graves, et al., ICML’06]
• RNN Transducer (RNN-T)[Graves, ICML workshop’12]
• Neural Transducer[Jaitly, et al., NIPS’16]
• Monotonic Chunkwise Attention (MoChA)[Chiu, et al., ICLR’18]
在上一篇论文中我们知道LAS是属于端到端的语音辨识系统,作为端到端识别的开端具有开创性意义,但是LAS的问题就在于我们需要听完一整段话,才可以进行识别,但是在大部分时候,实时的语音识别更有意义。那么我们该怎么做呢?CTC可以解决实时翻译的问题。
CTC
要做到实时翻译,首先我们将之前模型的双向的RNN变为单项序列,其次我们把之前LAS的解码器不要了,我们只需要一个编码器。通过编码产生的结果直接放到线性的分类器上去进行分类,线性分类器可以看成解码的部分。
当然CTC还包括其他的细节,
1.对于输入是T 个音频特征,他会输出T个tokens,(CTC的token一般用字母Grapheme,不考虑降采样)。
2.输出的tokens肯定没有输入的多,所以CTC想到一个补齐(alignment)的方法可以重复产生相同的tokens,最后对输出的T个tokens进行操作使得tokens变成一段话(将 blank 去除,重复字母去除),举个例子。

一目了然,删除重复字符与空集
这样做还有一个问题就是我这个 blank 可以放在任何地方使其输出的结果都是deep那么这个时候,训练标签该如何打呢?CTC的方法就是所有的可能性都保留。
CTC存在的问题
1.每一次的输出结果是相互独立的。
2.可能会出现重复输出的问题。举个例子

在C与空集之间,应该是C但是因为辨识度的问题产生出了空集就会对输出结果产生2个C
RNN Transducer (RNN-T)
先介绍一下RNA(Recurrent Neural Aligner)
为了解决CTC的输入与输出之间的相互独立性,我们可以将之强CTC产生的输出结果接一个一个RNN循环。

CTC我们知道是吃一个输入产生一个输出,那么有时候还会遇到这样的情况就是吃一个输入产生多个输出。比如说th,就很多情况都是在一起的,把t跟h分开反而会不太好。那么我们就引入了RNN-T,他的功能就在于每一个输入音频特征我们给定输出的音频tokens而这个token不受长度的限制。如下图所示。

T个token输入可以产生T个空集

RNN也可以是一个重新训练的模型像这样
RNN-T与CTC有相同的问题就在于不知道什么时候产生 。同样跟CTC一样他会穷举所有的可能输出结果的标签。
Neural Transducer
相当于RNN-T加Attention,为了考虑更多值的影响在输入端加入attention,但是attention是固定长度的。如下图

为了使得输入段长度变得可变,每次都集中在我认为重要的地方提出,Monotonic Chunkwise Attention (MoChA),每一个输入都先进行一次判定,判定这一次输出的注意力是否集中在这里。

Summarry
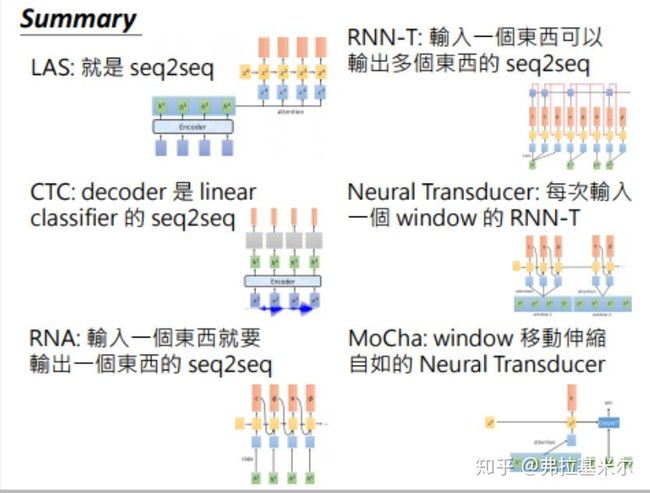
LAS:端到端
CTC:线性端到端
RNA:CTC+RNN
RNN-T:一对多的RNA
Neural Transducer:具有注意力机制的RNN-T
MoChA:可以移动窗口的Neural Transducer