【PyTorch 05】神经网络代码结构
目录
1. 搭建神经网络 torch.nn.Module 的使用
2. 卷积操作 nn.functional.Conv2d(二维卷积)
3. 卷积层(Convolution-Layers) torch.nn.Conv2d
4. 最大池化(Pooling layers)
5. 非线性激活 Non-linear Activations (weighted sum, nonlinearity 之 nn.ReLu)
6. 非线性激活 Non-linear Activations (weighted sum, nonlinearity 之 torch.nn.Sigmoid)
7. 线性层 (Linear Lyers)
8. 其他层简单介绍
8. 模型 nn.Sequential
9. 损失函数 和 反向传播
10. 优化器 (torch.optim.SGD)
参考视频:《PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】》
1. 搭建神经网络 torch.nn.Module 的使用
# 作者:要努力,努力,再努力
# 开发时间:2022/5/4 15:24
from torch import nn
import torch
# 搭建神经网络 torch.nn.Module 的使用 nn-> nerual network
class NewNN(nn.Module): # NewNN 继承了 nn.Module 类(神经网络模板)
def __init__(self):
super().__init__()
def forward(self, input): # 前向传播,神经网络中还有一个反向传播
output = input + 1;
return output
newnn = NewNN()
x = torch.tensor(1.0)
output = newnn(x)
print(output)
2. 卷积操作 nn.functional.Conv2d(二维卷积)
| 参数 | 说明 | 默认值 |
| input | 输入数据 | 无 |
| weight | 卷积核 | 无 |
| bias | 偏置 | 无 |
| stride | 步径 | 1 |
| padding | 间隔 | 0 |
卷积计算:对应位相乘再相加。

1*1+2*2+1*0+0*0+1*1+2*0+2*1+1*2+1*0 = 1+4+0+0+1+0+2+2+0=10
最后会得到3*3的矩阵。
# 作者:要努力,努力,再努力
# 开发时间:2022/5/4 21:35
import torch
import torch.nn.functional as F
# 输入
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 卷积核
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# batch-size = 1 一次训练所选取的样本数
# channel = 1 一次训练所选取的卷积核数
# reshape 将数据二参变四参
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1)
print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
3. 卷积层(Convolution-Layers) torch.nn.Conv2d
| 参数 | 说明 | 默认值 |
| in_channels | 输入通道数 | 无 |
| out_channels | 输出通道数 | 无 |
| kernel_size | 卷积核大小 | 无 |
| stride | 步径 | 1 |
| padding | 间隔 | 0 |
| dilation | 空洞卷积 | 1 |
# 作者:要努力,努力,再努力
# 开发时间:2022/5/5 10:42
import torch
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets
from torchvision import transforms
datasets = datasets.CIFAR100(root='./dataset', train=False, transform=transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset=datasets, batch_size=64, shuffle=False, num_workers=0, drop_last=False)
class Eccu(nn.Module):
def __init__(self):
super(Eccu, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
eccu = Eccu()
# print(eccu)
writer = SummaryWriter('logs')
step = 0
for data in dataloader:
imgs, targets = data
output = eccu(imgs)
# print(imgs.shape) # 卷积前 torch.Size([64, 3, 32, 32])
# print(output.shape) # 卷积后 torch.Size(torch.Size([64, 6, 30, 30]))
writer.add_images('input', imgs, step)
# 因为add_image必须输出的是3个channel,所以对数据需要变换
# (-1, 3, 30, 30) 第一个batch_size不知道是多少的时候,可以填 -1 ,会根据后面的进行自动变换
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images('output', output, step)
step += 1
writer.close()
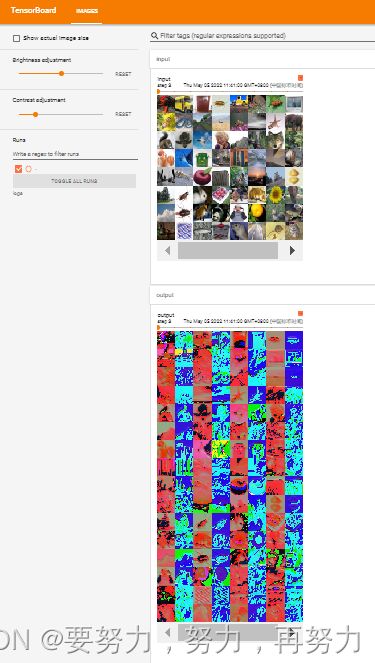
32 * 32 是如何变成 30*30的:
计算过程:
4. 最大池化(Pooling layers)
-
kernel_size – the size of the window to take a max over
-
stride – the stride of the window. Default value is
kernel_size -
padding – implicit zero padding to be added on both sides
-
dilation – a parameter that controls the stride of elements in the window
-
return_indices – if
True, will return the max indices along with the outputs. Useful for torch.nn.MaxUnpool2d later -
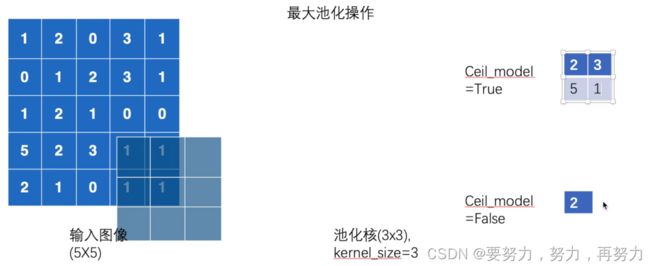
ceil_mode – when True, will use ceil instead of floor to compute the output shape
| kernel_size | 池化核,窗口 |
| stride | 步径,默认值为kernel_size |
| padding | 边距 |
| dilation | 空洞卷积 |
| return_indices | |
| ceil_mode | True,向上取整;False,向下取整。 默认值为 False |
设 kernel_size = 3,则会生成一个 3*3 的窗口,这个窗口会去对应输入图像,取最大值,步径也等于kernel_size,即也是3,则每次右移和下移都会移动3个位置;当不足3*3=9个数的时候,根据ceil_mode去判断,ceil_mode为True的时候,就直接取最大值,当ceil_mode为false的时候就不取值。
计算过程跟上面求卷积的方式一样。
池化的应用就相当于:一个1080p的视频,经过池化,降维720p的像素的视频,也能提供大部分需求,资源包大小会有所下降。
# 作者:要努力,努力,再努力
# 开发时间:2022/5/5 14:08
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 神经网络——最大池化
class Eccu(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=False) # ceil_mode--True,向上取整;False,向下取整。
def forward(self, input):
output = self.maxpool(input)
return output
# 1. 手动输入图像信息
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32) # 1->1.0 变成浮点数
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)
eccu = Eccu()
output = eccu(input)
print(output)
# 2. 加载图像信息,展示到tensorboard上
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset=dataset, batch_size=64, shuffle=False, num_workers=0, drop_last=False)
step = 0
writer = SummaryWriter('log_maxpool')
for data in dataloader:
imgs, targets = data
writer.add_images('input', imgs, step)
output = eccu(imgs) # 因为输出的channel也是3,所以不需要变换
writer.add_images('output', output, step)
step += 1
writer.close()
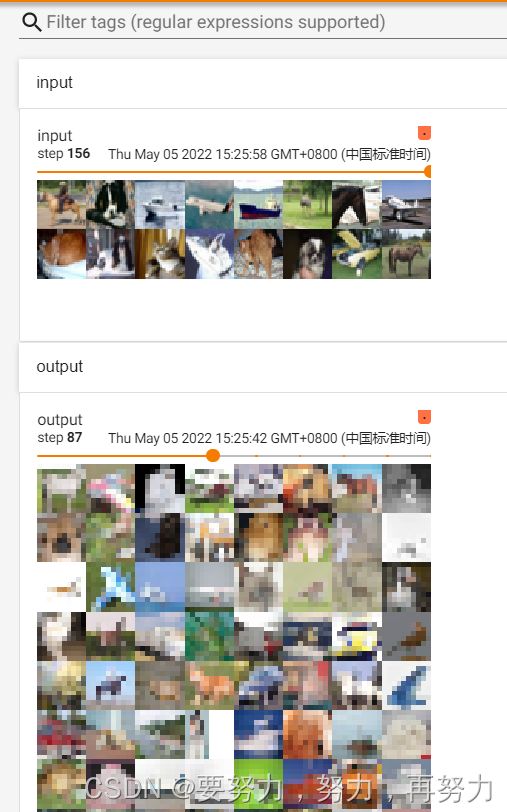
最大池化 tensorboard 可视化(打马赛克我有一手):
5. 非线性激活 Non-linear Activations (weighted sum, nonlinearity 之 nn.ReLu)
inplace – can optionally do the operation in-place. Default: False 是否在原来的位置进行替换。
# 作者:要努力,努力,再努力
# 开发时间:2022/5/5 15:46
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (1, 1, 2, 2))
print(input.shape)
class Eccu(nn.Module):
def __init__(self):
super().__init__()
self.relu = ReLU()
def forward(self, input):
output = self.relu(input)
return output
eccu = Eccu()
output = eccu(input)
print(output)
6. 非线性激活 Non-linear Activations (weighted sum, nonlinearity 之 torch.nn.Sigmoid)
(代码是上一小节的基础上添加的)
# 作者:要努力,努力,再努力
# 开发时间:2022/5/5 15:46
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class Eccu(nn.Module):
def __init__(self):
super().__init__()
self.relu = ReLU()
self.sigmoid = Sigmoid()
def forward(self, input):
# output = self.relu(input)
output = self.sigmoid(input)
return output
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10('./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset=dataset, batch_size=64, shuffle=False, num_workers=0, drop_last=False)
eccu = Eccu()
output = eccu(input)
print(output)
step = 0
writer = SummaryWriter('log_sigmoid')
for data in dataloader:
imgs, targets = data
writer.add_images('input', imgs, global_step=step)
output = eccu(imgs)
writer.add_images('output', output, global_step=step)
step += 1
writer.close()
非线性变换的目的:在网络中引入非线性特征,提高泛化能力。

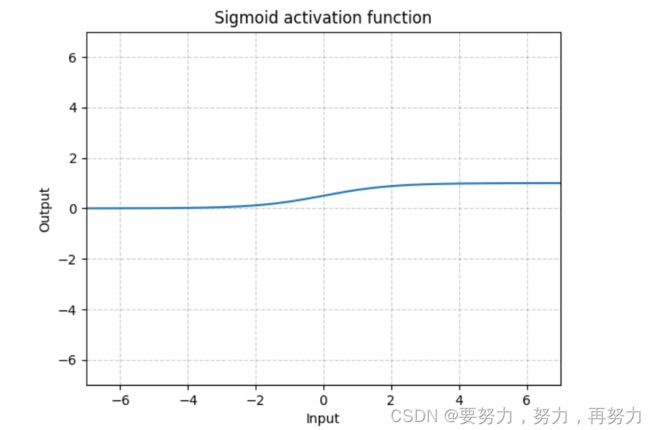
输入数,输出的数据都会处于0-1之间。将输入数据代入到sigmoid函数中,得到一个在这个光滑曲线上的某个点,若该点大于0.5,认为事件的概率为1,小于,则为0
7. 线性层 (Linear Lyers)
Parameters
-
in_features – size of each input sample
-
out_features – size of each output sample
-
bias – If set to
False, the layer will not learn an additive bias. Default:True

全连接神经网络:
加不加 b 是由 bias(偏置)来决定的。
g1 就是由 ( k1 * x1 + b1 ) + ( k2 * x2 + b2 ) + ( k... * x... + b... ) + ( kd * xd + bd ) 所得到的。
weight 相当于 k .
bias 相当于 b.

# 作者:要努力,努力,再努力
# 开发时间:2022/5/5 17:31
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset=dataset, batch_size=64, shuffle=False, num_workers=0, drop_last=True) # 丢弃最后的
class Eccu(nn.Module):
def __init__(self):
super().__init__()
self.linear = Linear(196608, 10)
def forward(self, input):
output = self.linear(input)
return output
eccu = Eccu()
for data in dataloader:
imgs, targets = data
print(imgs.shape) # torch.Size([64, 3, 32, 32])
# 将这个图片摊平
# 1. 将原本是并排的像素,全部变为横向排列,-1 是让他自己计算
# output = torch.reshape(imgs, (1, 1, 1, -1))
# 2. torch.flatten
output = torch.flatten(imgs)
print(output.shape)
# reshape:torch.Size([1, 1, 1, 10]) 、 flatten:torch.Size([196608])
# 进入线性神经网络
output = eccu(output)
print(output.shape) # torch.Size([10]) 把196608大小进入线性神经网络变为10
print('========================')8. 其他层简单介绍
| Normalization Layers | 正则化,可以加快神经网络训练速度 |
| Recurrent Layers | 主要用于文字识别的网络结构 |
| Droupout Layers | 主要防止过拟合 |
| Sparse Layers | 做自然语言处理 |
| Distance Function | 计算误差 |
torchvision.models 中直接使用,不用构建神经网络:
| Object Detection | 目标检测 |
| Instance Segmentation | 语义分割 |
| Person Keypoint Detection | 人体结构姿态检测 |
8. 模型 nn.Sequential
以CIFAR 10 为例:
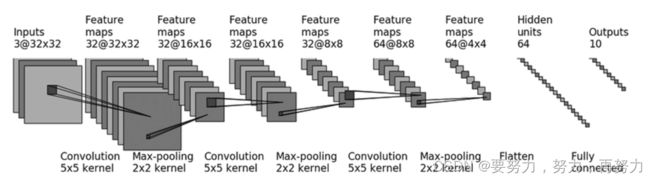
CIFAR 10 模型结构
两种方式实现这个神经网络:
# 作者:要努力,努力,再努力
# 开发时间:2022/5/5 21:42
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Eccu(nn.Module):
def __init__(self):
super().__init__()
# 1. 一般方式
# self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2)
# self.maxpool = MaxPool2d(kernel_size=2)
# self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2)
# self.maxpool2 = MaxPool2d(kernel_size=2)
# self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)
# self.maxpool3 = MaxPool2d(kernel_size=2)
# self.flatten = Flatten()
# self.linear1 = Linear(1024, 64) # 1024 = 64 * 4 * ; 尝试将 1024 -> 改成 一个随便的数,去看下面的程序会不会报错
# self.linear2 = Linear(64, 10)
# 2. Sequential 方式
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, input):
# 1. 一般方式
# output = self.conv1(input)
# output = self.maxpool(output)
# output = self.conv2(output)
# output = self.maxpool2(output)
# output = self.conv3(output)
# output = self.maxpool3(output)
# output = self.flatten(output) # torch.Size([64, 1024])
# output = self.linear1(output)
# output = self.linear2(output)
# 2. Sequential 方式
output = self.model1(input)
return output
eccu = Eccu()
print(eccu)
input = torch.ones((64, 3, 32, 32)) # 检测网络是否有错
output = eccu(input)
print(output.shape)
# 可视化
writer = SummaryWriter('logs_sequential')
writer.add_graph(eccu, input)
writer.close()tensorboard 上可以显示

太厉害了!
9. 损失函数 和 反向传播
nn.L1Loss(size_average=None, reduce=None, reduction='mean')
-
reduction (string, optional) – Specifies the reduction to apply to the output:
'none'|'mean'|'sum'.'none': no reduction will be applied,'mean': the sum of the output will be divided by the number of elements in the output,'sum': the output will be summed. Note:size_averageandreduceare in the process of being deprecated, and in the meantime, specifying either of those two args will overridereduction. Default:'mean'
① 计算实际输出和目标之间的差距
② 为我们更新输出提供一定的依据(反向传播)
CrossEntropyLoss :交叉熵

# 作者:要努力,努力,再努力
# 开发时间:2022/5/6 8:37
import torch
from torch.nn import L1Loss, MSELoss
from torch import nn
input = torch.tensor([1, 2, 3], dtype=torch.float32)
target = torch.tensor([1, 2, 5], dtype=torch.float32)
input = torch.reshape(input, (1, 1, 1, 3))
target = torch.reshape(target, (1, 1, 1, 3))
loss = L1Loss(reduction='sum')
result = loss(input, target)
print(result) # 默认: (0+0+2)/3 = 0.666 ; sum : (0+0+2) = 2
lossmse = MSELoss()
resultMse = lossmse(input, target)
print(resultMse) # (0+0+2^2)/3 = 1.333
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1,3))
loss_cross = nn.CrossEntropyLoss()
result_loss = loss_cross(x, y)
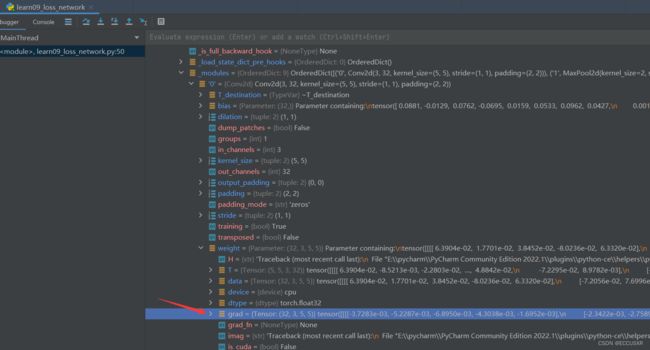
print(result_loss)反向传播:尝试如何调整网络过程中的参数才会导致loss变小,梯度grad的理解可以当成“斜率”。

梯度下降
经过神经网络后,计算交叉熵,并经过反向传播,可以得到梯度grad.
# 作者:要努力,努力,再努力
# 开发时间:2022/5/6 9:14
# 作者:要努力,努力,再努力
# 开发时间:2022/5/5 21:42
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset=dataset, batch_size=1, shuffle=False, num_workers=0, drop_last=False)
class Eccu(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, input):
output = self.model1(input)
return output
loss = CrossEntropyLoss()
eccu = Eccu()
for data in dataloader:
imgs, target = data
output = eccu(imgs)
# print(output, target)
# tensor([[ 0.0745, 0.0858, -0.1424, -0.0110, 0.1265, -0.1313, -0.0370, -0.0841, 0.1071, -0.1464]],
# grad_fn=) tensor([9])
# 输出10个类别,每个类别的概率 target为9
result = loss(output, target)
result.backward() # 反向传播
print(result)
10. 优化器 (torch.optim.SGD)
# 作者:要努力,努力,再努力
# 开发时间:2022/5/6 9:14
# 作者:要努力,努力,再努力
# 开发时间:2022/5/5 21:42
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset=dataset, batch_size=1, shuffle=False, num_workers=0, drop_last=False)
class Eccu(nn.Module):
def __init__(self):
super().__init__()
self.model1 = Sequential(
Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, input):
output = self.model1(input)
return output
eccu = Eccu()
loss = CrossEntropyLoss()
optims = torch.optim.SGD(eccu.parameters(), lr=0.01) # 设置优化器。lr = leaning rate 学习速率
for epoch in range(20): # 一般要学习成百上千次
runing_loss = 0.0
for data in dataloader:
imgs, target = data
output = eccu(imgs)
# print(output, target)
# tensor([[ 0.0745, 0.0858, -0.1424, -0.0110, 0.1265, -0.1313, -0.0370, -0.0841, 0.1071, -0.1464]],
# grad_fn=) tensor([9])
# 输出10个类别,每个类别的概率 target为9
result = loss(output, target)
optims.zero_grad() # 必须设置,每一次循环都要将梯度置为零
result.backward() # 反向传播,得到梯度
optims.step() # 对模型参数调优
# print(result)
runing_loss = runing_loss + result # 整体误差总和
print(runing_loss) 总误差值
