【目标检测】yolo系列:从yolov1到yolov5之YOLOv3详解及复现
在v1、v2的原理和技巧介绍之后,v3除了网络结构,其余的改变并不多。本文着重描述yolov3的原理细节。
相关阅读:
论文:YOLOv3: An Incremental Improvement
源码:https://github.com/ultralytics/yolov3
1. Yolov3网络结构
1.1 backbone:Darknet-53
Yolov3使用Darknet-53作为整个网络的分类骨干部分。backbone部分由Yolov2时期的Darknet-19进化至Darknet-53,加深了网络层数,引入了Resnet中的跨层加和操作。
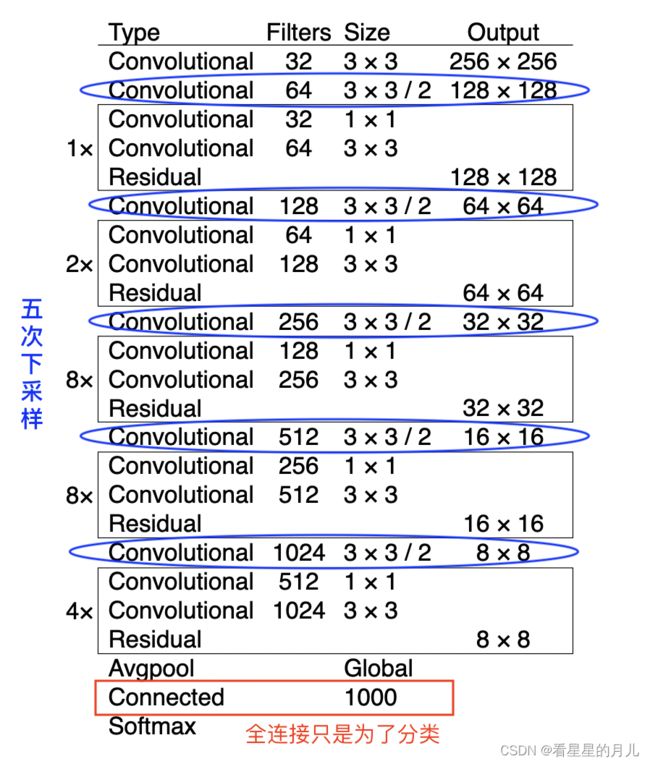
1.2 网络结构解析
借鉴Yolo三部曲解读——Yolov3
主要结构
Yolov3是一个全卷积网络,只有卷积层,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,作者直接摒弃了POOLing,通过调节卷积步长控制输出特征图的尺寸,即用conv的stride来实现降采样。所以对于输入图片尺寸没有特别限制。
下图流程图中,输入图片以256✖️256✖️3作为样例。
思想
Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为N✖️N✖️[3✖️(4+1+80)] ,N✖️N为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值 t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为8✖️8✖️255。
输出
Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。输入图像经过Darknet-53(无全连接层),再经过Yoloblock生成的特征图被当作两用,第一用为经过33卷积层、11卷积之后生成特征图一,第二用为经过1*1卷积层加上采样层,与Darnet-53网络的中间层输出结果进行拼接,产生特征图二。同样的循环之后产生特征图三。
concat操作
concat操作与加和操作的区别:
- 加和操作来源于ResNet思想,将输入的特征图,与输出特征图对应维度进行相加,即 y = f(x) + x;
- concat操作源于DenseNet网络的设计思路,将特征图按照通道维度直接进行拼接,例如8✖️8✖️16的特征图与8✖️8✖️16的特征图拼接后生成8✖️8✖️32的特征图。
上采样层
上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将88的图像变换为1616。上采样层不改变特征图的通道数。为了加强算法对小目标检测的精确度,YOLOv3中采用类似FPN的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52),在多个scale的feature map上做检测。
- 缩小图像(或称为下采样(subsampled),如池化)的主要目的有两个:使得图像符合显示区域的大小;生成对应图像的缩略图。
- 放大图像(或称为上采样(upSampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
总结:Yolo的整个网络,吸取了Resnet、Densenet、FPN的精髓,可以说是融合了目标检测当前业界最有效的全部技巧。
2. Yolo输出特征图解码(前向过程)
根据不同的输入尺寸,会得到不同大小的输出特征图,以上图为例,输入图片256 × 256 × 3为例,输出的特征图为8 × 8 × 255、16 × 16 × 255、32 × 32 × 255。在Yolov3的设计中,每个特征图的每个格子中,都配置3个不同的先验框,所以最后三个特征图,这里暂且reshape为8 × 8 × 3 × 85、16 × 16 × 3 × 85、32 × 32 × 3 × 85,这样更容易理解,在代码中也是reshape成这样之后更容易操作。
三张特征图就是整个Yolo输出的检测结果,检测框位置(4维)、检测置信度(1维)、类别(80维)都在其中,加起来正好是85维。特征图最后的维度85,代表的就是这些信息,而特征图其他维度N × N × 3,N × N代表了检测框的参考位置信息,3是3个不同尺度的先验框。下面详细描述怎么将检测信息解码出来:
先验框
在Yolov1中,网络直接回归检测框的宽、高,这样效果有限。所以在Yolov2中,改为了回归基于先验框的变化值,这样网络的学习难度降低,整体精度提升不小。
Yolov3沿用了Yolov2中关于先验框的技巧,并且使用k-means对数据集中的标签框进行聚类,得到类别中心点的9个框,作为先验框。在COCO数据集中(原始图片全部resize为416 × 416),九个框分别是 (10×13),(16×30),(33×23),(30×61),(62×45),(59× 119), (116 × 90), (156 × 198),(373 × 326) ,顺序为w × h。
注:先验框只与检测框的w、h有关,与x、y无关。
检测框解码
有了先验框与输出特征图,就可以解码检测框 x,y,w,h。
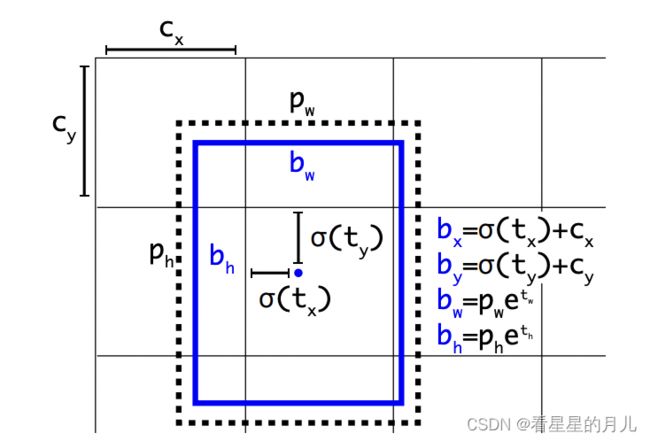
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y \\ b_w = {p_w}e^{t_w} \\ b_h = {p_h}e^{t_h} bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=pheth
如下图所示, σ ( t x ) , σ ( t y ) \sigma(t_x), \sigma(t_y) σ(tx),σ(ty) 是通过 Euler integral是基于矩形框中心点左上角格点坐标的偏移量, sigma是激活函数,论文中作者使用sigmoid。 p w , p h {p_w}, {p_h} pw,ph 是先验框的宽、高,通过上述公式,计算出实际预测框的宽高 b w , b h {b_w}, {b_h} bw,bh, e t {e^t} et为采样率。
置信度
置信度在输出85维中占固定一位,由sigmoid函数解码即可,解码之后数值区间在[0,1]中。
类别解码
COCO数据集有80个类别,所以类别数在85维输出中占了80维,每一维独立代表一个类别的置信度。使用sigmoid激活函数替代了Yolov2中的softmax,取消了类别之间的互斥,可以使网络更加灵活。
三个特征图一共可以解码出 8 × 8 × 3 + 16 × 16 × 3 + 32 × 32 × 3 = 4032 个box以及相应的类别、置信度。这4032个box,在训练和推理时,使用方法不一样:
- 训练时:4032个box全部送入打标签函数,进行后一步的标签以及损失函数的计算。
- 推理时:选取一个置信度阈值,取出每一类得分大于一定阈值的框和得分进行排序,过滤掉低阈值box,利用框的位置和得分进行经过NMS(非极大值抑制),最后可以得出概率最大的边界框,也就是整个网络的预测结果了。
3. 训练策略与损失函数(反向过程)
训练策略
预测框一共分为三种情况:正例(positive)、负例(negative)、忽略样例(ignore)。
- 正例:任取一个ground truth,与4032个框全部计算IOU,IOU最大的预测框,即为正例。并且一个预测框,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的4031个检测框中,寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。预测框为对应的ground truth box标签(需要反向编码,使用真实的x、y、w、h计算出 [公式] );类别标签对应类别为1,其余为0;置信度标签为1。
- 忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例。忽略样例不产生任何loss。
- 负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5),则为负例。负例只有置信度产生loss,置信度标签为0。
损失函数
YOLOv3重要改变之一:No more softmaxing the classes。
YOLO v3现在对图像中检测到的对象执行多标签分类。
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。
一些训练策略的解释
1.ground truth为什么不按照中心点分配对应的预测box?
在Yolov3的训练策略中,不再像Yolov1那样,每个cell负责中心落在该cell中的ground truth。原因是Yolov3一共产生3个特征图,3个特征图上的cell,中心是有重合的。训练时,可能最契合的是特征图1的第3个box,但是推理的时候特征图2的第1个box置信度最高。所以Yolov3的训练,不再按照ground truth中心点,严格分配指定cell,而是根据预测值寻找IOU最大的预测框作为正例。
2.为什么有忽略样例?
忽略样例是Yolov3中的点睛之笔。由于Yolov3使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分。比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想.
参考文章:https://zhuanlan.zhihu.com/p/76802514