周志华《机器学习》西瓜书 小白Python学习笔记(五) ———— 第五章 神经网络
周志华《机器学习》西瓜书 小白Python学习笔记(五) ———— 第五章 神经网络
-
- 什么是神经网络
- 神经网络的结构
-
- 输入层、隐含层和输出层
- 激活函数
- 权重
- 偏置
- 损失函数
- 神经网络原理
-
- 正向传播
- 负向传播
什么是神经网络
神经网络起源于生物神经元的生物原理,生物神经元通常包括细胞体、树突和轴突等部分。其中,树突适用于接受输入信息,突触对输入信息进行处理,达到一定条件后由轴突产生输出,此时神经元表现为激活兴奋的状态。
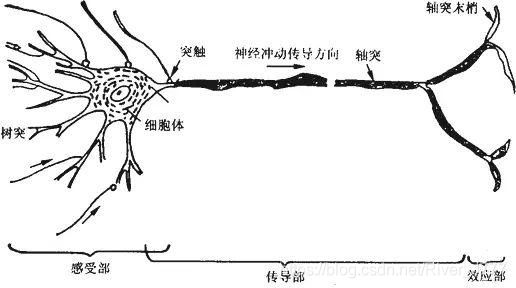
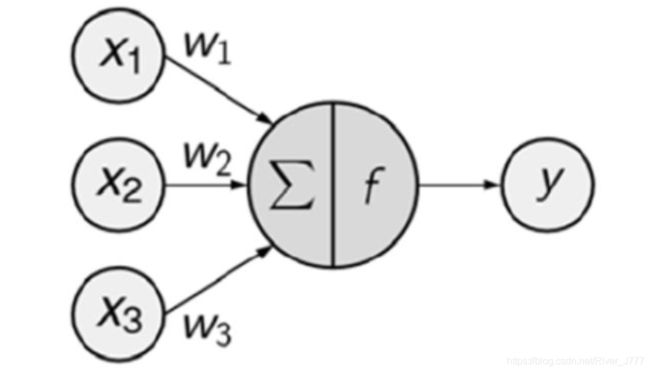
模仿生物神经元的工作原理,科学家们提出了人工神经元(感知机)的概念,基本的感知机如下图所示。输入信号 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3,经过赋予相应的权重 w 1 , w 2 , w 3 w_1,w_2,w_3 w1,w2,w3后,经过汇总后作为自变量输入到函数 f f f中,这个函数称为激活函数,激活函数通过判断产生输出信号 y y y。
神经网络的结构
输入层、隐含层和输出层
一般的神经网络包含三个部分,分别是输入层、隐含层和输出层,由下图所示。输入层,一般输入的是样本的各个特征的数据信息,有几个特征就会有几个输入的结点;隐含层位于输入层与输出层之间,可以为一层也可以为多层;输出层则对应标签值,若标签为猫或狗或猪,则有三个输出结点,哪个结点的输出数值越接近1,就被判断为哪个标签。

激活函数
之前提到隐层中的每个结点都会接受上一层所有结点传递来的信息 w i x i w_ix_i wixi,经过加总为 ∑ w i x i \sum{w_ix_i} ∑wixi后带入激活函数,结果作为本结点的输出传递到下一层隐含层或者输出层。那激活函数是什么呢?
激活函数是用来加入非线性因素,并将输入的 ∑ w i x i \sum{w_ix_i} ∑wixi压缩到0~1之间的数值,所以它一般要满足非线性、可微性和单调性等性质,我们在之前提到的sigmoid函数就是一个常用的激活函数。
之前的博客有具体讲到,请移步
权重
输入层各个结点的数据分别传输到隐含层第一层每一个结点时都要乘一个权重 w i w_i wi,传递到不同结点时权重也是不同的,所以准确的表达为,输入层的第 i i i个结点传输到隐层下一层的第 j j j个结点时的权重为 w i j w_ij wij,该第 j j j个结点的总输入为 ∑ i w i j x i \sum_i{w_{ij}x_i} ∑iwijxi.
偏置
神经元收到刺激时,通常会有一个阈值,只有当刺激超过阈值时,才会表现为兴奋状态,所以我们在此也会引入一个常数,加在 ∑ i w i j x i \sum_i{w_{ij}x_i} ∑iwijxi之后,即 ∑ i w i j x i + b j \sum_i{w_{ij}x_i}+b_j ∑iwijxi+bj, b j b_j bj称为第j个结点的偏置。
损失函数
损失函数是神经网络优化的目标函数,神经网络训练或者优化的过程就是最小化损失函数的过程。损失函数也有很多种,拿最普通的举例,若输出层第h个结点输出为 y ^ h \hat y_h y^h,实际值为 y h y_h yh,则损失函数为
L = ∑ i = 1 K ( y ^ h − y h ) 2 L=\sum_{i=1} ^{K}(\hat y_h-y_h)^2 L=i=1∑K(y^h−yh)2
神经网络原理
在介绍神经网络的工作原理时,我们选取最广泛使用的BP神经网络算法为例。
BP神经网络的全称为误差逆传播神经网络,其原理主要分为正向传播和反向传播两部分。
正向传播
正向传播是指的从样本信息中的 K K K个特征的数值 x i ( i = 1 , 2 , . . . , K ) x_i(i=1,2,...,K) xi(i=1,2,...,K)分别输入到输入层的K个单元中,从输入层进入网络后,在隐层的第一层H个单元中输出值 a i ( 2 ) a^{(2)}_{i} ai(2)分别为:
a i ( 2 ) = f ( w 1 i ( 1 ) x 1 + w 2 i ( 1 ) x 2 + . . . + w K i ( 1 ) x K + b i ( 1 ) ) a^{(2)}_{i}=f(w^{(1)}_{1i}x_1+w^{(1)}_{2i}x_2+...+w^{(1)}_{Ki}x_K+b_i^{(1)}) ai(2)=f(w1i(1)x1+w2i(1)x2+...+wKi(1)xK+bi(1))
将各输入值 x i x_i xi、输出值 a i ( 2 ) a^{(2)}_{i} ai(2)以及权重 w j i ( 1 ) w^{(1)}_{ji} wji(1)和偏置 b i b_i bi整合成矩阵,即
a ( 2 ) = f ( W ( 1 ) x + b ( 1 ) ) \mathrm{a}^{(2)}=f(W^{(1)} \mathrm{x}+\mathrm b^{(1)}) a(2)=f(W(1)x+b(1))
其中 i = 1 , 2 , . . . , H i=1,2,...,H i=1,2,...,H, f ( x ) f(x) f(x)为激活函数,上标 ( i ) ^{(i)} (i)表示为第 i i i 层.
由隐含层的第一层传递到下一层的L个单元时,输出值 a i ( 3 ) a^{(3)}_{i} ai(3)分别为:
a i ( 3 ) = f ( w 1 i ( 2 ) a 1 ( 2 ) + w 2 i ( 2 ) a 2 ( 2 ) + . . . + w H i ( 2 ) a H ( 2 ) + b i ( 2 ) ) a^{(3)}_{i}=f(w^{(2)}_{1i}a^{(2)}_1+w^{(2)}_{2i}a^{(2)}_2+...+w^{(2)}_{Hi}a^{(2)}_H+b_i^{(2)}) ai(3)=f(w1i(2)a1(2)+w2i(2)a2(2)+...+wHi(2)aH(2)+bi(2))
i = 1 , 2 , . . . , L i=1,2,...,L i=1,2,...,L
本层的矩阵表示为
a ( 3 ) = f ( W ( 2 ) x + b ( 2 ) ) \mathrm{a}^{(3)}=f(W^{(2)} \mathrm{x}+\mathrm b^{(2)}) a(3)=f(W(2)x+b(2))
如此类推,经过隐层间的逐层传递,传递到最后的输出层,输出层的M个单元中的输出整合在矩阵 Y ^ \mathrm {\hat Y} Y^中,为
Y ^ = a ( l + 1 ) = f ( W ( l ) x + b ( l ) ) \mathrm {\hat Y}=\mathrm{a}^{(l+1)}=f(W^{(l)} \mathrm{x}+\mathrm b^{(l)}) Y^=a(l+1)=f(W(l)x+b(l))
并可以根据实际值 Y Y Y得到损失函数
L = ( Y ^ − Y ) 2 L=(\mathrm {\hat Y}-Y)^2 L=(Y^−Y)2
以上的步骤就是由输入层一层一层向后传播,直至抵达最后的输出层,这些步骤就是正向传播。
负向传播
在得到损失函数后,不难看出,损失函数 L L L是各层的权重 W W W和偏置 b b b的函数.
根据梯度下降的原理,如有需要请移步,为使目标函数即损失函数最小化,应当沿着负梯度方向移动,所以我们可以对目标函数关于权重 W W W和偏置 b b b求出梯度,设置一个固定的学习率 η \eta η,得到第 l l l层更新后的权重和偏置为
W ( l ) ′ = W ( l ) − η ∂ L ( W , b ) ∂ W ( l ) \mathrm {W^{(l)}}'=\mathrm {W^{(l)}}-\eta \frac{\partial L(W,b)}{\partial W^{(l)}} W(l)′=W(l)−η∂W(l)∂L(W,b)
b ( l ) ′ = b ( l ) − η ∂ L ( W , b ) ∂ b ( l ) \mathrm {b^{(l)}}'=\mathrm {b^{(l)}}-\eta \frac{\partial L(W,b)}{\partial b^{(l)}} b(l)′=b(l)−η∂b(l)∂L(W,b)
依次向前类推,这一过程便是误差逆向传播。
值得注意的是,通常并不会在学习完每个样本后便进行误差逆向传播或者学习完数据集的全部样本,这样很容易浪费掉大量资源,而且效果不佳,所以通常是在学习完每个样本后计算出需要调整的幅度 − η ∂ L ( W , b ) ∂ b ( l ) -\eta \frac{\partial L(W,b)}{\partial b^{(l)}} −η∂b(l)∂L(W,b),在学习完固定数量的样本比如100个后,对需要调整的幅度进行求平均值,再对权重 W W W和偏置 b b b进行一次更新。
注:图片源自网络。