react - 你是如何理解单向数据流的?
1.你是如何理解单向数据流的?
组件的状态:状态可以理解为数据,与props类似,但是state是私有的,并且完全受控于当前组件,因此:组件状态指的就是一个组件自己维护的数据。数据驱动UI:意思很简单,就是:页面所展现的内容,完全是受状态控制的。这也就是mvvm的理念,UI的改变,全部交给框架本身来做,我们只需要管理好数据(状态)就好了。- 那么在 React 中,如何对状态进行管理呢?这就是本章节的重点,也是整个 React 学习的重点:
组件的状态管理。
- 什么是数据流?
数据流就是:数据在组件之间的传递。
- 单向数据流是什么意思?
单向数据流就是:数据在某个节点被改动后,只会影响一个方向上的其他节点。
- 为什么是自顶向下的?
就是说:数据只会影响到下一个层级的节点,不会影响上一个层级的节点。用下面的图来说就是:L2数据改变,只会影响到L3,不会影响到L1或者其他的节点。这就是自顶向下的单向数据流。那么我们在react框架中,就可以明确定义单向数据流:规范数据的流向,数据由外层组件向内层组件进行传递和更新。
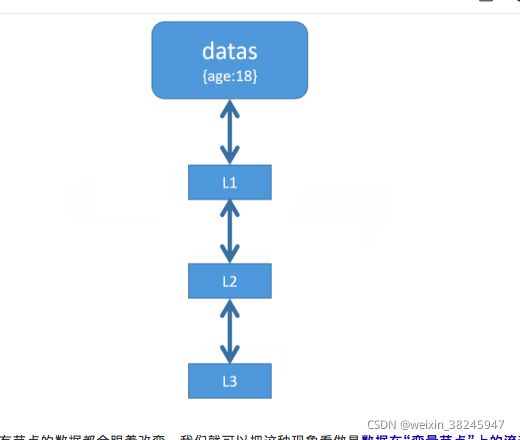
- 为什么是单向的?不能是双向的么?
因为:我们设想这样的情景:
父组件的数据通过props传递给子组件,而子组件更新了props,导致父组件和其他关联组件的数据更新,UI渲染也会随着数据而更新。毫无疑问,这是会导致严重的数据紊乱和不可控制的。
不能是双向的。
因此绝大多数框架在这方面做了处理。而 React 在这方面的处理,就是直接规定了 Props 为只读的,而不是可更改的。这也就是我们前面看到的数据更新不能直接通过 this.state 操作,想要更新,就需要通过 React 提供的专门的 this.setState() 方法来做。
单向数据流其实就是一种框架本身对数据流向的限制。
- 单向数据流有什么作用呢?
保证数据的可控性。
2.setState 是同步还是异步的呀?
- setState 本身的默认行为是什么?
其实也很简单,我们都知道,setState可以传递对象形式的状态,也可以传递函数形式的状态。而不论状态是对象形式还是函数形式,它都会先将所有状态保存起来,然后进行状态合并,所有状态合并完成后再进行一次性 DOM 更新。
- 如果状态是对象形式,后面的状态会直接覆盖前面的状态。类似于 Object.assign() 的合并操作。
对于对象状态这一点,我们看下代码:
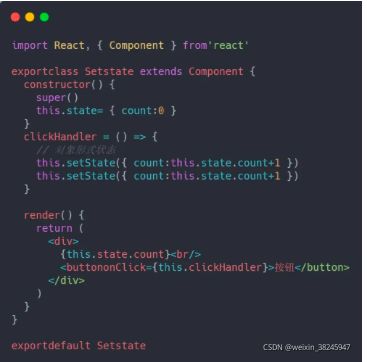
运行以上代码,Dom 中展示的结果为 1。很显然两次 setState 只有一次生效了。
真的吗?其实两次都有生效,只不过这两次 setState 在执行前,被合并成了一个。你不能说到底是那个生效,你可以说两个都没生效,因为最终执行的是被合并的那个代码。
- 如果状态是函数形式,那么依次调用函数进行状态累积,所有函数调用完成后, 得到最终状态,最终进行一次性 DOM 更新。
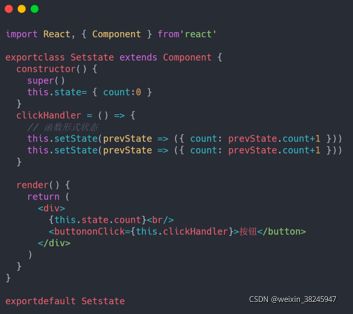
明显不一样的结果就能说明,两次都执行了,因为函数状态并不会合并,而是以此运行。
以上就是setState的默认行为。
- setState 同步 OR 异步
从 API 层面上说,它就是普通的调用执行的函数,自然是同步 API 。
因此,这里所说的同步和异步指的是 API 调用后更新 DOM 是同步还是异步的。
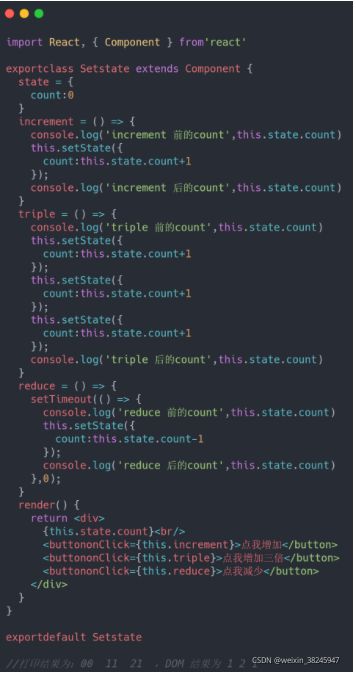
通过结果我们可以发现,非常奇怪的一个现象:
第一次事件执行显然为异步的,先打印了两个 0,Dom 随之改变为 1 ;
第二次同样是异步的,但是我们发现多次执行没效果 (异步?);
而第三次又是同步执行的了;
先说结论,首先,同步和异步主要取决于它被调用的环境。
- 如果 setState 在 React 能够控制的范围被调用,它就是异步的。
比如:合成事件处理函数, 生命周期函数, 此时会进行批量更新, 也就是将状态合并后再进行 DOM 更新。
- 如果 setState 在原生 JavaScript 控制的范围被调用,它就是同步的。
比如:原生事件处理函数中, 定时器回调函数中, Ajax 回调函数中, 此时 setState 被调用后会立即更新 DOM 。
为什么会这样呢?
其实,我们看到的所谓的 “异步”,是开启了 “批量更新” 模式的。
“批量更新” 模式:可以减少真实dom渲染的次数。所以只要是react能够控制的范围,出于性能因素考虑,一定是批量更新模式。批量更新会先合并状态,再一次性的做dom更新。
那么假设没有批量更新呢?
从生命周期的角度来看,每一次的setState都是一个完成的更新流程,这里面就包含了重新渲染(re-render)在内的很多操作。大体流程是这样的:
shouldComponentUpdate->componentWillUpdate->render->componentDidUpdate;
re-render 本身涉及到对dom的操作,它会带来较大的性能开销假如说:‘一次setState’就会触发一个完整的更新流程 这个结论成立,那么每一次setState的调用都会触发一次re-render,我们的视图没很可能没刷新几次就卡死了,渲染就会出现下面这样的流程:
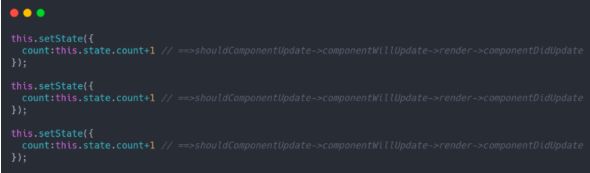
因此,setState 异步(或者说是批量更新)的一个重要动机就是避免频繁的 re-render。
在实际的 React 运行时中,setState 异步的实现方式有点类似于浏览器里的 Event-Loop:
每来一个setState,就把它塞进一个队列里。等时机成熟,再把队列里的 state 结果做合并,最后只针对最新的 state 值走一次更新流程。
这个过程,叫作“批量更新”,批量更新的过程正如下面代码中的箭头流程图所示:

只要我们的同步代码还在执行,“进队列” 这个动作就不会停止。因此就算我们在React 中写了一个 N 次的 setState 循环,也只是会增加 state 任务入队的次数,并不会带来频繁的 re-render。当 N 次调用结束后,仅仅是 state 的任务队列内容发生了变化, state 本身并不会立刻改变。
如果为非批量更新模式,调用多少次 setState 就会渲染多少次真实 DOM,性能较低。
但是我们在某些条件下需要对 JS 控制的区域实现批量更新 ( 异步更新 DOM ) ,那应该怎么做呢?强制批量更新:我们只需要将代码包裹在 unstable_batchedUpdates 方法的回调函数中就可以实现强制批量更新。
具体使用方式也很简单,从 react-dom 中引入进来,然后将代码放入调用函数中就可以了。

3.React 加入 Hooks 的意义是什么?
官方描述加入hooks的意义:https://react.docschina.org/docs/hooks-intro.html
- React 加入 Hooks 的意义是什么?或者说一下为什么 React 要加入Hooks 这一特性?
- 最后举例说一下 Hooks 的基本实现原理。
其实这样的问题并没有什么标准答案,但是我们可以换位思考,站在面试官的角度想一下“为什么会问这样的问题?”。无非就是想考察我们对 Hooks 最基本的使用情况以及对 Hooks 设计理念的个人思考。
文档中的 “动机” 就很好的解释了为什么 React 要加入 Hooks 特性,总结来说就是三个基本要素:
1.组件之间的逻辑状态难以复用。
2大型复杂的组件很难拆分。
3:Class 语法的使用不友好。
总的来说,实际上就是类组件在多年的应用实践中,发现了很多无法避免而又难以解决的问题。而相对类组件,函数组件又太过于简陋,比如:
类组件可以访问生命周期方法,函数组件不能;
类组件中可以定义并维护 state(状态),而函数组件不可以;
类组件中可以获取到实例化后的 this,并基于这个 this 做各种各样的事情,而函数组件不可以。
但是,函数式编程方式在 JS 中确实比 Class 的面向对象方式更加友好直观,那么只要能够将函数的组件能力补齐,也就解决了上面的问题。而如果直接修改函数组件的能力,势必会造成更大的成本,最好的方式就是开放对应接口进行调用,非侵入式引入组件能力,也就是我们现在看到的 Hooks 了。
明白了原因,面试中的问题也就迎刃而解了,基本思路就是先阐述在没有 Hooks 的时候,类组件有哪些问题,函数组件有哪些不足,而 Hooks 就是解决这些问题出现的。
5. Hooks 的设计理念是什么呢?
最重要的是,Hook 和现有代码可以同时工作,你可以渐进式地使用他们,而不用急着迁移到 Hook。尤其是对于现有的、复杂的 class 组件,我们建议避免任何“大规模重写”。在开始“用 Hook 的方式思考”之前,我们需要做一些思维上的转变。
6.React 为什么选择用jsx?
这里问 “为什么 React 选择使用 JSX ?”,其引申含义是 “为什么不用 A、B、C?”
举个例子,你二婶儿给你介绍了俩对象,一个温婉可爱小鸟依人,一个上得厅堂下得厨房,结果你依然选择单身不找对象。你二婶儿就问你为啥呀?你如果说单身有多好,你一定会被怼。怎么回答呢?温柔的太粘人,贤惠的长得丑,然后再说单身有多好。
套路就是,之所以选择 x,是因为 y 和 z 不好,然后接着说明 x 怎么怎么好。
但是,放到技术上,要答好这个问题“为什么 React 选择使用 JSX ?”,你需要先了解 React 可选的其他解决方案,然后才能知道有什么不好的地方。
其实相关方案有很多,最直观的就是模板。Vue 和 AngularJS 都选择使用模板方案,而 React 团队认为引入模板是一种不佳的实现。你觉得模板不好吗?我觉得还行啊,你觉得丑,我觉得美若天仙啊。这不仅仅是眼光不同,更多的是基于不同的角度来思考,再结合自身的特性做出的选择。
React 团队之所以认为模板不是最佳实现,原因在于,React 团队认为模板分离了技术栈,分散了组件内的关注点。其次,模板还会引入更多的概念,类似模板语法、模板指令等。
JSX 并不会引入太多新的概念,它仍然是 JavaScript,就连条件表达式和循环都仍然是 JavaScript 的方式,更具有可读性,更贴近 HTML。对于关注点分离这个问题,我们可以用两段代码来展示:

上面的两段代码分别使用了 React 及 Vue 的单文件组件来呈现。在 React 中,声明的 Users 类就是一个组件,全部的方法、数据及 UI 视图,可以以任意的方式呈现。而在 Vue 的组件中,很明确地要将 UI 部分写入 template 模板标签中(当然还可以在 component 方法中使用 template 字符串 ),功能及数据相关的要写入 script 标签中。而相对应的数据展示能力,则需要使用模板指令进行呈现,如:@click 指令绑定点击事件,v-for 循环遍历数据及样式结构;而在 JSX 中,全部都是 JavaScript 的,没什么规矩可言。
- 那么 JSX 到底是什么呢?
我们知道它不是字符串也不是 HTML,而是一个 JavaScript 的语法扩展,用于描述组件 UI。实际上,官方手册上早就说的很清楚了,JSX 仅仅只是React.createElement(component, props, ...children)函数的语法糖,最终会被编译为 React.createElement() 函数调用,并返回一个被称为 “React 元素” 的普通 JavaScript 对象。
我们用一段简单的代码展示一下,具体来看看:

上面的代码中,我们直接将 JSX 的内容打印到控制台,效果如下:
