元学习和持续学习中的Batch Normalization
元学习和持续学习中的Normalization
- TASKNORM: Rethinking Batch Normalization for Meta-Learning, ICML 2020
-
- 各种归一化方法的分析
- Task Normalization
- 实验结果
- CONTINUAL NORMALIZATION: RETHINKING BATCH NORMALIZATION FOR ONLINE CONTINUAL LEARNING, ICLR2022
-
- Batch Normalization在持续学习中的缺陷
- 适合持续学习的归一化层
- 实验结果
最近因为研究兴趣,对于元学习和持续学习中的Normalization问题做了一些调研,阅读了一些相关文章,再次做一个记录。
TASKNORM: Rethinking Batch Normalization for Meta-Learning, ICML 2020
本文敏锐地观察到了针对元学习Learning to Learn的双重结构下,传统的Batch Normalization理论并不成立,比如对于元学习经常应用的小样本学习任务来说,仅在每一个任务之内,所谓的独立同分布假设(IID)是满足的,因此所谓的均值和方差的归一化作用其实只限于每一个任务内部,所以有必要对于传统的归一化方法做一个重新的衡量,并设计出针对于元学习任务的有效的归一化方法,即标题中的Task Normalization。
各种归一化方法的分析
作者认为,对元学习来说,该方法应该满足以下几个特点:
- 提升训练速度和稳定性,并提升(至少不降低)结果。
- 对于不同的support set(本文称为context set)尺寸来说都能起作用。
- 是非直推的(non-transductive),也就是说,在元测试阶段(meta-testing)的query set(本文叫target set)的预测过程中归一化参数不再更新。这样可以适应不同的推理环境(模型在预测过程中保持稳定)。
基于这些标准,作者分析了不同的归一化方法,一些方法的简化图如下所示,主要反映的是 μ \mu μ和 δ 2 \delta^2 δ2(合称为moments)在不同阶段更新过程:

- Conventional Batch Normalization(CBN):按照传统的Batch Normalization的定义,在元学习中,训练集变成了元训练集,因此只元训练集中进行传统的BN,而在元测试过程中只使用元测试情况下计算出的running moments。
- Transductive Batch Normalization(TBN):这种方法和传统的Batch Normalization类似,但是其特点是在所有阶段(meta training和meta testing的support set和query set)都利用Batch信息进行归一化,这种做法最早来自于MAML并且对于模型性能影响巨大(相对于传统的BN),而且经常被视为BN,但对于学习系统来说,这种方式并不是一种公平的方法。
- Instance Normalization(IN) & Layer Normalization(LN):这两种方法因为都是基于每一个样本自己的统计数据,所以在任何情况下的表现都是一致的。但是对于提升训练效率和表现的帮助相对来说不够显著。
- Meta-Batch Normalization(MetaBN):这种方式是针对CBN和TBN的改进,它在meta training和meta testing阶段的support set都使用batch信息来进行学习并更新running moments,但是在二者的query set上都只使用记录的running moments,因此满足了non-transductive的条件,并且也提升了模型表现,但是其针对小batch size情况下(这在few shot learning下很常见)的能力有所不足,因此还有进一步提升的空间。
Task Normalization
作者提出的Task Normalization其实就是针对MetaBN的改良,根据support set的大小,动态调整BN和IN或LN的权重,其公式如下:
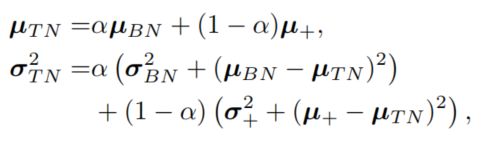
其中 μ + \mu_+ μ+和 δ + \delta_+ δ+来自于IN或LN,调节参数 α = S I G M O I D ( S C A L E ∣ D τ ∣ + O F F S E T ) \alpha=SIGMOID(SCALE|D^{\tau}|+OFFSET) α=SIGMOID(SCALE∣Dτ∣+OFFSET), S I G M O I D SIGMOID SIGMOID和 O F F S E T OFFSET OFFSET像其他参数一样通过学习得到。整个函数用于根据数据集大小调整使用的方式,对于大的support set则偏向BN,小的情况下偏向IN或LN,结合二者优势。注意该方法和Switch Normalization的不同,后者对不同归一化方法的结合是在结果上的,而Task Normalization是在均值和方差上的。
实验结果
作者做了很多实验,我只展示一个简单的:

在所有方法种直推式的方法取得了最好的结果,这也在意料之中,而在所有非直推方法中,Task-Norm取得了相对优秀的成绩,其中RN是Reptile方法使用的Normalization,可以看作是Task Norm的一个特例。另外这个结果也证实了IN,LN等方法由于没有考虑样本整体的信息而造成了效果下降。
对于直推式方法,作者还尝试了将所有样本一个个输入(stream列)或一整个类别一整个类别地输入(class列),这相当于削弱或抹去了直推式方法泄露测试数据整体分布的能力,因此其准确率出现了显著下降,反映了直推式方法的不足。
CONTINUAL NORMALIZATION: RETHINKING BATCH NORMALIZATION FOR ONLINE CONTINUAL LEARNING, ICLR2022
这也是一篇对于特殊场景下应用归一化方法的思考,文章标题全是大写看起来真是……。
Batch Normalization在持续学习中的缺陷
由于持续学习的研究主要针对于如何避免灾难性遗忘,而方法主要是使用replay、模块化、正则化等,基本上不涉及对于模型结构的重大调整,而且除了基于模块化的方法之外,很多方法直接采用了如ResNet之类的经典backbone进行实验,这些结构中使用到的归一化方法往往也就被自然而然地采用了,缺少对于其具体作用的思考,同时也对其局限性缺少了解。在本文中,作者认为,BN方法让过去的样本作用域当前样本的归一化以及不断更新BN的参数,从而促进了知识的迁移,然而BN作为为iid数据设计的归一化方法,其特性(更新的running mean和running var)也决定了它在non-iid的持续学习情景下必然更加偏向当前的任务,在验证中使用当前任务的moments(均值和方差文中统称为为moments)去归一化以往的任务,从而影响了以往任务的表现。作者将其称之为跨任务归一化效应(cross-task normalization effect)。
作者使用一个简单的例子展示了这个现象。下表中是在pMNIST数据集上顺序学习五个任务后的模型的结果,Single表示直接顺序进行训练,而ER代表带了一个Episode Memory的持续学习模型。BN代表了使用传统的Batch Normalization方法,而BN*则代表了使用整个数据集计算出全局的moments后固定使用该值进行Normalization的结果(在实际online学习中这是不可能做到的),可以看到BN*方法显著优于传统的BN(表格中的参数:ACC:学习完全部任务后在所有学过任务上的准确率(整体学习+抗遗忘能力);FM:学习完所有任务后,所有非最后学习任务相比于刚刚学习的时候下降的准确率;LA:学完每一个任务后在当前任务上的准确率(学习能力)。这种评估多个方面能力倒也比较全面,而且某个指标表现不好也有更多的余地哈哈),除此之外,对于右侧还列举了模型的两个BN层的moments相比于BN*中全局moments 的差值,可以看到其方差显著增大,而且越深的层影响越严重。

适合持续学习的归一化层
使用空间维度的归一化方法(如Instance Normalization,Layer Normalization等)可以很大程度上避免cross-task normalization的问题,因为他们对于每个样本的归一化只和样本自己有关。但是缺乏对于数据整体感知的归一化可能也会造成其相对BN的效果的降低,因此好的方法需要结合空间维和Batch维的信息,并在知识迁移和避免遗忘上做好平衡。为了实现这个目标,作者提出了Continual Normalization(CN)。
首先,作者提出了适合持续学习的归一化曾应该具有的性质:
- 促进任务内和任务间的知识共享从而提升模型(在所有任务上)的表现。
- 测试时的自适应能力:每一个数据点应该具有各自的归一化过程(不使用统一的moments)。同时每一个数据都应该对归一化曾整体的统计数据有贡献。
- 测试时不需要额外的辅助输入(记忆库(也就是Memory Free)或任务标识(也就是要Task Agnostic))。这是为了能够实现对于其它归一化层的平滑替代。
为了解决这些问题提出的持续归一化的公式很简单,如下所示:

GN代表Group Normalization,右下角的 1 , 0 _{1,0} 1,0代表该方法不经过仿射变换。也就是说GN不使用仿射变换而BN使用( γ \gamma γ和 β \beta β),作者说这是为了让 B N 1 , 0 BN_{1,0} BN1,0在空间和Batch维度上都实现正则化(当然我觉得其实用了也没有什么意义,因为BN计算的时候还是会把仿射变换重新归一化掉,最后只是做了一个缩放)。
实验结果
作者Split CIFAR和Split Tiny ImageNet上,用DER++持续学习算法(基于Episode Memory)和ResNet18 backbone,使用了不同的归一化方法,在Task-Incremental和Class-Incremental上进行了实验,部分结果如下(CN之后的G表示Group Normalization的组数):

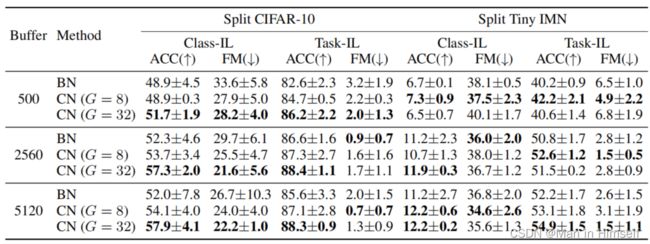
可以发现CN稳定超过BN(以及其它归一化方法),而在Split-CIFAR10的Class-Incremental的实验中BN表现不稳定(作者认为这是因为deviation很高,我没太看懂,不过数据自身的多样性的影响确实值得探讨),结果当然是好的,不过不知道如果不借助Episode Memory结果怎么样(补充:审稿人也是这么想的,在附录E.6的Table 10中作者对Single方法(直接顺序训练)也做了实验,仍然有提升)。
在openreview中作者回应了审稿人的要求增加了完全不使用归一化层的结果,可以发现学习效果降低(ACC和LA)但是遗忘也降低了(FM),这更加证实了作者认为BN在加速学习的同时,也让网络(对non-iid的数据)更加脆弱了。
我发现作者在实验中使用的Batch Size为10,会不会太小了一些?或者说,不同的Batch Size下的结果是否有必要研究?(不过作者在openreview中说这个方法主要是为了处理小batch size和不平衡数据等不理想或non-iid的情况,倒也可以理解,不过不同的momentum是否值得一试?)
此外作者还在不平衡的数据集(长尾分布)上做了比较(这对于BN来说比较难办)。作者使用PRS策略在COCOseq和NUS-WIDE上做了实验,对不同样本数的任务(minority:<200;moderate:200-900;majority:>900)做了区分,并对F1值做了样本平均(O-F1)和任务(类)平均(C-F1):
