【深度学习】预训练的卷积模型比Transformer更好?
引言
这篇文章就是当下很火的用预训练CNN刷爆Transformer的文章,LeCun对这篇文章做出了很有深意的评论:"Hmmm"。本文在预训练微调范式下对基于卷积的Seq2Seq模型进行了全面的实证评估。本文发现:
(1)预训练过程对卷积模型的帮助与对Transformer的帮助一样大;
(2)预训练的卷积模型在模型质量和训练速度方面在某些场景中是有竞争力的替代方案。
Pre-Trained Convolution Models
Lightweight Depthwise Convolution
1.Depthwise convolutions
假设输入一个tensor ,其维度为 ,depthwise卷积定义如下:
是可学习的矩阵, 是位置 和channel 的输出。最后整体的输出维度和输入维度是一样的都是 。
举例:一个大小为64×64像素、三通道彩色图片首先经过第一次卷积运算,depthwise卷积完全是在二维平面内进行,且Filter的数量与上一层的Depth相同。所以一个三通道的图像经过运算后生成了3个Feature map,如下图所示。
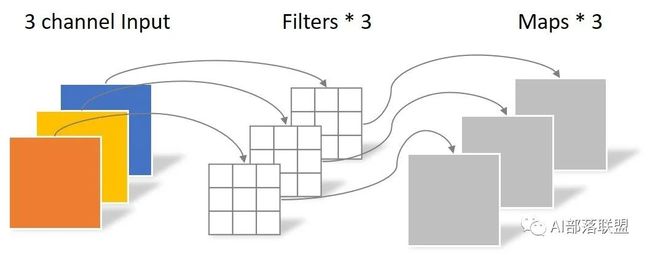
Depthwise Convolution完成后的Feature map数量与输入层的depth相同,但是这种运算对输入层的每个channel独立进行卷积运算后就结束了,没有有效的利用不同map在相同空间位置上的信息。
2. Lightweight Convolutions
Lightweight Convolutions在Depthwise Convolution的基础上使用了 , 是一个具有softmax归一化核以及共享输出通道和权重的深度可分离卷积:
其中 ,参数在每个 的输出通道中共享。当 的时候,相当于所有通道共享所有的参数。
3. Dynamic Convolutions
Dynamic Convolutions 是Lightweight Convolutions的一种变种,该方法关键的思想是学习特定位置的核来执行轻量级卷积:
其中 是一个线性变化,参数为 ,学习的是特定位置的kennel。
Span-based Seq2Seq pre-training
本文采用span-based的Seq2Seq预训练(Raffel等人,2019)。具体来说,给定一个输入序列,我们随机mask掉 个spans,并用特殊的[mask]标记替换。然后,预训练任务是生成被mask掉的token。例如:
Inputs: The happy cat sat [mask].
Outputs: on the mat.
Convolutional Seq2Seq Architecture 本文实现的Convolutional Seq2Seq模型与Transformer的区别在于将Transformer中的multi-headed self-attention替换为卷积blocks。对于Transformer中的query-key-value,本文使用门控线性单元代替。其中每个卷积block由以下部分组成:
其中 都是学习的参数。
作者实验了lightweight convolutions、dynamic convolutions以及dilated convolutions。和(Wu等人,2019年;Gehring等人,2017年)的实验相同,本文保持编码器-解码器的attention不变。并且遵循Transformer的主干模型,在该模型中,本文使用LayerNorm和残差连接形成每个子模块。因此,每个Conv block被写为:
就是上述的各个类型的卷积。 是一个两层带RELU的全连接。
Optimization
本文采用了token-wise的交叉熵loss:
第一个sum指的是将mask掉的 个span的loss求和, π 表示的是类别 在 时刻的预测值, 表示的是类别 在 时刻的ground truth。
Research Questions and Discussion
作者总结了几个希望本文能够解决的几个问题:
(1)pre-train给卷积模型带来的收益和Transformer相比怎样?卷机模型
(2)卷积模型如果通过预训练或者其他方式是否能够和Transformer模型对抗,什么情况下卷积模型表现好?
(3)使用预训练的卷积模型比预训练的Transformer有什么好 处(如果有的话)?卷积比基于自注意的Transformer更快吗?
(4)不使用预训练卷积效果不好,是否有无特定的故障模式、注意事项和原因分别是什么?
(5)某些卷积变体是否比其他变体更好?
Experiments and Analysis
数据集:
Toxicity Detection(二分类):CIVIL COMMENTS、WIKI TOXIC SUBTYPES 、
Sentiment Classification:IMDb、SST-2、Twitter Sentiment140
News Classification(四分类):AGNews
Question Classification(46类分类):TREC Semantic Parsing/Compositional
Generalization: COGS 生成给定英语句子的语义表示的任务。例如,A cat smiled → cat(x1) AND smile.agent(x2, x1).
Experimental Setup
Pre-training 数据:the Colossal Cleaned Com- monCrawl Corpus (C4)
span size: 3
optimizer: Adafactor optimizer
GPU: 16 TPU-v3 12小时
Results
可以看出,除了IMDb之外,其他的任务中,卷积模型的效果都是要优于Transformer的。
但是感觉也可以理解,因为除了替换self-attention之外,大致结构也都和Transformer是一致的,记得之前也有文章说过Transformer最有效的部分并不是self-attention?
此外作者还对比了二者的速度和操作数量变化:
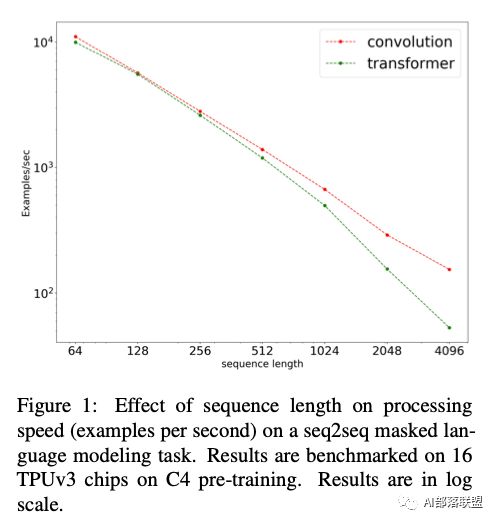

可以看出卷积不仅始终比Transformer更快(即使在较短的序列中)操作更少,而且比Transformer的规模更大。卷积处理文本的长度可以线性扩展,而Transformer不能扩展到更长的序列。
????
为啥没在GLUE上测试?
那如果把Transformer整体都替换为卷积是否还会有这样的效果呢?
而且作者说目前的模型还没办法处理cross-sentence的情况。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: