深度学习之后会是啥?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
![]()

大数据文摘出品
来源:datasciencecentral
编译:Min
我们被困住了,或者说至少我们已经停滞不前了。有谁还记得上一次一年没有在算法、芯片或数据处理方面取得重大显著进展是什么时候?几周前去参加Strata San Jose会议,却没有看到任何吸引眼球的新进展,这太不寻常了。
正如我之前所报告的那样,似乎我们已经进入了成熟期,现在我们的主要工作目标是确保我们所有强大的新技术能够很好地结合在一起(融合平台),或者从那些大规模的VC投资中赚取相同的钱。

我不是唯一一个注意到这些的人。几位与会者和参展商都和我说了非常类似的话。而就在前几天,我收到了一个由知名研究人员组成的团队的说明,他们一直在评估不同高级分析平台的相对优点,并得出结论:没有任何值得报告的差异。
我们为什么和在哪里陷入困境?
我们现在所处的位置其实并不差。我们过去两三年的进步都是在深度学习和强化学习领域。深度学习在处理语音、文本、图像和视频方面给我们带来了了不起的能力。再加上强化学习,我们在游戏、自主车辆、机器人等方面都有了很大的进步。
我们正处于商业爆炸的最早阶段,基于诸如通过聊天机器人与客户互动来节省大量资金、个人助理和Alexa等新的个人便利应用、个人汽车中的二级自动化,比如自适应巡航控制、事故避免制动和车道维护。
Tensorflow、Keras和其他深度学习平台比以往任何时候都更容易获得,而且由于GPU的存在,比以往任何时候都更高效。
但是,已知的缺陷清单根本没有解决:
需要太多标签化的训练数据。
模型的训练时间太长或者需要太多昂贵的资源,而且还可能根本无法训练。
超参数,尤其是围绕节点和层的超参数,仍然是神秘的。自动化甚至是公认的经验法则仍然遥不可及。
迁移学习,意味着只能从复杂到简单,而不是从一个逻辑系统到另一个逻辑系统。
我相信我们可以列一个更长的清单。正是在解决这些主要的缺点方面,我们已经陷入了困境。
是什么阻止了我们
在深度神经网络中,目前的传统观点是,只要我们不断地推动,不断地投资,那么这些不足就会被克服。例如,从80年代到00年代,我们知道如何让深度神经网络工作,只是我们没有硬件。一旦赶上了,那么深度神经网络结合新的开源精神,就会打开这个新的领域。
所有类型的研究都有自己的动力。特别是一旦你在一个特定的方向上投入了大量的时间和金钱,你就会一直朝着这个方向前进。如果你已经投入了多年的时间来发展这些技能的专业知识,你就不会倾向于跳槽。
改变方向,即使你不完全确定应该是什么方向。

有时候我们需要改变方向,即使我们不知道这个新方向到底是什么。最近,领先的加拿大和美国AI研究人员做到了这一点。他们认为他们被误导了,需要从本质上重新开始。
这一见解在去年秋天被Geoffrey Hinton口头表达出来,他在80年代末启动神经网络主旨研究的过程中功不可没。Hinton现在是多伦多大学的名誉教授,也是谷歌的研究员,他说他现在 "深深地怀疑 "反向传播,这是DNN的核心方法。观察到人脑并不需要所有这些标签数据来得出结论,Hinton说 "我的观点是把这些数据全部扔掉,然后重新开始"。
因此,考虑到这一点,这里是一个简短的调查,这些新方向介于确定可以实现和几乎不可能实现之间,但不是我们所知道的深度神经网的增量改进。
这些描述有意简短,无疑会引导你进一步阅读以充分理解它们。
看起来像DNN却不是的东西
有一条研究路线与Hinton的反向传播密切相关,即认为节点和层的基本结构是有用的,但连接和计算方法需要大幅修改。

我们从Hinton自己目前新的研究方向——CapsNet开始说起是很合适的。这与卷积神经网络的图像分类有关,问题简单来说,就是卷积神经网络对物体的姿势不敏感。也就是说,如果要识别同一个物体,在位置、大小、方向、变形、速度、反射率、色调、纹理等方面存在差异,那么必须针对这些情况分别添加训练数据。
在卷积神经网络中,通过大量增加训练数据和(或)增加最大池化层来处理这个问题,这些层可以泛化,但只是损失实际信息。
下面的描述是众多优秀的CapsNets技术描述之一,该描述来自Hackernoon。
Capsule是一组嵌套的神经层。在普通的神经网络中,你会不断地添加更多的层。在CapsNet中,你会在一个单层内增加更多的层。或者换句话说,把一个神经层嵌套在另一个神经层里面。capsule里面的神经元的状态就能捕捉到图像里面一个实体的上述属性。一个胶囊输出一个向量来代表实体的存在。向量的方向代表实体的属性。该向量被发送到神经网络中所有可能的父代。预测向量是基于自身权重和权重矩阵相乘计算的。哪个父代的标量预测向量乘积最大,哪个父代就会增加胶囊的结合度。其余的父代则降低其结合度。这种通过协议的路由方式优于目前的max-pooling等机制。
CapsNet极大地减少了所需的训练集,并在早期测试中显示出卓越的图像分类性能。
多粒度级联森林
2月份,我们介绍了南京大学新型软件技术国家重点实验室的周志华和冯霁的研究,展示了他们称之为多粒度级联森林的技术。他们的研究论文显示,多粒度级联森林在文本和图像分类上都经常击败卷积神经网络和循环神经网络。效益相当显著。
只需要训练数据的一小部分。
在您的桌面CPU设备上运行,无需GPU。
训练速度一样快,在许多情况下甚至更快,适合分布式处理。
超参数少得多,在默认设置下表现良好。
依靠容易理解的随机森林,而不是完全不透明的深度神经网。
简而言之,gcForest(多粒度级联森林)是一种决策树集合方法,其中保留了深网的级联结构,但不透明的边缘和节点神经元被随机森林组与完全随机的树林配对取代。在我们的原文中阅读更多关于gcForest的内容。
Pyro and Edward
Pyro和Edward是两种新的编程语言,它们融合了深度学习框架和概率编程。Pyro是Uber和Google的作品,而Edward则来自哥伦比亚大学,由DARPA提供资金。其结果是一个框架,允许深度学习系统衡量他们对预测或决策的信心。
在经典的预测分析中,我们可能会通过使用对数损失作为健身函数来处理这个问题,惩罚有信心但错误的预测(假阳性)。到目前为止,还没有用于深度学习的必然结果。
例如,这有望使用的地方是在自动驾驶汽车或飞机中,允许控制在做出关键或致命的灾难性决定之前有一些信心或怀疑感。这当然是你希望你的自主Uber在你上车之前就知道的事情。
Pyro和Edward都处于开发的早期阶段。
不像深网的方法
我经常会遇到一些小公司,他们的平台核心是非常不寻常的算法。在我追问的大多数案例中,他们都不愿意提供足够的细节,甚至让我为你描述里面的情况。这种保密并不能使他们的效用失效,但是在他们提供一些基准和一些细节之前,我无法真正告诉你里面发生了什么。当他们最终揭开面纱的时候,就把这些当作我们未来的工作台吧。
目前,我所调查的最先进的非DNN算法和平台是这样的。
层次时间记忆(HTM)
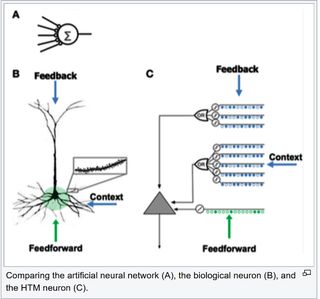
层次时间记忆(HTM)使用稀疏分布式表示法(SDR)对大脑中的神经元进行建模,并进行计算,在标量预测(商品、能源或股票价格等未来值)和异常检测方面优于CNN和RNN。
这是Palm Pilot名宿Jeff Hawkins在其公司Numenta的奉献作品。霍金斯在对大脑功能进行基础研究的基础上,追求的是一种强大的人工智能模型,而不是像DNN那样用层和节点来结构。
HTM的特点是,它发现模式的速度非常快,只需1,000次观测。这与训练CNN或RNN所需的几十万或几百万次的观测相比,简直是天壤之别。
此外,模式识别是无监督的,并且可以根据输入的变化来识别和概括模式的变化。这使得系统不仅训练速度非常快,而且具有自学习、自适应性,不会被数据变化或噪声所迷惑。
一些值得注意的渐进式改进
我们开始关注真正的游戏改变者,但至少有两个渐进式改进的例子值得一提。这些显然仍然是经典的CNN和RNNs,具有反向支撑的元素,但它们工作得更好。
使用Google Cloud AutoML进行网络修剪
谷歌和Nvidia的研究人员使用了一种名为网络修剪的过程,通过去除对输出没有直接贡献的神经元,让神经网络变得更小,运行效率更高。这一进步最近被推出,作为谷歌新的AutoML平台性能的重大改进。
Transformer
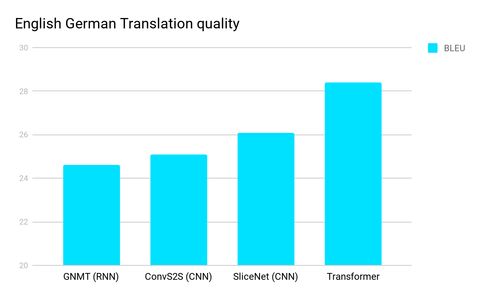
Transformer是一种新颖的方法,最初在语言处理中很有用,比如语言到语言的翻译,这一直是CNNs、RNNs和LSTMs的领域。去年夏末由谷歌大脑和多伦多大学的研究人员发布,它在各种测试中都表现出了显著的准确性改进,包括这个英语/德语翻译测试。
RNNs的顺序性使其更难充分利用现代快速计算设备(如GPU),因为GPU擅长的是并行而非顺序处理。CNN比RNN的顺序性要差得多,但在CNN架构中,随着距离的增加,将输入的远端部分的信息组合起来所需的步骤数仍然会增加。
准确率的突破来自于 "自注意功能 "的开发,它将步骤大幅减少到一个小的、恒定的步骤数。在每一个步骤中,它都应用了一种自我关注机制,直接对一句话中所有词之间的关系进行建模,而不管它们各自的位置如何。
就像VC说的那样,也许是时候该换换口味了。
相关报道:
https://www.datasciencecentral.com/profiles/blogs/what-comes-after-deep-learning
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

