pytorch深度学习入门笔记
Pytorch 深度学习入门笔记
作者:梅如你
学习来源:
公众号: 阿力阿哩哩、土堆碎念
B站视频:https://www.bilibili.com/video/BV1hE411t7RN?
中国大学MOOC:https://www.icourse163.org/course/FUDAN-1205806833?
文章目录
-
- Pytorch 深度学习入门笔记
-
- 一、导论
-
- 1.1人工智能与深度学习
- 1.2 深度学习算法流程
- 1.3 服务器租用
- 二、准备工作
-
- 2.1torch库
- 2.2安装cuda
- 2.3梯度下降
- 2.4手写数字识别
- 三、pytorch学习
-
- 3.1pytorch中的数据类型
- 3.2加载数据
- 3.3 tensorboard
- 3.4 transform
- 3.5 torchvision中数据集的使用
- 3.6 Dataloader的使用
- 3.7 神经网络基本骨架 nn.module的使用
-
- 神经网络-卷积层
- 神经网络-最大池化层
- 神经网络-非线性激活
- 神经网络-线性层
- 神经网络-序列squetial
- 模型的代码实现
- 3.8 损失函数
- 3.9优化器
- 四、模型使用
- 4.1 现有模型的修改
-
- 4.2 模型的保存与加载
- 4.3 完整的模型训练套路
- 4.4 利用GPU进行训练
- 4.5 模型验证(测试)套路
- 五、其他
一、导论
导论
1.1人工智能与深度学习
人工智能顾名思义就是人工赋予机器智能,但与人工智能先驱们所设想的赋予机器独立思考能力的“强人工智能”所不一样,目前我们所说的人工智能都是“弱人工智能”。它能跟人一样实现一些既定的任务,例如人脸识别、垃圾邮件分类等,有时甚至可以超越人类。
深度学习则是人们通过仿生学创造性提出的一种人工神经网络技术。人们通过训练这些神经网络,使其出色地完成了很多机器学习任务。因此,深度学习是人工智能历史上一个重大突破,它拓展了人工智能的领域范围和促进了人工智能的发展。
深度学习是基于大规模数据的学习算法
人工智能包裹着机器学习,机器学习包裹着深度学习。简单来讲,人工智能是一个概念,机器学习是实现人工智能的一种方法,而深度学习是实现机器学习的一种技术。
1.2 深度学习算法流程
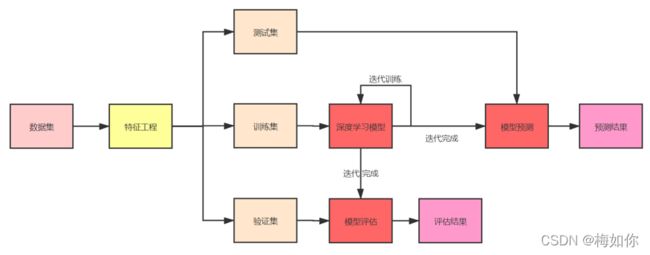
训练集用以训练深度学习模型;验证集用以评估模型结果,进而辅助模型调参;测试集用以模型的预测。
一般而言,训练集、验证集与测试集的比例为7:2:1。
特征工程
“数据和特征决定了机器学习的上限,而模型与算法则是逼近这个上限而已。”
一般将数据处理成算法能够理解的格式即可,后期对神经网络的训练,就是提取和归纳特征的过程。特征工程能够自动化
模型评估
深度学习模型执行的任务可以归为两类:分类任务和回归(预测)任务。为此我们也有不同的指标去评估模型。
-
分类任务评估指标
1)准确率(accuracy)
分类正确的样本数占总样本数的百分比

2)精确率(precision)和召回率(recall rate)
精确率(预测为正的样本中实际为正的有多少)衡量的是检索系统推送出来的真实正确结果(TP)与系统推送出来的 所有正确结果(TP+FP)的占比。
召回率(实际为正的样本中有多少预测为正了)衡量的是系统推送出来的真实正确结果(TP)与整个系统的实际正 确结果(TP+FN)的占比。
-
F1Score和ROC曲线
(1)F1Score是精确率和召回率的调和平均值:

(2)ROC曲线(Receiver Operating Characteristic):一开始用于心理学、医学检测应用,此后被引入机器学习领域,用以评估模型泛化性能好坏。ROC曲线的线下面积(AUC)越大,也意味着该模型的泛化性能越好。
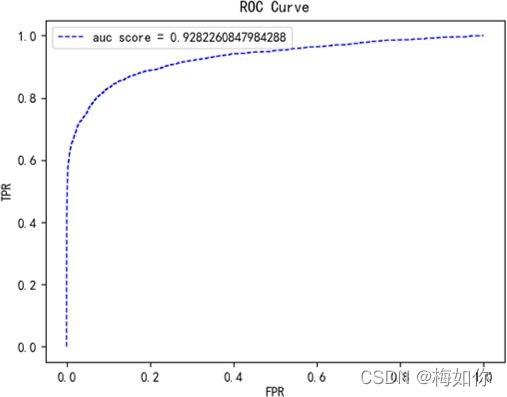
为了能更好地衡量我们模型的有效性,我们应该选择ROC曲线和F1Score作为评估指标。因为它们能够无视样本不均衡的情况,并根据预测结果给出最合理的评估。
1.3 服务器租用
云服务器(Elastic Compute Service, 简称ECS),是一种简单高效,处理能力可以弹性伸缩的计算服务。ECS的相关术语说明如下:
实例(Instance):是一个虚拟的计算环境,由CPU、内存、系统盘和运行的操作系统组成;ECS实例作为云服务器最为核心的概念,其他资源,比如磁盘、IP、镜像、快照等,只有与ECS结合后才具有使用意义。
地域(Region):指ECS实例所在的物理位置。地域内的ECS实例内网是互通的,不同的地域之间ECS实例内网不互通。
可用区(Zone):指在同一地域内,电力和网络互相独立的物理区域。
磁盘(Disk):是为ECS实例提供数据块级别的数据存储。可以分为4类: 普通云盘、SSD云盘、高效云盘和本地SSD磁盘
快照(Snapshot):是某一个时间点上某个磁盘的数据拷贝。
镜像(Image):是ECS实例运行环境的模板,一般包括操作系统和预装的软件。
安全组(Security Group):是一种虚拟防火墙,具备状态检测包过滤功能。每个实例至少属于一个安全组。同一个安全组内的实例之间网络互通,不同安全组的实例之间默认内网不通,但是可以授权两个安全组之间互访。
二、准备工作
2.1torch库
聚焦于大规模的机器学习应用,尤其是图像或者视频应用等领域。它的目标在保证使用的方式非常简单的基础上最大化地保证算法的灵活性和速度,可以使用并行的方式对CPU和GPU进行更有效的操作。
主要特性:
- 强大的N维数组操作的支持
- 提供很多对于索引/切片等的常用操作
- 常见线性代数计算的支持
- 神经网络和基于能量的模型
- 支持GPU计算
- 可嵌入,可移植到iOS或者Android
PyTorch在torch上开发的,因为相比于goole开发的tensenflow2,更简单,且是动态的,比较方便
优势:
-
GPU加速
-
自动求导
y = a 2 ∗ x + b ∗ x + c y=a^2*x+b*x+c y=a2∗x+b∗x+c
autograd.grad(y,[a,b,c])
-
常用网络层
2.2安装cuda
进入官网,下载cuda,选择local版本,下载后配置环境变量是在一个bin目录
然后在cmd中检测是否安装好了,观察一下有nvcc这个程序
输入nvcc -V
2.3梯度下降
梯度是深度学习的核心算法,一般设置学习率为0.01,让斜率慢慢降到0,逼近最小值
最常见的是Adam和sgd求解器
现实生活中往往有噪声,在原来的
y = w ∗ x + b + 误 差 噪 声 y=w*x+b+误差噪声 y=w∗x+b+误差噪声
l o s s = ∑ i = 1 n ( w x + b − y ) 2 loss=\sum_{i=1}^{n}{(wx+b-y)^2} loss=∑i=1n(wx+b−y)2损失函数:(实际值-理论值)的平方
#计算loss值
def compute_error_for_line_given_points(b,w,points):
totalError = 0
for i in range(0,len(points)):
x = points[i,0]
y = points[i,1]
totalError +=(y-(w*x+b))**2 #总的损失
return totalError/float(len(points))
#计算梯度
def step_gradient(b_current,w_current,points,learningRate):
b_gradient = 0
w_gradient = 0
N = float(len(points))
for i in range(0,len(points)):
x = points[i,0]
y = points[i,1]
b_gradient += -(2/N)*(y-((w_current*x)+b_current))
w_gradient += -(2/N)*x*(y-((w_current*x)+b_current))
new_b = b_current - (learningRate*b_gradient)
new_w = w_current - (learningRate*w_gradient)
#迭代返回最佳b和m
def gradient_descent_runner(points,starting_b,starting_m,learning_rate,num_iterations):
b = starting_b
m = staring_m
for i in range(num_iterations):
b,m = step_gradien(b,m,np.array(points),learning_rate)
return[b,m]
2.4手写数字识别
0-9,10种数字,有很多人书写的,mnist,每张大小是28*28
utils.py放置一些工具包
import torch
from matplotlib import pyplot as plt
#绘制下降图像
def plot_curve(data):
fig = plt.figure()
plt.plot(range(len(data)), data, color='blue')
plt.legend(['value'], loc='upper right')
plt.xlabel('step')
plt.ylabel('value')
plt.show()
def plot_image(img, label, name):
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(img[i][0]*0.3081+0.1307, cmap='gray', interpolation='none')
plt.title("{}: {}".format(name, label[i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
#完成编码
def one_hot(label, depth=10):
out = torch.zeros(label.size(0), depth)
idx = torch.LongTensor(label).view(-1, 1)
out.scatter_(dim=1, index=idx, value=1)
return out
训练过程
import torch
from torch import nn #引入与神经网络相关的
from torch.nn import functional as F #引入常见的函数用F代替
from torch import optim #导入优化工具包
import torchvision #做视觉需要这个工具包
from matplotlib import pyplot as plt
from utils import plot_image, plot_curve, one_hot
batch_size = 512 #gpu性能非常强大,一次可以处理多张图片,并行处理
# step1. load dataset
#训练集和测试集
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)#shuffle=True随机的打散
#ToTensor():torch中的数据载体
#torchvision.transforms.Normalize()正则化过程,使它数据均匀的分布在0附近
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=False)
x, y = next(iter(train_loader))
#list、tuple等都是可迭代对象,我们可以通过iter()函数获取这些可迭代对象的迭代器。然后,我们可以对获取到的迭代器不断使⽤next()函数来获取下⼀条数据。
print(x.shape, y.shape, x.min(), x.max())
#torch.Size([512, 1, 28, 28]) torch.Size([512]) tensor(-0.4242) tensor(2.8215)
#512张图片,1个通道,28*28大小
plot_image(x, y, 'image sample')
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# xw+b 创建3层次
self.fc1 = nn.Linear(28*28, 256)#,x的维度是28*28,线性层次,256是随机决定的,从一个大维度到小维度降低的过程
self.fc2 = nn.Linear(256, 64)#输入256是第一层的输出
self.fc3 = nn.Linear(64, 10)#10是10分类,不是经验决定的
#计算过程
def forward(self, x):
# x: [b, 1, 28, 28]一共有b张图片
# h1 = relu(xw1+b1)
x = F.relu(self.fc1(x))
# h2 = relu(h1w2+b2)
x = F.relu(self.fc2(x))
# h3 = h2w3+b3
x = self.fc3(x)#最后一层不加激活函数
return x #返回输出,完成网络的创建过程
net = Net()#创建网络对象
#net.parameters()返回 [w1, b1, w2, b2, w3, b3],知道我们要优化的权重就是这些
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) #梯度下降更新
#网络的训练
train_loss = []
for epoch in range(3):
for batch_idx, (x, y) in enumerate(train_loader):
# x: [b, 1, 28, 28], y: [512]
# [b, 1, 28, 28] => [b, 784]
x = x.view(x.size(0), 28*28)#打平,拉长
# => [b, 10]
out = net(x)
# [b, 10]
y_onehot = one_hot(y) #one_hot()是一个工具函数,将y转化为[b, 10],希望out能接近y_onehot
# loss = mse(out, y_onehot)
loss = F.mse_loss(out, y_onehot)
optimizer.zero_grad()#清0梯度
loss.backward()#梯度计算过程
# w' = w - lr*grad
optimizer.step()
train_loss.append(loss.item())
if batch_idx % 10==0:
print(epoch, batch_idx, loss.item())
plot_curve(train_loss)#绘制一个梯度下降曲线
# we get optimal [w1, b1, w2, b2, w3, b3]
#做准确度的测试
total_correct = 0
#从测试数据来
for x,y in test_loader:
x = x.view(x.size(0), 28*28)
out = net(x)#得到网络的输出, # out: [b, 10] => pred: [b]
pred = out.argmax(dim=1) #返回这个值中最大的那个值的索引,这是预测值
correct = pred.eq(y).sum().float().item()
total_correct += correct #总的正确的数量
total_num = len(test_loader.dataset) #总的数量
acc = total_correct / total_num
print('test acc:', acc)
x, y = next(iter(test_loader))
out = net(x.view(x.size(0), 28*28))
pred = out.argmax(dim=1)
plot_image(x, pred, 'test')
三、pytorch学习
深度学习的GPU加速库
两个自学函数:
dir():打开,看见:能让我们知道工具箱以及工具箱中的分隔区有什么东西
help():说明书,能让我们知道每个工具是如何使用的,工具的使用方法
3.1pytorch中的数据类型
Int —>IntTensor of size()
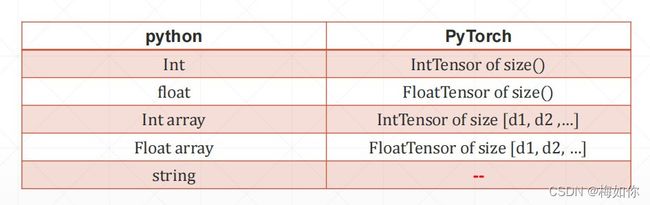
而python中String类型,pychar没有,采用One-hot表示
[0,1,0,0,…]代表第2种类别
数据类型,部署在cpu和gpu上

怎么判断tensor类型
a = torch.randn(2,3)#这是用随机正态分布初始化2行3列的tensor
a.type()
输出:'torch.FloatTensor'
type(a)
输出:torch.Tensor
isinstance(a,torch.FloatTensor)#做参数的合法化检验,如果是的话就返回True
输出:True
同一个tensor部署在CPU和GPU上类型是不一样的
isinstance(data,torch.cuda.DoubleTenser)
out:False
data=data.cuda() #返回一个gpu上的引用
isinstance(data,torch.cuda.DoubleTenser)
out:True
0维(单纯的一个数字)的表示:这种表示类型loss损失值
torch.tensor(1.)#使用这个方法直接把标量带进去,
out:tensor(1.)
torch.tensor(1.3)
out:tensor(1.300)
#1.3是0维,但[1.3]是1维,长度为1的Tensor
#怎么检验dim为0,可以用.shape
a = torch.tensor(2.2)
a.shape
out:torch.Size([])#空的list的size的对象
len(a.shape)
out:0 #告诉你这是一个9维的标量
a.size() #代表a都具体的形状
out:torch.Size([])
1维:通常用作偏置值(bias),还有线性input,把它打平[28*28]–>[784]
torch.tensor([1.1])
out:tensor([1.1000])
#Tensor是接受数据的维度,tensor是接受现有的数据
torch.FloatTensor(2) #给定一个向量的长度,它就会随机初始化
out:tensor([3.2239e-25,4.5915e-41])
#还可以从np引入
data = np.ones(2)
data
out:array([1.,1.])
2维:表示多张图片,[4,784]表示第4张照片,784是具体内容
a = torch.randn(2,3)#生成2行3列,值随机初始化
a.shape
out:torch.Size([2,3])
a.size(0)
out:2
#表示多张图片
[4,784]表示第4张照片,784是具体内容
3维:适合文字处理
a = torch.rand(1,2,3)
a
out:tensor([[[0.0764,0.2590,0.981116],
[0.6798,0.1568,0.7919]]])
a.shape
torch.Size([1,2,3])#三个维度
a[0]#取第一个元素的0个维度,就是2维
out:tensor([[0.0764,0.2590,0.981116],
[0.6798,0.1568,0.7919]])
list(a.shape)
[1,2,3]
4维:适合表示图片这种类型,特别适合卷积神经网络
a = torch.rand(2,3,28,28)
#28*28是长和宽,1是灰度图片,通道是1,3是彩色,2是两张图片
a
out:
tensor([[[[省略。。]]]])
索引与切片
a = torch.rand(4,3,28,28)
a[0].shape
out:torch.Size([3,28,28])
a[0,0].shape
torch.Size([28,28])
a[0,0,2,4]
out:tensor(0.8082)
3.2加载数据
获取图片名称列表
from PIL import Image
img_path = 'D:\\深度学习cnn\\PycharmProjects\\ant and bee\\dataset\\train\\ants\\0013035.jpg'
img = Image.open(img_path)
img.size
Out[8]: (768, 512)
img.show()
dir_path = "dataset/train/ants"
import os
img_path_list = os.listdir(dir_path)
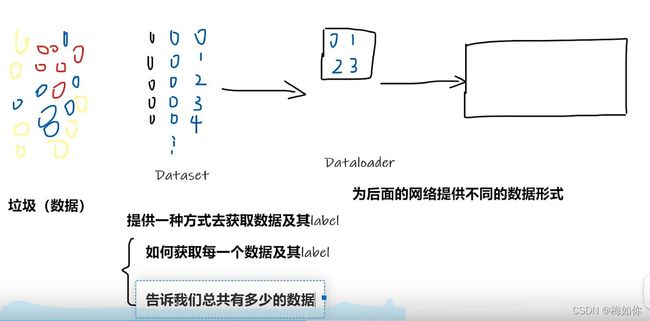
from torch.utils.data import Dataset
#常用的工具区中关于数据部分
import os#python中一个关于系统的库
from PIL import Image
class MyData(Dataset):#继承这个Dataset类
def __init__(self,root_dir,label_dir):
#初始化类,提供全局变量什么的
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
#通过索引获取所有图片地址列表
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir = 'dataset/train'
ants_label_dir = 'ants_image'
bees_label_dir = 'bees_image'
img_path = os.listdir(os.path.join(root_dir,ants_label_dir))
label = ants_label_dir.split('-')[0]
out_dir = 'ants_label'
for i in img_path:
file_name = i.split('.jpg')[0]
with open(os.path.join(root_dir,out_dir,"{}.txt".format(file_name)),'w') as f:
f.write(label)
3.3 tensorboard
tensorboard的使用
探索这个模型不同阶段到底是怎么输出的很有用
.按住ctrl键,变成蓝色,点击可以看到具体函数内容,用法
安装tensorboard
pip install tensorboard
from torch.utils.tensorboard import SummaryWriter
#对这个类创建一个实例,它对应的数据文件存储在logs文件夹下
writer = SummaryWriter("logs")
# writer.add_image()
# y=x
for i in range(100):
writer.add_scalar("y=x",i,i)
writer.close()
运行代码就生成了这个文件夹
命令行中
tensorboard --logdir=logs
# logdir=事件文件所在文件夹名
指定一下端口,防止和别人冲突
tensorboard --logdir=logs --port=6007
#然后点击出现的地址,就会在游览器中显示图像
#利用tensorboard打开图片
image_path = "dataset/train/ants_image/6240338_93729615ec.jpg"
image_PIL = Image.open(image_path)
#按住ctrl,点击add_image
可以看到img_tensor类型需要是下面框住道德3种类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-izt68iXd-1650352032618)(add_imge.png)]
打开后就会是这样的
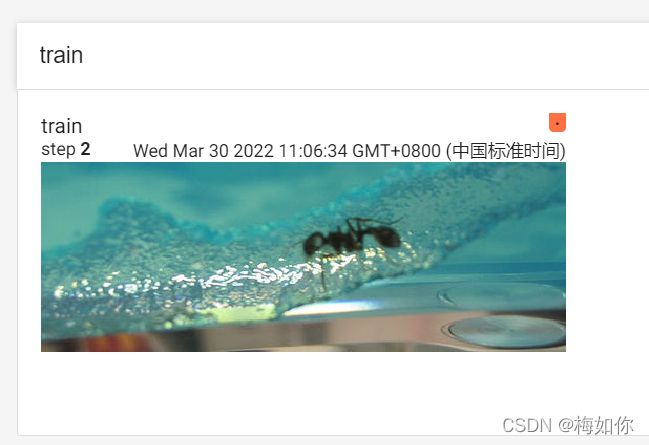
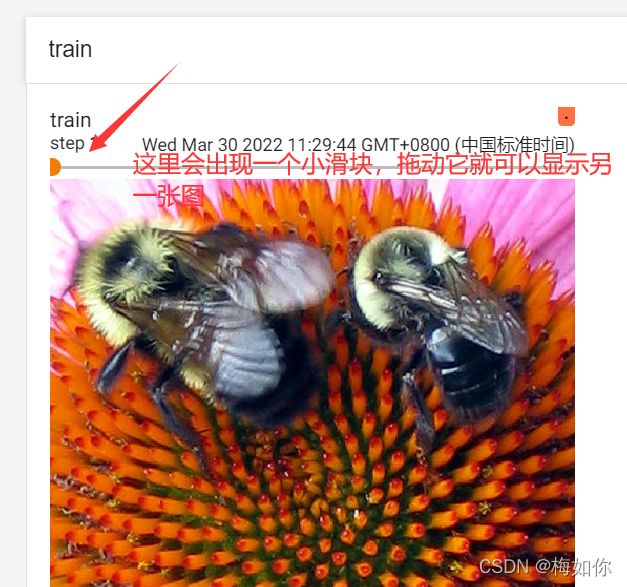
如果想让它显示两张
writer.add_image("train", img_arry, 1, dataformats='HWC')
#就把这里的step=1改为2,再把上面的image_path改成其他的图片路径,然后运行刷新游览器就可以看到两张
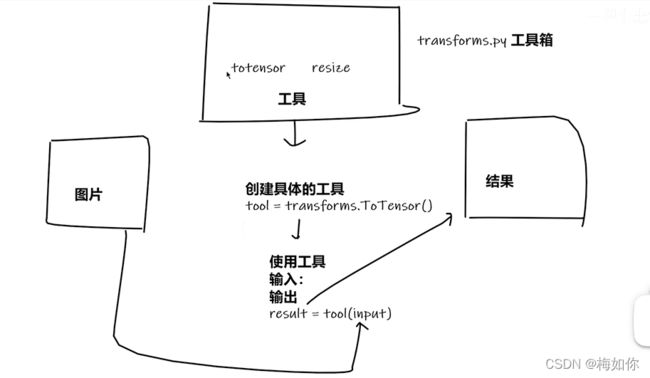
3.4 transform
transform的结构和用法
transform就是一个工具箱,处理图片的,将图片转化成什么格式
1、transforms该如何使用(python)
2、为什么我们需要使用Tensor数据类型
img_path = "dataset/train/ants_image/00130.jpg"
img = Image.open(img_path)
tensor_trans = transform.Totensor()
tensor_img = tensor_trans(img)
#Image是python内置的一个打开图片的函数,这就将一个PIL Image转换为Tensor类型
tensor数据类型可以理解为包装了卷积神经神经网络的理论基础参数
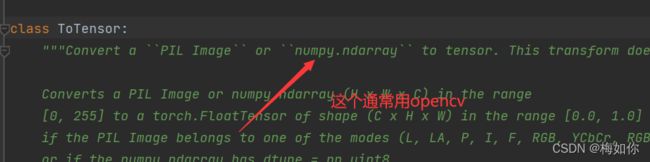
import cv2
cv_img = cv2.imread(img_path)
#cv2就是opencv,调用imread可以得到numpy.ndarray类型
一个小技巧
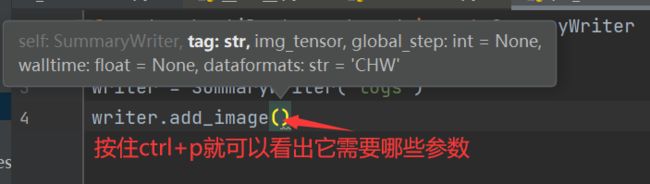
或者直接按住ctrl点击,看他需要什么类型
常见transforms

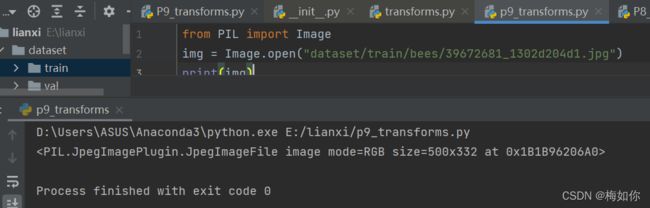
可以看到它是PIL的类型
–call–的用法
class Person:
def __call__(self,name):
print("__call__"+"Hello"+name)
def hello(selef,name):
print("hello"+name)
#我们有两种方式去调用它,内置call就是可以使用person("zhangsan")而不用person.hello("list")
person()#按住ctrl+p就可以知道该传什么参数
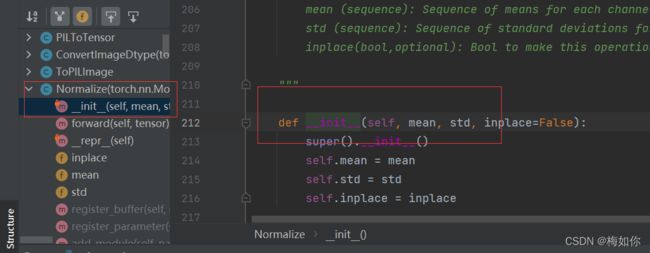
归一化Normalize
output[channel] = (input[channel] - mean[channel]) / std[channel]
归一化公式

输入[0,1]的数值,输出就在[-1,1]之间
transform用法示例
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
img = Image.open("dataset/train/bees/39672681_1302d204d1.jpg")
print(img)
#ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("Totensor",img_tensor)
#Normalize
print(img_tensor[0][0][0])#一开始我们先把我们的img_tensor的第一层第一行第一列输出
trans_norm = transforms.Normalize([6,3,2],[9,3,5])
#括号中的参数需要均值,标准差,因为图片rgb三通道所以需要三个参数
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,2)
#Resize 改变图片尺寸
print(img.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img)
#PIL->totensor -->resize totensor
img_resize = trans_totensor(img_resize)
print(img_resize)
#Compose -resize -2
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize",img_resize_2,1)
writer.close()
关注输入输出、
多看官方文档、
关注方法需要什么参数
不知道返回值的时候(print\print(type())\debug)
3.5 torchvision中数据集的使用
pytorch官网中提供处理声音、处理文本、处理视觉等的模块
其中torchvision就是处理视觉的,tensorboard、transform也是来自里面
torchvison中的datasets
如何使用:
import torchvision
#先取出训练集和验证集,没有数据会自动下载
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set[0])#输出测试数据集中的第一张图片
#(, 3)
#输出是PIL图片类型,target=3,代表是classes中的第四个cat
print(test_set.classes)
#['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
#展示一下这张图片
img,target = test_set[0]
print(img)
print(target)
#3
print(test_set.classes[target])
#cat
img.show()#图片展示出来会是一只猫
和transform进行联动,用tensorboard将其显示出来,将其转化为tensor数据类型
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])#将数据集中的每一张图片都转化为tensor数据类型
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
#注意别忘了加这句transform=dataset_transform
writer = SummaryWriter('p10')
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
#(标题,tensor图片类型,第i张图片)
writer.close()
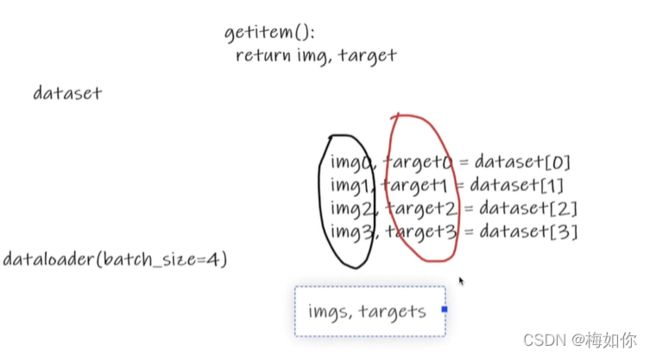
3.6 Dataloader的使用
dataloader是一个加载器,相当于从dataset中取数据

import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
#shuffle设置为true代表随机打乱,drop_last = True代表当64不够除的那部分给丢弃掉
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch: {}".format(epoch), imgs, step)#可以看到两次取都不一样
step = step + 1
writer.close()
3.7 神经网络基本骨架 nn.module的使用
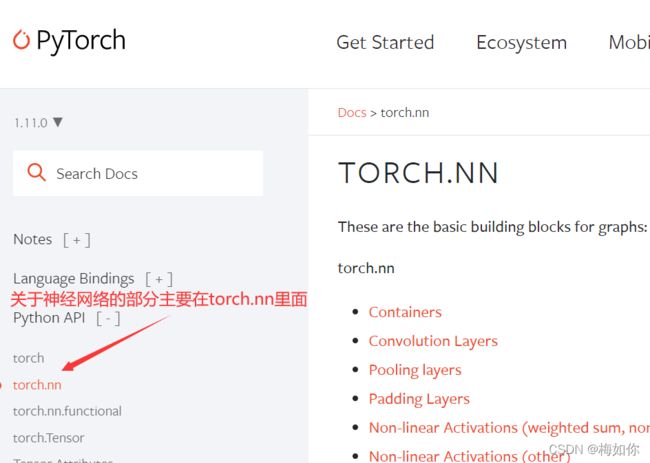
import torch
from torch import nn
#自定义一个类继承nn
class Tudui(nn.Module):
#重写这个方法
def __init__(self):
super().__init__()
#这个神经网络就是给他一个输入input输出就是input+1
def forward(self, input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)
神经网络-卷积层

参数设置

dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
#完成父类的初始化
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
#因为是彩色图像,所以in_channels=3(rgb三通道)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs, targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
#因为输入是6个通道,所以它不知道再怎么显示,所以把它变成3个通道
# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]
#不知道前面是多少就写-1
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
输出:
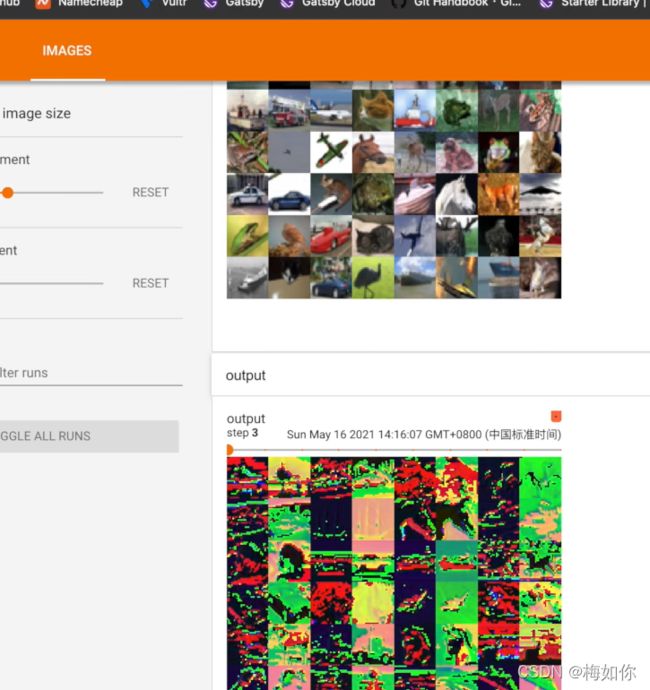
写论文可以用到这个输入、输出转换

神经网络-最大池化层
保留主要特征
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
神经网络-非线性激活
非线性变换的主要目的就是给我们的网络引入一些非线性特征,非线性特征越多就可以训练出符合更多数据的模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
神经网络-线性层
线性层就是最后把输出展平成一维的
把一张5*5图片展成一行25个,最后再把这25个变成3个

class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
#torch.Size([64, 3, 32, 32]) 64个,3通道,32*32大小的图片
output = torch.flatten(imgs)
print(output.shape)
# torch.Size([196608]) 展平有196608个
output = tudui(output)
print(output.shape)
# torch.Size([10]) 把196608变成10分类输出
神经网络-序列squetial
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
CIFAR10 模型
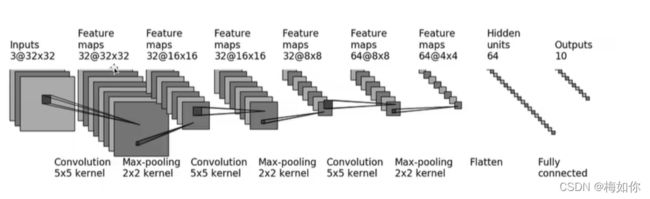
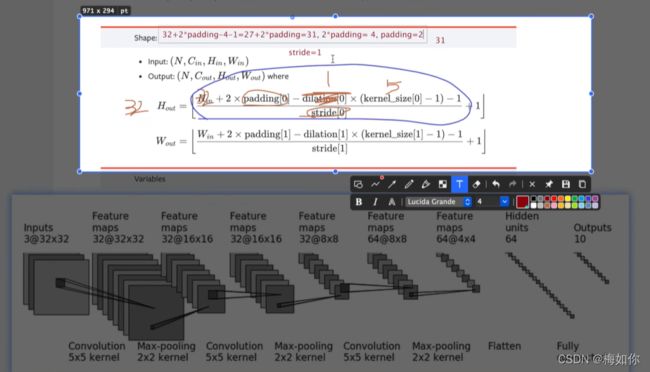
首先它是一个3通道32*32大小的图片,然后经过5*5的卷积核进行一次卷积,变成了32通道,大小没变,然后池化,再卷积,再池化,再卷积,再池化,然后flatten 得到1024,再经过线性层得到64,再经过线性层32输出10分类
我们可以根据公式算出padding和stride的值等于多少
模型的代码实现
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
tudui = Tudui()
print(tudui)
如何验证模型的正确性?
创建一个假想的输入:
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
#就可以看到输出形状是torch.Size([64, 10])
#如果改变1024,那么运行模型就会报错
引入Sequential可以简单很多
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
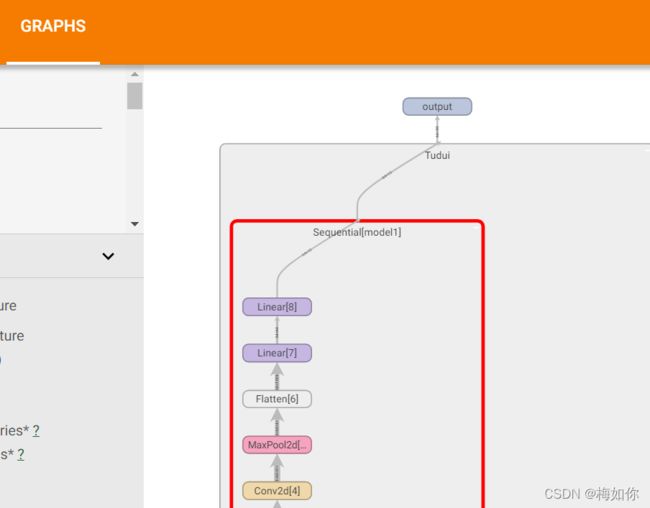
也可以引入tensorboard将模型可视化
writer = SummaryWriter("../logs_seq")
writer.add_graph(tudui,input)
writer.close()
3.8 损失函数
损失函数计算实际输出和目标之间的差距
为我们更新输出提供一定的依据(反向传播)
L1loss和MSE
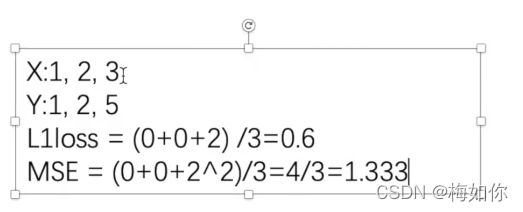
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
#相减结果相加计算损失函数
loss = L1Loss(reduction='sum')
result = loss(inputs, targets)
#平方差计算损失函数
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result)
print(result_mse)
交叉熵
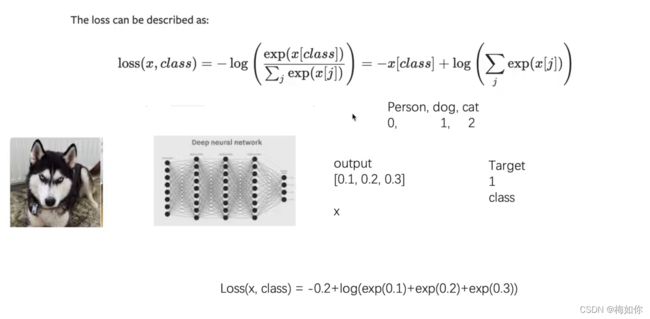
target(class) = 1,说明目标是狗,所以是-0.2,只有当0.2足够大时,也就是预测为狗的概率足够大,预测为其他的概率足够小,得到的损失才最小
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
3.9优化器
#加载数据集,并将其转成tensor数据类型
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
#用dataloader进行加载
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
#定义交叉熵,损失函数
loss = nn.CrossEntropyLoss()
tudui = Tudui()
#优化器,采用随机梯度下降,一般设置lr学习率为0.01小一点
optim = torch.optim.SGD(tudui.parameters(),lr=0.01)
#设置训练20轮
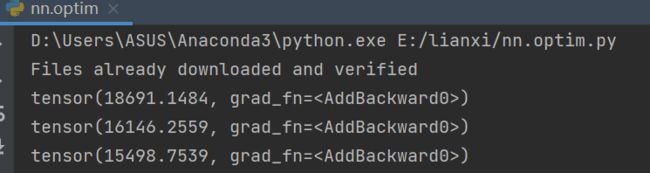
for epoch in range(20):
#在每一轮开始之前都把loss设置为0
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)#计算损失值
#把网络中梯度调为0
optim.zero_grad()
#设置为0后就需要优化器对梯度进行优化,所以我们需要调用反向传播
result_loss.backward()#得到了每一个可以调节的参数对应的梯度
optim.step()#对每个参数进行调优
running_loss = running_loss + result_loss
print(running_loss)
可以看到梯度在明显下降的
四、模型使用
4.1 现有模型的修改
VGG16分类类别是1000个类别,使用数据集是ImageNet
如何运用这个网络模型?如果我们想要完成10分类,那么可以把这个out_features = 1000,改成10,或者在后面再加一个线性成输入1000,输出10分类
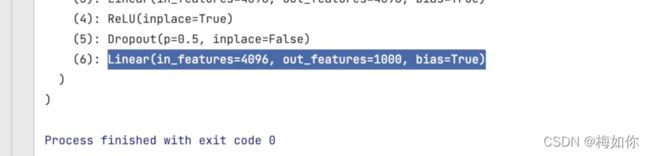
#没有训练过的模型
vgg16_false = torchvision.models.vgg16(pretrained=False)
#已经训练好的模型
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10('../data', train=True, transform=torchvision.transforms.ToTensor(),
download=True)
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)
print(vgg16_false)
#把vgg最后一行修改输出10
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
4.2 模型的保存与加载
model_save.py
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1,模型结构+模型参数
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2,模型参数(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
# 自定义模型的保存
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
torch.save(tudui, "tudui_method1.pth")
model_load.py
import torch
#为了引入自定义的模型
from model_save import *
# 方式1-》保存方式1,加载模型
import torchvision
from torch import nn
model = torch.load("vgg16_method1.pth")
print(model)
# 方式2,加载模型
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
#自定义模型引入
model = torch.load('tudui_method1.pth')
print(model)
4.3 完整的模型训练套路
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# 训练步骤开始
tudui.train()#以后关注网络层有没有一些特殊的层,如果有的话要加上
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
#loss.item()就是将其转化为单纯的数字
# 测试步骤开始
tudui.eval()#这一步作用比较小,但是一般加上比较好,调用它只会对一部分的网络层有作用
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
model.py
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
4.4 利用GPU进行训练
有两种方法
法一:在网络模型、loss损失函数、数据(输入、标注)后面调用.cuda()方法
法二: .to(device)
Device = torch.device(‘cpu’)
Torch.device(“cuda”)
#多个设备
Torch.device(“cuda:0”)
Torch.device(“cuda:1”)
tudui = tudui.cuda()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
# 定义训练的设备
device = torch.device("cuda")
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
4.5 模型验证(测试)套路
已经训练好的模型给他提供输入,进行测试
#引入测试图片
image_path = "../imgs/airplane.png"
image = Image.open(image_path)
print(image)#PIL类型
#因为png格式是四个通道,除了RGB三通道之外,还有一个透明度通道,所以,我们调用这一句是为了保留其颜色通道
image = image.convert('RGB')
#改变图像大小,和将图片转化为tensor数据类型
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Tudui(nn.Module):
....省略网络模型...
#加载模型
model = torch.load("tudui_29_gpu.pth", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
五、其他
为什么现在的CNN模型都是在Resnet、GoogleNet、VGGNet或者AlexNet上调整的?
这些基本模型的改进需要大量的实验和经验积累,一般的研究者和实验室很难负担得起
一般来说,某CNN网络在imagenet上面的分类结果越好,其deep feature的generalization能力越强。最近出现蛮多论文,里面在benchmark上面的比较是自己方法的核心网络换成resnet,然后去比别人基于vgg或者alexnet的方法,自然要好不少。所以对于某个CV的问题,选一个优秀的核心网络作为基础,然后fine-tune, 已经是套路,这点从ResNet那篇论文的citation的增长就可以看出来。fine-tune的原因一是训练AlexNet等网络需要imagenet, places等million级别的数据,一般的CV任务都没有这么多数据。二是因为pre-trained model本身的feature已经足够generalizable,可以立刻应用到另外一个CV任务。至于如何开发出新的CNN分类模型,这就需要积累训练CNN的经验和直觉,以及大量的计算资源来尝试不同的网络结构。一般的研究者和实验室很难负担得起。但如果能搞出个如ResNet一样的牛逼网络,瞬间Best Paper。
进行基本模型的改进需要大量的实验和尝试,很有可能投入产出比比较小。能做到Kaiming ResNet这样的工作真是需要大量的实验积累加强大的灵感,真是偶像。我们大部分人自己的实验过程,很多之前预想的可能会work的idea经过尝试可能提升有限或者不work.
这个领域只有一小部分人是在研究分类的网络结构,其他的应用的研究者,包括视觉、自然语言等更专注于本领域的内部知识,在一个base网络的基础之上进行修改,以验证自己方法的有效性。而这些网络正好提供了这样的baseline,所以何乐而不为呢。自己设计的网络结构有可能也会达到很好的效果,但这就偏离了自己本身的研究点。
数据处理部分
数据增强
Data Augmentation
当数据量不够的时候,在torchvision的transforms中就提供了常用的模块,高效的利用数据
图像预处理
一般是256乘256,再随机裁剪224乘224,这样得到的图像更多了
怎样用人家训练好的模型最好,为了更好的迁移学习,把数据改成和人家的一样会更好
训练集怎么做预处理,那测试集也怎么做预处理
1、神经网络概述(人工神经网络ANN)
https://mp.weixin.qq.com/s/daAtKBffv5dig2XmN-ASxQ
2、激活函数
https://mp.weixin.qq.com/s/pA9JW75p9J5e5KHe3ifcBQ
3、可以copy公式的英文关于神经网络的介绍
https://mlfromscratch.com/neural-networks-explained/#/
4、神经网络训练过程中的一些坑
https://mp.weixin.qq.com/s/OwykbsFufrflSXxhy_6o_w
5、神经网络的推导
https://mp.weixin.qq.com/s/dOOwpsc5_0FHs93syG3SHw
反向传播推导
https://blog.csdn.net/ft_sunshine/article/details/90221691?
http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html
中国书法是以汉字为载体,以文房四宝“笔、墨、纸、砚”作为主要创作工具,以笔法、章法为主要表现技巧,以文字涵义和书法审美取向为表现内容的一种融时间和空间于一体的线条造型艺术。
面的分类结果越好,其deep feature的generalization能力越强。最近出现蛮多论文,里面在benchmark上面的比较是自己方法的核心网络换成resnet,然后去比别人基于vgg或者alexnet的方法,自然要好不少。所以对于某个CV的问题,选一个优秀的核心网络作为基础,然后fine-tune, 已经是套路,这点从ResNet那篇论文的citation的增长就可以看出来。fine-tune的原因一是训练AlexNet等网络需要imagenet, places等million级别的数据,一般的CV任务都没有这么多数据。二是因为pre-trained model本身的feature已经足够generalizable,可以立刻应用到另外一个CV任务。至于如何开发出新的CNN分类模型,这就需要积累训练CNN的经验和直觉,以及大量的计算资源来尝试不同的网络结构。一般的研究者和实验室很难负担得起。但如果能搞出个如ResNet一样的牛逼网络,瞬间Best Paper。
进行基本模型的改进需要大量的实验和尝试,很有可能投入产出比比较小。能做到Kaiming ResNet这样的工作真是需要大量的实验积累加强大的灵感,真是偶像。我们大部分人自己的实验过程,很多之前预想的可能会work的idea经过尝试可能提升有限或者不work.
这个领域只有一小部分人是在研究分类的网络结构,其他的应用的研究者,包括视觉、自然语言等更专注于本领域的内部知识,在一个base网络的基础之上进行修改,以验证自己方法的有效性。而这些网络正好提供了这样的baseline,所以何乐而不为呢。自己设计的网络结构有可能也会达到很好的效果,但这就偏离了自己本身的研究点。
数据处理部分
数据增强
Data Augmentation
当数据量不够的时候,在torchvision的transforms中就提供了常用的模块,高效的利用数据
图像预处理
一般是256乘256,再随机裁剪224乘224,这样得到的图像更多了
怎样用人家训练好的模型最好,为了更好的迁移学习,把数据改成和人家的一样会更好
训练集怎么做预处理,那测试集也怎么做预处理
1、神经网络概述(人工神经网络ANN)
https://mp.weixin.qq.com/s/daAtKBffv5dig2XmN-ASxQ
2、激活函数
https://mp.weixin.qq.com/s/pA9JW75p9J5e5KHe3ifcBQ
3、可以copy公式的英文关于神经网络的介绍
https://mlfromscratch.com/neural-networks-explained/#/
4、神经网络训练过程中的一些坑
https://mp.weixin.qq.com/s/OwykbsFufrflSXxhy_6o_w
5、神经网络的推导
https://mp.weixin.qq.com/s/dOOwpsc5_0FHs93syG3SHw
反向传播推导
https://blog.csdn.net/ft_sunshine/article/details/90221691?
http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html
中国书法是以汉字为载体,以文房四宝“笔、墨、纸、砚”作为主要创作工具,以笔法、章法为主要表现技巧,以文字涵义和书法审美取向为表现内容的一种融时间和空间于一体的线条造型艺术。