3.1_21 JavaSE入门 P20 【正则】Pattern模式类、Matcher匹配器、元字符、分组捕获、反向引用
相关链接
- Excel目录
- 正则表达式 - 在线工具
- java8-api-online
目录
- P20 【正则】Pattern模式类、Matcher匹配器、元字符、分组捕获、反向引用
-
- 1.正则表达式 - 入门体验
-
- 1.1 入门1 提取文章中所有的英文单词
- 1.2 入门2 提取文章中所有的数字
- 1.3 入门3 提取文章中所有的英文单词和数字
- 1.4 入门4 提取百度热搜标题
- 1.5 入门5 找到所有的IP地址
- 2.正则表达式 - 底层实现
-
- 2.1 案例 找出四个连续数字
- 2.2 原理 Matcher源码
- 2.3 应用 找出四个连续数字,2、3位相等
- 3.正则表达式 - 基本语法
-
- 3.1 贪婪模式
- 3.2 分组捕获与反向引用
- 4.正则匹配 - 元字符使用案例
-
- 4.1 正则转义符 \\
- 4.2 分组捕获 - 与内部反向引用
- 4.3 分组捕获 - 与外部反向引用(结巴去重)
- 4.4 反向否定零宽断言
- 5.Pattern模式类
-
- 5.1 Pattern.CASE_INSENSITIVE 大小写不敏感模式
- 5.2 Pattern.COMMENTS 注释模式
- 5.3 Pattern.MULTILINE 多行匹配模式
- 6.Matcher匹配器
- 7.PatternSyntaxException异常类
- 8.正则表达式 - 应用案例
-
- 8.1 String.split()使用正则分割
- 8.2 String.matches()使用正则校验
- 8.3 邮箱校验
- 8.4 域名解析
- 8.5 爬虫百度热搜
- 8.6 LeetCode算法5
- 9.正则表达式 - 常用功能
-
- 9.1 解析hive建表语句
- 附录 在线工具设置
P20 【正则】Pattern模式类、Matcher匹配器、元字符、分组捕获、反向引用
今日要掌握的内容:
- 【理解】理解正则表达式作用
- 【理解】理解正则表达式底层原理
- 【应用】掌握正则表达式的基本语法
- 【应用】掌握正则表达式的三个常用类(1.模式类Pattern、2.匹配器Matcher、3.异常类PatternSyntaxException)
- 【应用】掌握正则表达式的分组、捕获、反向引用
- 【应用】掌握正则表达式的元字符(1.限定符、2.选择匹配符、3.分组组合和反向引用符、4.特殊字符、5.字符匹配符、6.定位符)
- 【练习】应用实例
1.正则表达式 - 入门体验
1.概念: 正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),适用于大部分主流开发语言(C,Java,Python,SQl等)。是对字符串(包括普通字符 例如,a 到 z 之间的字母,和特殊字符(称为“元字符”))进行模式匹配的技术,可以达到快速处理(匹配、校验、过滤、清洗等)文本的目的。
1.1 入门1 提取文章中所有的英文单词
a. 待处理文本
1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的静态网页能够“灵活”起来,急需一种软件技术来开发一种程序,这种程序可以通过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投入了大量的人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结构进行编写的,所以非常小,特别适用于网络上的传输系统,而Oak也是一种精简的语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以嵌入网页并且可以随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的技术),并将Oak更名为Java(在申请注册商标时,发现Oak已经被人使用了,再想了一系列名字之后,最终,使用了提议者在喝1杯Java咖啡时无意提到的Java词语)。
b.匹配模式
Pattern pattern = Pattern.compile("[a-zA-Z]+");
c.匹配结果
【1.1 提取文章中所有的英文单词】找到1: Oak
【1.1 提取文章中所有的英文单词】找到2: IT
【1.1 提取文章中所有的英文单词】找到3: Sun
【1.1 提取文章中所有的英文单词】找到4: Oak
【1.1 提取文章中所有的英文单词】找到5: Oak
【1.1 提取文章中所有的英文单词】找到6: Sun
【1.1 提取文章中所有的英文单词】找到7: Applet
【1.1 提取文章中所有的英文单词】找到8: Applet
【1.1 提取文章中所有的英文单词】找到9: Oak
【1.1 提取文章中所有的英文单词】找到10: Java
【1.1 提取文章中所有的英文单词】找到11: Oak
【1.1 提取文章中所有的英文单词】找到12: Java
【1.1 提取文章中所有的英文单词】找到13: Java
案例代码一 提取文章中所有的英文单词
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/09
* @introduction 1.1 正则快速入门 - 提取文章中所有的英文单词
*/
public class Demo01Regexp {
public static void main(String[] args) {
String content = "1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的" +
"静态网页能够“灵活”起来,急需一种软件技术来开发一种程序,这种程序可以通" +
"过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投入了大量的" +
"人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且" +
"重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结" +
"构进行编写的,所以非常小,特别适用于网络上的传输系统,而Oak也是一种精简的" +
"语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以嵌入网页并且可以" +
"随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的技术)," +
"并将Oak更名为Java(在申请注册商标时,发现Oak已经被人使用了,再想了一系列" +
"名字之后,最终,使用了提议者在喝1杯Java咖啡时无意提到的Java词语)。";
int number = 0;
//需求:提取文章中所有的英文单词
//方式一:传统方式:遍历字符串,判断每个字符的ASCII码,代码量大,效率不高
//方式二:正则表达式
//1 创建Pattern对象,模式对象,可以理解成就是一个正则表达式对象
Pattern pattern = Pattern.compile("[a-zA-Z]+");
//2 创建Matcher匹配器对象
//理解:匹配器Matcher按照pattern(模式/样式),到content文本中去匹配
//找到就返回true,否则就返回false
Matcher matcher = pattern.matcher(content);
//3 开始匹配循环
while (matcher.find()) {
//匹配内容,文本,放到 matcher.group()
System.out.println("【1.1 提取文章中所有的英文单词】找到" + (++number) + ": " + matcher.group(0));
}
}
}
1.2 入门2 提取文章中所有的数字
a. 待处理文本
1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的静态网页能够“灵活”起来,急需一种软件技术来开发一种程序,这种程序可以通过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投入了大量的人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结构进行编写的,所以非常小,特别适用于网络上的传输系统,而Oak也是一种精简的语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以嵌入网页并且可以随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的技术),并将Oak更名为Java(在申请注册商标时,发现Oak已经被人使用了,再想了一系列名字之后,最终,使用了提议者在喝1杯Java咖啡时无意提到的Java词语)。
b.匹配模式
Pattern pattern = Pattern.compile("[0-9]+");
c.匹配结果
【1.2 提取文章中所有数字】找到1: 1995
【1.2 提取文章中所有数字】找到2: 1
案例代码二 提取文章中所有的数字
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/09
* @introduction 1.2 正则快速入门 - 提取文章中所有数字
*/
public class Demo02Regexp {
public static void main(String[] args) {
String content = "1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的" +
"静态网页能够“灵活”起来,急需一种软件技术来开发一种程序,这种程序可以通" +
"过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投入了大量的" +
"人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且" +
"重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结" +
"构进行编写的,所以非常小,特别适用于网络上的传输系统,而Oak也是一种精简的" +
"语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以嵌入网页并且可以" +
"随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的技术)," +
"并将Oak更名为Java(在申请注册商标时,发现Oak已经被人使用了,再想了一系列" +
"名字之后,最终,使用了提议者在喝1杯Java咖啡时无意提到的Java词语)。";
int number = 0;
//1.创建Pattern对象,模式对象,可以理解成就是一个正则表达式对象
Pattern pattern = Pattern.compile("[0-9]+");
//2.创建Matcher匹配器对象
//理解:匹配器Matcher按照pattern(模式/样式),到content文本中去匹配
//找到就返回true,否则就返回false
Matcher matcher = pattern.matcher(content);
//3.开始匹配循环
while (matcher.find()) {
//匹配内容,文本,放到 matcher.group()
System.out.println("【1.2 提取文章中所有数字】找到" + (++number) + ": " + matcher.group(0));
}
}
}
1.3 入门3 提取文章中所有的英文单词和数字
a. 待处理文本
1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的静态网页能够“灵活”起来,急需一种软件技术来开发一种程序,这种程序可以通过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投入了大量的人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结构进行编写的,所以非常小,特别适用于网络上的传输系统,而Oak也是一种精简的语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以嵌入网页并且可以随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的技术),并将Oak更名为Java(在申请注册商标时,发现Oak已经被人使用了,再想了一系列名字之后,最终,使用了提议者在喝1杯Java咖啡时无意提到的Java词语)。
b.匹配模式
Pattern.compile("([0-9])+|([a-zA-Z]+)")
c.匹配结果
【1.3 提取文章中所有数字和英文单词】找到1: 1995
【1.3 提取文章中所有数字和英文单词】找到2: Oak
【1.3 提取文章中所有数字和英文单词】找到3: IT
【1.3 提取文章中所有数字和英文单词】找到4: Sun
【1.3 提取文章中所有数字和英文单词】找到5: Oak
【1.3 提取文章中所有数字和英文单词】找到6: Oak
【1.3 提取文章中所有数字和英文单词】找到7: Sun
【1.3 提取文章中所有数字和英文单词】找到8: Applet
【1.3 提取文章中所有数字和英文单词】找到9: Applet
【1.3 提取文章中所有数字和英文单词】找到10: Oak
【1.3 提取文章中所有数字和英文单词】找到11: Java
【1.3 提取文章中所有数字和英文单词】找到12: Oak
【1.3 提取文章中所有数字和英文单词】找到13: 1
【1.3 提取文章中所有数字和英文单词】找到14: Java
【1.3 提取文章中所有数字和英文单词】找到15: Java
案例代码三 提取文章中所有的英文单词和数字
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/09
* @introduction 1.3 正则快速入门 - 提取文章中所有数字和英文单词
*/
public class Demo03Regexp {
public static void main(String[] args) {
String content = "1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的" +
"静态网页能够“灵活”起来,急需一种软件技术来开发一种程序,这种程序可以通" +
"过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投入了大量的" +
"人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且" +
"重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结" +
"构进行编写的,所以非常小,特别适用于网络上的传输系统,而Oak也是一种精简的" +
"语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以嵌入网页并且可以" +
"随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的技术)," +
"并将Oak更名为Java(在申请注册商标时,发现Oak已经被人使用了,再想了一系列" +
"名字之后,最终,使用了提议者在喝1杯Java咖啡时无意提到的Java词语)。";
int number = 0;
//1.创建Pattern对象,模式对象,可以理解成就是一个正则表达式对象
Pattern pattern = Pattern.compile("([0-9])+|([a-zA-Z]+)");
//2.创建Matcher匹配器对象
//理解:匹配器Matcher按照pattern(模式/样式),到content文本中去匹配
//找到就返回true,否则就返回false
Matcher matcher = pattern.matcher(content);
//3.开始匹配循环
while (matcher.find()) {
//匹配内容,文本,放到 matcher.group()
System.out.println("【1.3 提取文章中所有数字和英文单词】找到" + (++number) + ": " + matcher.group(0));
}
}
}
1.4 入门4 提取百度热搜标题
a. 待处理文本
Step1: 打开 百度搜索,右击鼠标,选择检查,使用浏览器工具查看源码
Step2: 使用浏览器工具,查看百度热搜所在源码位置,复制源码(复制该内容)
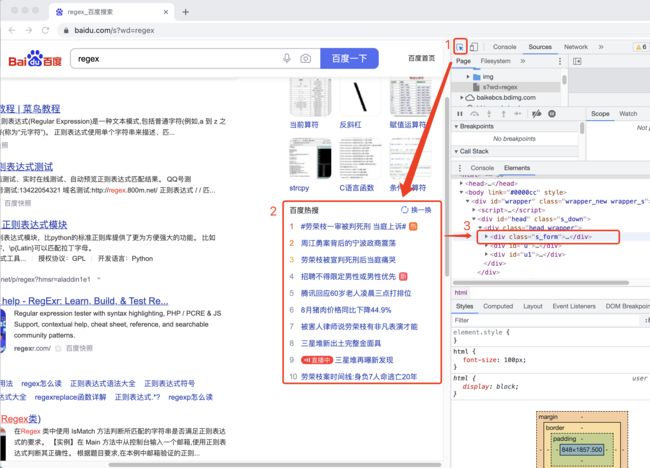
b.匹配模式
Pattern pattern = Pattern.compile(");
c.匹配结果
【1.4 提取百度热搜标题】找到1: ********背后的********
【1.4 提取百度热搜标题】找到2: ***************痛哭
【1.4 提取百度热搜标题】找到3: 招聘**********
【1.4 提取百度热搜标题】找到4: 腾讯回应60岁老人凌晨三点打排位
【1.4 提取百度热搜标题】找到5: 8月猪肉价格同比下降44.9%
【1.4 提取百度热搜标题】找到6: *********有非凡表演才能
【1.4 提取百度热搜标题】找到7: 三星堆新出土完整金面具
【1.4 提取百度热搜标题】找到8: 三星堆再曝新发现
【1.4 提取百度热搜标题】找到9: ******:身负7*****20年
【1.4 提取百度热搜标题】找到10: 张家齐陈芋汐全运会再现复制粘贴
【1.4 提取百度热搜标题】找到11: ********31次提及**
【1.4 提取百度热搜标题】找到12: ****济南整形机构****
【1.4 提取百度热搜标题】找到13: 过半学生可解开游戏防沉迷系统
【1.4 提取百度热搜标题】找到14: 中方决定向****提供价值2亿援助
【1.4 提取百度热搜标题】找到15: ****男子电梯******
【1.4 提取百度热搜标题】找到16: 广东祖孙3人********
【1.4 提取百度热搜标题】找到17: 南京这些文娱场所恢复开放
【1.4 提取百度热搜标题】找到18: ***政府将出现女性职位
【1.4 提取百度热搜标题】找到19: 货拉拉乘客********
【1.4 提取百度热搜标题】找到20: ******一女子乘出租车****司机
【1.4 提取百度热搜标题】找到21: 中消协回应视频平台超前点播
【1.4 提取百度热搜标题】找到22: 李维嘉代言******
【1.4 提取百度热搜标题】找到23: 意大利连续37场不败破巴西纪录
【1.4 提取百度热搜标题】找到24: 老人用****给孙子*********
【1.4 提取百度热搜标题】找到25: 吉林省原***********
【1.4 提取百度热搜标题】找到26: 大表姐劳伦斯****
【1.4 提取百度热搜标题】找到27: **************阅兵式
【1.4 提取百度热搜标题】找到28: 妈妈为女儿长高每天逼其跳绳3000个
案例代码四 提取百度热搜标题
package com.groupies.base.day20; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * @author GroupiesM * @date 2021/09/09 * @introduction 1.4 正则快速入门 - 提取百度热搜标题 */ public class Demo04Regexp { public static void main(String[] args) { //4.提取百度热搜标题 String content = "略"; int number = 0; //System.out.println(content); //1 创建Pattern对象,模式对象,可以理解成就是一个正则表达式对象 Pattern pattern = Pattern.compile("); //2.创建Matcher匹配器对象 //理解:匹配器Matcher按照pattern(模式/样式),到content文本中去匹配 //找到就返回true,否则就返回false Matcher matcher = pattern.matcher(content); //3.开始匹配循环 while (matcher.find()) { //匹配内容,文本,放到 matcher.group() System.out.println("【1.4 提取百度热搜标题】找到" + (++number) + ": " + matcher.group(1)); } } }
1.5 入门5 找到所有的IP地址
a. 待处理文本
私有地址(Private address)属于非注册地址,专门为组织机构内部使用。
以下列出留用的内部私有地址
A类 10.0.0.0--10.255.255.255
B类 172.16.0.0--172.31.255.255
C类 192.168.0.0--192.168.255.255
b.匹配模式
Pattern pattern = Pattern.compile("(\\d+\\.){3}(\\d+)");
c.匹配结果
【1.5 找到所有的IP地址】 找到1: 10.0.0.0
【1.5 找到所有的IP地址】 找到2: 10.255.255.255
【1.5 找到所有的IP地址】 找到3: 172.16.0.0
【1.5 找到所有的IP地址】 找到4: 172.31.255.255
【1.5 找到所有的IP地址】 找到5: 192.168.0.0
【1.5 找到所有的IP地址】 找到6: 192.168.255.255
案例代码五 找到所有的IP地址
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/09
* @introduction 1.5 正则快速入门 - 找到所有的IP地址
*/
public class Demo05Regexp {
public static void main(String[] args) {
//5.找到所有的IP地址
String content = "私有地址(Private address)属于非注册地址,专门为组织机构内部使用。\n" +
"以下列出留用的内部私有地址\n" +
"A类 10.0.0.0--10.255.255.255\n" +
"B类 172.16.0.0--172.31.255.255\n" +
"C类 192.168.0.0--192.168.255.255";
//1.创建Pattern对象,模式对象,可以理解成就是一个正则表达式对象
Pattern pattern = Pattern.compile("(\\d+\\.){3}(\\d+)");
//2.创建Matcher匹配器对象
//理解:匹配器Matcher按照pattern(模式/样式),到content文本中去匹配
//找到就返回true,否则就返回false
Integer number = 0;
Matcher matcher = pattern.matcher(content);
//3.开始匹配循环
while (matcher.find()) {
//匹配内容,文本,放到 matcher.group()
System.out.println("【1.5 找到所有的IP地址】 找到" + (++number) + ": " + matcher.group(0));
}
}
}
2.正则表达式 - 底层实现
2.1 案例 找出四个连续数字
a. 待处理文本
1998年12月8日,第二代Java平台的企业版J2EE发布。
1999年6月,Sun公司发布了第二代Java平台(简称为Java2)的3个版本:
J2ME(Java2 Micro Edition,Java2平台的微型版):应用于移动、无线及有限资源的环境
J2SE(Java 2 Standard Edition,Java 2平台的标准版):应用于3433桌面环境
J2EE(Java 2Enterprise Edition,Java 2平台的企业版):应用于基于Java的应用服务器
Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着Java的应用开始普及9889
b.匹配模式
Pattern pattern = Pattern.compile("\\d\\d\\d\\d");
c.正则解析
1. \\d中的第一个\是转义符号,将第二个\转成普通符号
2. \\d 实际表达的意思是 \d ,表示一个任意的数字
3. \\d\\d\\d\\d 则表示四个连续的任意数字
d.匹配结果
【2.1 找出四个连续数字】 找到1: 1998
【2.1 找出四个连续数字】 找到2: 1999
【2.1 找出四个连续数字】 找到3: 3433
【2.1 找出四个连续数字】 找到4: 9889
案例代码六 找出四个连续数字
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/09
* @introduction 2.1 正则表达式 - 底层原理1
*/
public class Demo06RegTheory {
public static void main(String[] args) {
String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。\n" +
"1999年6月,Sun公司发布了第二代Java平台(简称为Java2)的3个版本:\n" +
"J2ME(Java2 Micro Edition,Java2平台的微型版):应用于移动、无线及有限资源的环境\n" +
"J2SE(Java 2 Standard Edition,Java 2平台的标准版):应用于3433桌面环境\n" +
"J2EE(Java 2Enterprise Edition,Java 2平台的企业版):应用于基于Java的应用服务器\n" +
"Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着Java的应用开始普及9889";
int number = 0;
//目标:找出所有四个数字连在一起的子串
//1.创建正则表达式 (\\d:表示任意一个数字)
String regStr = "\\d\\d\\d\\d";
//2.创建模式对象 (正则表达式对象)
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
//说明:按照正则表达式的规则去匹配content字符串
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
System.out.println("【2.1 找出四个连续数字】 找到" + (++number) + ": " + matcher.group(0));
}
}
}
2.2 原理 Matcher源码
2.2.A Matcher.find()方法
a.Matcher.find()功能:
1.通过 Pattern.matcher() 方法实例化对象,并给text属性赋值(text属于字符序列类CharSequence)
//Matcher matcher = pattern.matcher(content);
CharSequence text;
2.通过 Matcher.find()方法匹配一次,根据匹配结果给匹配器Matcher的部分属性赋值
//while (matcher.find()) {}
2.1 int[] groups (上一次匹配起始索引)
2.2 int oldLast (上次匹配结束索引)
下一次执行find方法时从上次 oldLast 索引位置开始
b.Matcher类部分源码:
public final class Matcher implements MatchResult {
...
/**
* The storage used by groups. They may contain invalid values if
* a group was skipped during the matching.
*/
int[] groups; 记录匹配子字符串的起止索引
整个子字符串的起止索引: groups[0]、groups[1]
第一组子字符串的起止索引:groups[2]、groups[3]
第二组子字符串的起止索引:groups[4]、groups[5]
第三组子字符串的起止索引:groups[6]、groups[7]
...
/**
* The end index of what matched in the last match operation.
*/
int oldLast = -1; 记录上一次匹配的结束位置,oldLast = groups[1]
...
Pattern parentPattern;
...
transient Node root;
...
public boolean find() {
int nextSearchIndex = last;
if (nextSearchIndex == first)
nextSearchIndex++;
// If next search starts before region, start it at region
if (nextSearchIndex < from)
nextSearchIndex = from;
// If next search starts beyond region then it fails
if (nextSearchIndex > to) {
for (int i = 0; i < groups.length; i++)
groups[i] = -1;
return false;
}
return search(nextSearchIndex);
}
...
boolean search(int from) {
this.hitEnd = false;
this.requireEnd = false;
from = from < 0 ? 0 : from;
this.first = from;
this.oldLast = oldLast < 0 ? from : oldLast;
for (int i = 0; i < groups.length; i++)
groups[i] = -1;
acceptMode = NOANCHOR;
boolean result = parentPattern.root.match(this, from, text);//核心逻辑
if (!result)
this.first = -1;
this.oldLast = this.last;
return result;
}
...
Node类部分源码(parentPattern.root.match
...
boolean match(Matcher matcher, int i, CharSequence seq) {
matcher.last = i;
matcher.groups[0] = matcher.first;
matcher.groups[1] = matcher.last;
return true;
}
...
c.代码执行过程:
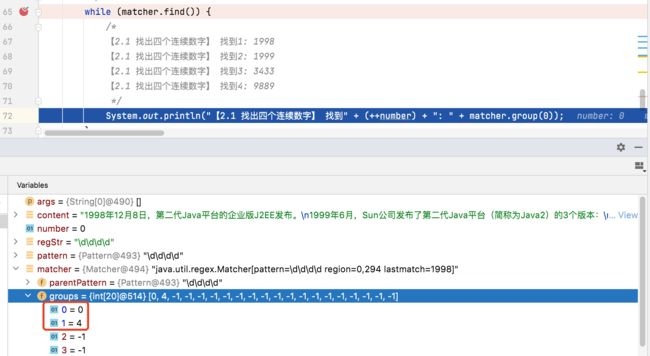
Step1: 根据指定的规则,定位子字符串的起、止索引值,记录到matcher对象的属性中(此处以1998为例) ;
Step2: 找到后,将子字符串的起始索引值记录到Matcher 对象的属性值 int[] groups ;
1998索引开始位置 : groups[0] = 0;
1998索引结束位置+1: groups[1] = 4;
就是[0,4),包含 0 但是不包含索引为 4 的位置;
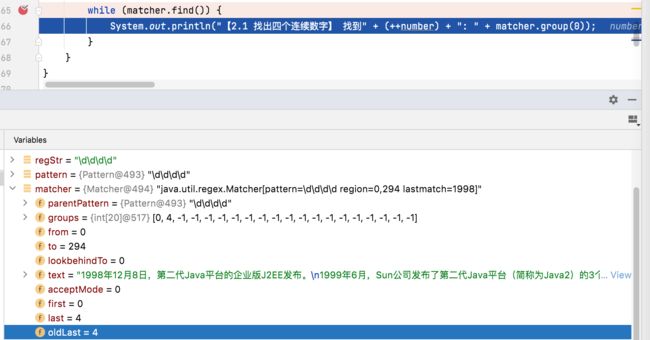
Step3: 记录Matcher 对象的属性值 oldLast = groups[1] = 4, 即下次匹配的起始索引值=4 ;
1998匹配后 : oldLast = 4
Step2:通过debug验证 groups[0] = 0; groups[1] = 4; 即匹配到的子字符串的起止索引分别为0和4;
step3:通过debug验证 oldLast = 4,即下次匹配的起始索引值=4 ;
2.2.B Matcher.group()方法
a.Matcher.group()功能:
1.通过 Pattern.matcher() 方法实例化对象,并给text属性赋值(text属于字符序列类CharSequence)
//Matcher matcher = pattern.matcher(content);
CharSequence text;
2.通过 Matcher.find()方法匹配一次,根据匹配结果给匹配器Matcher的部分属性赋值
//while (matcher.find()) {}
2.1 int[] groups (上一次匹配起始索引)
2.2 int oldLast (上次匹配结束索引)
下一次执行find方法时从上次 oldLast 索引位置开始
3. 通过 Mathcer.group()方法获取该次匹配的匹配结果
核心逻辑:
public String group(int group) {
根据传入参数获取要截取的字符位置 :参数x2 = 起始索引,参数x2+1 = 截止索引
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
获取全子字符串,传入参数 (0) => 根据起始索引group[0] 和截至索引group[1] ,通过getSubSequence截取原字符串text,并返回
获取第一个分组,传入参数 (1) => 根据起始索引group[2] 和截至索引group[3] ,通过getSubSequence截取原字符串text,并返回
获取第二个分组,传入参数 (2) => 根据起始索引group[4] 和截至索引group[5] ,通过getSubSequence截取原字符串text,并返回
获取第三个分组,传入参数 (3) => 根据起始索引group[6] 和截至索引group[7] ,通过getSubSequence截取原字符串text,并返回
...
b.Matcher类部分源码:
public final class Matcher implements MatchResult {
...
@Contract(pure=true)
/*每次调用传入值为group(0)
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
=> return getSubSequence(groups[0 * 2], groups[0 * 2 + 1]).toString();
=> return getSubSequence(groups[0], groups[1]).toString();
∵ group[0]=0 且 group[1]=4
=> return getSubSequence(0,4).toString();
*/
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
...
//截取字符串,等于String的substring方法
CharSequence getSubSequence(int beginIndex, int endIndex) {
return text.subSequence(beginIndex, endIndex);
}
...
c.执行过程分析:
Step1: 通过Pattern.compile() 实例化Matcher对象,给Matcher的text属性赋值;
Step2: 通过matcher.find()方法匹配一次,如果返回true,则表示匹配到一次结果,进入循环;如果返回false则结束循环;
Step3: 通过matcher.group()获取指定的匹配结果;
Step4: 再次执行find方法,循环上面的执行逻辑 ;
public static void main(String[] args) {
String content = "xxx";
//1.创建正则表达式
String regStr = "xxx";
//2.创建模式对象 (正则表达式对象)
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
System.out.println(matcher.group(0));
}
}
2.3 应用 找出四个连续数字,2、3位相等
a. 待处理文本
1998年12月8日,第二代Java平台的企业版J2EE发布。
1999年6月,Sun公司发布了第二代Java平台(简称为Java2)的3个版本:
J2ME(Java2 Micro Edition,Java2平台的微型版):应用于移动、无线及有限资源的环境
J2SE(Java 2 Standard Edition,Java 2平台的标准版):应用于3433桌面环境
J2EE(Java 2Enterprise Edition,Java 2平台的企业版):应用于基于Java的应用服务器
Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着Java的应用开始普及9889
b.匹配模式
Pattern pattern = Pattern.compile("\\d(\\d)(\\d)\\d");
c.正则解析
1. \\d 表示一个任意的数字
2. () 在正则表达式中表示分组
3. \d(\d)(\d)\d 表示分成两组,第一组为第2位数,第二组为第3位数
4. 调用matcher.find(),根据指定的规则,将匹配到的子字符串起始索引值【以(19)(98)为例】赋值给int[] groups
4.1 groups[0] = 1 开始位置
4.2 groups[1] = 4 结束位置
4.3 groups[2] = 0 1(9)(9)8中的第一个9开始位置
4.4 groups[3] = 1 1(9)(9)8中的第一个9结束位置
4.5 groups[4] = 1 1(9)(9)8中的第二个9结束位置
4.6 groups[5] = 2 1(9)(9)8中的第二个9结束位置
5. 调用matcher.group(),根据每一组groups属性值截取字符串
5.1 全部子字符串 matcher.group(0) = 1998
5.2 第一组 matcher.group(1) = 9
5.3 第二组 matcher.group(2) = 9
6. 判断第一组和第二组相等时再输出即可
d.匹配结果
【2.2 找出四个连续数字,且2、3位相等】 找到1: 1998
【2.2 找出四个连续数字,且2、3位相等】 找到2: 1999
【2.2 找出四个连续数字,且2、3位相等】 找到3: 9889
e.补充说明:通过分组捕获、反向引用的方式可以更方便的处理这种需求
案例代码七 找出四个连续数字,且2、3位相等
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/09
* @introduction 2.2 正则表达式 - 底层原理2
*/
public class Demo07RegTheory {
public static void main(String[] args) {
String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。\n" +
"1999年6月,Sun公司发布了第二代Java平台(简称为Java2)的3个版本:\n" +
"J2ME(Java2 Micro Edition,Java2平台的微型版):应用于移动、无线及有限资源的环境\n" +
"J2SE(Java 2 Standard Edition,Java 2平台的标准版):应用于3433桌面环境\n" +
"J2EE(Java 2Enterprise Edition,Java 2平台的企业版):应用于基于Java的应用服务器\n" +
"Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着Java的应用开始普及9889";
int number = 0;
//1.创建正则表达式 (\\d:表示任意一个数字)
String regStr = "\\d(\\d)(\\d)\\d";
//2.创建模式对象 (正则表达式对象)
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
//说明:按照正则表达式的规则去匹配content字符串
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
//4.1 判断第2位和第3位值相等时,再输出
if (matcher.group(1).equals(matcher.group(2))) {
System.out.println("【2.2 找出四个连续数字,且2、3位相等】 找到" + (++number) + ": " + matcher.group(0));
}
}
}
}
3.正则表达式 - 基本语法
1.语法: 正则表达式(regular expression)描述了一种字符串匹配模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
2.Java使用正则标准格式
public static void main(String[] args) {
String content = "1a2b3c";
//1.创建正则表达式 (\\d:表示任意一个数字)
String regStr = "\\d";
//2.创建模式对象 (正则表达式对象)
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
//说明:按照正则表达式的规则去匹配content字符串
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
System.out.println(matcher.group(0));//匹配到3次,结果分别为 1 2 3
}
}
3.正则表达式语法: 按照4.元字符分类中定义的名称,大致可以按照以下规则使用正则表达式:
① 规定1: A.普通字符 或 字符串 指定字符串范围 + B.特殊字符 给普通字符 或 字符串添加规则(例如字符串长度,出现次数,大小写,分组等)。
② 规定2: A.普通字符 或 字符串 必须出现,B.特殊字符 可以不出现。
③ 规定3: A.普通字符 或 字符串 可以单独使用,B.特殊字符 不能单独使用。
④ 特殊字符1: b3.限定符 的?在子表达式后面表示限定,当?跟在另一个 b3.限定符 后面表示非贪婪匹配模式。
⑤ 特殊字符2: b4.定位符 的^在[ ]外面在用作定位,在[ ]里面使用(且必须在第一个),表示取反。
例如[^abc]是表示对abc取反;[\^abc]是表示abc^这四个字符,[a^bc]也表示abc^这四个字符
⑥ 特殊字符3: Java中转义符号"\“在使用时需要注意用叠词词。例如元字符\d 需要写作”\\d",第一个"\“作用是将第二个”\“的转为原义。第二个没有特殊含义的”\“和"d"组成元字符”\d" 。
⑦ Java正则与其他正则: 由于Java封装,正则表达式语法有一些细微的差别,例如 这里所讲的修饰符,java中默认使用g全局匹配,其他模式例如:i大小写不敏感,s多行匹配,m点阵模式,需要通过Pattern模式类的compile方法或 b7.嵌入式表达式 来实现。嵌入式表达式不是所有语言都支持的,比如JavaScript就不支持嵌入式表达式。
⑧ 表达多样性: 在保证功能的情况下尽量使表达式简洁易读,例如a((?i)b)c与a[bB]c是基本等价的,用来匹配字符串"abc"或者"aBc"。但第一种模式看起来很难读懂,我会选择使用第二种方式。区别在于第一组为了使 b7.嵌入式表达式 (?i)只修饰字符b,所以添加了小括号,等于使用了分组捕获,所以与a((?i)b)c 完全等价的应该是 a([bB])c,如果没有反向引用的需求,写作a[bB]c就可满足需求。
⑨ 执行顺序: 多个 B.特殊字符 同时使用时,要注意解析顺序,下表从最高到最低说明了各种正则表达式运算符的优先级顺序:原文 。
| 运算符 | 描述 |
|---|---|
\ |
转义符 |
(),(?:),(?=),[] |
圆括号和方括号 |
*,+,?,{n},{n,},{n,m} |
b3.限定符 |
^,$,\任何元字符,任何字符 |
b4.定位符 和序列 |
| ` | ` |
4.元字符: 元字符意思是在正则表达式中,会被特殊处理的字符(按照默认规则进行处理),叫元字符。元字符经常成对出现,一些常用的序列组合就成对(大小写关系)定义为了一些元字符方便使用。例如\d表示数字序列,即[0-9]、\D表示非数字,等价于[^\d]或[^0-9]。
5.元字符分类: 以下分类网上众说纷纭,没有标准名称,我按照自己的理解,造词进行了分类
A.普通字符: 所有 可能出现的字符;
a1.可见字符: 可以直接观察到的字符。如abC123,可以搭配连字符-和字符列表[]使用[a-z]表示小写字母a到z、[0-9]表示0到9、还有一些元字符表达特定可见字符序列,\w表示字母
abc 匹配abc这个字符串,这个并不属于元字符,只是个字符串
[abc] 匹配abc中任意一个字符
a[ab] 匹配aa或者ab中,等价于aa|ab
\d 匹配数字字符,等效于 [0-9]
\w 匹配字母or数字or下划线,与[A-Za-z0-9_]等效
\S 匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。
a2.不可见字符: 不可以直接观察到的字符。如[\r]表示回车符、[\n]表示换行符
空格,不可见字符都属于非打印字符
\f 匹配换页符,等效于 \x0c 和 \cL
\n 匹配换行符,等效于 \x0a 和 \cJ
\r 匹配回车符,等效于 \x0d 和 \cM
\t 匹配垂直制表符匹配,与 \x0b 和 \cK 等效
\v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
\s 匹配任何空白字符,包括空格、制表符、换页符等,与 [ \f\n\r\t\v] 等效
a3.薛定谔的字符: 在匹配到字符之前,处于量子叠加状态,既可见又不可见。匹配到的一瞬间坍缩为可见/不可见状态之一。常见于取反字符序列"[^xxx]"、\大写字母
[^a-z] 匹配非小写字母字符,对一个可见字符列表取反,取反内容同时包含可见、不可见字符
比较下面两个案例,可以看出来[^a-z]会匹配到换行符


\D 匹配非数字字符,等价于[^d]和[^0-9]
\W 匹配非字母、数字、下划线字符,等价于^w和[^A-Za-z0-9_]
\S 匹配非空白字符,等价于[^\s]和[^ \f\n\r\t\v]
. 匹配换行符(\n)以外的任何字符
B.特殊字符: 一些有特殊含义的字符,若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符**\** 放在它们前面,如*、.、?;
b1.基本符号: 正则表达式的基本组成部分
\ 转义字符:正则表达式中,将后面一个字符转义,可以简单理解为键盘上的shift键;①如果是原义字符,则转义为元字符(如果存在的话),②如果是转义字符,转为原义字符。举例:
d: 是原义字符,通过加 \ 成为元字符\d, \d表示所有数字
c: 是原义字符,通过加 \ 也变不成元字符,\c还会提示正则表达式错误
*: 是转义字符,表示匹配前面的子表达式0次或多次,通过加 \ 成为原义字符,* 表示*这个字符
\: 是转义字符,功能是将后面一个字符转义,如果想使用元字符\d,需要输入\\d
() 需要成对使用,括号内的内容优先运算,而且会按照左括号出现的顺序进行分组捕获,通过分组进而可以使用反向引用。
[] 需要成对使用,表示字符合集,括号内的内容会视作一个字符的范围,大部分转义字符在中括号里面表达这个字符本身,除了个别字符例如"^“和”-"
- 在[]里使用时
可以表示"-“这个字符本身,例如[\d-]表示所有数字和”-“符号。
也可以表示一个范围,叫连字符,例如 [a-c] 等价于[abc],会匹配到"a"或"b"或"c”
b2.运算逻辑: 指定普通表达式之间的组合关系
XY 匹配"XY"这个字符串
X|Y 匹配X或Y
^ 用在[]里
可以表示"^"这个字符本身,例如[a^bc]表示"abc^"这四个字符
也可以表示 取反,例如 [^abc] 表示除了"abc"以外的任一字符,即对 [abc]取反
b3.限定符: 指定正则表达式给定组合的出现次数,有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种
{n} 对限定的表达式匹配确定的n次
{n,} 对限定的表达式匹配至少n次
{n,m} 对限定的表达式匹配至少n次,至多m次
? 等价于 [0,1] 对限定的表达式匹配至少0次,至多1次
* 等价于 [0,n] 对限定的表达式匹配至少0次,至多不限制
+ 等价于 [1,n] 对限定的表达式匹配至少1次,至多不限制
b4.定位符: 匹配到的是符合条件的位置,而不是字符,所以也叫零宽(占0个字符)
^ 匹配字符串起始位置,即前面没有其他字符 ,测试1-3
$ 匹配字符串结束位置,测试4
\b 匹配单词边界,即没有其他字母(\w),测试5-6
\B 匹配非单词边界,即相邻位置必须是\w => [0-9a-zA-Z_] ,测试7-8
测试1:(^ 匹配字符串起始位置)
XY
YX
XYZ
需求: 匹配除了X以外的所有字符
正则: ”[^X]” //这里^不能在中括号[]中使用,在中括号中[^]表示对字符列表取反,这里很容易混淆
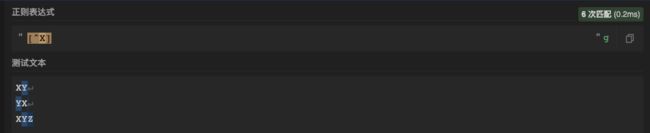
测试2:(^ 匹配字符串起始位置)
XY
YX
XYZ
需求: 匹配在开头的X,匹配模式为单行匹配 //Java默认为单行模式,即^和$只能对整个字符串匹配一次
正则: ”^X”

测试3:(^ 匹配字符串起始位置)
XY
YX
XYZ
需求: 匹配在开头的X,匹配模式为多行匹配 //开启多行模式(详见Pattern类compile方法)后,可以对字符串的每一行都匹配一次
正则: ”^X”(开启多行模型)
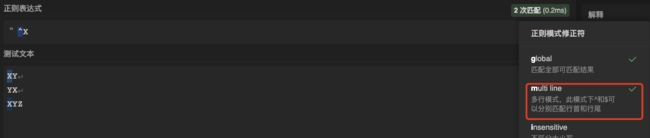
测试4: ($ 匹配字符串结束位置)
ZX
ZXC
X
需求: 匹配在结尾的X,匹配模式为
正则: ”X$”(开启多行模型)

测试5: “AXY XY XYZ”(\b 匹配单词边界)
需求: 匹配XY,其中Y的右边是单词边界
正则: ”XY\b”

测试6: “AXY XY XYZ”(\b 匹配单词边界)
需求: 匹配XY,其中X的左边是单词边界
正则: ”XY\b”

测试7: “AXY XY XYZ”(\B 匹配非单词边界)
需求: 匹配XY,其中Y的右边不是单词边界
正则: ”XY\B”

测试8: “AXY XY XYZ”(\B 匹配非单词边界)
需求: 匹配XY,其中X的左边不是单词边界
正则: ”\BXY”

b5.非获取匹配: 和定位符作用类似,但这里的条件是由一个子级正则表达式 pattern 来表示,这个子级表达式仅用作定位,不参与匹配。
(pattern) 分组捕获 ,不属于非获取匹配,因为表达式的内容参与了最终匹配,放在这里是为了和 零宽断言(?:pattern) 作比较,测试9
(?:pattern) 零宽断言,测试10
经测试(pattern) 分组捕获与(?:pattern) 零宽断言都不属于非获取匹配,但 runoob.com 显示为零宽,所以暂且放在这个分类
(?:pattern)与(pattern)的区别在于
① (pattern)中的内容视为分组捕获,因为只有一对括号,所以放在了第一组group(1)中;
② (?:pattern)没有进行分组捕获,匹配结果作为一个整体放在group(0)中;
(?=pattern) 正向肯定零宽断言,代表字符串中的一个位置,紧接该位置之后的字符序列能够匹配pattern。(zero-width positive lookahead assertion), 测试11
(?!pattern) 正向否定零宽断言,代表字符串中的一个位置,紧接该位置之后的字符序列不能匹配pattern。 (zero-width negative lookbehind assertion),测试12
(?<=pattern) 反向肯定零宽断言, 代表字符串中的一个位置,紧接该位置之前的字符序列能够匹配pattern。(zero-width positive lookahead assertion),测试13
(? 反向否定零宽断言,代表字符串中的一个位置,紧接该位置之前的字符序列不能匹配pattern。zero-width positive lookbehind assertion),测试14
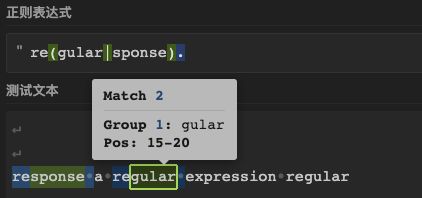
测试9: “response a regular expression”((pattern) 分组捕获)
需求: 匹配regular或response,再加上后面一个字符
正则: “re(gular|sponse).”
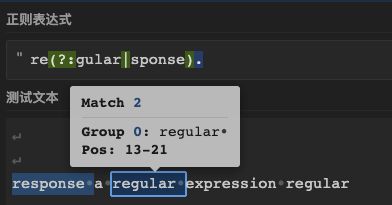
测试10: “response a regular expression”((?:pattern) 零宽断言)
需求: 匹配regular或response,再加上后面一个字符
正则: “re(?:gular|sponse).”
测试11: “response a regular expression”((?=pattern) 正向肯定零宽断言)
需求: 匹配regular中的re和response中的re,但不能匹配expression中的re,再加上后面一个字符;
正则: “re(?=gular|sponse).”
解析:该表达式限定了re右边(正向)的位置,可以(肯定)是gular或者sponse,但并不参与最终匹配(零宽)。(?=gular|sponse) 这部分就叫正向肯定零宽断言;

测试12: “response a regular expression”((?!pattern) 正向否定零宽断言)
需求: 匹配所有re,再加上后面一个字符,但后面这个字符不能是g;
正则: “re(?!g).”
解析:该表达式限定了re右边(正向)的位置,不能(否定)是g,但并不参与最终匹配(零宽)。(?=gular|sponse) 这部分就叫正向否定零宽断言;元字符.匹配了response的s和regular的g,括号这一坨匹配了re之后的表达式是否符合规则

测试13: “regex represents regular expression”((?<=pattern) 反向肯定零宽断言)
需求: 匹配单词内部的re,但不匹配单词开头的re。
正则: “(?<=\w)re”
翻译:该表达式限定了re左边(反向)的位置,可以(肯定)是字符,但\w不参与最终匹配(零宽),(?<=\w) 这部分就叫反向肯定零宽断言;

测试14: “regex represents regular expression”((? 反向否定零宽断言)
需求: 匹配单词开头的re,但不匹配单词内部的re;
正则: “(? 翻译:该表达式限定了re左边(反向)的位置,不能(否定)是字符,但\w不参与最终匹配(零宽),(? 这部分就叫反向否定零宽断言;

b6.分组捕获: 将匹配到的子串,按要求进行分组,需要将正则表达式括起来,表示一个整体 (X) ;
b7.嵌入式表达式: 设置正则表达式的解析模式,常用的有大小写不敏感模式(?i),注释模式 (?x),多行模式(?m),详情见 5.Pattern的Pattern.compile 方法
3.1 贪婪模式
b3.限定符: 指定正则表达式的一个给定组件必须要出现多少次才能满足匹配,有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种,限定符有两种匹配模式。贪婪匹配模式 和 非贪婪匹配模式
贪婪模式: 匹配符合条件的最长字符串,默认为此模式;
例如:
(.)\1+,表示匹配连续出现重复的字符,+表示对限定的表达式匹配至少1次,至多不限制

非贪婪模式: 匹配符合条件的最短字符串,需要在限定符后面加上 ?;
例如:
(.)\1+?,表示匹配连续出现重复的字符,?表示非贪婪匹配模式

3.2 分组捕获与反向引用
b6.分组捕获: 分组后,一般有三种用法;
① 内部反向引用(可以理解为动态正则表达式)来添加正则匹配的规则;
② 外部反向引用对正则表达式进行部分替换;
③ 类比 入门4 提取百度热搜标题 案例中,提取正则中的某一部分值。
分组: 将匹配到的子串,按要求进行分组,需要将正则表达式括起来,表示一个整体 (X) ;
捕获: 将分组内容,保存在Matcher类的属性group中,组1为group(1),组2位group(2),以此类推。组0代表整个子串;
反向引用: 捕获后再次使用,称为反向引用。这种引用可以再正则内部,也可以在正则外部;
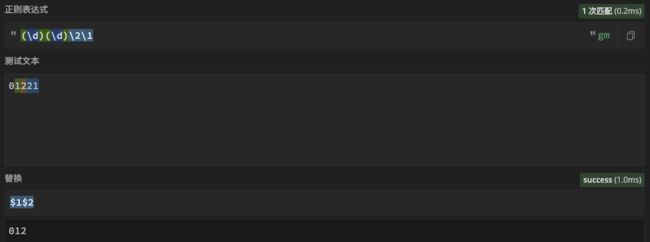
内部反向引用: 在正则表达式内部使用,\分组号数字,一般用于添加匹配规则
例如:
(\d)(\d)\2{2}\1=> 表示匹配 ABBBA 格式的数字

外部反向引用: 在正则表达式外部使用,$分组号数字,一般用于正则匹配后的替换
例如:匹配到ABBA格式数字后,ABBA替换为AB
public static void main(String[] args) { final String regex = "(\\d)(\\d)\\2\\1"; final String string = "01221"; final String subst = "$1$2"; final Pattern pattern = Pattern.compile(regex, Pattern.MULTILINE); final Matcher matcher = pattern.matcher(string); final String result = matcher.replaceAll(subst); //替换结果: 012 System.out.println("替换结果: " + result); //简写为 Pattern.compile("(\\d)(\\d)\\2\\1").matcher("01221").replaceAll("$1$2"); }$1表示匹配到的第一组内容:1
$2表示匹配到的第二组内容:2
01221中匹配到的部分为1221,1221被替换为$1$2 ,最后结果为012
4.正则匹配 - 元字符使用案例
元字符列表 (删除线表示不常用,一些很少用到的元字符未列入此表)
| id | demo | sign | 作用 | 示例 | 说明 | 匹配示例 |
|---|---|---|---|---|---|---|
| 1 | 4.1 | \ | 转义符号,将下一个字符标记为一个特殊字符,属于b1.基本符号 | \\d | 第一个"\“将第二个”“转为原义字符,第二个”\“没有转义的功能。并且第二个”\"和"d"组成元字符\d,表示数字类型 | 见4.1案例 |
| 1 | 4.2 | () | 分组,组内优先计算,还可用于b6.分组捕获和反向引用,属于b1.基本符号 | \\d(\\d)\\1\\d | 四个连续数字,2、3位相等 | 见4.2案例 |
| 2 | - | [] | 自定义字符集合,可接收的字符列表,属于b1.基本符号 | [efgh\] | 在自定义字符集合中,除了开头位的^表示取反,其他任何特殊符号都只表达本身含义,没有转义的含义。这里[efgh\]表示e、f、g、h,\中的任意1个字符 | e、g、\ |
| 3 | - | - | 需要在[ ]里使用。连字符,表示范围 ,属于b1.基本符号 | [A-Z] | 任意单个大写字母 注意:连字符"-"需要放在两个字符之间,如果写为[AZ-]则表示"AZ-"这三个字符 |
A、C |
| 4 | - | ^ | 需要在[ ]起始位置使用。取反,表示除了自定义字符集合以外的,属于b2.运算逻辑符 | [^a-c] | 除a、b、c之外的任意1个字符,包括数字和特殊符号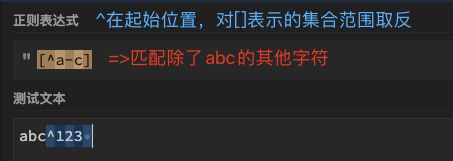 注意:^只有在起始位置时才表示取反,否则表示定位符"^"本身 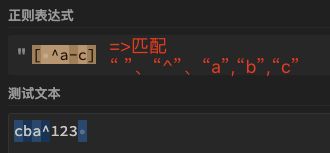 |
d、" " (空格) |
| 5 | - | | | 表示"或"的关系,属于b2.运算逻辑符 | x|y | x或y | x、y |
| 6 | 5.3 | ^ | 需要在[ ]以外使用。表示匹配开头的位置,属于b4.定位符 | ^ab | 匹配ab字符串,a必须是在行开头处,需要注意Java默认匹配模式位单行模式,也就是最多会匹配一次,如果需要多行匹配模式 参考 5.3 Pattern.MULTILINE 多行匹配模式 |
abcdab 中的高亮部分 |
| 7 | 5.3 | $ | 表示匹配结尾的位置,属于b4.定位符 | ab$ | 匹配ab字符串,b必须是在行结尾处,需要注意Java默认匹配模式位单行模式,也就是最多会匹配一次,如果需要多行匹配模式 参考 5.3 Pattern.MULTILINE 多行匹配模式 |
abcdab 中的高亮部分 |
| 8 | - | {n} | 修饰前一个对象,n是一个非负整数,匹配确定的 n 次,属于b3.限定符 | (木大){2} | {2} 修饰的对象"木大",连续出现2次 | 木大木大 |
| 9 | - | {n,} | 修饰前一个对象,n是一个非负整数,匹配至少 n 次,属于b3.限定符 | (木大){1,} | {1,} 修饰的对象"木大",至少连续出现1次,默认为贪婪匹配模式 ,满足条件的前提下,匹配尽可能多的结果,如果需要非贪婪匹配模式 参考 3.1 贪婪模式 |
木大、木大木大、木大木大木大 |
| 10 | - | {n,m} | 修饰前一个对象,n和m都为非负整数,且n<=m,匹配至少 n 次,至多m次 ,属于b3.限定符 | 木大{2,3} | {2,3} 修饰的对象"大",连续出现至少2次,至多3次,这里的{2,3}对字符"木"不起作用。 默认为贪婪匹配模式 ,满足条件的前提下,匹配尽可能多的结果,如果需要非贪婪匹配模式 参考 3.1 贪婪模式 |
木大大、木大大大 |
| 11 | - | * | 匹配前面的子表达式0次或多次,* 等价于{0,},属于b3.限定符 | 欧(拉)* | * 修饰的对象"拉",至少连续出现0次,这里的 * 对字符"欧"不起作用 | 欧、欧拉、欧拉拉 |
| 12 | - | + | 匹配前面的子表达式1次或多次,+ 等价于{1,},属于b3.限定符 | (欧拉)+ | + 修饰的对象"欧拉",至少连续出现1次 | 欧拉、欧拉欧拉、欧拉欧拉欧拉 |
| 13 | - | ? | 匹配前面的子表达式0次或1次,+ 等价于{0,1} ,属于b3.限定符 | 欧(拉)? | ? 修饰的对象"拉",至少连续出现0次或1次 | 欧、欧拉 |
| 14 | - | ? | 需要跟在一个 b3.限定符后面,启用非贪婪匹配模式 | (欧拉)+? | 满足(欧拉)+条件的情况下,欧拉最少的次数,即匹配最少的结果 |
欧拉 |
| 15 | 1.5 | (pattern) | 分组捕获,一般用于以下功能: ① 内部反向引用(可以理解为动态正则表达式)来添加正则匹配的规则; ② 外部反向引用对正则表达式进行部分替换; ③ 类比 入门4 提取百度热搜标题 案例中,提取正则中的某一部分值 |
pattern表示一串正则表达式,在 b5.非获取匹配 中有详细介绍 | 见1.5案例 | |
| 16 | - | (?:pattern) | 零宽断言 测试结果:非零宽断言 |
pattern表示一串正则表达式,在 b5.非获取匹配 中有详细介绍 | - | |
| 17 | - | (?=pattern) | 正向肯定零宽断言 zero-width positive lookahead assertion |
作用类似于b4.定位符,不参与匹配结果。=表示正向肯定,?表示零宽,pattern 表示断言,在 b5.非获取匹配 中有详细介绍 | - | |
| 18 | - | (?!pattern) | 正向否定零宽断言 zero-width negative lookbehind assertion |
作用类似于b4.定位符,不参与匹配结果。!表示正向否定,?表示零宽,pattern 表示断言,在 b5.非获取匹配 中有详细介绍 | - | |
| 19 | - | (?<=pattern) | 反向肯定零宽断言 zero-width positive lookbehead assertion |
作用类似于b4.定位符,不参与匹配结果。<=表示反向肯定,?表示零宽,pattern 表示断言,在 b5.非获取匹配 中有详细介绍 | - | |
| 20 | 4.4 | (? | 反向否定零宽断言 zero-width negative lookbehind assertion |
作用类似于b4.定位符,不参与匹配结果。反向否定,?表示零宽,pattern 表示断言,在 b5.非获取匹配 中有详细介绍 案例含义:该表达式限定了re左边(反向)的位置,不能(否定)是字符,但\w不参与最终匹配(零宽),(? 这部分就叫反向否定零宽断言; |
- | |
| 21 | - | \b | 匹配单词边界且零宽。零宽表示\b自身不参与匹配,属于b4.定位符 | er\b | 表示er后面需要是单词的边界,可以匹配"never"中的"er",但不能匹配"verb"中的"er",这里\b匹配的范围是会将[a-zA-Z0-9_]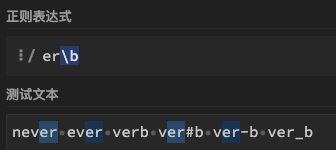 |
never、header |
| 22 | - | \B | 匹配非单词边界且零宽。也就是指所在位置是a1.可见字符,且\B自身不参与匹配,属于b4.定位符 | \Bla | 表示la前面不能是单词边界,可以匹配"impala"中的"la",但不能匹配"lamp"中的"la"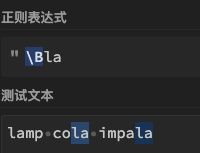 |
impala、cola |
| 23 | - | \d | 匹配数字字符,也就是指单词和空格之间的位置,等价于[0-9]、[^\D],属于a1.可见字符 | \d\d | 表示两个连续数字 | 15、22 |
| 24 | - | \w | 匹配常用字符,等价于[A-Za-z0-9_],[^\W],属于a1.可见字符 | \w\w | 表示两个连续的字母or数字or下划线 | a_、68、_1、qw |
| 25 | - | \S | 匹配非空白字符,于[^ \f\n\r\t\v],[^\s],属于a1.可见字符 | \S* | 表示匹配任何连续的可见字符串,例如字符串"abc 1@“,则会匹配到四次,第一次匹配结束后oldLast=2,第二次会从索引2的位置开始匹配,但索引2位置字符是空格” ",匹配到的结果为null,按理说这个null不应该返回,但经过测试确实是反回了。这里应该是属于正则匹配规则的bug 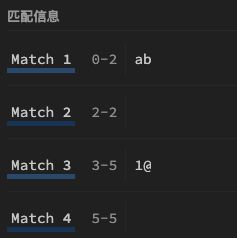 |
第1次:ab 第2次: 第3次:1@ 第4次: |
| - | - | |||||
| - | - | |||||
| - | - | |||||
| - | - | |||||
| - | - | |||||
| 31 | - | \s | 匹配空白字符,包括空格、制表符等等。等价于[ \f\n\r\t\v],属于a2.不可见字符 | hello\s | 表示hello后面跟一个不可见字符,能匹配"hello world" 中的hello,但不能匹配"helloworld"中的hello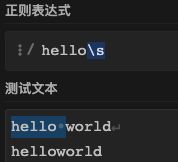 |
“hello\t”,"hello " |
| 32 | - | . | 匹配除 \n 以外的任一个字符,属于a3.薛定谔的字符 | a…b | 以a开头,b结尾,中间包括2个任意字符且长度为4的字符串,如果需要点阵模式("."可以匹配\n) 参考 5.2 Pattern.COMMENTS 注释模式 |
aaab、aefb、a35b、a#*b |
| 33 | - | \D | 匹配非数字字符,等价于[^0-9],[^\d],属于a3.薛定谔的字符 | A\D | 表示A后面跟一个非数字字符,后面的非数字字符可以是字母,空格,甚至换行符等 |
- |
| 34 | - | \W | 匹配非常用字符,等价于[^A-Za-z0-9_],[^\w],属于a3.薛定谔的字符 | \Bla | 表示la前面不能是单词边界,可以匹配"impala"中的"la",但不能匹配"lamp"中的"la" | impala、cola |
| 35 | 4.2 | \number | number表示分组号的数字,b6.分组捕获后的内部反向引用,这里不考虑八进制转义用法 | (\d)\1 | 表示两个连续且相等的数字,\1表示引用组1的内容,和组1完全一致 |
11、22、33 |
| 36 | 4.3 | $number | number表示分组号的数字,b6.分组捕获后的外部反向引用 | number:$1 | 除了案例4.结巴去重用法,还可以像这样,批量修改指定内容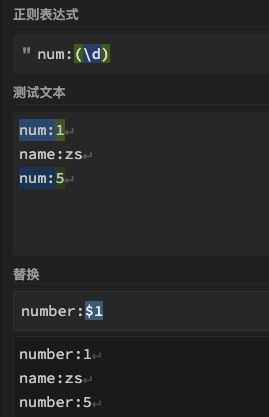 |
- |
4.1 正则转义符 \
元字符(Metacharacter) - 转义符(\): 当匹配的目标字符串中有特殊符号时,需要通过\将转义符号转为原义字符,正则表达式中需要用到转义符号的字符有:.、*、+、(、)、$、/、\、?、[、]、{、}、^,Java中正则表达式是作为字符串传入的,所以"也需要进行转义
a.需求: 匹配所有的"(",和其相应的后面一位的字符
b. 待处理文本
abc$(abc(123(
c.匹配模式
Pattern pattern = Pattern.compile("\\(.");
d.正则解析
1. 第一个\表示对第二个\进行转义,
2. 第二个转义后的\对(进行转义,即\(
3. .表示匹配除 \n 以外的任何1个字符
e.匹配结果
【4.1 正则转义符】 找到1: (a
【4.1 正则转义符】 找到2: (1
案例代码八 正则转义符 “\”
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/10
* @introduction 4.1 正则转义符
* 需求:使用转义符号,匹配特殊字符
*/
public class Demo08Regexp {
public static void main(String[] args) {
String content = "abc$(abc(123(";
int number = 0;
//1.创建正则表达式 \\(表示查找特殊字符"("
String regStr = "\\(.";
//2.创建模式对象 (正则表达式对象)
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
System.out.println("【4.1 正则转义符】 找到" + (++number) + ": " + matcher.group(0));
}
}
}
4.2 分组捕获 - 与内部反向引用
a.需求: 找出四个连续数字,2、3位相等,并将2,3位都替换成**
b. 待处理文本
1998年12月8日,第二代Java平台的企业版J2EE发布。
1999年6月,Sun公司发布了第二代Java平台(简称为Java2)的3个版本:
J2ME(Java2 Micro Edition,Java2平台的微型版):应用于移动、无线及有限资源的环境
J2SE(Java 2 Standard Edition,Java 2平台的标准版):应用于3433桌面环境
J2EE(Java 2Enterprise Edition,Java 2平台的企业版):应用于基于Java的应用服务器
Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着Java的应用开始普及9889
c.匹配模式
Pattern pattern = Pattern.compile("\\d((\\d)\\1)\\d");
d.正则解析
1. ()表示分组捕获,按照左括号出现顺序进行分组
2. \2表示引用第一组内的内容,\2与第一组捕获内容完全一致,即2,3位相等
3. ((\d)\2) 这里的扩号将(\d)和\2都括起来是为了将其分组,匹配后可以通过外部反向引用进行替换
e.匹配结果
【4.2 内部反向引用】 找到1: 1998
【4.2 内部反向引用】 找到2: 1999
【4.2 内部反向引用】 找到3: 9889
案例代码九 分组捕获 - 与内部反向引用
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/18
* @introduction 4.2 分组捕获 - 与内部反向引用
* 需求:找出四个连续数字,2、3位相等
*/
public class Demo09Regexp {
public static void main(String[] args) {
String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。 " +
"1999年6月,Sun公司发布了第二代Java平台(简称为Java2)的3个版本: " +
"J2ME(Java2 Micro Edition,Java2平台的微型版):应用于移动、无线及有限资源的环境 " +
"J2SE(Java 2 Standard Edition,Java 2平台的标准版):应用于3433桌面环境 " +
"J2EE(Java 2Enterprise Edition,Java 2平台的企业版):应用于基于Java的应用服务器 " +
"Java 2平台的发布,是Java发展过程中最重要的一个里程碑,标志着Java的应用开始普及9889";
int number = 0;
//1.创建正则表达式
String regStr = "\\d(\\d)\\1\\d";
//2.创建模式对象 (正则表达式对象)
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
System.out.println("【4.2 内部反向引用】 找到" + (++number) + ": " + matcher.group(0));
}
}
}
4.3 分组捕获 - 与外部反向引用(结巴去重)
a.匹配需求: 当出现多个连续重复字符时,只保留第一个
b. 待处理文本
aabb33334
c.匹配模式
Pattern pattern = Pattern.compile("(.)\\1+");
d.正则解析
1. ()表示分组捕获,按照左括号出现顺序进行分组
2. .除了换行符\n以外任意字符
3. \1表示内部反向引用
4. +表示至少出现1次
5. matcher.replaceAll(String str);表示将所有匹配到的字符替换为指定字符串
e.匹配结果
【4.3 分组捕获 - 外部反向引用】 找到1: aa
【4.3 分组捕获 - 外部反向引用】 找到2: bb
【4.3 分组捕获 - 外部反向引用】 找到3: 3333
f.替换结果
content: ab34
案例代码十 分组捕获 - 与外部反向引用
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/18
* @introduction 4.3 分组捕获 - 与外部反向引用
* 需求:当出现多个连续重复字符出现时,只保留第一个
*/
public class Demo10Regexp {
public static void main(String[] args) {
String content = "aabb33334";
int number = 0;
//1.创建正则表达式
String regStr = "(.)\\1+";
//2.创建模式对象 (正则表达式对象)
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
System.out.println("【4.3 分组捕获 - 外部反向引用】 找到" + (++number) + ": " + matcher.group(0));
}
//5.替换匹配到的重复字符串,只保留第一位
content = matcher.replaceAll("$1");
System.out.println("content: " + content);
}
}
4.4 反向否定零宽断言
a.匹配需求: 找出所有re开头的单词
b. 待处理文本
regex represents regular expression finish
c.匹配模式
Pattern pattern = Pattern.compile("(?);
d.正则解析
1. (?<!pattern)表示反向否定零宽断言
2. (?<!\w)限定了re左边(<反向)的位置,不能(!否定)是字符(\w),但\w不参与最终匹配(?零宽)
3. 第二个转义后的\对(进行转义,即\(
4. .表示匹配除 \n 以外的任何1个字符
e.匹配结果
【4.4 反向否定零宽断言】 找到1: regex
【4.4 反向否定零宽断言】 找到2: represents
【4.4 反向否定零宽断言】 找到3: regular
案例代码十一 反向否定零宽断言
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/18
* @introduction 4.4 反向否定零宽断言
* 需求:匹配单词开头的re,但不匹配单词内部的re
*/
public class Demo11Regexp {
public static void main(String[] args) {
String content = "regex represents regular expression finish";
int number = 0;
//1.创建正则表达式
String regStr = "(?;
//2.创建模式对象 (正则表达式对象)
Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
//说明:按照正则表达式的规则去匹配content字符串
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
System.out.println("【4.4 反向否定零宽断言】 找到" + (++number) + ": " + matcher.group(0));
}
}
}
5.Pattern模式类
Pattern模式类: pattern对象是一个正则表达式对象。Pattern类没有公共构造方法,要创建一个 Pattern 对象,调用其公共静态方法,他会返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。
//关于Pattern模式类只需要了解compile方法即可
Pattern pattern = Pattern.compile(String regex)
Pattern.compile( )方法: 通过方法的重载,有两种实现方式,这里主要介绍flag参数的取值和案例
/**
* 方式1
* @param regex 正则表达式
*/
Pattern Pattern.compile(String regex);
/**
* 方式2
* @param regex 正则表达式
* @param flag 编译模式的标志
* 控制正则表达式的匹配行为的参数,多个参数用 | 分隔
* 例如 Pattern.CASE_INSENSITIVE | Pattern.COMMENTS
* 注:这里flag取值范围为Pattern类的默认定义属性值,可以通过属性值赋值,也可以直接赋值
* Pattern p = Pattern.compile("xxx", Pattern.CASE_INSENSITIVE);
* Pattern p = Pattern.compile("xxx", 2);
* 以上两种方式完全等价
*/
Pattern Pattern.compile(String regex, int flag)
编译标志:调用Pattern.compile时指定flag参数值使用。编译标志的枚举值定义在Pattern类中,静态修饰,可以直接通过类名获取 => Pattern.xx;
注1: 定义使用的十六进制值(例如0x01),对应十进制值见最后一列;
注2: unicode相关标志(对应十进制的64,128,256)不建议使用,也不常用,会造成性能损失;
注3: 嵌入式表达式意思为放在正则表达式内中使用(见下面案例),方式比编译标志更加灵活,但使用会比较麻烦;
注4: 掌握最常用的标红的三种模式即可;
注5: 关于DOTALL,早期的正则表达式工具是基于行处理文本的,所以.匹配的是除换行符以外的任意字符。大多数编程语言在设计正则表达式时沿用了这个传统,但是提供一个选项用于开启"点号匹配换行符"模式;
| id | flag取值范围 | 嵌入式表达式 | 描述 | 十六进制 | 十进制 |
|---|---|---|---|---|---|
| 0 | GLOBAL | - | 全局模式。开启全局模式后匹配全部可以匹配的结果,否则只会匹配一次。 Java默认为全局模式,其他语言使用正则才需要指定(flag没有这个取值,是我瞎编的) |
- | - |
| 1 | UNIX_LINES | (?d) | Unix行模式。只有’/n’才被认作一行的中止,并且与’.‘,’^‘,以及’$'进行匹配。 | 0x01 | 1 |
| 2 | CASE_INSENSITIVE | (?i) | 大小写不敏感模式。 | 0x02 | 2 |
| 3 | COMMENTS | (?x) | 注释模式。在此模式下正则表达式中允许出现空格和注解,①忽略空格;②以#开头的嵌入式注释将被忽略,直到行尾。 |
0x04 | 4 |
| 4 | MULTILINE | (?m) | 多行模式。在多行模式下,表达式^和$分别匹配每一行终止符或输入序列的结尾$。默认情况下只匹配整个输入序列的开头和结尾。 |
0x08 | 8 |
| 5 | LITERAL | 无 | 文字解析模式。序列中的元字符或转义序列将没有特殊的含义。 | 0x10 | 16 |
| 6 | DOTALL | (?s) | 点阵模式。表达式.匹配任何字符,包括行终止符。默认情况下,.不能匹配换行符\n。 |
0x20 | 32 |
| 7 | (?u) | Unicode感知的大小写折叠。 默认情况下,不区分大小写的匹配假定仅匹配US-ASCII字符集中的字符。 |
0x40 | 64 | |
| 8 | 无 | 正规分解模式。是Unicode字符集编码中的一个规范 简单来说就是两个不同的code point表示同一个字符Pattern pattern=Pattern.compile(“a\u030A”,Pattern.CANON_EQ); Matcher matcher=pattern.matcher(“\u00E5”); System.out.println(matcher.find()); // true 默认情况下,匹配不考虑采用规范等价。 |
0x80 | 128 | |
| 9 | (?U) | Unicode版本的预定义字符类和POSIX字符类。 | 0x100 | 256 |
5.1 Pattern.CASE_INSENSITIVE 大小写不敏感模式
| 示例 (?i)后面的字符不区分大小写 | 说明 | 匹配示例 |
|---|---|---|
| Pattern pat = Pattern.compile(“(?i)abc”) | 表示abc都不区分大小写 | abc、ABC |
| Pattern pat = Pattern.compile(“a(?i)bc”) | 表示bc不区分大小写 | abc、aBC |
| Pattern pat = Pattern.compile(“a((?i)b)c”) | 表示b不区分大小写 | abc、aBc |
| Pattern pat = Pattern.compile(“abc”,Pattern.CASE_INSENSITIVE) | 通过方法重载,指定大小写不敏感 | abc、ABC |
案例代码十二 2) Pattern.CASE_INSENSITIVE (?i) 的使用
package com.groupies.base.day20.pattern;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/10
* @introduction 2) Pattern.CASE_INSENSITIVE (?i) 的使用
* 需求:大小写敏感匹配练习
*/
public class Demo12Regexp {
public static void main(String[] args) {
String content = "1.abc,2.abC,3.aBc,4.aB C,5.Abc,6.AbC,7.ABc,8.ABC";
int number = 0;
//1.创建正则表达式
//2.创建模式对象 (正则表达式对象)
//方式一:使用编译标志
//String regStr = "..(?i)abc";//abc大小写都不敏感 => 找到12345678
//String regStr = "..a(?i)bc";//bc大小写都不敏感 => 找到1234
String regStr = "..a((?i)b)c";//abc大小写都不敏感 => 找到13
Pattern pattern = Pattern.compile(regStr);
//方式二:使用嵌入式表达式
//String regStr = "..abc";//abc大小写都不敏感 => 找到12345678
//Pattern pattern = Pattern.compile(regStr,Pattern.CASE_INSENSITIVE);//abc大小写都不敏感 => 找到12345678
//3.创建匹配器
//说明:按照正则表达式的规则去匹配content字符串
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
/*
【Pattern.CASE_INSENSITIVE (?i) 的使用】 找到1: 1.abc
【Pattern.CASE_INSENSITIVE (?i) 的使用】 找到2: 3.aBc
*/
System.out.println("【Pattern.CASE_INSENSITIVE (?i) 的使用】 找到" + (++number) + ": " + matcher.group(0));
}
}
}
5.2 Pattern.COMMENTS 注释模式
案例代码十三 3) Pattern.COMMENTS (?x) 的使用
package com.groupies.base.day20.pattern;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/10
* @introduction 3) Pattern.COMMENTS (?x) 的使用
* 需求:正则表达式中使用注释和空格,并且忽略空格和注释内容
*/
public class Demo13Regexp {
public static void main(String[] args) {
String content = "123456";
int number = 0;
//1.创建正则表达式
//2.创建模式对象 (正则表达式对象)
//方式一:使用编译标志
String regStr = "(?x)1 2 3#456";
Pattern pattern = Pattern.compile(regStr);
//方式二: 使用嵌入式表达式
//String regStr = "1 2 3#456";
//Pattern pattern = Pattern.compile(regStr, Pattern.COMMENTS);
//3.创建匹配器
//说明:按照正则表达式的规则去匹配content字符串
Matcher matcher = pattern.matcher(content);
//4.开始匹配
while (matcher.find()) {
/* 【Pattern.COMMENTS 的使用】 找到1: 123 */
System.out.println("【Pattern.COMMENTS 的使用】 找到" + (++number) + ": " + matcher.group());
}
}
}
5.3 Pattern.MULTILINE 多行匹配模式
案例代码十四 4) Pattern.MULTILINE (?m) 的使用
package com.groupies.base.day20.pattern;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/10
* @introduction 4) Pattern.MULTILINE (?m) 的使用
* 需求:多行字符串中,匹配每一行以123开头的六位字符
*/
public class Demo14Regexp {
public static void main(String[] args) {
String content = "123456\n123890";
int number = 0;
//1.创建正则表达式 (^表示字符串开始位置,即)
String regStr = "^123...";
//String regStr = "(?m)^123..."; //使用嵌入式表达式
//2.创建模式对象 (正则表达式对象)
/*【Pattern.COMMENTS 的使用】 找到1: 123456 */
//Pattern pattern = Pattern.compile(regStr);//没有匹配模式
/*【Pattern.COMMENTS 的使用】 找到1: 123456
【Pattern.COMMENTS 的使用】 找到2: 123890 */
Pattern pattern = Pattern.compile(regStr,Pattern.MULTILINE);
//方式二: 使用嵌入式表达式
//String regStr = "1 2 3#456";
//Pattern pattern = Pattern.compile(regStr);
//3.创建匹配器
//说明:按照正则表达式的规则去匹配content字符串
Matcher matcher = pattern.matcher(content);
Pattern.compile("(\\d)(\\d)\\2{2}\\1").matcher(content).replaceAll("$1");
//4.开始匹配
while (matcher.find()) {
System.out.println("【Pattern.MULTILINE (?m) 的使用】 找到" + (++number) + ": " + matcher.group());
}
}
}
6.Matcher匹配器
Matcher匹配器: Matcher对象是对输入字符串进行解释和匹配的引擎。与 Pattern 类一样,Matcher 也没有共欧诺个构造方法。需要调用 Pattern 对象的 matcher 方法来获得一个Matcher对象
Matcher常用方法:
| id | return | Method and Description | Note |
|---|---|---|---|
| 1 | boolean | find() 尝试找到匹配模式的输入序列的下一个子序列。 |
while循环调用,配合group方法,获取匹配到的子串 参考:案例4.2 分组捕获 - 与内部反向引用 |
| 2 | boolean | find(int start) 重新设置该匹配器,然后尝试从指定的索引开始找到匹配模式的输入序列的下一个子序列。 |
没有测试案例 |
| 3 | String | group() 返回与上一个匹配匹配的输入子序列。 |
不输入数字时默认按照group(0)处理,返回整个子串 |
| 4 | String | group(int group) 返回在上一次匹配操作期间由给定组捕获的输入子序列。 |
int=0时返回整个子串,int<>0时,按照指定分组返回。 指定分组>分组数时会报错。 参考:案例4.2 分组捕获-内部反向引用 |
| 5 | boolean | matches() 尝试将整个区域与模式进行匹配。 |
参考:案例8.4 域名解析 |
| 6 | String | replaceAll(String replacement) 将与模式匹配的输入序列的每个子序列替换为给定的替换字符串。 |
参考:案例4.3 分组捕获-外部反向引用 |
7.PatternSyntaxException异常类
PatternSyntaxException异常类: 是一个非强制异常类,他表示一个正则表达式模式中的语法错误,可以借助这个异常类来帮助定位异常位置和错误信息。
PatternSyntaxException常用方法:
| id | return | Method and Description | DemoPatternSyntaxException测试案例 |
|---|---|---|---|
| 1 | String | getDescription() 检索错误的描述。 |
Unclosed group 未闭合的组 |
| 2 | int | getIndex() 检索错误索引位置。 |
1 这里指正则表达式REGEX中的"("的索引值 |
| 3 | String | getMessage() 返回一个多行字符串,其中包含语法错误及其索引的描述,错误的正则表达式模式以及模式中错误索引的可视指示。 |
Unclosed group near index 1 ( 和getDescription描述的类似 |
| 4 | String | getPattern() 检索错误的正则表达式模式。 |
( 返回整个正则表达式 |
大部分情况下,错误的正则表达式是不能通过编译的,且不能执行
但也有个别漏网之鱼,可以通过编译,但执行时会解析错误,这时候就可以通过异常类来协助定位异常发生位置
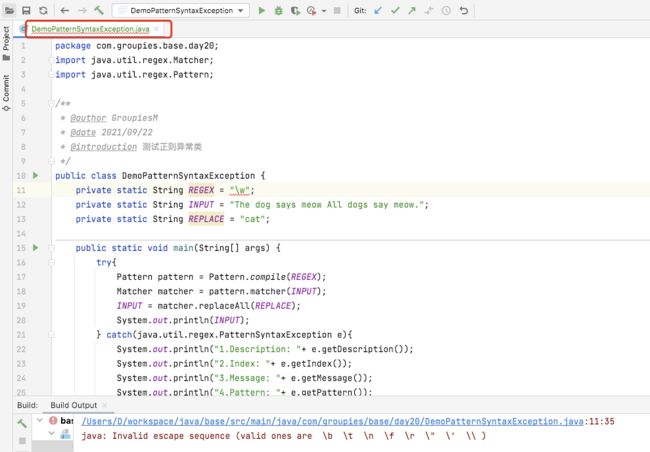
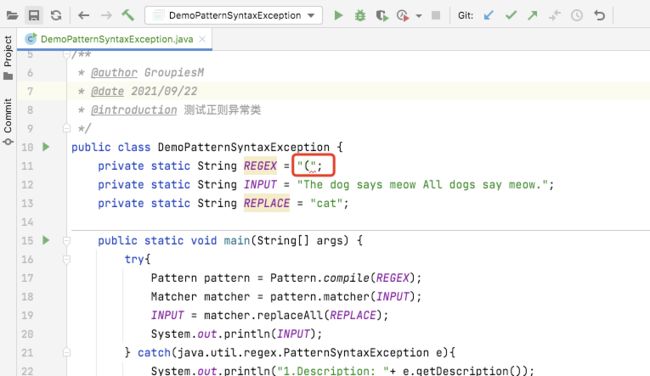
测试代码:
public class DemoPatternSyntaxException {
private static String REGEX = "(";
private static String INPUT = "The dog says meow All dogs say meow.";
private static String REPLACE = "cat";
public static void main(String[] args) {
try{
Pattern pattern = Pattern.compile(REGEX);
Matcher matcher = pattern.matcher(INPUT);
INPUT = matcher.replaceAll(REPLACE);
System.out.println(INPUT);
} catch(java.util.regex.PatternSyntaxException e){
System.out.println("1.Description: "+ e.getDescription());
System.out.println("2.Index: "+ e.getIndex());
System.out.println("3.Message: "+ e.getMessage());
System.out.println("4.Pattern: "+ e.getPattern());
}
}
}
执行结果:
1.Description: Unclosed group
2.Index: 1
3.Message: Unclosed group near index 1
(
4.Pattern: (
8.正则表达式 - 应用案例
8.1 String.split()使用正则分割
a.需求: 分割字符串,分割后内容只有英文字母和数字,其它字符都作为分隔符号处理
b. 待处理文本
aa-bb#34_35~4
案例代码十五 String.split()使用正则分割
/**
* @author GroupiesM
* @date 2021/09/18
* @introduction 8.1 String.split()使用正则分割
* 需求:分割字符串,除了字母和数字都是分割符号
*/
public class Demo15Regexp {
public static void main(String[] args) {
String content = "aa-bb#34_35~4";
String[] split = content.split("[^\\w]|_");
for (String s : split) {
//aa、bb、34、35、4
System.out.print(s+"、");
}
}
}
8.2 String.matches()使用正则校验
a.需求: 校验字符串内容是否全部是 a-zA-Z0-9_
b. 待处理文本
String content1 = "abc123-";
String content2 = "abc123_";
c. string.matches()与matcher.find()的区别
string.matches()会用正则匹配整个字符串,如果完全符合则返回true,不符合返回false
matcher.find()会找到每一个符合要求的子串,并获取符合要求的每个部分
案例代码十六 String.split()使用正则分割
/**
* @author GroupiesM
* @date 2021/09/18
* @introduction 8.2 String.matches()使用正则校验
* 需求:校验字符串内容是否全部是 a-zA-Z0-9_
*/
public class Demo16Regexp {
public static void main(String[] args) {
String content1 = "abc123-";
String content2 = "abc123_";
boolean matches1 = content1.matches("\\w+");
boolean matches2 = content2.matches("\\w+");
System.out.println("matches1: " + matches1);//false
System.out.println("matches2: " + matches2);//true
}
}
8.3 邮箱校验
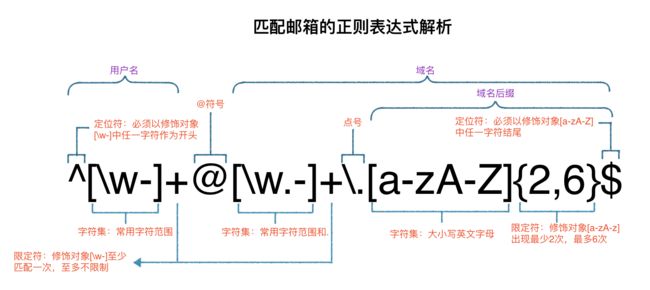
a.需求: 邮箱校验,要求符合以下规则
1. 用户输入邮箱,后台校验输入邮箱是否符合规则
2. 常用字符范围定义: a-z A-Z 0-9 _ -
3. 只有一个@,@前面是用户名,@后面是域名
4. 用户名属于【常用字符范围】
5. 域名可以出现【常用字符】和"."
6. 域名的后缀只能是a-zA-Z,字符长度不少于2个,不多于6个
b.正则表达式
^[\w-]+@[\w.-]+\.[a-zA-Z]{2,6}$
c. 测试结果
"groupiesM@163.comcom";//true
"12345678M@vip.qq.com";//true
" 57139213@qq.com";//false 邮箱开头有空格
"email#123@163.com";//false @前面用户名部分包含常用符号以外的字符 #
"groupiesM@vip.hotmailcom";//false 后缀最后一个.后面长度9 超出范围{2,6}
d. 正则表达式解析
案例代码十七 邮箱校验
package com.groupies.base.day20;
/**
* @author GroupiesM
* @date 2021/09/18
* @introduction 8.3 邮箱校验
*/
public class Demo17Regexp {
//邮箱校验规则
static String emailRegex = "^[\\w-]+@[\\w.-]+\\.[a-zA-Z]{2,6}$";
public static void main(String[] args) {
String email1 = "groupiesM@163.comcom";//true
String email2 = "12345678M@vip.qq.com";//true
String email3 = " 57139213@qq.com";//false 邮箱开头有空格
String email4 = "email#123@163.com";//false @前面用户名部分有非常用符号 #
String email5 = "groupiesM@1.6.3.comcomcom";//false 后缀最后一个.后面长度9 超出范围{2,6}
boolean matches1 = email1.matches(emailRegex);
boolean matches2 = email2.matches(emailRegex);
boolean matches3 = email3.matches(emailRegex);
boolean matches4 = email4.matches(emailRegex);
boolean matches5 = email5.matches(emailRegex);
System.out.println("matches1:" + matches1);
System.out.println("matches2:" + matches2);
System.out.println("matches3:" + matches3);
System.out.println("matches4:" + matches4);
System.out.println("matches5:" + matches5);
}
}
8.4 域名解析
a.需求: 域名解析,要求符合以下规则
1. 解析一个url地址,打印对应的【协议、域名、端口号、文件名】
url:http://www.bilibili.com:8080/java/regex/qwer/index.html
2. 提示:使用分组功能
b.正则表达式
((http|https)://)?([\w-.]+):(\d{1,5})/([\w-/]+)/([\w-.]+)
c. 测试结果
协议:http
域名:www.bilibili.com
端口号:8080
资源路径:java/regex/qwer
文件名:index.html
案例代码十八 域名解析
package com.groupies.base.day20;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/18
* @introduction 8.4 域名解析
*/
public class Demo18Regexp {
//邮箱校验规则
static String emailRegex = "((http|https)://)?([\\w-.]+):(\\d{1,5})/([\\w-/]+)/([\\w-.]+)";
public static void main(String[] args) {
String url = "http://www.bilibili.com:8080/java/regex/qwer/index.html";
Pattern pattern = Pattern.compile(emailRegex);
Matcher matcher = pattern.matcher(url);
//matcher.matchers表示完全匹配
if (matcher.matches()) {
System.out.println("协议:" + (matcher.group(2) == null ? "无" : matcher.group(2)));
System.out.println("域名:" + matcher.group(3));
System.out.println("端口号:" + matcher.group(4));
System.out.println("资源路径:" + matcher.group(5));
System.out.println("文件名:" + matcher.group(6));
} else {
System.out.println("匹配失败");
}
}
}
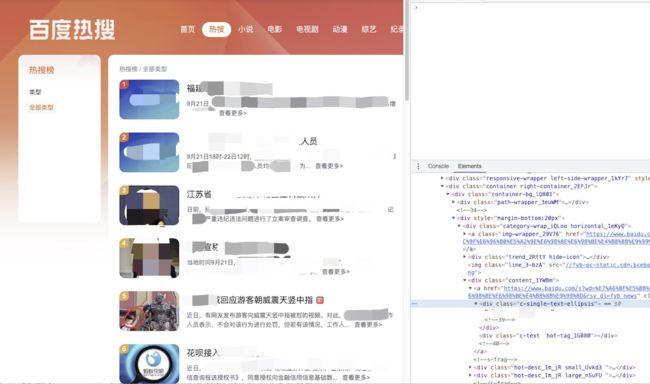
8.5 爬虫百度热搜
a.需求: 使用爬虫爬取百度热搜,要符合以下要求
1. 爬虫实时获取百度热搜标题,描述,链接
2. 热搜地址:https://top.baidu.com/board?tab=realtime
b.正则表达式(页面可能会有改动,现在能执行不代表以后也能执行)
<div class=\"c-single-text-ellipsis\">([\S ]*?)</div>(.*?)
<div class=\"hot-desc_1m_jR(.*?)\">(.*?)<a href=\"([\S ]*?)\"(.*?)
c. 测试结果
热搜截图
找到1:
标题:福建本土*****
描述:9月21日,福建省新增本土*****,其中厦门市****、莆田市**,本土******。
链接:https://www.baidu.com/s?wd=%E7%A6%8F%E5%BB%BA%E6%9C%AC%E5%9C%9F%E6%96%B0%E5%A2%9E%E6%98%8E%E6%98%BE%E4%B8%8B%E9%99%8D&rsv_dl=fyb_news
找到2:
标题:哈尔滨市************
描述:9月21日18时-22日12时,哈尔滨********确*************人员。******人员均在***,为...
链接:https://www.baidu.com/s?wd=%E5%93%88%E5%B0%94%E6%BB%A8%E5%B8%82%E6%96%B0%E5%A2%9E3%E4%BE%8B%E6%A0%B8%E9%85%B8%E5%88%9D%E7%AD%9B%E9%98%B3%E6%80%A7%E4%BA%BA%E5%91%98&rsv_dl=fyb_news
找到3:
标题:江苏省************被双开
描述:日前,经****批准,*******对江苏省****、***原**王**严重****问题进行了*****调查。
链接:https://www.baidu.com/s?wd=%E6%B1%9F%E8%8B%8F%E7%9C%81%E5%A7%94%E6%94%BF%E6%B3%95%E5%A7%94%E5%8E%9F%E4%B9%A6%E8%AE%B0%E7%8E%8B%E7%AB%8B%E7%A7%91%E8%A2%AB%E5%8F%8C%E5%BC%80&rsv_dl=fyb_news
找到4:
标题:**宣称*****
描述:当地时间9月21日,******宣称*********,准备与“********”、反对“******...
链接:https://www.baidu.com/s?wd=%E6%8B%9C%E7%99%BB%E5%AE%A3%E7%A7%B0%E7%BE%8E%E5%9B%BD%E4%B8%8D%E5%AF%BB%E6%B1%82%E6%96%B0%E5%86%B7%E6%88%98&rsv_dl=fyb_news
找到5:
标题:****回应游客朝威震天竖中指
描述:近日,有网友发布游客向威震天竖中指被怼的视频。对此,北京****工作人员表示,不会对该行为进行处罚,但若有该情况,工作人...
链接:https://www.baidu.com/s?wd=%E7%8E%AF%E7%90%83%E5%BD%B1%E5%9F%8E%E5%9B%9E%E5%BA%94%E6%B8%B8%E5%AE%A2%E6%9C%9D%E5%A8%81%E9%9C%87%E5%A4%A9%E7%AB%96%E4%B8%AD%E6%8C%87&rsv_dl=fyb_news
......略
案例代码十九 爬虫百度热搜
package com.groupies.base.day20;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author GroupiesM
* @date 2021/09/22
* @introduction 8.5 爬虫百度热搜
*/
public class Demo19Regexp {
static String regex = "([\\S ]*?)(.*?)" +
"8.6 LeetCode算法5
a.需求: 给你一个字符串 s,找到 s 中最长的回文子串。
示例 1:
输入:s = "babad"
输出:"bab"
解释:"aba" 同样是符合题意的答案。
示例 2:
输入:s = "cbbd"
输出:"bb"
示例 3:
输入:s = "a"
输出:"a"
示例 4:
输入:s = "ac"
输出:"a"
提示:
1 <= s.length <= 1000
s 仅由数字和英文字母(大写和/或小写)组成
b.正则表达式
动态拼接
案例代码二十 最长回文字符串
/**
* @author GroupiesM
* @date 2021/09/29
* @introduction 寻找最大回文字符串
* 需求:
* 找出最长的中心对称的字符串 例如 aba abcba
* 提示:
* 1 <= s.length <= 1000
* s 仅由数字和英文字母(大写和/或小写)组成
*/
public class Demo20Regexp {
public static void main(String[] args) {
int maxLength = 1;
String maxContent = "";
String content = "bbadcadacbkansdbvkajbvkjabavkbakjsvbakbkjbk";
StringBuilder sb1;
StringBuilder sb2;
String sb1str = "";
String sb2str = "";
for (int i = (content.length() / 2) + 1; i > 0; i--) {
sb1 = new StringBuilder();
sb2 = new StringBuilder();
for (int j = i - 1; j > 0; j--) {
sb1str = new String(sb1.append("(.)"));
sb2str = new String(sb2.append("(\\" + j + ")"));
}
String regex = new String(sb1str + "." + sb2str);
//todo delete
System.out.println(regex);
Pattern compile = Pattern.compile(regex);
Matcher matcher = compile.matcher(content);
while (matcher.find() && matcher.group().length() > maxLength) {
maxContent = matcher.group();
maxLength = matcher.group().length();
if (maxLength != 1) break;
}
regex = new String(sb1str + sb2str);
//todo delete
System.out.println(regex);
compile = Pattern.compile(regex);
matcher = compile.matcher(content);
while (matcher.find() && matcher.group().length() > maxLength) {
maxContent = matcher.group();
maxLength = matcher.group().length();
if (maxLength != 1) break;
}
}
if (maxLength == 1) {
System.out.println("最长回文长度:" + maxLength);
System.out.println("最长回文内容:" + content.substring(0, 1));
} else {
System.out.println("最长回文长度:" + maxLength);
System.out.println("最长回文内容:" + maxContent);
}
}
}
9.正则表达式 - 常用功能
以下内容均未经测试,后面有用到的会将验证过的记录下来 => java常用正则表达式
9.1 解析hive建表语句
- 测试数据
`appeal_attachment` string COMMENT '申诉审核的材料',
`appeal_batch_id` string COMMENT '申诉批次id',
`appeal_bill_type` bigint COMMENT '申诉单类型 0洗客 1撞客',
`appeal_end_time` decimal(38,5) COMMENT '申诉单关闭时间,申诉审核完成时更新',
`appeal_search_code` bigint COMMENT '0双端都显示 1pc搜索 2H5搜索',
`appeal_user_role` bigint COMMENT '0申诉人 1申请人 2报备人',
`clue_channel_id` string COMMENT '一级渠道编码',
`clue_sub_channel_id` string COMMENT '二级渠道编码',
`parent_id` bigint COMMENT '撞客申诉主单的id',
`related_info` string COMMENT '关联的线索等信息'
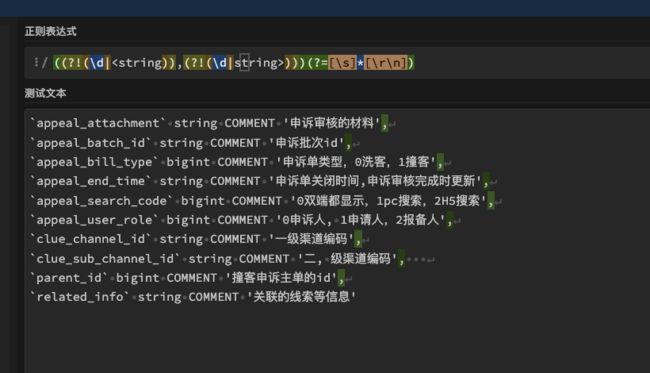
正则1 :拆分字段
//按照逗号分隔,但是要排除 decimal(xx,xx) 和 map(string,string)这种情况出现的逗号
//反向否定零宽断言,逗号前面不能是a-zA-Z0-9_
//正向否定零宽断言,逗号后面不能是a-zA-Z0-9_
//正向肯定零宽断言,逗号后面去掉空白字符后,必须以\r或\n结尾
((?!(\d|<string)),(?!(\d|string>)))(?=\s*[\r\n])
正则2 :分组捕获
- 正则
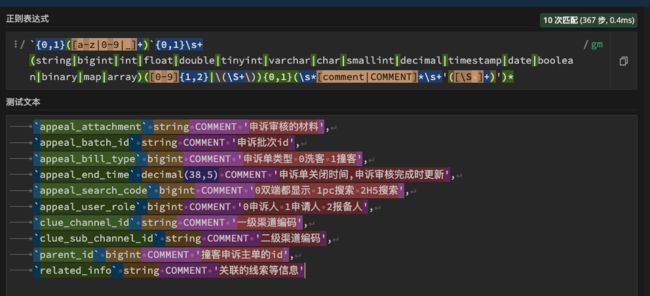
`{0,1}([a-z|0-9|_]+)`{0,1}\s+(string|bigint|int|float|double|tinyint|varchar|char|smallint|decimal|timestamp|date|boolean|binary|map|array)([0-9]{1,2}|\(\S+\)){0,1}(\s*[comment|COMMENT]*\s+'([\S ]+)')*
- 测试结果
这个正则太复杂了,写完以后自己也看不懂,想研究的自己看吧
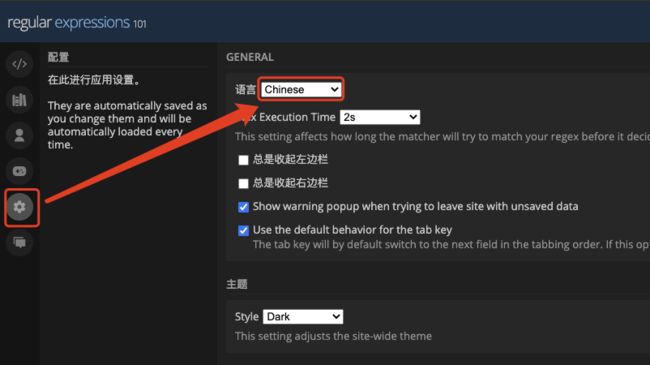
附录 在线工具设置
正则表达式 - 在线工具 默认为英文,点击⚙️ 修改为中文
21/09/22
M