(UE4 4.27) UHierarchicalInstancedStaticMesh(HISM)原理分析
前言
游戏开发中的植被管理一直是个棘手的问题,因为植被数量庞大,对于剔除(CPU)和渲染(GPU)都存在很大的压力。

是 UE4的植被有一套独特的管理方式, 是基于 UHierarchicalInstancedStaticMeshComponent组件实现了植被的视椎体剔除和合批渲染。
UHierarchicalInstancedStaticMeshComponent原理分析
HISM类关系
UFoliageInstancedStaticMeshComponent下面简称FSM.
UHierarchicalInstancedStaticMeshComponent下面简称HISM.
InstancedStaticMeshComponent下面简称ISM.
在UE4里FSM,HISM,ISM是UE4最常用的对网格Instance合批渲染组件.
这三个组件的关系类图如下所示

FSM在UE4进行植被编辑模式的时候产生(挂载在AFoliageActor上).而HISM得手动进行AddInstance的合批, 由于FSM的CPU剔除和GPU合批方式基本沿用HISM,而ISM是最基本的粗暴合批,没有精妙的CPU剔除, 所以本文重点分析HISM。
CPU剔除实例
HISM管理着同一个StaticMesh的大量实例, 假设实例数量高达1万个,当然在提交drawcall前并非每个Instance都得被渲染,所以得进行视锥体剔除,按照传统的CPU方式,暴力进行对每一个实例视锥体剔除,CPU压力很大。

暴力遍历Instance进行视锥体求交对CPU性能压力很大,往往是瓶颈的所在,因此场景管理上出现了各种空间管理结构,加速CPU的实例剔除。 典型的有BSP(二叉空间树),Octree(八叉树), QuadTree(四叉树)等等。UE4的HISM针对大量Instance也有独特的空间管结构,我称其为基于Cluster的N叉树。空间结构和KD树有些类似(Build),剔除(Cull)的过程则和二叉,四叉树等类似,都是从大空间开始剔除,依次递归往子空间进行剔除,最终得到和视锥体相交的所有Instance.
HISM的空间结构和构建过程
上面我简称HISM的空间结构为N叉树,是因为这个N是可控的,随着某些因素的影响变化(比如StaticMesh的顶点数量,叶子节点最大顶点数量等等)
HISM的N叉树原理
首先说下HISM的N叉树的数据结构是用索引数组而非链表构成的。
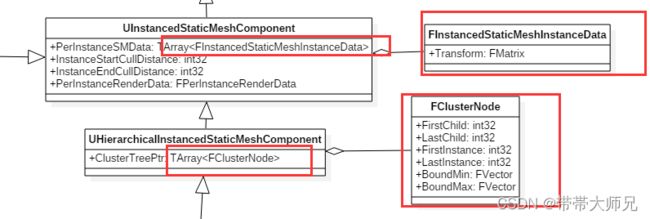
首先TArray
TArray
FClusterNode的FirstChild指当前节点在数组ClusterTree的第一个子节点的索引,而LastChild代表当前节点在数组ClusterTree的最后一个子节点的索引,也就是说当前节点存在
(LastChild - FirstChild + 1)子节点,而当前节点的BoundMax, BoundMin指的是当前节点包含的所有实例在世界空间形成的BoundBox,而当前节点的FirstInstance和LastInstance指当前节点包含所有实例的第一个Instance在PerInstanceSMData的索引,而LastInstance指的是所有实例的最后一个Instance在PerInstanceSMData的索引,也就是说当前节点拥有实例数量等于(LastInstance - FirstInstance + 1). 当前节点和子节点各种变量的关系如图下所示:
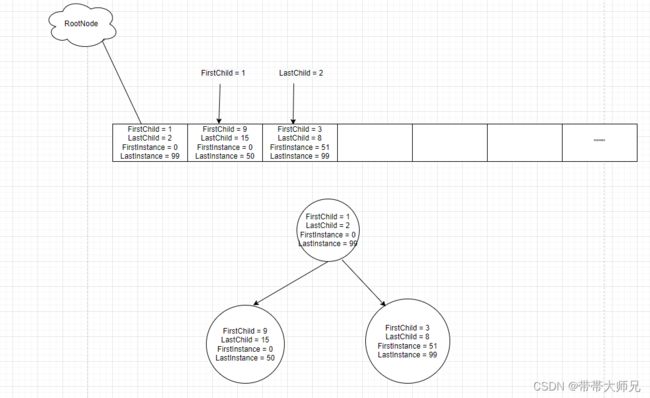
可以这样说, 当前节点的所有子节点所有的Instance加起来就等于当前节点所拥有的Instance, 当前节点所有Instance形成的BoundBox和其所有子节点的Instance形成的BoundBox涵盖的范围总和是一样的。说到这里,熟悉空间剔除结构的人看到这里大体应该明白了HISM N叉树的基本原理,也就是大空间包含数个小空间,大空间的BoundBox如果与视锥体相交, 那遍历其所有子空间的BoundBox和视锥体求交,反之大空间不与视锥体相交,则其所有子空间都不可能与视锥体相交,整个过程都在递归进行。可以大致参考下地形渲染之四叉树(QuadTree) 来理解。
唯一的问题在于HISM的N叉树具体是怎么构建的,我简单总结,HISM的N叉树结构和构建过程和KD树有些类似

HISM的N叉树构建
第一步----构建叶子节点: 首先生成N叉树的所有叶子节点,覆盖了所有Instance的Index范围, 并且每个节点的Index范围不重叠。
比如我们存在90个实例,并假设一个FClusterNode叶子最多容纳20个实例, 则生成5个叶子节点:
[0, 19], [20, 39], [40, 59], [60, 79],[80, 90], 当然实际上不会分得那么均匀.
这个生成叶子节点的过程是怎么发生的:
假设我们有M个实例:
(1)将所有Instance的Transform组成一个数组为TArray
(2)对[0, M-1] 口模型划分数量划分

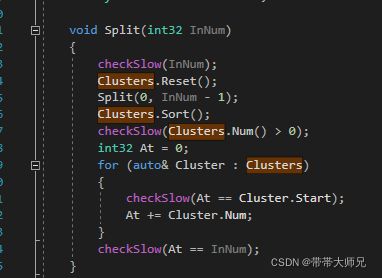

如果当前范围实例总数量小于等于BranchingFactor,则递归结束, 形成一个叶子节点
BranchingFactor = clamp(叶子节点可以容纳最大顶点数量 / 实例StaticMesh 0级Lod的顶点数量, 1, 1024)

可以看出叶子节点可以容纳最大顶点数量的是个可控的量
如果当前范围实例总数量大于BranchingFactor ,对所有实例形成的BoundBox的最长轴(X或者Y或者Z)代表的Position分量进行距离排序,如下面X轴就是最长轴

然后对排序后进行数量上二分切分(类似二分查找),回到第二步的初始一直递归下去.
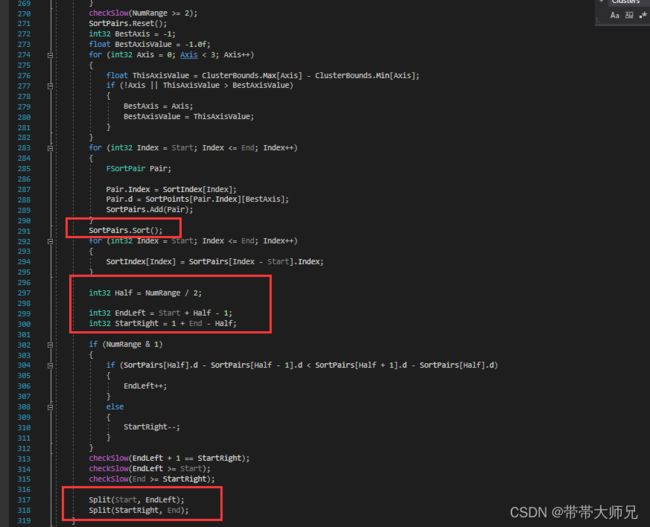

最后所有递归结束,形成 Q个叶子节点FClusterNode, 这Q个叶子节点各自代表的InstanceIndex范围不存在重叠,并且总和数量刚好 = 总实例数量M
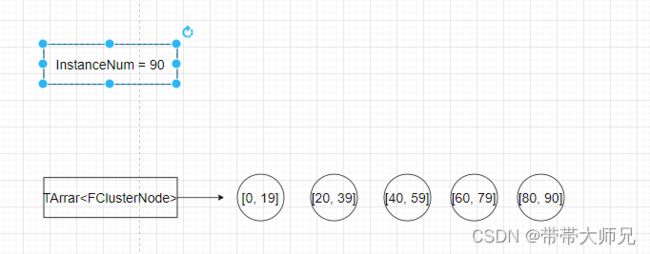

当然递归二分法下得到的InstanceIndex的分布范围不会这么均匀, 我这里只是一个假设的例子
第二步----由叶子节点从下往上构建上层树节点直到根节点为止
第一步我们得到包含了全InstanceIndex范围的一些ClusterNode节点(看上面图所示), 下面我们进一步把这些ClusterNode都分为视为一个位置点, 位置点为一个ClusterNode内所有实例形成的BoundBox的中心点. 所以上面90个实例下得到5个Cluster, 就是5个位置点,一个位置点有些类似一个Instance实例

然后利用这些位置点类似上面的第一步那样进行二分递归划分,一直往上得到根节点,当然这里和第一步不太一样的是,节点自下往上过程得把子节点FCsluterNode的InstanceIndex范围归纳到母FClusterNode里,并且这里二分递归的终结递归因子和第一步形成叶子节点的终结递归因子不一样。这里的BranchingFactor 变为CVarFoliageSplitFactor,也是可控变量,默认情况是16,也就是每16个FClusterNode子节点才能形成一个母节点FClusterNode。



经过上面的步骤最终形成空间结构N叉树

HISM的Runtime剔除和渲染过程
上面我们分析了在编辑器下HISM针对Instance的空间数据结构N叉树的构建过程。下面就是利用这个N叉树进行剔除的过程。首先从上面的N叉树构建过程,我们可以知道TArray
母节点的InstanceIndex范围 = 所有子节点InstnceIndex范围总和
母节点的Instance构成的BoundBox = 所有子节点Instnce构成的BoundBox总和
因此整个剔除的过程是从根节点开始,自上而下进行剔除,遵循大空间BoungBox和视锥体相交, 则其子空间BoungBox也可能与视锥体相交, 反之大空间BoungBox和视锥体不相交,则子空间BoungBox绝对不可能与视锥体相交。和四叉树等等的剔除原理基本相似。
这个剔除过程发生在 FHierarchicalStaticMeshSceneProxy::GetDynamicMeshElements 提交MeshBatch之前
![]()
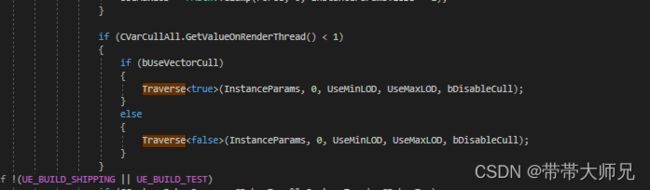

这里有个小细节的是剔除用视锥体是根据你在编辑器设置的CullDistance(UserData_AllInstances.EndCullDistance)计算出来,如下所示:

最终能渲染的ClusterNode的InstanceIndex的列表加入到一个分LOD管理的可渲染列表里


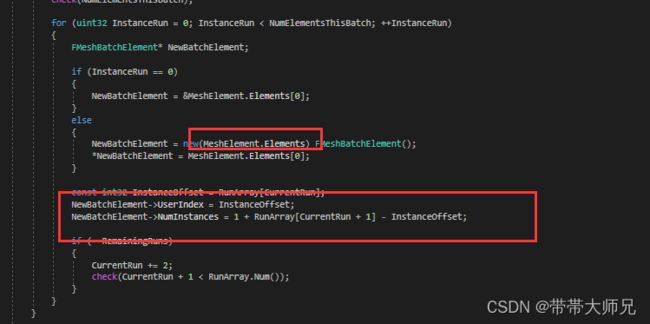
这里连续Index的Cluster节点会在AddRun后进行合并,比如[0, 31], [32, 50]合并成[0, 50]

最后遍历可渲染列表的InstanceIndex分段,比如[0, 19] [30, 59]等等,来进行提交MeshBatch


这里的NumBatchs一般是1,而InstanceIndex分段数量意味着MeshBatch的Elements的数量,一个MeshBatchElement就是一次DrawIndexedInstance, 上面所说的N叉树的每个Cluster叶子节点代表可能存在的一次DrawIndexedInstance.

HISM的优缺点
优点
以Cluster为单位(每个Cluster存储的Instance数量可控),在CPU进行空间N叉树的剔除,总体上效率还可以。
缺点
因为是以Cluster为单位来剔除,假设一个簇刚还只有一个Instance在视锥体内,则造成Cluster其他Instance的绘制浪费,cluster粒度(包含Instanc总数)越大,绘制浪费越大。如果Cluster粒度小,绘制浪费比较小, 但是可能造成Cluster总数量提高,潜在的DrawCall(DrawIndexedInstance)数量也会提高。
参考资料
[1] HierarchicalInstancedStaticMeshComponent.h 和 HierarchicalInstancedStaticMesh.cpp