时间序列预测系列文章总结(代码使用方法)
前言
本科阶段的研究方向是电力负荷预测,期间也发过一篇《中国电机工程学报》的论文,不过随着本科毕业,时序预测也该告一段落了,之后重心便放在研究生期间的社交网络挖掘方向了。
前面已经写过不少时间序列预测的文章:
- 深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)
- PyTorch搭建LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)
- PyTorch搭建双向LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- PyTorch搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- PyTorch中实现LSTM多步长时间序列预测的几种方法总结(负荷预测)
- PyTorch-LSTM时间序列预测中如何预测真正的未来值
- PyTorch搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- PyTorch搭建ANN实现时间序列预测(风速预测)
- PyTorch搭建CNN实现时间序列预测(风速预测)
- PyTorch搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
- PyTorch搭建Transformer实现多变量多步长时间序列预测(负荷预测)
这篇文章是对这16篇文章的总结,顺便也谈一谈代码如何使用。
1. 深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)
这篇文章主要讲PyTorch中LSTM的输入和输出,具体讲了数据流动过程中的维度变化,是所有文章的基础,必须要理解。这篇文章不涉及代码使用。
2. PyTorch搭建LSTM实现时间序列预测(负荷预测)
这篇文章是单变量单步预测的示例,即利用前24小时的负荷预测下一时刻的负荷值。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的LSTM-Load-Forecasting项目,如下所示:
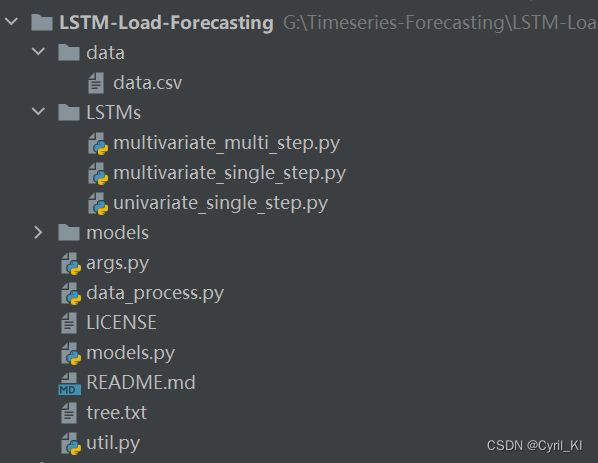
然后打开并运行LSTMs文件夹下的univariate_single_step.py文件,如果需要更换预测长度,比如前12小时预测下一小时,只需将args.py中us_args_parser()函数中的参数seq_len改为12,即:

如果需要使用自己的数据,只需要将data文件夹下的data.csv替换为自己的csv文件,然后再对data_process.py中的nn_seq_us进行更改:

如果需要预测的变量为第s列,那么只需将图中的1改为s即可。
3. PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)
这篇文章是多变量单步预测的示例,即利用前24小时的负荷+环境因素预测下一时刻的负荷值。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的LSTM-Load-Forecasting项目,然后打开并运行LSTMs文件夹下的multivariate_single_step.py文件。如果需要使用自己的数据,首先需要将data.csv进行替换,其次,对data_process.py中的nn_seq_ms进行更改:
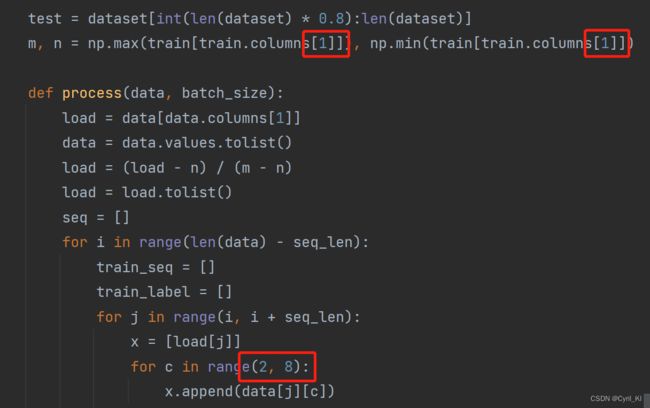
具体来讲,首先需要将1替换为想要预测的变量的列索引,然后将2, 8替换为环境变量的列索引。
4. PyTorch搭建双向LSTM实现时间序列预测(负荷预测)
这篇文章是双向LSTM预测的示例,即将23节中的单向LSTM替换为双向LSTM。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的LSTM-Load-Forecasting项目,然后将args.py中三个args_parser()函数中的bidirectional参数改为True即可:
![]()
5. PyTorch搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
这篇文章是多变量多步长预测的第一篇:直接多输出。我们利用前24小时的负荷+环境因素预测接下来多个小时的负荷值。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的LSTM-MultiStep-Forecasting项目,如下所示:

然后打开并运行algorithms文件夹下的multiple_outputs.py文件即可。
如果需要调整预测长度,比如利用前24小时预测接下来12个小时,只需将args.py中mo_args_parser()函数中的output_size参数改为12即可。
如果需要使用自己的数据,首先需要将data文件夹下的data.csv替换为自己的csv文件,然后更改data_process.py中的nn_seq_mo()函数,更改方式和前面一样。
6. PyTorch搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
这篇文章是多变量多步长预测的第二篇:单步滚动预测。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的LSTM-MultiStep-Forecasting项目,然后打开并运行algorithms文件夹下的single_step_scrolling.py文件即可。
如果需要使用自己的数据,首先需要将data文件夹下的data.csv替换为自己的csv文件,然后更改data_process.py中的nn_seq_sss()函数,更改方式和前面一样。
7. PyTorch搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
这篇文章是多变量多步长预测的第三篇:多模型单步预测。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的LSTM-MultiStep-Forecasting项目,然后打开并运行algorithms文件夹下的multi_model_single_step.py文件即可。
如果需要使用自己的数据,首先需要将data文件夹下的data.csv替换为自己的csv文件,然后更改data_process.py中的nn_seq_mmss()函数,更改方式和前面一样。
8. PyTorch搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
这篇文章是多变量多步长预测的第四篇:多模型滚动预测。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的LSTM-MultiStep-Forecasting项目,然后打开并运行algorithms文件夹下的multi_model_scrolling.py文件即可。
如果需要使用自己的数据,首先需要将data文件夹下的data.csv替换为自己的csv文件,然后更改data_process.py中的nn_seq_mmss()函数,更改方式和前面一样。
9. PyTorch搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
这篇文章是多变量多步长预测的第五篇:seq2seq预测。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的LSTM-MultiStep-Forecasting项目,然后打开并运行algorithms文件夹下的seq2seq.py文件即可。
如果需要使用自己的数据,首先需要将data文件夹下的data.csv替换为自己的csv文件,然后更改data_process.py中的nn_seq_mos()函数,更改方式和前面一样。
10. PyTorch中实现LSTM多步长时间序列预测的几种方法总结(负荷预测)
总结文章,不涉及代码使用,没啥可说的。
11. PyTorch-LSTM时间序列预测中如何预测真正的未来值
这部分讲怎么利用现有的模型预测未来不存在的值,这篇文章中给出了一个大致的模型框架,如果需要针对自己的情况进行预测,可以加我微信进行询问。
12. PyTorch搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
这篇文章是时间序列预测多任务学习的示例,即一次性输出多个变量,例如利用前24小时的负荷+温度预测接下来12个小时的负荷+温度。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的LSTM-MultiStep-Forecasting项目,然后打开并运行algorithms文件夹下的multi_task_learning.py文件即可。
如果需要使用自己的数据,首先需要将data文件夹下的mtl_data_1.csv或者mtl_data_2.csv替换为自己的csv文件,然后更改data_process.py中的nn_seq_mtl()函数。同时,args.py中的multi_task_args_parser()函数也需要进行更改:
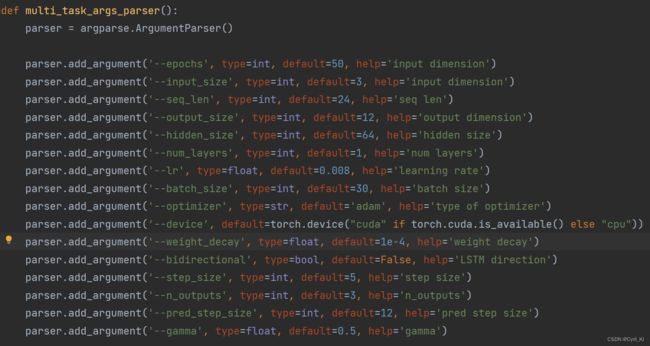
其中output_size表示预测长度,即预测接下来12个小时的多个变量值;n_outputs表示需要预测的变量个数,比如本篇文章中需要预测三个变量。
13. PyTorch搭建ANN实现时间序列预测(风速预测)
这篇文章是ANN时间序列预测示例。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的ANN-Speed-Forecasting项目,如下所示:
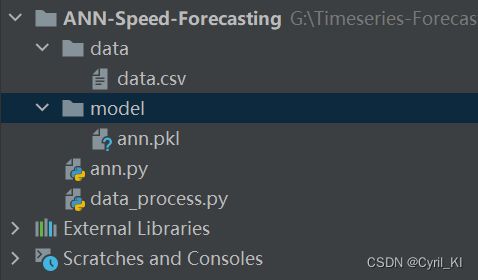
然后打开并运行ann.py文件即可。
如果需要使用自己的数据集,只需将data文件夹下的data.csv替换为自己的csv文件,然后更改data_process.py的相关方法。
14. PyTorch搭建CNN实现时间序列预测(风速预测)
这篇文章是ANN时间序列预测的示例。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的CNN-Speed-Forecasting项目,如下所示:

然后打开并运行cnn.py文件即可。
如果需要使用自己的数据集,只需将data文件夹下的data.csv替换为自己的csv文件,然后更改data_process.py的相关方法。
15. PyTorch搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
这篇文章是CNN-LSTM混合模型时间序列预测的示例。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的CNN-Speed-Forecasting项目,如下所示:
然后打开并运行main.py文件即可。
如果需要使用自己的数据集,只需将data文件夹下的data.csv替换为自己的csv文件,然后更改get_data.py的相关方法,更改方法同前面多变量多步长预测。
16. PyTorch搭建Transformer实现多变量多步长时间序列预测(负荷预测)
这篇文章是Transformer时间序列预测的示例。
具体使用方法:利用pycharm或者其他IDE打开压缩包中的Transformer-Timeseries-Forecasting项目,如下所示:
然后打开并运行main.py文件即可。
如果需要使用自己的数据集,只需将data文件夹下的data.csv替换为自己的csv文件,然后更改get_data.py的相关方法,更改方法同前面多变量多步长预测。
源码获取
时间序列预测系列文章代码汇总