【pytorch记录】torch.utils.data.Dataset、DataLoader、分布式读取并数据
pytorch提供了一个数据读取的方法,使用了
torch.utils.data.Dataset和torch.utils.data.DataLoader。
要自定义自己数据的方法,就要继承torch.utils.data.Dataset,实现了数据读取以及数据处理方式,并得到相应的数据处理结果。然后将Dataset封装到DataLoader中,可以实现了单/多进程迭代输出数据。
1
torch.utils.data.Dataset
- 要自定义自己的 Dataset 类,需要重载两个方式,【
__len__】、【__getitem__】- 【
__len__】返回数据集的大小- 【
__getitem__】实现索引数据集中的某一个元素from torch.utils.data import DataLoader, Dataset import torch class MyDataset(Dataset): # TensorDataset继承Dataset, 重载了__init__, __getitem__, __len__ # 能够通过index得到数据集的数据,能够通过len得到数据集大小 def __init__(self, data_tensor, target_tensor): self.data_tensor = data_tensor self.target_tensor = target_tensor def __getitem__(self, index): return self.data_tensor[index], self.target_tensor[index] def __len__(self): return self.data_tensor.size(0) # 生成数据 data_T = torch.randn(4, 3) label_T = torch.rand(4) tensor_dataset = MyDataset(data_T, label_T) # 将数据封装成Dataset print('tensor_data[0]: ', tensor_dataset[0]) print('len(tensor_data): ', len(tensor_dataset))
2
torch.utils.data.DataLoader
- 本质是一个可迭代对象(与python 的内置类型 list 等一样),使用 iter() 访问,不能使用 next()访问
- 使用 iter(dataloader)返回的是一个迭代器,可以使用 next 访问
- 也可以使用
for inputs, labels in dataloaders进行可迭代对象的访问- 实现多进程、shuffle、不同采样策略,数据校对等等处理过程;然后内部使用 yeild 返回每一次的batch 的数据
tensor_dataloader = DataLoader(tensor_dataset, # 封装的对象 batch_size=2, # 输出的batchsize shuffle=True, # 随机输出 num_workers=0) # 只有1个进程 # 以for循环形式输出 for data, target in tensor_dataloader: print(data, target) print('one batch tensor data: ', iter(tensor_dataloader).next()) # 输出一个batch print('len of batchtensor: ', len(list(iter(tensor_dataloader)))) # 输出batch数量
这里介绍下 DataLoader 的入参
from torch.utils.data import DataLoader DataLoader( dataset, batch_size, shuffle=False, #在每个 epoch 开始时,是否对数据进行打乱 sampler=None, #自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False batch_sample=None, #与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是, #一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了 num_workers=0, #使用几个进程来获取并处理数据 collate_fn=None, #将一个list的sample组成一个mini-batch的函数 pin_memory=False, #如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存中。 # pin_memory可在cpu主存(内存)中分配不可交换到swap(缓存)的内存。 # 默认内存分配中的数据都可交换到swap中,那CUDA驱动会通过DRAM机制将数据从内存传到GPU显存时会复制2次 # (先复制到一临时不可见pinned固定内存,再往显存中复制), # 因此pin_memory=True可提高约2倍cpu到gpu传输效率(.cuda()或 .to(device)的时候) drop_last=False, #为True:一个 epoch 的最后一组数据#为False:继续正常执行,只是最后的batch_size会小一点。 timeout=0, #如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到, #那就不收集这个内容了。这个数值应总是大于等于0。默认为 worker_init_fn=None #每个worker初始化函数 。一般并不进行设置 )

3 数据读取处理示例(单卡/分布式)
网络训练起来,根据硬件的情况,可以设置为单卡训练、分布式训练。分布式训练时,数据就要分布式的读取派发数据。此时会需要用到常用的 API:
torch.utils.data.DataLoadersampler=torch.utils.data.distributed.DistributedSampler:数据被平分到多块gpu上,每个epoch被分配到每块卡上的数据都一样。gpu的个数是由运行代码时,python -m torch.distributed.launch --nproc_per_node=2决定的。torch.utils.data.sampler.BatchSampler:它其实是将sampler作为参数进行打包,进而每次迭代返回以batch size为大小的index列表。
下面举例进行比较pytorch数据读取时的各种设置:假设使用一个主机里面的两张显卡来测试。
import os import torch import torch.nn as nn import torch.distributed as dist from torch.utils.data import Dataset, DataLoader import numpy as np class DataTest(Dataset): def __init__(self, n=8): self.n = n def __len__(self): return self.n def __getitem__(self, item): np_img = np.random.rand(3,256,256) image = torch.from_numpy(np_img).float() label = np.random.randint(0,9) return image, label, item local_rank = int(os.environ['LOCAL_RANK']) world_size = int(os.environ['WORLD_SIZE']) rank = int(os.environ['RANK']) dist.init_process_group('nccl',world_size=world_size, rank=rank) torch.cuda.set_device(local_rank) def do_test(data_num=9, batch_size=4, sampler=None, drop_last=True, shuffle=False): ds = DataTest(data_num) Sampler = torch.utils.data.distributed.DistributedSampler(ds) if sampler ==True else None dataloader = DataLoader(ds, batch_size=batch_size, sampler=Sampler, drop_last=drop_last) for epoch in range(2): Sampler.set_epoch(epoch) if sampler==True and shuffle==True else None print("=====================") for index,(_,labels, items) in enumerate(dataloader): print(items.cuda()) dist.barrier() def do_test_batchsampler(data_num=9, batch_size=4, drop_last=True, shuffle=False): ds = DataTest(data_num) Sampler = torch.utils.data.distributed.DistributedSampler(ds) batchsampler = torch.utils.data.sampler.BatchSampler(Sampler, batch_size, drop_last=drop_last) dataloader = DataLoader(ds, batch_sampler = batchsampler) for epoch in range(2): Sampler.set_epoch(epoch) if shuffle==True else None print("=====================") for index,(_,labels, items) in enumerate(dataloader): print(items.cuda()) dist.barrier() # do_test(data_num=8, sampler=False, drop_last=True) # do_test(data_num=8, sampler=True, drop_last=True) # do_test(data_num=8, sampler=True, drop_last=True, shuffle=True) # do_test(data_num=9, sampler=True, drop_last=True) # do_test(data_num=9, sampler=True, drop_last=False) # do_test(data_num=6, sampler=True, drop_last=False) # do_test(data_num=5, sampler=True, drop_last=False) do_test(data_num=6, batch_size=1, sampler=True, drop_last=False) do_test_batchsampler(data_num=8, batch_size=4, drop_last=True, shuffle=True)运行命令:
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 test.py
注意:这里为了方便对比,【 DataLoader(…,num_workers=4, pin_memory=True)】这两个参数没有进行设置。
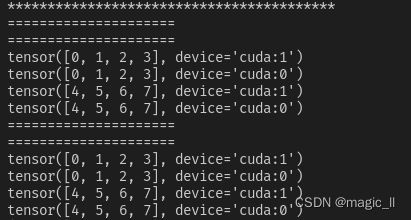
- case1【do_test(data_num=8, sampler=False, drop_last=True)】
没有使用DistributedSampler。这种情况是非分布式训练的通用情况。无论使用单卡或多卡训练,都会在每个卡上的每个epoch中迭代所有数据。两张显卡在一个epoch共跑两边数据集
这里需要注意,如果训练时,此时应同步设置上DataLoader(..., shuffle=True)
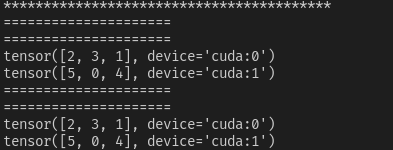
case2【do_test(data_num=8, sampler=True, drop_last=True)】
sampler=True,使用了DistributedSampler,此时必须设置DataLoader(..., shuffle=False),否则会报错。(可以理解为 是否打乱的主动权已经到sampler上,DataLoader以及无权将shuffle设置为True)- 在一个epoch中,数据被平均分到了两张显卡上;并且在多个epoch中,单张显卡所迭代的数据、以及数据顺序都不发生变化。这种情况常用于验证
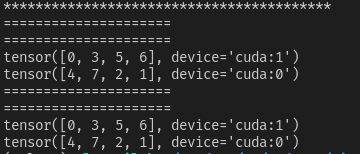
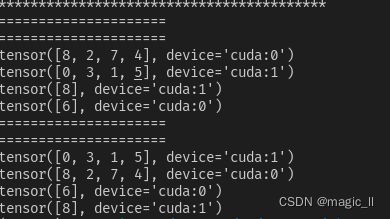
case3【do_test(data_num=8, sampler=True, drop_last=True, shuffle=True)】
当sampler=True, shuffle=True,使用了DistributedSampler、sampler.set_epoch(epoch)。运行得到如下图。可以发现,在多个epoch中,数据集的顺序会先被打乱,然后再平均分配到每张显卡上。这种情况常用于训练
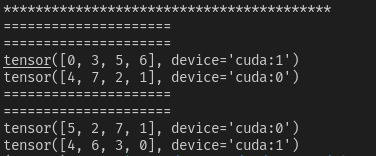
- case4【do_test(do_test(data_num=9, sampler=True, drop_last=True)】
当data_num=9,batch_size=4, drop_last=True时,剩余组不成一个batch的数据会被丢弃
- case5【do_test(do_test(data_num=9, sampler=True, drop_last=False)】
当data_num=9,batch_size=4, drop_last=False时,剩余组不成一个batch的数据会被保留
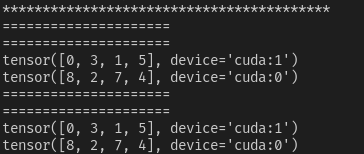
- case6【do_test(data_num=6, sampler=True, drop_last=False)】
当data_num=6, drop_last=False时,总共6个数据,会平均分配到两显卡上
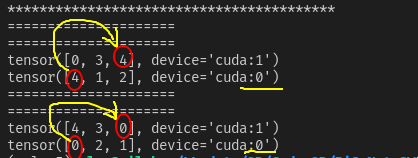
- case7【do_test(data_num=5, sampler=True, drop_last=False, shuffle=True )】
当data_num=5, drop_last=False时,总共5个数据,会平均分配到2两显卡上各2.5个,会向上补齐到6个数据,每张卡上三个,补齐的标准是把数据集的第一个数据用来补齐。
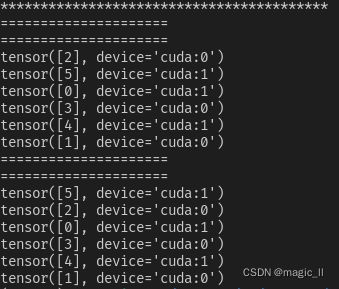
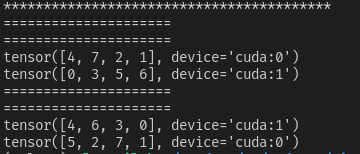
- case8【do_test(data_num=6, batch_size=1, sampler=True, drop_last=False)】
当batch_size=1时,数据读取没有问题,但如果网络结构中存在BatchNormalize,运行可能报错
- case8【do_test_batchsampler(data_num=8, batch_size=4, drop_last=True, shuffle=True)】
- case7的问题就需要使用
torch.utils.data.sampler.BatchSampler(sampler, batch_size, drop_last)来避免这样的问题发生。它其实是将Sampler作为参数进行打包,进而每次迭代返回以batch size为大小的index列表。BatchSampler的使用,需要提供sampler, batch_size, drop_last,那么DataLoader的sampler, batch_size, drop_last以及shuffle,都必须使用默认值,否则会报错。