YOLOV5之backbone介绍与迁移使用
1 整体架构
yolov5的特征提取网络如图所示:
该网络兼顾速度与精度,将PAN与PFN深度融合,对不同尺度鲁棒性强,可以即插即用,后接不同的检测器。
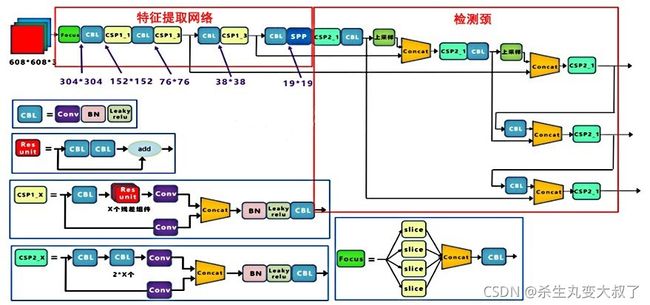
输入为(btsize,608,608),共包括24层(括号为输出):
(0) focus : (4, 64, 304, 304)
(1) conv : (4, 128, 152, 152)
(2) BottlenackCSP : (4, 128, 152, 152)
(3) conv : (4, 256, 76, 76)
(4) BottlenackCSP : (4, 256, 76, 76)
(5) conv : (4, 512, 38, 38)
(6) BottlenackCSP :(4, 512, 38, 38)
(7) Conv :(4, 1024 ,19 ,19 )
(8) SPP :(4, 1024 ,19 ,19 )
将上一特征图降维至(4,1024,19,19),做3个最大池化并cat,再降维
(9) BottlenackCSP :(4, 1024 ,19 ,19 )
(10) Conv : (4, 512 ,19 ,19 )
(11) Upsample : (4, 512 ,38 ,38 )
(12) Concat :(4,1024,38,38) (11)与(6)cat
(13) BottlenackCSP :(4, 512, 38, 38)
(14) Conv:(4, 256, 38, 38)
(15) Upsample:(4, 256, 76, 76)
(16) Concat: (4, 512, 76, 76) (15)与(4)cat
(17) BottlenackCSP :(4, 256, 76, 76)
(18) Conv :(4, 256, 38, 38)
(19) Concat :(4, 512, 38, 38) (18)与(14)cat
(20) BottlenackCSP :(4, 512, 38, 38)
(21) Conv :(4, 512, 19, 19)
(22) Concat :(4, 1024, 19, 19) (21)与(10)cat
(23) BottlenackCSP :(4, 1024, 19, 19)
()
最后输出为(17,20,23):(bt,256,76,76) (bt,512,38,38)(bt,1024,19,19)
2 代码实现
首先建立self.backbone,后续可以自己写检测头
from mmdet.models.yolo import Model
weights = '/home/ubuntu/r3det_tutorials/r3det-on-mmdetection-master/mmdet/models/yolov5l.pt'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
sys.path.insert(0, '/home/ubuntu/r3det_tutorials/r3det-on-mmdetection-master/mmdet')
ckpt = torch.load(weights, map_location=device) # load checkpoint
dic = {}
dic['nc']= ckpt['model'].yaml['nc']
dic['depth_multiple']= ckpt['model'].yaml['depth_multiple']
dic['width_multiple']= ckpt['model'].yaml['width_multiple']
dic['anchors']= ckpt['model'].yaml['anchors']
dic['backbone']= ckpt['model'].yaml['backbone']
dic['head'] = ckpt['model'].yaml['head'][:-1]
self.backbone = Model(dic, ch=3, nc=15).to(device) # create
# 加载 backbone 的预训练权重
# state_dict = ckpt['model'].float().state_dict() # to FP32
# state_dict = intersect_dicts(state_dict, self.backbone.state_dict()) # intersect
# self.backbone.load_state_dict(state_dict, strict=False) # load
yolo.py文件自行前往yolo5项目下载。以下提供代码,也需要其他库(如commen utils等)。
import argparse
import logging
import math
from copy import deepcopy
from pathlib import Path
import torch
import torch.nn as nn
from mmdet.models.common import Conv, Bottleneck, SPP, DWConv, Focus, BottleneckCSP, Concat
from mmdet.models.experimental import MixConv2d, CrossConv, C3
from mmdet.utils.general import check_anchor_order, make_divisible, check_file, set_logging
from mmdet.utils.torch_utils import (
time_synchronized, fuse_conv_and_bn, model_info, scale_img, initialize_weights, select_device)
logger = logging.getLogger(__name__)
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None): # model, input channels, number of classes
super(Model, self).__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
# Define model
if nc and nc != self.yaml['nc']:
print('Overriding model.yaml nc=%g with nc=%g' % (self.yaml['nc'], nc))
self.yaml['nc'] = nc # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist, ch_out
# print([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 128 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
# Init weights, biases
initialize_weights(self)
self.info()
print('')
def forward(self, x, augment=False, profile=False):
if augment:
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si)
yi = self.forward_once(xi)[0] # forward
# cv2.imwrite('img%g.jpg' % s, 255 * xi[0].numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi[..., :4] /= si # de-scale
if fi == 2:
yi[..., 1] = img_size[0] - yi[..., 1] # de-flip ud
elif fi == 3:
yi[..., 0] = img_size[1] - yi[..., 0] # de-flip lr
y.append(yi)
return torch.cat(y, 1), None # augmented inference, train
else:
return self.forward_once(x, profile) # single-scale inference, train
def forward_once(self, x, profile=False):
# x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
# x:list3:[4, 320, 80, 80] [4,640,40,40] [4,1280,20,20]
if profile:
try:
import thop
o = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # FLOPS
except:
o = 0
t = time_synchronized()
for _ in range(10):
_ = m(x)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
x = m(x) # run
# y.append(x if m.i in self.save else None) # save output [17, 20, 23]
y.append(x)
if profile:
print('%.1fms total' % sum(dt))
return tuple([y[17], y[20], y[23]])
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
print(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# print('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
for m in self.model.modules():
if type(m) is Conv and hasattr(Conv, 'bn'):
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatability
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.fuseforward # update forward
self.info()
return self
def info(self, verbose=False): # print model information
model_info(self, verbose)
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, Bottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
c1, c2 = ch[f], args[0]
# Normal
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1.75 # exponential (default 2.0)
# e = math.log(c2 / ch[1]) / math.log(2)
# c2 = int(ch[1] * ex ** e)
# if m != Focus:
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
# Experimental
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1 + gw # exponential (default 2.0)
# ch1 = 32 # ch[1]
# e = math.log(c2 / ch1) / math.log(2) # level 1-n
# c2 = int(ch1 * ex ** e)
# if m != Focus:
# c2 = make_divisible(c2, 8) if c2 != no else c2
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3]:
args.insert(2, n)
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[-1 if x == -1 else x + 1] for x in f])
elif m is Detect:
args.append([ch[x + 1] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
else:
c2 = ch[f]
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
opt = parser.parse_args()
opt.cfg = check_file(opt.cfg) # check file
set_logging()
device = select_device(opt.device)
# Create model
model = Model(opt.cfg).to(device)
model.train()
# Profile
# img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
# y = model(img, profile=True)
# ONNX export
# model.model[-1].export = True
# torch.onnx.export(model, img, opt.cfg.replace('.yaml', '.onnx'), verbose=True, opset_version=11)
# Tensorboard
# from torch.utils.tensorboard import SummaryWriter
# tb_writer = SummaryWriter()
# print("Run 'tensorboard --logdir=models/runs' to view tensorboard at http://localhost:6006/")
# tb_writer.add_graph(model.model, img) # add model to tensorboard
# tb_writer.add_image('test', img[0], dataformats='CWH') # add model to tensorboard
3。可视化
在yolo.py文件中添加可视化代码
import os
import matplotlib.pyplot as plt
from torchvision import transforms
def feature_visualization(features, model_type, model_id, feature_num=100):
"""
features: The feature map which you need to visualization
model_type: The type of feature map
model_id: The id of feature map
feature_num: The amount of visualization you need
"""
save_dir = "features/"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# print(features.shape)
# block by channel dimension
blocks = torch.chunk(features, features.shape[1], dim=1)
# # size of feature
# size = features.shape[2], features.shape[3]
plt.figure()
for i in range(feature_num):
torch.squeeze(blocks[i])
feature = transforms.ToPILImage()(blocks[i].squeeze())
# print(feature)
ax = plt.subplot(int(math.sqrt(feature_num)), int(math.sqrt(feature_num)), i+1)
ax.set_xticks([])
ax.set_yticks([])
plt.imshow(feature)
# gray feature
# plt.imshow(feature, cmap='gray')
# plt.show()
plt.savefig(save_dir + '{}_{}_feature_map_{}.png'
.format(model_type.split('.')[2], model_id, feature_num), dpi=300)
# 在此处添加代码
def forward_once(self, x, profile=False):
y, dt = [], [] # outputs
x = self.model[0](x)
y.append(x)
x = self.model[1](x) # ([1, 96, 160, 160])
y.append(x)
trans_x = x
# Trans_out = self.backbone(trans_x)
for m in self.model[2:]:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
# x:list3:[4, 320, 80, 80] [4,640,40,40] [4,1280,20,20]
# if m.f[-1] == 6:
# x.append(Trans_out[2])
# elif m.f[-1] == 4:
# x.append(Trans_out[1])
# elif m.f[-1] == 10:
# x.append(Trans_out[3])
# else:
# bbbb=0
if profile:
try:
import thop
o = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # FLOPS
except:
o = 0
t = time_synchronized()
for _ in range(10):
_ = m(x)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
x = m(x) # run
y.append(x if m.i in self.save else None) # save output [17, 20, 23]
feature_vis = True
if m.type == 'models.common.BottleneckCSP' and feature_vis:
print(m.type, m.i)
feature_visualization(x, m.type, m.i)
if profile:
print('%.1fms total' % sum(dt))
return x
可视化 效果展示
原图
