linux epoll 历史,linux下epoll实现机制
linux下epoll实现机制
原作者:陶辉
链接:http://blog.csdn.net/russell_tao/article/details/7160071
先简单回顾下如何使用C库封装的select系统调用吧
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select的使用方法是这样的:
返回的活跃连接 ==select(全部待监控的连接)
对高并发而言,全部待监控连接是数以十万计的,返回的只是数百个活跃连接,而select的每次调用都需要传入全部待监控连接给内核,这是非常低效的。
再来看epoll模型的API:
int epoll_create(intsize);int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
epoll的使用方法是这样的:
新建的epoll描述符==epoll_create()
epoll_ctrl(epoll描述符,添加或者删除所有待监控的连接)
返回的活跃连接 ==epoll_wait( epoll描述符 )
这么做的好处主要是:分清了频繁调用和不频繁调用的操作。例如,epoll_ctrl是不太频繁调用的,而epoll_wait是非常频繁调用的。这时,epoll_wait却几乎没有入参,这比select的效率高出一大截,而且,它也不会随着并发连接的增加使得入参越发多起来,导致内核执行效率下降。
epoll的工作方式:首先要调用epoll_create建立一个epoll对象。参数size是内核保证能够正确处理的最大句柄数,多于这个最大数时内核可能不保证效果。
epoll_ctl可以操作上面建立的epoll对象,例如,将刚建立的socket加入到epoll中让其监控,或者把 epoll正在监控的某个socket句柄移出epoll,不再监控它等等。
epoll_wait在调用时,在给定的timeout时间内,当在监控的所有句柄中有事件发生时,就返回用户态的进程。
从上面的调用方式就可以看到epoll比select/poll的优越之处:因为后者每次调用时都要传递你所要监控的所有socket给select/poll系统调用,这意味着需要将用户态的socket列表copy到内核态,如果以万计的句柄会导致每次都要copy几十几百KB的内存到内核态,非常低效。而我们调用epoll_wait时就相当于以往调用select/poll,但是这时却不用传递socket句柄给内核,因为内核已经在epoll_ctl中拿到了要监控的句柄列表。
所以,实际上在你调用epoll_create后,内核就已经在内核态开始准备帮你存储要监控的句柄了,每次调用epoll_ctl只是在往内核的数据结构里塞入新的socket句柄。
在内核里,一切皆文件。所以,epoll向内核注册了一个文件系统,用于存储上述的被监控socket。当你调用epoll_create时,就会在这个虚拟的epoll文件系统里创建一个file结点。当然这个file不是普通文件,它只服务于epoll。
epoll在被内核初始化时(操作系统启动),同时会开辟出epoll自己的内核高速cache区,用于安置每一个我们想监控的socket,这些socket会以红黑树的形式保存在内核cache里,以支持快速的查找、插入、删除。这个内核高速cache区,就是建立连续的物理内存页,然后在之上建立slab层,简单的说,就是物理上分配好你想要的size的内存对象,每次使用时都是使用空闲的已分配好的对象。
static int __init eventpoll_init(void)
{
... .../*Allocates slab cache used to allocate "struct epitem" items*/epi_cache= kmem_cache_create("eventpoll_epi", sizeof(structepitem),0, SLAB_HWCACHE_ALIGN|EPI_SLAB_DEBUG|SLAB_PANIC,
NULL, NULL);/*Allocates slab cache used to allocate "struct eppoll_entry"*/pwq_cache= kmem_cache_create("eventpoll_pwq",sizeof(struct eppoll_entry), 0,
EPI_SLAB_DEBUG|SLAB_PANIC, NULL, NULL);
... ...
epoll的高效就在于,当我们调用epoll_ctl往里塞入百万个句柄时,epoll_wait仍然可以飞快的返回,并有效的将发生事件的句柄给我们用户。这是由于我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。
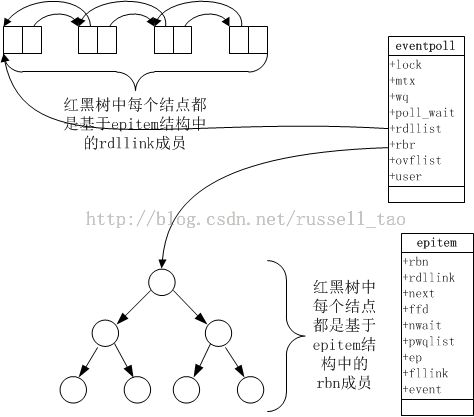
图中左下方的红黑树由所有待监控的连接构成。左上方的链表,同是目前所有活跃的连接。于是,epoll_wait执行时只是检查左上方的链表,并返回左上方链表中的连接给用户(仅需要从内核态copy少量的句柄到用户态而已)。这样,epoll_wait的执行效率能不高吗?
那么,这个准备就绪list链表是怎么维护的呢?当我们执行epoll_ctl时,除了把socket放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到准备就绪链表里了。
如此,一颗红黑树,一张准备就绪句柄链表,少量的内核cache,就帮我们解决了大并发下的socket处理问题。执行epoll_create时,创建了红黑树和就绪链表,执行epoll_ctl时,如果增加socket句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,用于当中断事件来临时向准备就绪链表中插入数据。执行epoll_wait时立刻返回准备就绪链表里的数据即可。
最后看看epoll独有的两种模式LT(水平触发)和ET(边缘触发)。无论是LT和ET模式,都适用于以上所说的流程。
这件事怎么做到的呢?当一个socket句柄上有事件时,内核会把该句柄插入上面所说的准备就绪list链表,这时我们调用epoll_wait,会把准备就绪的socket拷贝到用户态内存,然后清空准备就绪list链表,最后,epoll_wait干了件事,就是检查这些socket,如果是LT模式,并且这些socket上确实有未处理的事件时,又把该句柄放回到刚刚清空的准备就绪链表了。所以,LT模式的句柄,只要它上面还有事件,epoll_wait每次都会返回。而ET模式的句柄,除非有新中断到,即使socket上的事件没有处理完,也是不会次次从epoll_wait返回的。
例如,我们需要监控一个连接的写缓冲区是否空闲,满足“可写”时我们就可以从用户态将响应调用write发送给客户端 。但是,或者连接可写时,我们的“响应”内容还在磁盘上呢,此时若是磁盘读取还未完成呢?肯定不能使线程阻塞的,那么就不发送响应了。但是,下一次epoll_wait时可能又把这个连接返回给你了,你还得检查下是否要处理。可能,我们的程序有另一个模块专门处理磁盘IO,它会在磁盘IO完成时再发送响应。那么,每次epoll_wait都返回这个“可写”的、却无法立刻处理的连接,是否符合用户预期呢?
LT是每次满足期待状态的连接,都得在epoll_wait中返回,所以它一视同仁,都在一条水平线上。ET则不然,它倾向更精确的返回连接。在上面的例子中,连接第一次变为可写后,若是程序未向连接上写入任何数据,那么下一次epoll_wait是不会返回这个连接的。ET叫做 边缘触发,就是指,只有连接从一个状态转到另一个状态时,才会触发epoll_wait返回它。可见,ET的编程要复杂不少,至少应用程序要小心的防止epoll_wait的返回的连接出现:可写时未写数据后却期待下一次“可写”、可读时未读尽数据却期待下一次“可读”。
当然,从一般应用场景上它们性能是不会有什么大的差距的,ET可能的优点是,epoll_wait的调用次数会减少一些,某些场景下连接在不必要唤醒时不会被唤醒(此唤醒指epoll_wait返回)。但如果像我上面举例所说的,有时它不单纯是一个网络问题,跟应用场景相关。当然,大部分开源框架都是基于ET写的,框架嘛,它追求的是纯技术问题,当然力求尽善尽美。