【因果推断与机器学习】Causal Inference: Chapter_2
chapter 2: Models and Assumptions
Introduction
常规的统计学和机器学习问题着重数据,虽然数据很重要但是他不是整个系统的唯一部分。同样重要的是我们带来的外部知识,我们对数据生成机制的先验知识和似是而非的因果机制的假设。事实上,正是这种外部先验知识将因果推理与联想方法区分开来。得到关于因果机制和任何的因果假设是因果分析的第一步。
2.1 Causal Graph
_causal graph_因果图是用于建模因果机制和表达我们假设的主要语言。因果图编码了我们关于系统或者背后现象的一些因果机制和领域先验知识。因果图主要有两种元素组成。值得注意的是:因果图被认为是有向无环图。
-Node代表我们正在建模的世界或系统中的变量或特征。
-Edges代表连接一个结点到另一个结点的连结。每条边代表一种机制或因果关系。有向边表示指定的因果影响关系。图1表示结点A的值改变会影响结点B,但是如果改变B的值并不会改变A。在影响方向未知的情况下,用一条无向边表示。
Causal graphs and statistical independence
从根本上说,因果图描述了在其节点上的非参数数据生成过程。通过指定节点之间的独立性和依赖性,该图约束了对应于那些节点的所生成的变量之间的关系。
因果图提供了关于统计独立性的信息。如果知道一个节点的值并不能给出关于另一个节点的值的信息,则两个节点x和y在统计上是独立的。那就是:
x ⊥ y , i f f P ( x ) = P ( x ∣ y ) x{\bot}y,iffP(x)=P(x|y) x⊥y,iffP(x)=P(x∣y)
其中 ⊥ \bot ⊥是独立的符号,我们还经常处理条件独立,其中两个节点x和y可能仅在统计上独立于某个其他节点z:
( x ⊥ y ) ∣ z , i f f P ( x ∣ z ) = P ( x ∣ y , z ) (x{\bot}y)|z,iffP(x|z)=P(x|y,z) (x⊥y)∣z,iffP(x∣z)=P(x∣y,z)
这里统计关系和因果论最大的不同就是:统计关系对应于特定的数据分布,不应与因果关系混淆。因果关系关注的是操纵一个节点的值是否会导致另一个节点的值发生变化,而统计关系关注的是知道一个节点的值是否会提供关于另一个节点的值的信息。
three classic Kinds of Causal Graph
为了说明因果图如何暗示某些统计独立性,让我们考虑三个变量的不同图结构。图2显示了三个重要的结构:碰撞结构、分叉结构和链式结构。
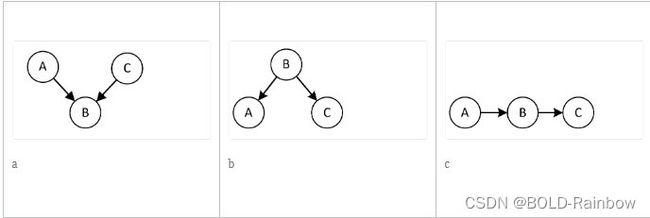
左子图显示了由A和C引起的节点B。这样的节点称为碰撞结点collider,因为来自两个父节点的因果在该节点上发生碰撞。重要的是,没有因果信息通过B从A传递到C,因此A和C在统计上是独立的。中间的子图表示分叉结构,其中B导致A和C,在这里B的值决定A和C的值,因此A和C不是独立的。然而,它们之间统计相关性的唯一来源是B。若限定条件B也就是给定B的值,在这种情况下A和C在统计上独立的。换句话说就是在限定条件B的情况下,A和C独立。右图:表示链式结构,因为从A到C的任何因果信息必须经过B。因此,与分叉结构类似,在给定B的条件下,A和C是有条件独立的。
这里我们使用任意两个节点之间的无向路径的概念,定义为连接两个节点的一组邻接边。为了确定两个节点之间的统计独立性,我们考虑两个节点之间的所有无向路径,并测试这些路径是否具有任何这些结构。对撞结构的因果图是唯一不需要条件就能导致统计独立的结构。因此,如果两个节点之间的所有无向路径都包含一个碰撞器,则这两个节点是独立的。当然,如果没有无向路径连接它们,它们也是独立的。
在这里引入两个重要的概念**d-separated和Conditional d-separation**:导致统计独立变量的节点被称为是彼此d分离的。也就是说因果图中的两个节点不存在连接两节点的无向路径,或者连接它们的所有路径都包含Collider。
然而,有条件的独立并不简单。从fork和chain的另外两个基础结构中,我们看到了在B上的条件作用使得A和C是独立的。然而,对撞结构显示了相反的性质。以对撞机B为条件,A和C变得依赖。这是因为知道一个碰撞器的价值和它的一个父母告诉我们一些关于另一个父母的事情。举个例子:什么样的情况会导致一个男生变成渣男,那就是长得有点小帅然后还爱养鱼。基于上述讨论,条件独立或d-separation要求条件变量沿着两个节点之间的所有路径形成一个分叉结构或者链式结构,但也要求它不在任何路径上形成碰撞器。
conditional d-separation:因果图中的两个节点在另一个节点B上是条件d-分离的,如果它们是d-分离的,或者连接它们的所有无向路径包含B作为分支结构或链式结构,但不是碰撞结构。
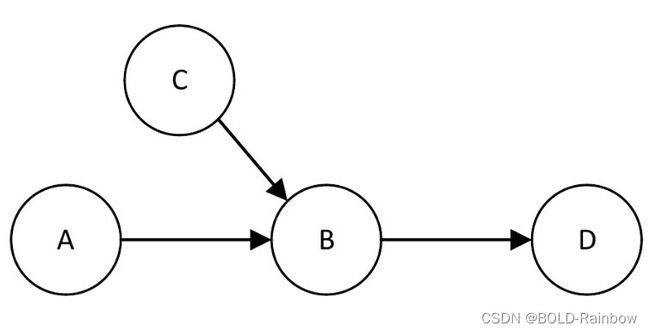
Causal graph and resulting data distributions
因为图中的边只表示影响的方向,而没有规定其大小、形状或相互作用,因此多个数据生成过程和多个数据概率分布与同一因果图兼容。形式上,因果图指定了数据的联合概率分布的因子分解。任何符合图的概率分布都需要遵循特定的因式分解。举个例子,在图3中可以写出A、B、C、D的联合概率分布是:
P ( A , B , C , D ) = P ( D ∣ A , B , C ) P ( B ∣ C , A ) P ( C ∣ A ) P ( A ) = P ( D ∣ B ) P ( B ∣ C , A ) P ( C ) P ( A ) P(A,B,C,D)=P(D|A,B,C)P(B|C,A)P(C|A)P(A) \\ =P(D|B)P(B|C,A)P(C)P(A) P(A,B,C,D)=P(D∣A,B,C)P(B∣C,A)P(C∣A)P(A)=P(D∣B)P(B∣C,A)P(C)P(A)
以上等式来源于概率论中的链式法则:
2个时间同时发生的概率: P ( a , b ) = P ( a ∣ b ) ∗ P ( b ) P(a,b)=P(a|b)*P(b) P(a,b)=P(a∣b)∗P(b)其中, P ( a , b ) P(a,b) P(a,b)表示a和b事件同时发生的概率, P ( a ∣ b ) P(a|b) P(a∣b)是一个条件概率,表示在b事件发生的条件下,a发生的概率。
3个事件的联合概率公式可写为: P ( a , b , c ) = P ( a ∣ b , c ) ∗ P ( b , c ) = P ( a ∣ b , c ) ∗ P ( b ∣ c ) ∗ P ( c ) P(a,b,c)=P(a|b,c)*P(b,c)=P(a|b,c)*P(b|c)*P(c) P(a,b,c)=P(a∣b,c)∗P(b,c)=P(a∣b,c)∗P(b∣c)∗P(c)
推广到N个事件,根据链式法则可写出联合概率分布式子为: P ( x 1 , x 2 , ⋯ , x n ) = P ( x 1 ∣ X 2 , x 3 , ⋯ , x n ) ∗ P ( x 2 ∣ x 3 , x 4 , ⋯ , x n ) ⋯ P ( x n − 1 ∣ x n ) ∗ P ( x n ) P(x_1,x_2,\cdots,x_n)=P(x_1|X_2,x_3,\cdots,x_n)*P(x_2|x_3,x_4,\cdots,x_n){\cdots}P(x_n-1|x_n)*P(x_n) P(x1,x2,⋯,xn)=P(x1∣X2,x3,⋯,xn)∗P(x2∣x3,x4,⋯,xn)⋯P(xn−1∣xn)∗P(xn)
所有的事件只与它们的父节点有依赖关系,在概率图模型中可简化联合概率分布等式。
其中第一个方程来自概率链法则。第二个方程和第三个方程来自因果图的结构。如上所述,基于该图,A和C是独立的。此外,B阻塞了从A、C到D的有向路径,所以D独立于给定B的A和C。更一般地,对于变量 V 1 、 V 2 , . . . V m V1、V2,...Vm V1、V2,...Vm,数据的概率分布由下式给出:
P ( V 1 , V 2 , . . . , V m ) = ∏ i = 1 m P ( V i ∣ P a G ( V i ) ) P(V_1,V_2,...,V_m)=\prod_{i=1}^mP(V_i|PaG(V_i)) P(V1,V2,...,Vm)=i=1∏mP(Vi∣PaG(Vi))
其中 P a G ( V i ) PaG(V_i) PaG(Vi)指的是因果图.中 V i V_i Vi的父结点。注意,从图中生成的每个概率分布都必须满足上述因式分解和由此产生的独立性约束。
此外,一些数据分布可能会进一步分解分布,并包含更多的独立性。因果图中两个节点之间的边传达了它们之间可能存在关系的假设,但是并非所有的数据分布都必然遵循它。由于存在多种可能的分布,在一些分布中,节点之间的影响变为零。例如,虽然A和B通过图2中的边连接,但是可能存在A对B的影响为零的数据集。作为另一个例子,在第一章的冰淇淋和游泳因果图中,我们会发现冰淇淋对游泳的影响为零,即使因果图包括一条边。因此,包含一条边反映了因果关系的可能性,但并不证实它。因果图中一个节点对另一个节点的影响也可以通过多重交互影响而抵消。例如,基于图2的图表,如果B对D的影响直接抵消A对B的影响,则可能存在A和D独立的分布。这种确切的抵消通常被认为是不可信的。
因果图的另一个含义是数据的联合概率的特定因子分解。虽然其他因子分解对于给定的数据集也是有效的,但是符合等式1的因子分解,更可能概括数据分布的变化。也就是说,我们可以将单个条件概率因子视为独立的机制。在从图2中的图生成的任何数据集中,如果P(A)改变,我们期望P(B)也改变,但是不期望它们之间的因果关系P(B|A)改变。
总的来说,比较因果图和概率图模型是很有用的。虽然概率图形模型也提供了条件独立性的图形表示,但这样的图形仅对应于特定的数据分布。相反,因果图表示跨数据分布稳定的不变关系。这些关系应该适用于底层系统的所有配置。因此,因果图提供了一种简洁的方式来描述一个系统的关键的、不变的特性。
key Properties
- 因果图断言的假设由图中缺失的边和边的方向编码。
- 因果关系对应稳定独立的机制。
- 因果图不能仅从数据中学习。
- 因果图是帮助我们对特定问题进行推理的工具。
属性1:这些关于图的属性表达的含义是:一旦我们将可能的因果关系和相关领域知识以图表的形式建立,我们可以推理出图中任何一对节点之间的因果关系,而不需要求助于额外的领域知识。但是,什么时候使用对潜在的因果机制做出更多或更少假设的模型更好?一帮来说,在创建因果图时,我们应该努力在图中编码尽可能多的领域知识。如果我们通过外部知识确实知道两个节点之间没有直接的因果关系,那么我们没有理由添加这样的边,事实上如果我们添加了这样的边会导致我们的计算和分析变得更加困难。
Structural Equations, Noise, and Unobserved Nodes
由于因果图只是一种简化抽象的表示,它捕捉了系统的许多关键信息但同时也忽略了许多细节,比如噪声和未观测节点的重要性。在这一节中,我们将介绍结构方程如何表示由图的边表示的函数关系的细节;并讨论噪声和未观测节点的重要性。为了更好的描述和表示因果推理的结构模型框架,引入结构方程、噪声模型、和未观测结点变量。
Structural Equations
因果图中虽然一条边的关键信息是结点之间的某种联系,但是这条边并没有告诉我们变量之间的影响的形状或者大小,which means我们无法确定改变一个变量的值对另一个变量值的影响的量变关系。在多个节点相互影响的更复杂的情况下,我们无法判断这些节点的值如何相互影响。
为了用节点之间的功能关系的更强特征来扩充因果图,我们经常使用结构方程模型(SEM)。每个等式从等式的右边到左边代表一个因果分配。等式。2、3分别示出了图1 (a)、2的一般结构方程:
B ← f ( A ) ( 2 ) B\:\leftarrow\:f(A) \qquad \qquad \qquad \qquad \qquad (2) B←f(A)(2)
D ← f 1 ( B ) B ← f 2 ( A , C ) ( 3 ) D\: \leftarrow\:f_1(B)\\ B\:\leftarrow\:f_2(A,C)\qquad(3) D←f1(B)B←f2(A,C)(3)
结构方程和等式的最大区别是,结构方程更多地展示了因果关系表达了因果关系方向,传统方程没有此意义。
Noisy models
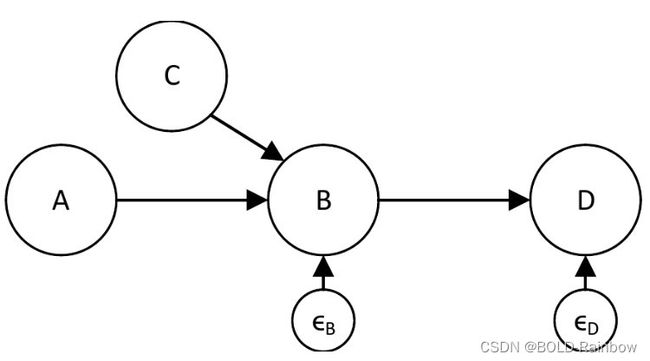
任何模型,无论是因果图还是一组结构方程,都必然(充其量)代表控制系统行为的最重要的因果因素和关系的简化版本。为了说明影响系统行为的许多次要因素,通常的做法是在结构方程中引入一个ϵ噪声项:
D ← α 1 ∗ B + ϵ D D\:\leftarrow\:\alpha_1*B\:+\:\epsilon_D D←α1∗B+ϵD
B ← α 2 ∗ A + β 2 ∗ C + ϵ B B\:\leftarrow\:\alpha_2*A\:+\:\beta_2*C\:+\:\epsilon_B B←α2∗A+β2∗C+ϵB
Unobserved Nodes
通常,我们知道我们将创建一个系统的因果模型,但是我们不能观察我们的因果系统中的所有节点。一些节点的值可能完全不可见或隐藏。如果我们不知道如何衡量一个节点的价值,该节点太昂贵而无法衡量,或者一段数据太隐私或太机密,就会发生这种情况。根据系统的因果结构,我们仍然可以经常通过对其值被观察的节点进行计算来解决我们的特定任务或问题。为了表示因果图中未观察到的节点,我们将其轮廓标记为虚线(图7)。
