丢弃法——dropout
《动手学深度学习pytorch》部分学习笔记,仅用作自己复习。
丢弃法——dropout
除了权重衰减以外,深度学习模型常使⽤丢弃法(dropout) 来应对过拟合问题。丢弃法有一些不同的变体。本节中提到的丢弃法特指倒置丢弃法(inverted dropout)。
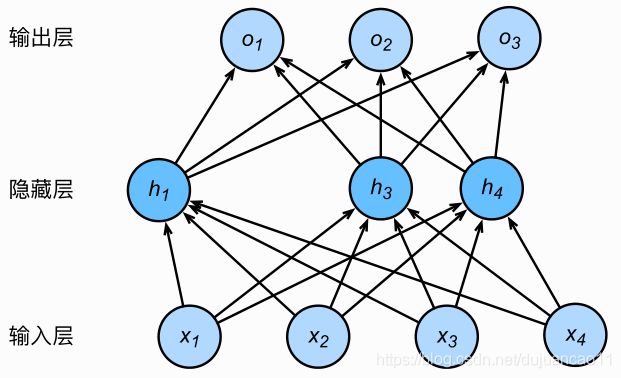
单隐藏层的多层感知机,其中输⼊个数为4,隐藏单元个数为5,且隐藏单元 的计算表达式为
![]()



从零开始实现
# dropout 函数将以 drop_prob 的概率丢弃 X中的元素。
%matplotlib inline
import torch
import torch.nn as nn
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
def dropout(X, drop_prob):
X = X.float()
assert 0 <= drop_prob <= 1
keep_prob = 1 - drop_prob
# 这种情况下把全部元素都丢弃
if keep_prob == 0:
return torch.zeros_like(X)
mask = (torch.randn(X.shape) < keep_prob).float()
return mask * X / keep_prob运行几个例⼦来测试一下 dropout 函数。其中丢弃概率分别为0、0.5和1。
X = torch.arange(16).view(2, 8)
dropout(X, 0)dropout(X, 0.5)dropout(X, 1.0)定义模型参数
(softmax回归的从零开始实现)中介绍的Fashion-MNIST数据集。我们将定义一个包含两个隐藏层的多层感知机,其中两个隐藏层的输出个数都是256。
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256,256
W1 = torch.tensor(np.random.normal(0, 0.01, size=(num_inputs,num_hiddens1)), dtype=torch.float, requires_grad=True)
b1 = torch.zeros(num_hiddens1, requires_grad=True)
W2 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens1,num_hiddens2)), dtype=torch.float, requires_grad=True)
b2 = torch.zeros(num_hiddens2, requires_grad=True)
W3 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens2,num_outputs)), dtype=torch.float, requires_grad=True)
b3 = torch.zeros(num_outputs, requires_grad=True)
params = [W1, b1, W2, b2, W3, b3]定义模型
下面定义的模型将全连接层和激活函数ReLU串起来,并对每个激活函数的输出使⽤丢弃法。我们可以分别设置各个层的丢弃概率。通常的建议是把靠近输入层的丢弃概率设得⼩一点。实验中,我们把第一个隐藏层的丢弃概率设为0.2,把第二个隐藏层的丢弃概率设为0.5。我们可以通过参数 is_training 函数来判断运行模式为训练还是测试,并只需在训练模式下使⽤用丢弃法。
# 把靠近输入层的丢弃概率设得⼩一点
drop_prob1, drop_prob2 = 0.2, 0.5
def net(X, is_training=True):
# 这里通过 view 函数将每张原始图像改成长度为 num_inputs 的向量。
X = X.view(-1, num_inputs)
H1 = (torch.matmul(X, W1) + b1).relu()
if is_training: # 只在训练模型时使⽤用丢弃法
H1 = dropout(H1, drop_prob1) # 在第⼀层全连接后添加丢弃层
H2 = (torch.matmul(H1, W2) + b2).relu()
if is_training:
H2 = dropout(H2, drop_prob2) # 在第二层全连接后添加丢弃层
return torch.matmul(H2, W3) + b3在 对 模 型 评 估 的 时 候 不 应 该 进 行 丢 弃 , 所 以 我 们 修 改一 下 d2lzh_pytorch 中 的evaluate_accuracy 函数:
# 本函数已保存在d2lzh_pytorch
def evaluate_accuracy(data_iter, net):
# 初始化
acc_sum, n = 0.0, 0
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
net.train() # 改回训练模式
else: # 自定义的模型
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, s_training=False).argmax(dim=1)==y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n训练和测试模型
num_epochs, lr, batch_size = 5, 100.0, 256
loss = torch.nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs,batch_size, params, lr)输出:
epoch 1, loss 0.0044, train acc 0.574, test acc 0.648
epoch 2, loss 0.0023, train acc 0.786, test acc 0.786
epoch 3, loss 0.0019, train acc 0.826, test acc 0.825
epoch 4, loss 0.0017, train acc 0.839, test acc 0.831
epoch 5, loss 0.0016, train acc 0.849, test acc 0.850
简洁实现
在PyTorch中,我们只需要在全连接层后添加 Dropout 层并指定丢弃概率。在训练模型时, Dropout层 将 以 指 定 的 丢 弃 概 率 随 机 丢 弃 上 ⼀ 层 的 输 出 元 素 ; 在测试模型时 ( 即 model.eval()后), Dropout 层并不发挥作用。
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens1),
nn.ReLU(),
nn.Dropout(drop_prob1),
nn.Linear(num_hiddens1, num_hiddens2),
nn.ReLU(),
nn.Dropout(drop_prob2),
nn.Linear(num_hiddens2, 10)
)
for param in net.parameters():
nn.init.normal_(param, mean=0, std=0.01)训练并测试模型。
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs,batch_size, None, None, optimizer)输出:
epoch 1, loss 0.0045, train acc 0.553, test acc 0.715
epoch 2, loss 0.0023, train acc 0.784, test acc 0.793
epoch 3, loss 0.0019, train acc 0.822, test acc 0.817
epoch 4, loss 0.0018, train acc 0.837, test acc 0.830
epoch 5, loss 0.0016, train acc 0.848, test acc 0.839
小结
- 我们可以通过使用丢弃法应对过拟合。
- 丢弃法只在训练模型时使用。