李沐-丢弃法dropout
理论
- 动机:一个好的模型需要对输入数据的扰动鲁棒!
- 使用有噪音的数据等价于Tikho’nov正则
- 丢弃法:在层之间加入噪音
- 无偏差的加入噪音

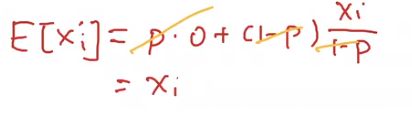
3.使用丢弃法
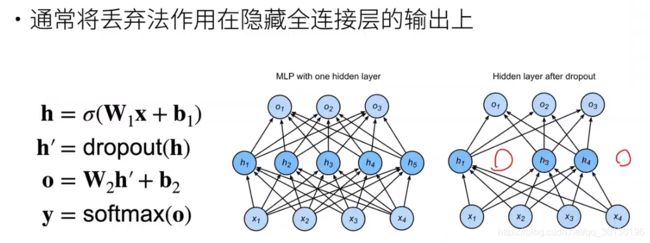
推理中的丢弃法

总结

代码
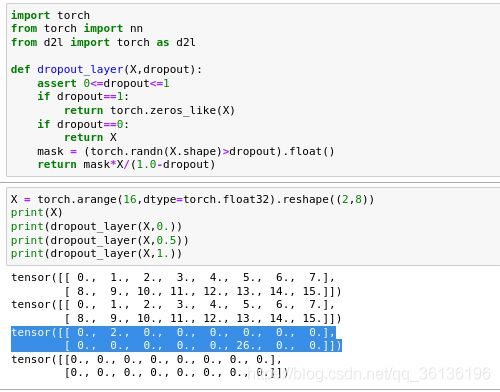
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃。
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留。
if dropout == 0:
return X
mask = (torch.Tensor(X.shape).uniform_(0, 1) > dropout).float()
return mask * X / (1.0 - dropout)
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
注意
在上边没有初始化参数,是nn.Linear中初始化了

而下边初始化是用的特定实现(下边是pytorch的demo)
参考博文https://blog.csdn.net/qq_37025073/article/details/106739513
>>> m = nn.Linear(20, 30)
>>> input = torch.randn(128, 20)
>>> output = m(input)
>>> print(output.size())
torch.Size([128, 30])
简洁实现
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1), nn.Linear(256, 256), nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2), nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
QA
- 一般地,把模型弄大一点,dropout一下,会比模型小一些效果更好。
- BN用在卷积(CNN),dropout用在全连接层上(MLP)
- 在预测/推理时,不需要更新权重,不用dropout的。训练时才用。推理时只关心某一个样本,则dropout的不稳定性很致命,而训练时,要训练非常多次,参数也是要更新的。
- 随机dropout,推理时不会翻倍。因为有1-p存在,均值保持不变,
- 丢弃法(dropout)和权重衰减(weigh decay)都是正则,但* dropout一般用在全连接层,效果也好,weigh decay可以用在各个地方,比如全连接层,卷积层。
- dropout一般有0.1,0.5,0.9三个值,好调参。