多层感知机(PyTorch)
https://courses.d2l.ai/zh-v2/
文章目录
-
- 多层感知机
-
- 感知机
- 训练感知机
- 收敛定理
- XOR 问题(Minsky & Papert,1969)
- 总结
- 多层感知机
-
- 学习 XOR
- 单隐藏层
-
- 单隐藏层 — 单分类
- 激活函数
-
- Sigmoid 激活函数
- Tanh 激活函数
- ReLU 激活函数
- 多类分类
- 多隐藏层
- 总结
- 多层感知机的从零开始实现
-
- 激活函数
- 模型
- 损失函数
- 训练
- 多层感知机的简洁实现
- 模型
- QA
多层感知机
感知机
- 给定输入 x \bf x x,权重 w \bf w w,和偏移b,感知机输出:
o = σ ( < w , x > + b ) σ ( x ) = { 1 i f x > 0 0 o t h e r w i s e o=\sigma(
感知机就是二分类的问题
把0改成-1也行
- 二分类:-1或1
- Vs. 回归输出实数
- VS. Softmax 回归输出概率
线性回归输出是一个实数,这里输出是一个离散的类
训练感知机
initalize w=0 and b=0
repeat
if yi[<w,xi>+b] <= 0then # <=0 意味着感知机把样本预测错了
w <-- w + yixi and b <-- b + yi
end if
until all classfied correctly
就是预测和真实值相乘,>0说明预测正确,<0说明预测错误。
看不懂可以先去学感知机的数学推导。
等价于使用批量大小为1的梯度下降,并使用如下的损失函数。
θ ( y , x , w ) = m a x ( 0 , − y < w , x > ) \theta(y,x,w)=max(0, -y
max 对应 if 语句
当正确的时候,loss 为0,为常数,没有梯度
注意,这里梯度下降的学习率设置为1,
收敛定理
- 数据在半径 r 内
- 余量 ρ \rho ρ分类两类
y ( x T w + b ) ≥ ρ y(x^Tw+b)\ge\rho y(xTw+b)≥ρ
对于 ∣ ∣ w ∣ ∣ 2 + b 2 ≤ 1 ||w||^2+b^2\le1 ∣∣w∣∣2+b2≤1 - 感知机保证在 r 2 + 1 ρ 2 {r^2+1 \over \rho^2} ρ2r2+1步后收敛

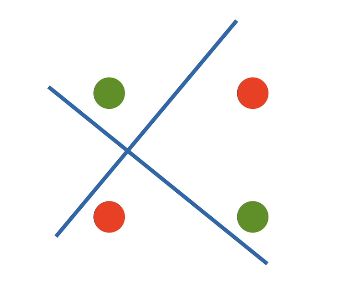
XOR 问题(Minsky & Papert,1969)
感知机不能拟合 XOR 函数,它只能产生线性分割面
总结
- 感知机是一个二分类模型,是最早的 Al 模型之一
- 它的求解算法等价于使用批量大小为1的梯度下降
- 它不能拟合 XOR 函数,导致的第一次 Al 寒冬
多层感知机
学习 XOR
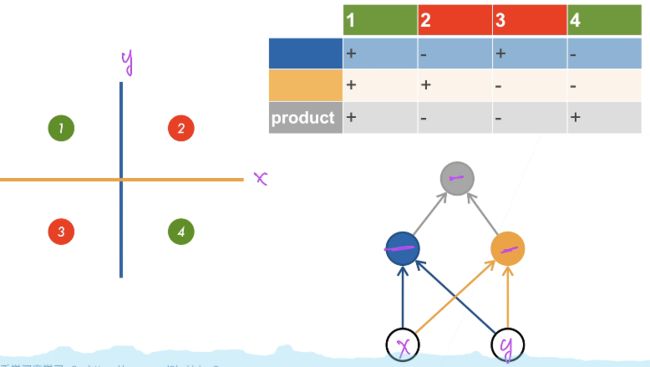
单隐藏层

隐 藏 层 大 小 是 超 参 数 隐藏层大小是超参数 隐藏层大小是超参数
单隐藏层 — 单分类
- 输入 x ∈ R n x \in R^n x∈Rn
- 隐藏层 W 1 ∈ R m × n , b 1 ∈ R m W_1 \in R^{m\times n},b_1 \in R^m W1∈Rm×n,b1∈Rm
- 输出层 w 2 ∈ R m , b 2 ∈ R w_2 \in R^m,b_2 \in R w2∈Rm,b2∈R
h = σ ( W 1 x + b 1 ) o = w 2 T h + b 2 h =\sigma(W_1x + b_1)\\ o = w_2^Th+b2 h=σ(W1x+b1)o=w2Th+b2
σ \sigma σ是按元素的激活函数
为什么需要非线性激活函数?
否则结果还是一个最简单的线性函数
hence o = w 2 T W 1 x + b ′ o = w_2^TW_1x + b' o=w2TW1x+b′
激活函数
Sigmoid 激活函数
把输入投影到(0,1),是一个软的 σ ( x ) = { 1 i f x > 0 0 o t h e r w i s e \sigma(x)= \begin{cases} 1\quad if\; x>0\\ 0\quad otherwise \end{cases} σ(x)={1ifx>00otherwise
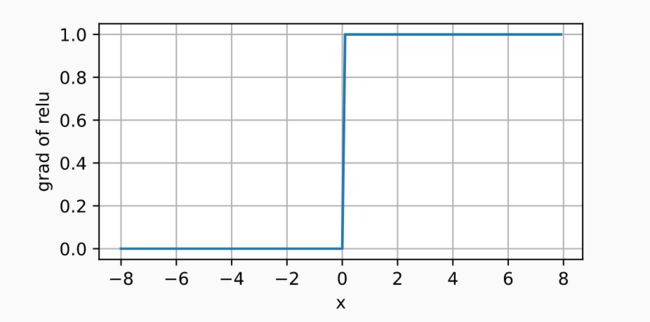
σ ( x ) \sigma(x) σ(x)在原点0处不好求导
s i g m o i d ( x ) = 1 1 + e x p ( − x ) sigmoid(x)={1 \over 1+exp(-x)} sigmoid(x)=1+exp(−x)1


Tanh 激活函数
把输入投影到(-1,1)
t a n h ( x ) = 1 − e x p ( − 2 x ) 1 + e x p ( − 2 x ) tanh(x)={1-exp(-2x) \over 1+ exp(-2x)} tanh(x)=1+exp(−2x)1−exp(−2x)

ReLU 激活函数
ReLU:rectified linear uint
R e L U ( x ) = m a x ( x , 0 ) ReLU(x)=max(x,0) ReLU(x)=max(x,0)
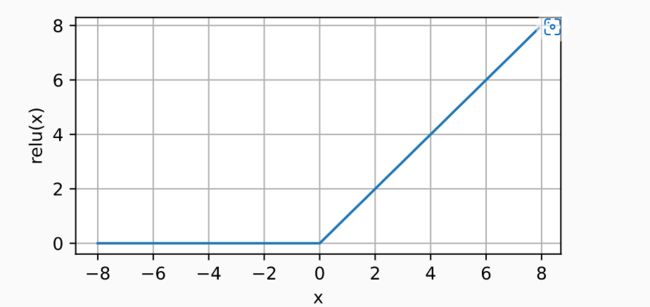
深度学习就是把很多经典的东西重命名
多类分类
y 1 , y 2 , . . . , y k = s o f t m a x ( o 1 , o 2 , . . . , o k ) y_1,y_2,...,y_k=softmax(o_1,o_2,...,o_k) y1,y2,...,yk=softmax(o1,o2,...,ok)
多类分类和 softmax 回归基本没区别,就是多加了一层隐藏层,从而变成多层感知机
softmax 把所有输入拉到0和1的区域,使得它们加起来等于1,这就得到了概率

- 输入 x ∈ R n x \in R^n x∈Rn
- 隐藏层 W 1 ∈ R m × n , b 1 ∈ R m W_1 \in R^{m\times n},b_1 \in R^m W1∈Rm×n,b1∈Rm
- 输出层 W 2 ∈ R m × k , b 2 ∈ R k W_2 \in R^{m\times k},b_2 \in R^k W2∈Rm×k,b2∈Rk
h = σ ( W 1 x + b 1 ) o = W 2 T h + b 2 y = s o f t m a x ( o ) h =\sigma(W_1x + b_1)\\ o = W_2^Th+b2\\ y=softmax(o) h=σ(W1x+b1)o=W2Th+b2y=softmax(o)
多隐藏层
h 1 = σ ( W 1 x + b 1 ) h 2 = σ ( W 2 h 1 + b 2 ) h 3 = σ ( W 3 h 2 + b 3 ) o = W 4 h 3 + b 4 h_1 =\sigma(W_1x + b_1)\\ h_2 =\sigma(W_2h_1 + b_2)\\ h_3 =\sigma(W_3h_2 + b_3)\\ o=W_4h_3+b_4 h1=σ(W1x+b1)h2=σ(W2h1+b2)h3=σ(W3h2+b3)o=W4h3+b4
超参数
- 隐藏层数
- 每层隐藏层的大小

激活函数主要用来避免层数的塌陷
意思就是,如果是线性映射就能把所有层合并(层数塌陷),非线性就不能合并
总结
- 多层感知机使用隐藏层和激活函数来得到非线性模型
- 常用激活函数Sigmoid,Tanh,ReLU
- 使用 Softmax 来处理多类分类
- 超参数为隐藏层数,和各个隐藏层大小
多层感知机的从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
回想一下,Fashion-MNIST中的每个图像由 28 × 28 = 784 28 \times 28 =784 28×28=784个灰度像素值组成。 所有图像共分为10个类别。 忽略像素之间的空间结构, 我们可以将每个图像视为具有784个输入特征 和10个类的简单分类数据集。 首先,我们将实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元。 注意,我们可以将这两个变量都视为超参数。 通常,我们选择2的若干次幂作为层的宽度。 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
我们用几个张量来表示我们的参数。 注意,对于每一层我们都要记录一个权重矩阵和一个偏置向量。 跟以前一样,我们要为损失关于这些参数的梯度分配内存。
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
randn 是正态(0,1)分布,乘0.01使得分布为正态(0,0.1)分布,数据方差更小。
激活函数
为了确保我们对模型的细节了如指掌, 我们将实现ReLU激活函数, 而不是直接调用内置的relu函数。
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
模型
因为我们忽略了空间结构, 所以我们使用reshape将每个二维图像转换为一个长度为num_inputs的向量。 只需几行代码就可以实现我们的模型。
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1) # 这里“@”代表矩阵乘法
return (H @ W2 + b2)
@ 是 numpy 里面的点积运算符号,相当于np.dot()
损失函数
这里我们直接使用高级API中的内置函数来计算softmax和交叉熵损失。
loss = nn.CrossEntropyLoss(reduction='none')
训练
幸运的是,多层感知机的训练过程与softmax回归的训练过程完全相同。 可以直接调用d2l包的train_ch3函数参见 Softmax 回归从零开始实现, 将迭代周期数设置为10,并将学习率设置为0.1.
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
多层感知机的简洁实现
我们可以通过高级API更简洁地实现多层感知机。
import torch
from torch import nn
from d2l import torch as d2l
模型
与softmax回归的简洁实现相比, 唯一的区别是我们添加了2个全连接层(之前我们只添加了1个全连接层)。 第一层是隐藏层,它包含256个隐藏单元,并使用了ReLU激活函数。 第二层是输出层。
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
训练过程的实现与我们实现softmax回归时完全相同, 这种模块化设计使我们能够将与和模型架构有关的内容独立出来。
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
- MLP(multi layer perceptron)(多层感知机) 效果要是不好,可以转卷积、RNN、transformer
- 如果转SVM(支持向量机)的话调的东西会要多一点
QA
-
神经网络中的一层网络指什么?
所谓的一层,一般来说就是权重、加上激活函数和你的计算
可以简记为有几层权重W,就有多少层
输入层不算层 -
SVM和MLP
SVM对于超参数不敏感,优化调起来会容易一点
多层感知机和SVM效果差不多
SVM数学表达式很优美
MLP容易改成其他神经网络
3.神经网络为什么要增加隐藏层的层数,而不是神经元的个数?
理论上,模型大小差不多
右边叫深度学习,好训练
左边叫浅度学习(宽度学习),容易过拟合
不能一口吃成一个胖子!
这块李宏毅老师讲得特别好