PyTorch注意力机制【动手学深度学习v2】
文章目录
- 1.注意力机制
-
- 1.1 注意力机制
-
- 1.1.1 非参注意力池化层
- 1.1.2 Nadaraya-Watson核回归
- 1.1.3 参数化的注意力机制
- 1.1.4 注意力汇聚:Nadaraya-Watson核回归的代码实现
- 2 注意力分数
-
- 2.1 加性注意力
- 2.2 缩放点积注意力
- 2.3 注意力打分函数代码实现
- 3 使用注意力机制的seq2seq
- 4 多头注意力
- 5 自注意力
-
- 5.1 比较卷积神经网络、循环神经网络和自注意力
- 5.2 位置编码
-
- 5.2.1 绝对位置信息
- 5.2.2 相对位置信息
1.注意力机制
生物上的注意力机制
- 动物需要 复杂环境下有效关注值得注意的点
- 心理学框架:人类根据随意线索和不随意线索选择注意点
举个例子:
假如你面前有五个物品: 一份报纸、一篇研究论文、一杯咖啡、一本笔记本和一本书, 所有纸制品都是黑白印刷的,但咖啡杯是红色的。 换句话说,这个咖啡杯在这种视觉环境中是突出和显眼的, 不由自主地引起人们的注意。 所以你把视力最敏锐的地方放到咖啡上, 下图。
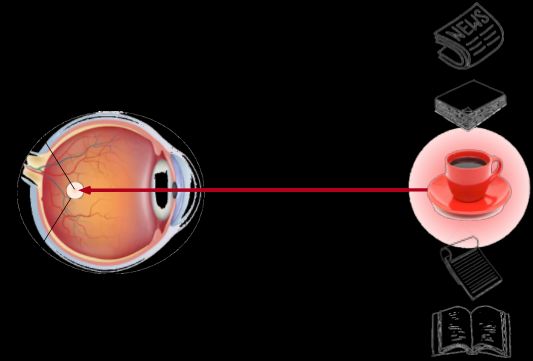
由于突出性的非自主性提示的红杯子,被称为不随意线索。
喝咖啡后,你会变得兴奋并想读书。 所以你转过头,重新聚焦你的眼睛,然后看看书, 就像下图描述那样。 与上图中由于突出性导致的选择不同, 此时选择书是受到了认知和意识的控制, 因此注意力在基于自主性提示去辅助选择时将更为谨慎。 受试者的主观意愿推动,选择的力量也就更强大。
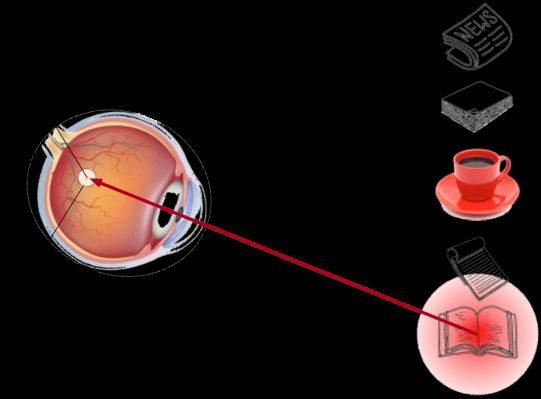
依赖于任务的意志提示(想读一本书),注意力被自主引导到书上,因此书被称为随意线索。
1.1 注意力机制
- 卷积、全连接、池化层都只考虑不随意线索
- 注意力机制则显示的考虑随意线索
- 随意线索被称之为查询(query),结合之前内容,query就是想读书。
- 每个输入是一个值(value)和不随意线索(key)的对,结合前面,key就是红色的杯子,value可以一样也可以不同,红色杯子的value可以是杯子的价值,或杯子的重量等。
- 通过注意力池化层来有偏向性的选择选择某些输入
- 注意力机制也可以叫注意力池化(attention pooling),会根据query有偏向性的选择某些key-value pair。总结注意力池化(attention pooling)和之前的池化(pooling)不一样的地方是:attention显示地加入了query,即“随意线索”,然后根据query去找到感兴趣的key-value pair。
因此,“是否包含自主性提示”将注意力机制与全连接层或汇聚层区别开来。 在注意力机制的背景下,我们将自主性提示称为查询(query)。 给定任何查询,注意力机制通过注意力汇聚(attention pooling) 将选择引导至感官输入(sensory inputs,例如中间特征表示)。 在注意力机制中,这些感官输入被称为值(value)。 更通俗的解释,每个值都与一个键(key)配对, 这可以想象为感官输入的非自主提示。 如下图所示,我们可以设计注意力汇聚, 以便给定的查询(自主性提示)可以与键(非自主性提示)进行匹配, 这将引导得出最匹配的值(感官输入)。

1.1.1 非参注意力池化层
- 给定数据 ( x i , y i ) , i = 1 , . . . , n (x_i,y_i),i=1,...,n (xi,yi),i=1,...,n
- 平均池化是最简单的方案: f ( x ) = 1 n ∑ i y i f(x) = \frac{1}{n} \sum_{i} y_i f(x)=n1∑iyi
- 更好的方案是60年代提出的Nadaraya-Watson核回归 f ( x ) = ∑ i = 1 n K ( x − x i ) ∑ j = 1 n K ( x − x j ) y i (①) f(x)=\sum^n_{i=1}\frac{K(x-x_i)}{\sum^n_{j=1}K(x-x_j)}y_i \tag{①} f(x)=i=1∑n∑j=1nK(x−xj)K(x−xi)yi(①)
其中,
x x x是query;
x i x_{i} xi是key;
y i y_i yi是value;
K是衡量 x x x和 x i x_{i} xi之间距离的一个函数(kernel),比如K值越大距离就越近,越小就距离越远;
公式中的分式,就是概率,每一项是一个相对重要性。对这项加权对 y i y_{i} yi求和,意思是将和x相近那些的 x i x_{i} xi和 y i y_{i} yi选出来。可以这么理解,找出和query相近的key-value pair,别的就不管了。
1.1.2 Nadaraya-Watson核回归
- 使用高斯核 K ( u ) = 1 2 π exp ( − u 2 2 ) K(u)=\frac{1}{\sqrt{2\pi}}\exp(-\frac{u^2}{2}) K(u)=2π1exp(−2u2)
- 那么 f ( x ) = ∑ i = 1 n exp ( − 1 2 ( x − x i ) 2 ) ∑ j = 1 n exp ( − 1 2 ( x − x i ) 2 ) y i = ∑ i = 1 n s o f t m a x ( − 1 2 ( x − x i ) 2 ) y i (②) f(x) = \sum^n_{i=1}\frac{\exp(-\frac{1}{2}(x-x_i)^2)}{\sum^n_{j=1}\exp(-\frac{1}{2}(x-x_i)^2)}y_i = \sum^n_{i=1} softmax(-\frac{1}{2}(x-x_i)^2)y_i \tag{②} f(x)=i=1∑n∑j=1nexp(−21(x−xi)2)exp(−21(x−xi)2)yi=i=1∑nsoftmax(−21(x−xi)2)yi(②)
1.1.3 参数化的注意力机制
- 在之前的基础上引入可以学习的w f ( x ) = ∑ i = 1 n s o f t m a x ( − 1 2 ( ( x − x i ) w ) 2 ) y i (③) f(x) = \sum^n_{i=1} softmax(-\frac{1}{2}((x-x_i)w)^2)y_i \tag{③} f(x)=i=1∑nsoftmax(−21((x−xi)w)2)yi(③)
w是一元的,因为是标量而不是向量
1.1.4 注意力汇聚:Nadaraya-Watson核回归的代码实现
- 生成数据集:
非线性函数生成一个人工数据集,其中加入噪声 ϵ \epsilon ϵ
y i = 2 s i n ( x i ) + x i 0.8 + ϵ y_i = 2sin(x_i) + x_i^{0.8} + \epsilon yi=2sin(xi)+xi0.8+ϵ
其中 ϵ \epsilon ϵ服从均值为和标准差为的正态分布。生成了个50训练样本和50个测试样本。
import torch
from torch import nn
from d2l import torch as d2l
n_train = 50 # 训练样本数
x_train, _ = torch.sort(torch.rand(n_train) * 5) # 排序后的训练样本
def f(x):
return 2 * torch.sin(x) + x**0.8
y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 训练样本的输出
x_test = torch.arange(0, 5, 0.1) # 测试样本
y_truth = f(x_test) # 测试样本的真实输出
n_test = len(x_test) # 测试样本数
n_test
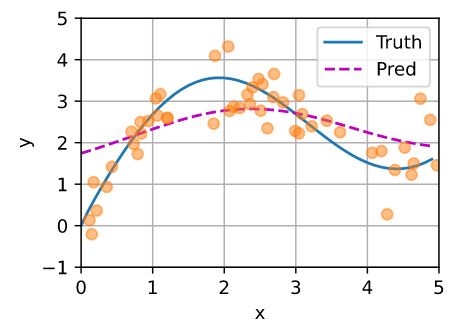
- 使用平均汇聚计算所有训练样本输出值的平均值
def plot_kernel_reg(y_hat):
d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'],
xlim=[0, 5], ylim=[-1, 5])
d2l.plt.plot(x_train, y_train, 'o', alpha=0.5);
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
plot_kernel_reg(y_hat)

- 非参数注意力汇聚(池化)
平均汇聚忽略了输入 x i x_i xi,非参数注意力汇聚使用公式①或②对输出 y i y_i yi进行加权,K函数是描述输入 x i x_i xi与查询 x x x距离的函数,为了使距离越大K函数的值越小,K函数采用以下函数:
K ( u ) = 1 2 π exp ( − u 2 2 ) = 1 2 π exp ( − 1 2 ( x − x i ) 2 ) K(u) = \frac{1}{\sqrt{2\pi}}\exp(-\frac{u^2}{2}) = \frac{1}{\sqrt{2\pi}}\exp(-\frac{1}{2}(x-x_i)^2) K(u)=2π1exp(−2u2)=2π1exp(−21(x−xi)2)
将K函数代入公式①中,得到公式②即:
f ( x ) = ∑ i = 1 n exp ( − 1 2 ( x − x i ) 2 ) ∑ j = 1 n exp ( − 1 2 ( x − x i ) 2 ) y i = ∑ i = 1 n s o f t m a x ( − 1 2 ( x − x i ) 2 ) y i f(x) = \sum^n_{i=1}\frac{\exp(-\frac{1}{2}(x-x_i)^2)}{\sum^n_{j=1}\exp(-\frac{1}{2}(x-x_i)^2)}y_i = \sum^n_{i=1} softmax(-\frac{1}{2}(x-x_i)^2)y_i f(x)=i=1∑n∑j=1nexp(−21(x−xi)2)exp(−21(x−xi)2)yi=i=1∑nsoftmax(−21(x−xi)2)yi
由公式可知,键(key)的值 x i x_i xi越接近查询(query) x x x,K值越大,即分配给这个键(key) x i x_i xi的对应值(value) y i y_i yi的权重越大,值(value)的权重越大,因此获得了更多的注意力。
# X_repeat的形状:(n_test,n_train),
# 每一行都包含着相同的测试输入(例如:同样的查询)
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
# x_train包含着键。attention_weights的形状:(n_test,n_train),
# 每一行都包含着要在给定的每个查询的值(y_train)之间分配的注意力权重
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1)
# y_hat的每个元素都是值的加权平均值,其中的权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
plot_kernel_reg(y_hat)
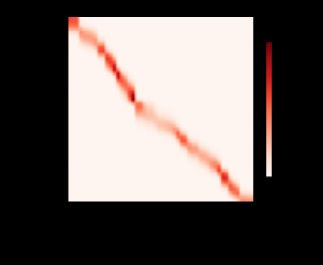
现在来观察注意力的权重。 这里测试数据的输入相当于查询,而训练数据的输入相当于键。 因为两个输入都是经过排序的,因此由观察可知“查询-键”对越接近, 注意力汇聚的注意力权重就越高。
d2l.show_heatmaps(attention_weights.unsqueeze(0).unsqueeze(0),
xlabel='Sorted training inputs',
ylabel='Sorted testing inputs')

- 带参数的注意力汇聚
非参数的Nadaraya-Watson核回归具有一致性(consistency)的优点: 如果有足够的数据,此模型会收敛到最优结果。 尽管如此,我们还是可以轻松地将可学习的参数集成到注意力汇聚中。为了更有效地计算小批量数据的注意力,通过训练这个带参数的注意力汇聚模型③来学习注意力汇聚的参数。
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
# queries和attention_weights的形状为(查询个数,“键-值”对个数)
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
self.attention_weights = nn.functional.softmax(
-((queries - keys) * self.w)**2 / 2, dim=1)
# values的形状为(查询个数,“键-值”对个数)
return torch.bmm(self.attention_weights.unsqueeze(1),
values.unsqueeze(-1)).reshape(-1)
# X_tile的形状:(n_train,n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
# Y_tile的形状:(n_train,n_train),每一行都包含着相同的训练输出
Y_tile = y_train.repeat((n_train, 1))
# keys的形状:('n_train','n_train'-1)
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
# values的形状:('n_train','n_train'-1)
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5])
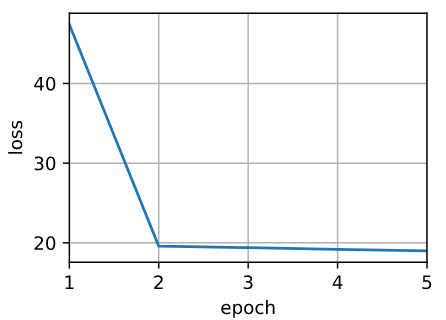
for epoch in range(5):
trainer.zero_grad()
l = loss(net(x_train, keys, values), y_train)
l.sum().backward()
trainer.step()
print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')
animator.add(epoch + 1, float(l.sum()))
# keys的形状:(n_test,n_train),每一行包含着相同的训练输入(例如,相同的键)
keys = x_train.repeat((n_test, 1))
# value的形状:(n_test,n_train)
values = y_train.repeat((n_test, 1))
y_hat = net(x_test, keys, values).unsqueeze(1).detach()
plot_kernel_reg(y_hat)

在尝试拟合带噪声的训练数据时, 预测结果绘制的线不如之前非参数模型的平滑。与非参数的注意力汇聚模型相比, 带参数的模型加入可学习的参数后, 曲线在注意力权重较大的区域变得更不平滑。
d2l.show_heatmaps(net.attention_weights.unsqueeze(0).unsqueeze(0),
xlabel='Sorted training inputs',
ylabel='Sorted testing inputs')
2 注意力分数
在注意力汇聚中,使用[高斯核](# 1.1.2 Nadaraya-Watson核回归)来对查询和键之间的关系建模,高斯核的指数部分为注意力评分函数(Attention scoring function),简称评分函数,然后将这个函数的输出结果输入到softmax函数中进行运算,得到与键对应的值的概率分布(即注意力权重)。最后注意力汇聚的输出就是基于这些注意力权重的值的加权和。
公式②中评分函数为 a ( q , k i ) = a ( x , x i ) = − 1 2 ( x − x i ) 2 a(q,k_i) = a(x,x_i) = -\frac{1}{2}(x-x_i)^2 a(q,ki)=a(x,xi)=−21(x−xi)2
图①的注意力汇聚内部细节如下图所示。
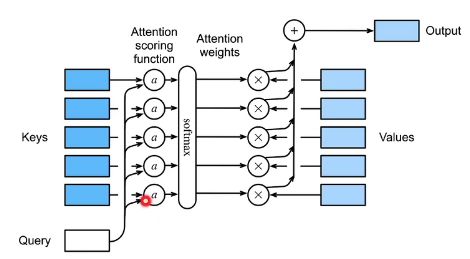
假设有一个查询q和m个键值对 ( k 1 , v 1 ) , . . . , ( k m , v m ) (k_1,v_1),...,(k_m,v_m) (k1,v1),...,(km,vm)。注意力汇聚函数 f f f被表示成值(value)的加权和:
f ( q , ( k 1 , v 1 ) , . . . , ( k m , v m ) ) = ∑ i = 1 m α ( q , k i ) v i f(q,(k_1,v_1),...,(k_m,v_m)) = \sum^{m}_{i=1}\alpha(q,k_i)v_i f(q,(k1,v1),...,(km,vm))=i=1∑mα(q,ki)vi
注意力评分函数 a a a将 q q q和 k i k_i ki两个向量映射成标量,通过softmax得到注意力权重 α ( q , k i ) \alpha(q,k_i) α(q,ki)。
α ( q , k i ) = s o f t m a x ( a ( q , k i ) ) = e x p ( a ( q , k i ) ) ∑ j = 1 m e x p ( a ( q , k j ) ) \alpha(q,k_i) = softmax(a(q,k_i)) = \frac{exp(a(q,k_i))}{\sum^m_{j=1}exp(a(q,k_j))} α(q,ki)=softmax(a(q,ki))=∑j=1mexp(a(q,kj))exp(a(q,ki))
不同的注意力评分函数a会导致不同的注意力汇聚操作,如加性注意力(additivie attention)和缩放点积注意力(Scale Dot-Product Attention)。
2.1 加性注意力
当查询和键的长度是不同长度的矢量时使用加性注意力作为评分函数,加性注意力机制(additivie attention)的评分函数为:
a ( q , k ) = w v T tanh ( W q q + W k k ) a(\bf{q,k}) = \bf{w}^T_{v} \tanh{(W_qq + W_kk)} a(q,k)=wvTtanh(Wqq+Wkk)
其中 W q ∈ R h × q , W k ∈ R h × k , W v ∈ R h W_q \in R^{h\times q},W_k \in R^{h\times k},W_v \in R^{h} Wq∈Rh×q,Wk∈Rh×k,Wv∈Rh是可学习的参数。模型等价于将key和value合并后放入到一个隐藏大小为h输出大小为1的单隐藏层多层感知机(MLP),激活函数是tanh。
2.2 缩放点积注意力
当查询和键的长度是同样的长度,就可以使用点积操作,因为点积需要两个向量具有相同长度,假设这个长度为d。 假设查询和键的所有元素都是独立的随机变量, 并且都满足零均值和单位方差, 那么两个向量的点积的均值为0,方差为d。为了使在任意向量长度下,点积的方差都为1, 将最后的点击除以 d \sqrt{d} d,公式为:
a ( q , k ) = < q , k i > / d a(q,k) =
用向量表示时,
- n为查询数量,m为键值对数量,d为查询和键的长度,值的长度为v
- 当 Q ∈ R n × d , K ∈ R m × d , V ∈ R m × v \bf{Q} \in \bf{R}^{n \times d}, \bf{K} \in \bf{R}^{m \times d}, \bf{V}\in \bf{R}^{m \times v} Q∈Rn×d,K∈Rm×d,V∈Rm×v时,
- 注意力分数 a ( Q , K ) = Q K T / d ∈ R n × m a(Q,K) = QK^T/\sqrt{d} \in \bf{R}^{n \times m} a(Q,K)=QKT/d∈Rn×m,
- 注意力池化 f = s o f t m a x ( a ( Q , K ) ) V ∈ R n × v f = softmax(a(Q,K))V \in \bf{R}^{n\times v} f=softmax(a(Q,K))V∈Rn×v
总的来说
- 注意力分数是查询和键的相似度,注意力权重是分数的softmax结果。
- 两种常见的分数计算:
- 将查询和键合并起来进入一个单输出的单隐藏层的MLP
- 直接将查询和键做点积
2.3 注意力打分函数代码实现
softmax操作用于输出一个概率分布作为注意力权重,在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。在处理文本时,有一些文本序列填充了一些没有意义的特殊词元,为了只将有意义的词元做注意力汇聚,因此引入了masked_softmax,使得在计算Softmax时过滤超出指定范围的词,让超出有效长度的位置都被掩蔽并置为0
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,第一个维度是批量大小,
# valid_lens:1D或2D张量,表示一个序列的有效长度
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
# X:两个2x4矩阵表示的样本,valid_lens:每一个批量的有效长度分别为2和3
masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))
# 二维张量时,可以具体到指定每一行的有效长度
masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))
经过掩蔽softmax操作,超出有效长度的值都被掩蔽为0。每一行相加为1。
tensor([[[0.6090, 0.3910, 0.0000, 0.0000],
[0.3773, 0.6227, 0.0000, 0.0000]],
[[0.2018, 0.4158, 0.3824, 0.0000],
[0.3291, 0.4351, 0.2358, 0.0000]]])
tensor([[[1.0000, 0.0000, 0.0000, 0.0000],
[0.2598, 0.4734, 0.2669, 0.0000]],
[[0.3285, 0.6715, 0.0000, 0.0000],
[0.3421, 0.2215, 0.1667, 0.2698]]])
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys) #(queries~[2, 1, 8],keys~[2, 10, 8])
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden) (queries~[2,1,1,8])
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens) (key~[2,1,10,8])
# 使用广播方式进行求和
features = queries.unsqueeze(2) + keys.unsqueeze(1) # features~[2, 1, 10, 8]
features = torch.tanh(features) #[2, 1, 10, 8]
# self.w_v仅有一个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数) (scores ~ [2, 1, 10])
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens) # (attention_weights~[2,1,10])
# values的形状:(batch_size,“键-值”对的个数,值的维度) 【[2, 1, 10]bmm[2, 10, 4] = [2, 1, 4]】
return torch.bmm(self.dropout(self.attention_weights), values)
# query批量大小为2,一个query,query长度是20,key批量大小是2,10个键,一个key长度为2
# (queries~[2, 1, 20],keys~[2, 10, 2]|[批量大小,步数或词元序列长度,特征大小])
queries, keys = np.random.normal(0, 1, (2, 1, 20)), np.ones((2, 10, 2))
# values的小批量数据集中,两个值矩阵是相同的。10个value,value的长度是4 (values~[2, 10, 4])
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
# 有效长度,第一个样本查query时查前两个key-value pair,第二个样本查query时查前六个key-value pair
valid_lens = torch.tensor([2, 6])
attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,
dropout=0.1)
attention.eval()
attention(queries, keys, values, valid_lens) # [2, 1, 4]
注意力汇聚输出[批量大小,查询的步数,值的维度]
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=)
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')
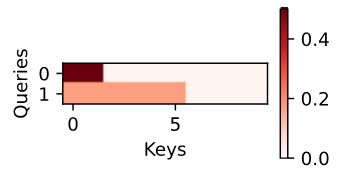
由于value相同,所以权重相等。
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
queries = torch.normal(0, 1, (2, 1, 2))
attention = DotProductAttention(dropout=0.5)
attention.eval()
attention(queries, keys, values, valid_lens)
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]])
3 使用注意力机制的seq2seq
机器翻译中,每个生成的词可能相关于源句子中不同的词。seq2seq模型不能对注意力直接建模。

在seq2seq中,解码器的上下文是编码器RNN在最后一个时刻的输出,上下文与embedding并在一起传到解码器。现在说用编码器最后一个时刻作为context传进解码器不能到达理想效果,应该需要根据现在值的不一样去选择编码端的一个时刻,而不是最后一个时刻。比如说在解码端翻译hello时,不应该把最后一个时刻的句号的state传到解码端bonjour,而是应该用hello的时刻的state(隐藏状态输出)作为context(上下文)再加上的embedding作为输入。同样的在解码端翻译le时,应该用world的隐藏状态输出和bonjour的embedding。
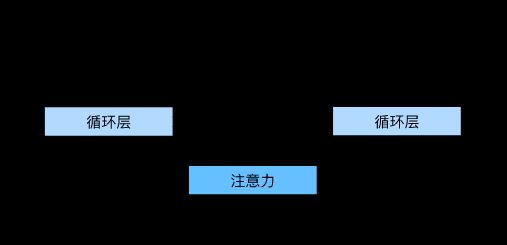
- 编码器对每个词的输出作为key和value
- 解码器RNN对上一个词的输出是query
- 注意力的输出和下一个词的词嵌入合并进入
假设输入序列有T个词元,解码时间步 t ′ t' t′的上下文变量是注意力集中的输出:
c t ′ = ∑ t = 1 T α ( s t ′ − 1 , h t ) h t c_{t'} = \sum^T_{t=1} \alpha(s_{t'-1},h_t)h_t ct′=t=1∑Tα(st′−1,ht)ht
其中,时间步t’-1时的解码器隐状态 s t ′ − 1 s_{t'-1} st′−1是查询,编码器隐状态 h t h_t ht即是键,也是值,注意力权重 α \alpha α是使用加性注意力打分函数计算的。
带有注意力机制的解码器
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# query的形状为(batch_size,1,num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# context的形状为(batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# 将x变形为(1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
4 多头注意力
用独立学习得到的h组不同的线性投影(linear projections)(可以理解为全连接层)来变换查询、键和值。 然后,这h组变换后的查询、键和值将并行地送到注意力汇聚(f函数)中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影(全连接层)进行变换, 以产生最终输出。 这种设计被称为多头注意力(multihead attention)。 对于个注意力汇聚输出,每一个注意力汇聚都被称作一个头(head)。 下图展示了使用全连接层来实现可学习的线性变换的多头注意力。
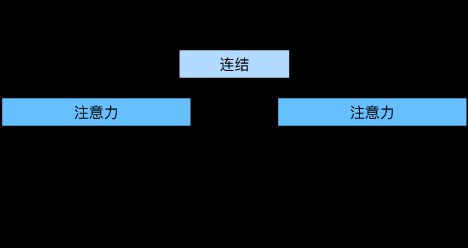
给定查询 q ∈ R d q q \in \bf{R}^{d_q} q∈Rdq,键 k ∈ R d k k \in \bf{R}^{d_k} k∈Rdk,值 v ∈ R d v v \in \bf{R}^{d_v} v∈Rdv,每个注意力头 h i ( i = 1 , 2 , . . . , h ) h_i(i = 1,2,...,h) hi(i=1,2,...,h)的计算方法为:
h i = f ( W i ( q ) q , W i ( k ) k , W i ( v ) v ) ∈ R p v h_i= f(W^{(q)}_iq,W^{(k)}_ik,W^{(v)}_iv) \in \bf{R}^{p_v} hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv
f可以是加性注意力和缩放点积注意力。 多头注意力的输出需要经过另一个线性转换, 它对应着h个头连结后的结果,因此其可学习参数是
W o [ h 1 h 2 . . . h h ] ∈ R p o W_o\left[ \begin{array}{c} h_1 \\ h_2 \\ ... \\ h_h \end{array} \right] \in \bf{R_{po}} Wo⎣⎢⎢⎡h1h2...hh⎦⎥⎥⎤∈Rpo
多头注意力的每个头都可能会关注输入的不同部分, 可以表示比简单加权平均值更复杂的函数。
import math
import torch
from torch import nn
from d2l import torch as d2l
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
class MultiHeadAttention(nn.Module):
"""多头注意力:使用缩放点积注意力作为每一个注意力头"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
```[2,4,100],[2,6,100],[2,6,100],[3,2]```
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads) #[10,4,20]
keys = transpose_qkv(self.W_k(keys), self.num_heads) # [10,6,20]
values = transpose_qkv(self.W_v(values), self.num_heads) #[10,6,20]
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens) #[10,4,20]
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads) # [2,4,100]
return self.W_o(output_concat)
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens)) #[2,4,100]
Y = torch.ones((batch_size, num_kvpairs, num_hiddens)) #[2,6,100]
attention(X, Y, Y, valid_lens).shape #[2,4,100]
MultiHeadAttention(
(attention): DotProductAttention(
(dropout): Dropout(p=0.5, inplace=False)
)
(W_q): Linear(in_features=100, out_features=100, bias=False)
(W_k): Linear(in_features=100, out_features=100, bias=False)
(W_v): Linear(in_features=100, out_features=100, bias=False)
(W_o): Linear(in_features=100, out_features=100, bias=False)
)
torch.Size([2, 4, 100])
多头注意力融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。基于适当的张量操作,可以实现多头注意力的并行计算。
5 自注意力
- 给定序列 x 1 , . . . , x n x_1,...,x_n x1,...,xn
- 自注意力池化层将 x i x_i xi都当做key,value,query来对序列抽取特征得到 y 1 , . . . , y n y_1,...,y_n y1,...,yn
y i = f ( x i , ( x 1 , x 1 ) , ( x 2 , x 2 ) , . . . , ( x n , x n ) ) y_i = f(x_i,(x_1,x_1),(x_2,x_2),...,(x_n,x_n)) yi=f(xi,(x1,x1),(x2,x2),...,(xn,xn))
num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
# 与上面所有注意力不同的是,自注意力查询,键,值都是X,都是自己本身,因此叫做自注意力
attention(X, X, X, valid_lens).shape
torch.Size([2, 4, 100])
5.1 比较卷积神经网络、循环神经网络和自注意力
| CNN | RNN | 自注意力 | |
|---|---|---|---|
| 计算复杂度 | O ( k n d 2 ) O(knd^2) O(knd2) | O ( n d 2 ) O(nd^2) O(nd2) | O ( n 2 d ) O(n^2d) O(n2d) |
| 并行度 | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) | O ( n ) O(n) O(n) |
| 最长路径 | O ( n k ) O(\frac{n}{k}) O(kn) | O ( n ) O(n) O(n) | O ( 1 ) O(1) O(1) |
5.2 位置编码
- 跟CNN/RNN不同,自注意力因为并行计算放弃了记录位置信息。假设没有位置编码,输入的序列位置打乱之后,对输出的内容没有影响。因此在自注意力机制的输入加入位置编码,当输入位置打乱后,输出内容也会随之变化,序列的顺序信息得到利用。
- 位置编码将位置信息注入到输入里
- 假设长度为n的序列是 X ∈ R n × d X \in \bf{R}^{n \times d} X∈Rn×d,那么使用位置编码矩阵 P ∈ R n × d P \in \bf{R}^{n \times d} P∈Rn×d来输出 X + P X + P X+P作为自编码输入
- 当使用基于正弦函数和余弦函数的固定位置编码时,矩阵第 i i i行、第 2 j 2j 2j列和 2 j + 1 2j+1 2j+1列上的元素为:
p i , 2 j = s i n ( i 1000 0 2 j / d ) , p i , 2 j + 1 = c o s ( i 1000 0 2 j / d ) \bf{p_{i,2j} = sin(\frac{i}{10000^{2j/d}}),p_{i,2j+1} = cos(\frac{i}{10000^{2j/d}})} pi,2j=sin(100002j/di),pi,2j+1=cos(100002j/di)
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P(batch_size, max_len, num_hiddens)与taken embedding的长度一样
self.P = torch.zeros((1, max_len, num_hiddens))
X = torch.arange(max_len, dtype=torch.float32).reshape(-1, 1) / torch.pow(10000, torch.arange(0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
self.P[:, :, 0::2] = torch.sin(X) # 偶数位赋值为sinx
self.P[:, :, 1::2] = torch.cos(X) # 奇数位赋值为cosx
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
return self.dropout(X) # 加入dropout是为了避免模型对P过于敏感
# d=32,h=60
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)',
figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])
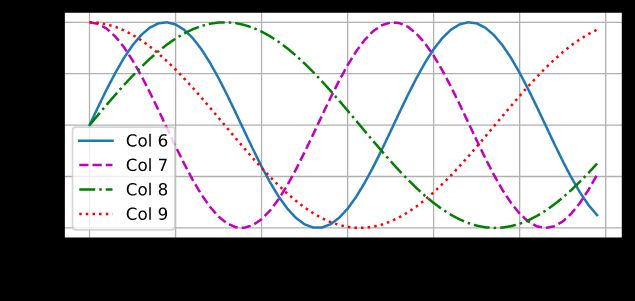
如图第6列是sin,第7列是cos,第6,7列频率不变,但是发生了相移。第8,9列周期变长。因此每个样本可以加不同的数值作为位置信息,如第20个样本加上ROW=20的Col,第21个样本加上ROW=21的Col,让模型分辨这些细微的数值变化,这些细微的数值变化可以作为不同的位置变化,从而让模型分辨不同的位置信息。这种记录位置的方法与CNN等其他模型位置与样本分开的机制不同,自注意力将样本与位置相加来融合位置信息。
5.2.1 绝对位置信息
编码维度单调降低的频率与绝对位置信息的关系可以简单看做二进制的表示原理。
0的二进制是:000
1的二进制是:001
2的二进制是:010
3的二进制是:011
4的二进制是:100
5的二进制是:101
6的二进制是:110
7的二进制是:111
如上面二进制表示中,最低位的变化频率是1,第二位的变化频率是1/2,最高位的变化频率是1/4,因此仅仅用3位可以表示8个不同的数字。与上图位置编码中…,col6,col7,col8,col9,…的采用不同频率的sin和cos的思想是一致的。
5.2.2 相对位置信息
假设矩阵第 i i i行、第 2 j 2j 2j列和 2 j + 1 2j+1 2j+1列上的元素 ( p i , 2 j , p i , 2 j + 1 ) (p_{i,2j},p_{i,2j+1}) (pi,2j,pi,2j+1)为
p i , 2 j = s i n ( i 1000 0 2 j / d ) , p i , 2 j + 1 = c o s ( i 1000 0 2 j / d ) \bf{p_{i,2j} = sin(\frac{i}{10000^{2j/d}}),p_{i,2j+1} = cos(\frac{i}{10000^{2j/d}})} pi,2j=sin(100002j/di),pi,2j+1=cos(100002j/di)
则偏移 δ \delta δ后 p i + δ , 2 j , p i + δ , 2 j + 1 p_{i+\delta,2j},p_{i+\delta,2j+1} pi+δ,2j,pi+δ,2j+1的元素可以变换为:
