OpenCV(五)停车场的车位识别
一、标题
在一段停车场,车辆来往的视频中实时检测出:
- 有多少个停车位被占据了,有多少是空着的;
- 哪个被占,哪个是空的。
视频中的一些截图
二、思路
视频是由一帧一帧的图像构成的,对视频的处理就是对图像的处理。
第一步就是用测试图像找出每个停车位的坐标位置(不管是有车的还是没车的);
第二步是用测试图像,检测空车位的位置,可视化。
第三步是处理视频,将视频以一帧一帧的形式交给神经网络处理,以视频流的形式输出。
三、分步实现:
第一步:处理图像:
- 首先对图像进行过滤,除去背景,剩下实物的大致轮廓A。
- 对A进行灰度化,边缘检测,提取出停车场的大致轮廓B。
- 对B进行霍夫检测,检测出其中的直线(车位之间的分割线)。
- 在画好线的图像中进行分割,分割出每一个停车位,给每一个停车位编号。
- 对每个车位的方框,裁剪下来保存,作为测试和训练神经网络的样本。
处理测试图像
将图像过滤背景,留下物体的大致轮廓。
def select_rgb_white_yellow(self,image):
#过滤掉背景
lower = np.uint8([120,120,120])
upper = np.uint8([255,255,255])
# lower_red和高于upper_red的部分分别变成0,lower_red~upper_red之间的值变成255,相当于过滤背景
# 一般来说传入三个参数:原图像,最低阈值,最高阈值
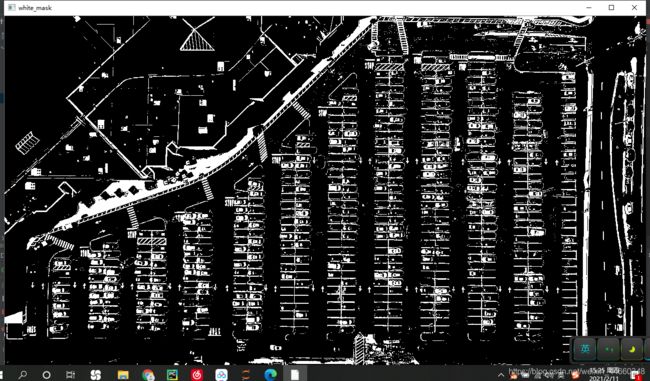
white_mask = cv2.inRange(image,lower,upper) #有点像掩模的意思
self.cv_show('white_mask',white_mask)
masked = cv2.bitwise_and(image,image,mask=white_mask) #进行与操作
self.cv_show('masked',masked)
return masked
结果图:
灰度化、边缘检测
def convert_gray_scale(self,image): #做灰度图
return cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
def detect_edges(self,image,low_threshold=50,high_threshold=200): #边缘检测
return cv2.Canny(image,low_threshold,high_threshold)
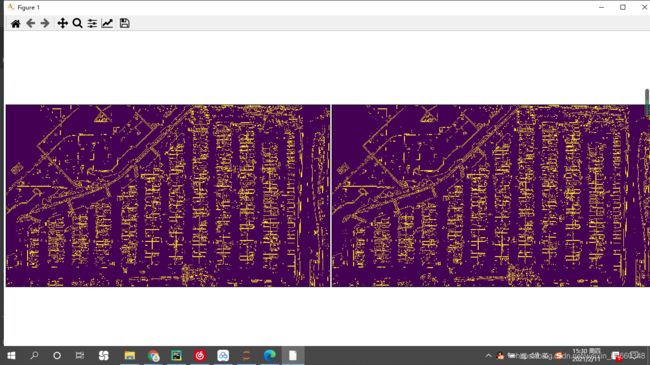
灰度化:(我也不知道为什么变成这个鬼颜色,没看到哪里错了)

边缘检测:
提取出停车场的轮廓,这里指定几个能包住停车场的点,制作掩模,与原图做与操作,提取出图像内的轮廓。
def select_region(self,image):
rows,cols = image.shape[:2]
#我们手动制作几个能够将停车场轮廓大致围起来的点
pt_1 = [cols * 0.05, rows * 0.90]
pt_2 = [cols * 0.05, rows * 0.70]
pt_3 = [cols * 0.30, rows * 0.55]
pt_4 = [cols * 0.60, rows * 0.15]
pt_5 = [cols * 0.90, rows * 0.15]
pt_6 = [cols * 0.90, rows * 0.90]
vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32)
point_img = image.copy()
point_img = cv2.cvtColor(point_img, cv2.COLOR_GRAY2RGB)
# 在图像上画线最好不要在灰度图上操作,所以我们将之转换为RGB的彩色图(在复制图片上面操作)
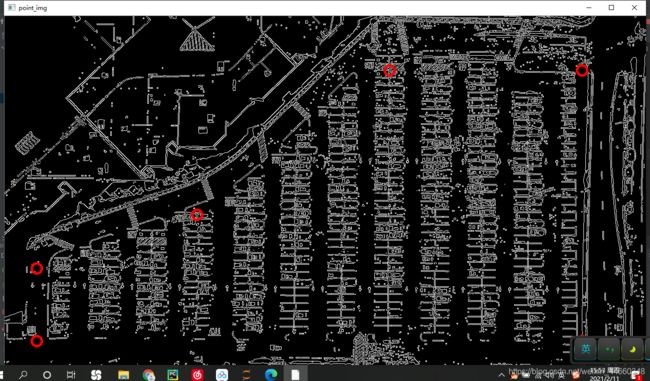
for point in vertices[0]:
cv2.circle(point_img,(point[0],point[1]),10,(0,0,255),4)
# 画图函数,需要传入原始图像,坐标点(元组格式),——————,颜色,粗细
self.cv_show('point_img',point_img)
# filter是将框好的部分过滤出来,传入图像与定点
return self.filter_region(image,vertices)
def filter_region(self,image,vertices): #提取出我需要的部分:停车场的轮廓
#image为原图像,vertices为传入的顶点
mask = np.zeros_like(image)
if len(mask.shape)==2:
cv2.fillPoly(mask,vertices,255) #基于传入的顶点,围成一个区域,全部填充为255(白色)
self.cv_show('mask',mask)
return cv2.bitwise_and(image,mask)
挑选出的点,包住停车场

cv2.fillPoly(mask,vertices,255)
基于传入的顶点,围成一个区域,全部填充为255(白色)
mask:原图像
vertices:需要描的点
255:填充的灰度值
提取出停车场的部分

做基于霍夫变换的直线检测,检测出输入图像中的直线
def hough_lines(self,image):
# 输入的图像需要是边缘检测后的结果!!!
# minLineLengh(线的最短长度,比这个短的都被忽略)和MaxLineCap(两条直线之间的最大间隔,小于此值,认为是一条直线)
# rho距离精度,theta角度精度(这两个精度越小越精确),threshod超过设定阈值才被检测出线段
# 原本是HoughLines(),变成HoughLinesP的话更快了
return cv2.HoughLinesP(image,rho=0.1,theta=np.pi/10,threshold=15,minLineLength=9,maxLineGap=4)

将提取出的图像经过筛选,在图像中画出。
一条直线保存的形式为首尾两个坐标点,我们比较长度以及倾斜程度,判断这条直线是否为停车位的线。
def draw_lines(self,image,lines,color=[255,0,0],thickness=2,make_copy=True):
#对霍夫检测出的线段进行筛选并且在原图中画出
if make_copy:
image = np.copy(image)
cleaned = [] #对线段进行过滤,并在图像中画出,cleaned是过滤后的线段
for line in lines:
for x1,y1,x2,y2 in line:#一条线是由(x1,y1)与(x2,y2)组成的
if abs(y2-y1)<=1 and abs(x2-x1)>=25 and abs(x1-x1)<=55:
# (y2-y1)测量倾斜程度,停车线肯定是直线或者倾斜程度很小的线
# (x2-x1)衡量水平距离,若水平距离过长或过短,则也不是停车线
cleaned.append((x1,y1,x2,y2))
cv2.line(image,(x1,y1),(x2,y2),color,thickness)
print("总共的线段数为:",len(cleaned))
return image
结果:(画的稀烂,哈哈)
在画好线的图像中进行每一列车道的划分,框柱每一列车道。
- 首先对直线进行过滤。(传入的是没有被过滤的直线列表)
- 对直线按照x1的值进行排序,结果中每一列直线是排在一起的。
- 为每个列分配一个簇,将处于同一列的直线放在一个簇中。这里的方法是取两个相邻的直线出来,他们的x1值相减,若小于设定值,就说明属于同一个簇i的。否则就是不同簇的,并且后面的直线也不是簇i的。(因为同一簇的直线在集合很中是排在一起的)
- 取出每一簇中的所有直线,计算出x1与x2的平均值以及y1(纵坐标最大值)y2(纵坐标的最小值)形成方框形状的集合,在图像中画出每一列车道的方框。
def identify_blocks(self,image,lines,make_copy=True):
if make_copy:
new_image = np.copy(image)
#step1:过滤部分直线
cleaned = []
for line in lines:
for x1,y1,x2,y2 in line:
if abs(y2-y1)<=1 and abs(x2-x1)>=25 and abs(x1-x1)<=55:
cleaned.append((x1,y1,x2,y2))
#step2:对直线按照x1的值进行排序
import operator
list1 = sorted(cleaned,key=operator.itemgetter(0,1))
# 排序的结果是,处于同一列的现在在一起
# Step 3: 找到多个列,相当于每列是一排车
clusters = {}#为每个列分配一个簇
dIndex = 0
clus_dist = 10 #每个簇,或者说,每一列停车道之间的距离为10
for i in range(len(list1)-1):#我需要的是0-10的序列,因为我下面是从i+1开始的(真正的序列是0-11)
distance = abs(list1[i+1][0]-list1[i][0]) #用两个线段内的x1相减,若距离够小就处于同一个簇
if distance <= clus_dist:
if not dIndex in clusters.keys():
clusters[dIndex] = []
clusters[dIndex].append(list1[i])
clusters[dIndex].append(list1[i+1]) #将第i个,第i+1个线段加入第Index号簇中
else:
dIndex += 1#因为已经按照x1是排好序的,所以只要出现大于簇间距的情况肯定就是另外一个簇的点了,簇号加1
# Step 4: 得到坐标
rects = {}
i=0
for key in clusters:
all_list = clusters[key]
cleaned = list(set(all_list)) #将第key号簇的所有线段拿出
if len(cleaned) > 5:#cleaned代表一个簇中的所有线段,若个数大于5,则该簇为一列停车位
cleaned = sorted(cleaned,key=lambda tup:tup[1])#将每一个簇中的所有线段按照y值排序(这个tup只是起个名字)
avg_y1 = cleaned[0][1]#avg_y1为第一个线段的y值,也就是第key个簇中所有y1的最大值
avg_y2 = cleaned[-1][1]#avg_y2为最后一个线段的y值,也就是第key个簇中所有y1的最小值
avg_x1 = 0
avg_x2 = 0
# x的值不好确定,所以我们求一个簇中所有线段的平均
# clean中的元素形式为(x1,y1,x2,y2),tup[0]为x1tup[2]为x2
for tup in cleaned:
avg_x1 += tup[0]
avg_x2 += tup[2]
avg_x1 = avg_x1 / len(cleaned)
avg_x2 = avg_x2 / len(cleaned)
rects[i] = (avg_x1, avg_y1, avg_x2, avg_y2)
i += 1
print("方框的总数,或者说停车道的列数是:",len(rects))
# Step 5: 用之前算出的每个簇的方框的坐标把每一列的矩形画出来
buff = 7 #这个7应该是将每列车道的方框括的范围变大一些
for key in rects:
tup_topLeft = (int(rects[key][0] - buff), int(rects[key][1]))
tup_botRight = (int(rects[key][2] + buff), int(rects[key][3]))
cv2.rectangle(new_image, tup_topLeft, tup_botRight, (0, 255, 0), 3)
return new_image, rects
结果:
将框好的每一列车位按照每一个车位分割。
- 可以看到,上图方框并没有将所有车位框柱,所以我们要进行一些微调。
- 设置一个gap值,代表两条直线之间的距离(其实就是一个停车位的宽度)
- 用方框的长度整除gap值,得到这一列能够放多少个停车位,然后在图中将停车位直线画出
- 注意第一列与最后一列是单列停车位,其他列是双列停车位。在画直线的时候,单列停车道的一个车位只需要画出上下两条直线,双列停车道需要在两个停车位中间画一条竖线。在给停车位进行编号的时候,双列停车位应该给两个车位编号,单列停车道只需要给一个停车位编号。
- 返回效果图以及两张侧视图中每个车位的坐标集合。
def draw_parking(self, image, rects, make_copy=True, color=[255, 0, 0], thickness=2, save=True):
if make_copy:
new_image = np.copy(image)
gap = 15.5 # gap值是每个车位两条线之间的距离
spot_dict = {} # 字典:一个车位对应一个坐标
tot_spots = 0
# 对12列的矩形框的坐标进行微调
adj_y1 = {0: 20, 1: -10, 2: 0, 3: -11, 4: 28, 5: 5, 6: -15, 7: -15, 8: -10, 9: -30, 10: 9, 11: -32}
adj_y2 = {0: 30, 1: 50, 2: 15, 3: 10, 4: -15, 5: 15, 6: 15, 7: -20, 8: 15, 9: 15, 10: 0, 11: 30}
adj_x1 = {0: -8, 1: -15, 2: -15, 3: -15, 4: -15, 5: -15, 6: -15, 7: -15, 8: -10, 9: -10, 10: -10, 11: 0}
adj_x2 = {0: 0, 1: 15, 2: 15, 3: 15, 4: 15, 5: 15, 6: 15, 7: 15, 8: 10, 9: 10, 10: 10, 11: 0}
for key in rects:
tup = rects[key] # tup就是第key个簇的矩形框的两个坐标(x1,y1,x2,y2)
x1 = int(tup[0] + adj_x1[key])
x2 = int(tup[2] + adj_x2[key])
y1 = int(tup[1] + adj_y1[key])
y2 = int(tup[3] + adj_y2[key])
cv2.rectangle(new_image, (x1, y1), (x2, y2), (0, 255, 0), 2)
num_splits = int(abs(y2 - y1) // gap) # num_splits代表这一列一共能停多少辆车
for i in range(0, num_splits + 1): # 设一共能停s辆车,那么我们要画s+1根线才能表示出s个停车位
y = int(y1 + i * gap)
cv2.line(new_image, (x1, y), (x2, y), color, thickness)
if key > 0 and key < len(rects) - 1: # 除去第一组与最后一组,停车位都是两列,所以我们中间要画一根直线
# 竖直线
x = int((x1 + x2) / 2)
cv2.line(new_image, (x, y1), (x, y2), color, thickness)
# 计算数量
if key == 0 or key == (len(rects) - 1):
tot_spots += num_splits + 1 # 第一列和最后一列,是单列停车位
else:
tot_spots += 2 * (num_splits + 1) # 其他列是双列停车位
# tot_spots记录了多少个停车位
# 将字典中每个停车位的键(矩形坐标)值(第几个停车位)
if key == 0 or key == (len(rects) - 1): # 将第一列,最后一列与中间列分开两种情况讨论
for i in range(0, num_splits + 1):
cur_len = len(spot_dict) # 这个操作就是查找字典当前的长度Q,那么Q+1就是当前遍历停车位的值
y = int(y1 + i * gap)
spot_dict[(x1, y, x2, y + gap)] = cur_len + 1
else:
for i in range(0, num_splits + 1):
cur_len = len(spot_dict)
y = int(y1 + i * gap)
x = int((x1 + x2) / 2)
spot_dict[(x1, y, x, y + gap)] = cur_len + 1
spot_dict[(x, y, x2, y + gap)] = cur_len + 2
print("total parking spaces: ", tot_spots, cur_len)
if save:
filename = 'with_parking.jpg'
cv2.imwrite(filename, new_image)
return new_image, spot_dict
结果图:
可以看到第二张图的效果稍微好一些,我们选第二张图作为范本,构造每一个车位的坐标集合。
- 将图二的车位坐标点集合存起来。
- 将每个车位按照车位的坐标在原图中截取下来保存,作为cnn的训练数据。
def save_images_for_cnn(self,image,spot_dict,folder_name='cnn_data'):
for spot in spot_dict.keys():
(x1,y1,x2,y2) = spot
(x1,y1,x2,y2) = (int(x1),int(y1),int(x2),int(y2))
#裁剪
spot_img = image[y1:y2,x1:x2] #这里为什么先传y再传x,因为是按照image.shape的格式传的
sopt_img = cv2.resize(spot_img,(0,0),fx=2.0,fy=2.0) #放大图片
spot_id = spot_dict[spot]
filename = 'spot' + str(spot_id) + '.jpg'
print(spot_img.shape,filename,(x1,y1,x2,y2))
cv2.imwrite(os.path.join(folder_name,filename),spot_img)
用VGG16模型构造神经网络,由训练数据太少,我们冻结前10层,只训练后面几层的参数。
使用图像增强对训练数据和测试数据进行旋转等操作。
import numpy
import os
from keras import applications
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
from keras.models import Sequential, Model
from keras.layers import Dropout, Flatten, Dense, GlobalAveragePooling2D
from keras import backend as k
from keras.callbacks import ModelCheckpoint, LearningRateScheduler, TensorBoard, EarlyStopping
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.initializers import TruncatedNormal
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
files_train = 0
files_validation = 0
cwd = os.getcwd()
folder = 'train_data/train'
for sub_folder in os.listdir(folder):
path, dirs, files = next(os.walk(os.path.join(folder,sub_folder)))
files_train += len(files)
folder = 'train_data/test'
for sub_folder in os.listdir(folder):
path, dirs, files = next(os.walk(os.path.join(folder,sub_folder)))
files_validation += len(files)
print(files_train,files_validation)
img_width, img_height = 48, 48
train_data_dir = "train_data/train"
validation_data_dir = "train_data/test"
nb_train_samples = files_train
nb_validation_samples = files_validation
batch_size = 32
epochs = 5
num_classes = 2
model = applications.VGG16(weights='imagenet', include_top=False, input_shape = (img_width, img_height, 3))
for layer in model.layers[:10]:
layer.trainable = False
x = model.output
x = Flatten()(x)
predictions = Dense(num_classes, activation="softmax")(x)
model_final = Model(input = model.input, output = predictions)
model_final.compile(loss = "categorical_crossentropy",
optimizer = optimizers.SGD(lr=0.0001, momentum=0.9),
metrics=["accuracy"])
train_datagen = ImageDataGenerator(
rescale = 1./255,
horizontal_flip = True,
fill_mode = "nearest",
zoom_range = 0.1,
width_shift_range = 0.1,
height_shift_range=0.1,
rotation_range=5)
test_datagen = ImageDataGenerator(
rescale = 1./255,
horizontal_flip = True,
fill_mode = "nearest",
zoom_range = 0.1,
width_shift_range = 0.1,
height_shift_range=0.1,
rotation_range=5)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size = (img_height, img_width),
batch_size = batch_size,
class_mode = "categorical")
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size = (img_height, img_width),
class_mode = "categorical")
checkpoint = ModelCheckpoint("car1.h5", monitor='val_acc', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1)
early = EarlyStopping(monitor='val_acc', min_delta=0, patience=10, verbose=1, mode='auto')
history_object = model_final.fit_generator(
train_generator,
samples_per_epoch = nb_train_samples,
epochs = epochs,
validation_data = validation_generator,
nb_val_samples = nb_validation_samples,
callbacks = [checkpoint, early])
用神经网络对两张测试图像进行测试。
取出每一个车位的坐标,用神经网络模型进行预测,若结果为空,填充原图中该车位。并且记录空车位与全部车位的数量。
def predict_on_image(self,image, spot_dict , model,class_dictionary,make_copy=True, color = [0, 255, 0], alpha=0.5):
if make_copy:
new_image = np.copy(image)
overlay = np.copy(image)
self.cv_show('new_image', new_image)
cnt_empty = 0
all_spots = 0
for spot in spot_dict.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (48, 48))
label = self.make_prediction(spot_img, model, class_dictionary)
if label == 'empty':
cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
save = False
if save:
filename = 'with_marking.jpg'
cv2.imwrite(filename, new_image)
self.cv_show('new_image', new_image)
return new_image
def make_prediction(self,image,model,class_dictionary):
# 预处理
img = image / 255.
# 转换成4D tensor
image = np.expand_dims(img, axis=0)
# 用训练好的模型进行训练
class_predicted = model.predict(image)
inID = np.argmax(class_predicted[0])
label = class_dictionary[inID]
return label
结果图:
最后,对视频进行处理,将图像一帧一帧的读出,按照处理图像的方法进行处理,最后按照图像流输出。(这里我也搞不太清楚,二刷的时候在来完善)
def predict_on_video(self, video_name, final_spot_dict, model, class_dictionary, ret=True):
cap = cv2.VideoCapture(video_name)
count = 0
while ret:
ret, image = cap.read()
count += 1
if count == 5:
count = 0
new_image = np.copy(image)
overlay = np.copy(image)
cnt_empty = 0
all_spots = 0
color = [0, 255, 0]
alpha = 0.5
for spot in final_spot_dict.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (48, 48))
label = self.make_prediction(spot_img, model, class_dictionary)
if label == 'empty':
cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.imshow('frame', new_image)
if cv2.waitKey(10) & 0xFF == ord('q'): #按q退出
break
cv2.destroyAllWindows()
cap.release()
四、一些函数
set()
set() 函数创建一个无序不重复元素的集合,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等,返回新的集合对象
with open(A,‘b’) as f 将A文件以b的方式打开,命名为f,对f操作就是对文件A操作
- with open(r’filename.txt’) as f:
data_user=pd.read_csv(f) #文件的读操作- with open(‘data.txt’, ‘w’) as f:
f.write(‘hello world’) #文件的写操作
r: 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
rb: 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
r+: 打开一个文件用于读写。文件指针将会放在文件的开头。
rb+:以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
w: 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb: 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
w+: 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+:以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a: 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不- 存在,创建新文件进行写入。
ab: 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+: 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+:以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
file对象的属性
file.read([size]) 将文件数据作为字符串返回,可选参数size控制读取的字节数
file.readlines([size]) 返回文件中行内容的列表,size参数可选
file.write(str) 将字符串写入文件
file.close() 关闭文件
pickle.dump(obj, file, protocol) 将obj中的内容写入file文件
必填参数obj表示将要封装的对象
必填参数file表示obj要写入的文件对象,file必须以二进制可写模式打开,即“wb”
可选参数protocol表示告知pickler使用的协议
**cv2.resize(InputArray src, OutputArray dst, Size, fx, fy, interpolation)
**

#### 缩放到原来的二分之一,输出尺寸格式为(宽,高)
img_test1 = cv.resize(img, (int(y / 2), int(x / 2)))
cv.imshow('resize0', img_test1)
cv.waitKey()
#----------------------------
#### 最近邻插值法缩放,缩放到原来的四分之一
img_test2 = cv.resize(img, (0, 0), fx=0.25, fy=0.25, interpolation=cv.INTER_NEAREST)
cv.imshow('resize1', img_test2)
cv.waitKey()
cv.destroyAllWindows()
#### join()和os.path.join()函数
- join():连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
- os.path.join():将多个路径组合后返回
#### cap = cv2.VideoCapture()
- 参数0表示默认为笔记本的内置第一个摄像头,如果需要读取已有的视频则参数改为视频所在路径路径
#### cap.isOpened()
- 判断视频对象是否成功读取,成功读取视频对象返回True
#### ret,frame = cap.read()
- 按帧读取视频,返回值ret是布尔型,正确读取则返回True,读取失败或读取视频结尾则会返回False。frame为每一帧的图像。
#### key = cv2.waitKey(1)
- 等待键盘输入,参数1表示延时1ms切换到下一帧,参数为0表示显示当前帧,相当于暂停
#### cap.release()
- 释放资源,这个与cv2.destroyAllWindows()最好写在while ret循环外
#### if key == ord('q'):
- 按Q退出
#### bitwise_and(src1, src2, dst=None, mask=None)
- 函数返回值:调用时若无mask参数则返回src1 & src2,若存在mask参数,则返回src1 & src2 & mask
- src1:输入原图1
- src2:输入原图2,src1与src2可以相同也可以不相同,可以是灰度图像也可以是彩色图像
- dst:若存在参数时:src1 & src2 或者 src1 & src2 & mask
- mask:可以是单通道8bit灰度图像,也可以是矩阵,一般为二值化后的图像