【R语言数据科学】:机器学习常见评估指标
【R语言数据科学】:机器学习评估指标
- 个人主页:JoJo的数据分析历险记
- 个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生
- 如果文章对你有帮助,欢迎✌
关注、点赞、✌收藏、订阅专栏- ✨本文收录于【R语言数据科学】本系列主要介绍R语言在数据科学领域的应用包括:
R语言编程基础、R语言可视化、R语言进行数据操作、R语言建模、R语言机器学习算法实现、R语言统计理论方法实现。本系列会坚持完成下去,请大家多多关注点赞支持,一起学习~,尽量坚持每周持续更新,欢迎大家订阅交流学习!

文章目录
- 【R语言数据科学】:机器学习评估指标
- 前言
- 1.训练集和测试集
- 2.总体准确率(accuracy)
- 3.混淆矩阵
- 4.敏感性(Sensitivity)和特异性(specificity)
- 5.F1-score
- 6.ROC曲线和AUC值
前言
在我们开始介绍如何构建机器学习算法之前,我们首先介绍一下如何对一个模型的效果进行评估。我们将重点描述评估机器学习算法的指标。具体来说,我们需要量化什么样的模型是“更好”的,本篇我们来讨论一下如何评估一个模型的效果。在这里我们需要使用
caret包
library(tidyverse)
library(caret)
我们使用身高数据集来举例说明
library(dslabs)
data(heights)
X <- heights$height
Y <- heights$sex
在这里,我们只有一个解释变量:
身高(height),一个被解释变量:性别(sex),其中sex是一个二元变量:分别为female和male。
我们想要研究的是不同身高对性别的影响。
1.训练集和测试集
机器学习算法是通过在新的数据集上进行评估。但是,在我们训练模型时,我们往往在一个已知结果的数据集上进行。 因此,我们在模型评估时,往往将数据集划分为两部分,一部分用于训练,另一部分用于测试。生成训练集和测试集的标准方法是随机拆分数据。
caret包含函数createDataPartition,它帮助我们生成索引以将数据随机分成训练集和测试集,具体如下
set.seed(12345)#设计随机种子
test_index <- createDataPartition(Y,times=1,p=0.3,list = FALSE)
其中,
times表示随机抽样的次数,p表示测试集的比例。有了测试集索引,我们就可以划分数据集
# 训练集
train_set <- heights[-test_index,]
# 测试集
test_set <- heights[test_index,]
现在我们有了训练集和测试集,我们评估模型的一般做法是,只用训练集的数据训练模型,然后训练好的模型来对测试集上的数据进行预测,然后将预测结果与实际值进行比较。对于二分类目标而言,最常用的指标之一是总体准确率。
2.总体准确率(accuracy)
整体准确率简单定义为正确预测的整体比例,具体公式如下:
# T r u e P r e d i c t # T o t a l \frac{\#True Predict}{\#Total} #Total#TruePredict
为了演示整体准确性的使用,我们将构建两个不同的算法并进行比较。在这里我们不适用任何算法,选取两种方式得到我们的预测结果:
- 1.随机选取"Male"和"Female"
- 2.根据X的均值来预测结果
y_hat <- sample(c("Male", "Female"), length(test_index), replace = TrUE)
请注意,我们完全忽略了预测变量,只是随机猜测了性别。 在机器学习应用中,使用因子来表示分类结果很有用,因为为机器学习开发的 r 函数(例如插入符号包中的函数)要求或建议将分类结果编码为
factor。因此,使用factor函数将 y_hat 转换为因子,并没有其他的含义:
y_hat <- sample(c("Male", "Female"), length(test_index), replace = TrUE) %>%
factor(levels = levels(test_set$sex))
mean(y_hat == test_set$sex)
0.484177215189873
可以看出随机猜测的正确率为0.48,在意料之中,我们的准确率约为 50%。因为我们完全是在随机猜测,但是我们能做得更好吗?通过先验知识我们知道,平均而言,男性略高于女性。 因此,我们先计算一下不同性别的身高均值和标准差
heights %>% group_by(sex) %>% summarize(mean(height), sd(height))
| sex | mean(height) | sd(height) |
|---|---|---|
| Female | 64.93942 | 3.760656 |
| Male | 69.31475 | 3.611024 |
我们如何使用这些数据呢?我们尝试一个比较简单的方法:如果身高在平均男性的两个标准差范围内,则预测男性:
y_hat <- ifelse(test_set$height > 62, "Male", "Female") %>%
factor(levels = levels(test_set$sex))
mean(y_hat == test_set$sex )
0.810126582278481
可以看出,此时的准确率上升到了81%,这是因为我们应用了一定的信息,即身高高于62英尺的为男性
3.混淆矩阵
如果学生身高超过 64 英寸,按照我们上一节的结果,我们会预测男性。鉴于女性的平均身高约为 64 英寸,这个预测规则似乎是错误的。 如果一个学生是普通女性的身高,我们不应该预测女性吗?一般来说,整体准确性可能是一种欺骗性的衡量指标。为了看到这一点,我们将从构建所谓的混淆矩阵开始,它基本上将预测值和实际值的每个组合制成表格。我们可以在 r 中使用函数
table来做到这一点
table(predicted = y_hat, actual = test_set$sex)
actual
predicted Female Male
Female 14 2
Male 58 242
如果我们仔细研究这张表,就会发现一个问题。如果我们分别计算每种性别的准确度,我们会得到:
test_set %>%
mutate(y_hat = y_hat) %>%
group_by(sex) %>%
summarize(accuracy = mean(y_hat == sex))
| sex | accuracy |
|---|---|
| Female | 0.1944444 |
| Male | 0.9918033 |
可以看出,对于女性的预测精度很低,不到20%,这种情况在数据不均衡的情况下很容易出现,我们的数据集中,
mean(Y=='Male')
0.773333333333333
77%都是男性。因此如果还是使用准确率作为评估指标是没有意义的。 举一个很极端的例子,在信贷违约中,违约的比例很小,可能不到1%,这个时候哪怕我们一直预测不违约也有99%的精度,但是这样显然没有意义。因此这个时候我们使用其他的评估指标
我们可以使用几个指标来评估算法,这些都可以从混淆矩阵中推导出来。使用整体准确性的一般改进是分别研究敏感性和特异性。
4.敏感性(Sensitivity)和特异性(specificity)
为了定义敏感性和特异性,我们需要一个二元结果。当结果是分类的时,我们可以为特定类别定义这些术语。
为了方便定义,我们来看下面这个混淆矩阵!
 )
)
一般来说,敏感性被定义为当实际结果为正时算法预测正结果的能力: Y ^ = 1 , Y = 1 \hat Y=1,Y=1 Y^=1,Y=1。用上边指标定义:
T P T P + F N \frac{TP}{TP+FN} TP+FNTP
这个值被称为真阳性率 (TPR) 或召回率(recall)。
特异性被定义为 T P T P + F P \frac{TP}{TP+FP} TP+FPTP,这个值被称为Precition。我们可以使用
caret中的函数confusionMatrix,计算各个指标的值
cm <- confusionMatrix(data = y_hat, reference = test_set$sex)
cm
Confusion Matrix and Statistics
reference
Prediction Female Male
Female 14 2
Male 58 242
Accuracy : 0.8101
95% CI : (0.7625, 0.8519)
No Information rate : 0.7722
P-Value [Acc > NIr] : 0.05927
Kappa : 0.2566
Mcnemar's Test P-Value : 1.243e-12
Sensitivity : 0.19444
Specificity : 0.99180
Pos Pred Value : 0.87500
Neg Pred Value : 0.80667
Prevalence : 0.22785
Detection rate : 0.04430
Detection Prevalence : 0.05063
Balanced Accuracy : 0.59312
'Positive' Class : Female
我们可以看到,尽管灵敏度相对较低,但总体精度仍然很高。正如我们在上面所总结的,发生这种情况的原因是女性比例低。所以无法将实际女性预测为女性(低敏感性)。这就是为什么检查敏感性和特异性而不仅仅是准确性很重要的一个例子。在将此评估指标应用于一般数据集之前,我们需要考虑样本量是否平衡
5.F1-score
尽管我们通常建议同时研究特异性和敏感性,但通常有一个单独的指标是有用的。例如用于优化目的。一种优于整体准确度的指标是特异性和灵敏度的平均值,称为平衡准确度。因为特异性和敏感性是比率,所以计算调和平均值更合适。事实上,F1-score 是一种广泛使用的单数总结,是准确率和召回率的调和平均值:
F 1 = 2 1 r e c a l l + 1 p r e c i s i o n F_1 = \frac{2}{\frac{1}{recall}+\frac{1}{precision}} F1=recall1+precision12我们知道我们希望F1-score越大越好。
请记住,有的时候根据具体情况,某些类型的错误比其他类型的错误代价更高。 例如,在判决死刑谋杀案件中,我们更注重precision,因为误判导致了处决无辜公民。相反,在飞机是否会发生故障情况时,我们更注重recall,因为如果会发生事故结果我们预测没有发生事故会造成更大的损失。因此,我们可以调整F1-score以适应不同的特异性和敏感性。为此,我们定义β,表示recall和precision的重要性比值:
F 1 = 1 β 2 1 + β 2 1 r e c a l l + 1 1 + β 2 1 p r e c i s i o n F_1 = \frac{1}{\frac{\beta^2}{1+\beta^2}\frac{1}{recall}+\frac{1}{1+\beta^2}\frac{1}{precision}} F1=1+β2β2recall1+1+β21precision11
F_meas函数可以指定 β \beta β,默认为1
现在我们构建一个模型,其评估指标为F1-score,而不是准确率
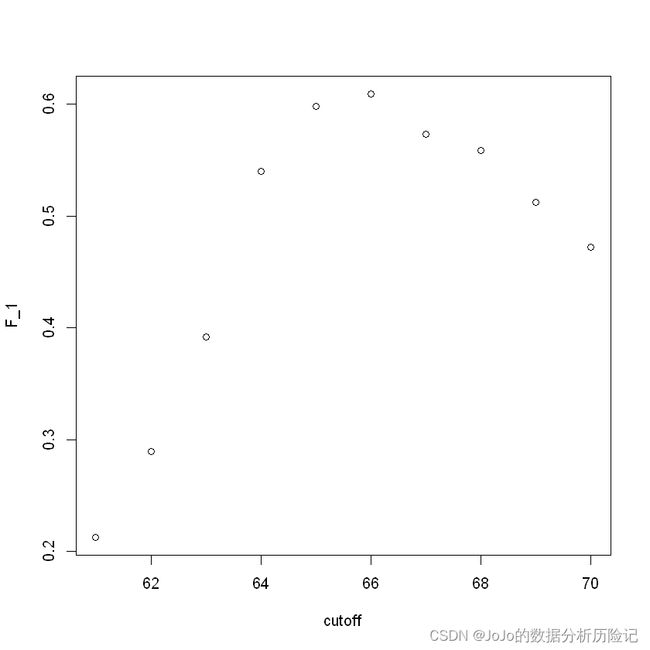
cutoff <- seq(61, 70)
F_1 <- map_dbl(cutoff, function(x){
y_hat <- ifelse(train_set$height > x, "Male", "Female") %>%
factor(levels = levels(test_set$sex))
F_meas(data = y_hat, reference = factor(train_set$sex))
})
plot(cutoff,F_1)
 )
)
max(F_1)
0.609164420485175
best_cutoff <- cutoff[which.max(F_1)]
best_cutoff
66
可以看出大于66英尺得到的F1-score最高
6.ROC曲线和AUC值
加粗样式在比较这两种方法(随机猜测与使用身高判断)时,我们查看了准确性和F1两个指标。
第二种方法明显优于第一种方法。然而,虽然我们为第二种方法考虑了几个临界点,但对于第一种方法,我们只考虑了一种方法:以等概率猜测。请注意,由于样本中不均衡数据,以更高的概率猜测男性会给我们更高的准确性:
p <- 0.9
n <- length(test_index)
y_hat_1 <- sample(c("Male", "Female"), n, replace = TrUE, prob=c(p, 1-p)) %>%
factor(levels = levels(test_set$sex))
mean(y_hat_1 == test_set$sex)
0.721518987341772
可以看出此时的准确率有所提升,这是因为样本的不均衡数据
y_hat_2 <- ifelse(test_set$height > 66, "Male", "Female") %>%
factor(levels = levels(test_set$sex))
mean(y_hat_2 == test_set$sex)
0.800632911392405
下面我们来看看如何绘制roc曲线,并返回AUC值,首先导入prOC包
library(prOC)
roc1<-roc(test_set$sex,test_set$height,levels=c("Male","Female"))
plot(roc1,print.auc=T, auc.polygon=T, grid=c(0.1, 0.2), grid.col=c("green","red"), max.auc.polygon=T, auc.polygon.col="skyblue",print.thres=T)

本章的介绍到此介绍,如果文章对你有帮助,请多多点赞、收藏、评论、关注支持!!