第六章 正则,BeautifulSoup,xpath
文章目录
- 1.正则
-
- 1.1 提取字符串
- 1.2 替换
- 1.3 搜索
- 2. beautifulsoup
-
- 2.1 各种解析器
- 2.2 提取方式
- 2.3 find方法
-
- 2.3.1 find
- 2.3.2 find_all
- 2.3.3 通过id和类型精确定位
-
- 2.3.3.1 通过符合正则表达式的id定位
- 2.3.4 通过内容查找元素
- 2.4 获取父子节点和兄弟节点
-
- 2.4.1 获取父子节点
-
- 2.4.1.1 contents属性,提取一级子元素
- 2.4.1.2 descendants属性,提取所有级子元素
- 2.4.1.3 获取第一个父元素
- 2.4.1.4 获取所有父元素
- 2.4.2 获取兄弟节点
-
- 2.4.2.1 获取之后的兄弟元素——next_siblings
- 2.4.2.2 获取之前的兄弟元素——previous_siblings
- 2.4.3 多值属性
- 3. xpath基本语法
-
- 3.1 xpath简介
- 3.2 xpath术语
- 3.3 xpath语法
-
- 3.3.1 xpath基础表达式
- 3.3.2 提取标签节点
- 3.3.3 提取标签字符串:extract函数
- 3.3.4 提取标签里的内容
-
- 3.3.4.1 text()
- 3.3.4.2 再反向演示一下extract的作用
- 3.4.4.3 代码灵活化
- 3.3.4.2 关于多值属性
-
- 3.3.4.2.1 直接写@class要把所有属性都写上
- 3.3.4.2.2 contains函数
1.正则
1.1 提取字符串
import re
#提取字符串
#替换
#搜索
info="姓名:bobby 1987 生日:1987年10月1日 本科:2005年9月1日"
print(re.findall("\d{4}",info))
result=re.match(".*生日.*?(\d{4}).*本科:(\d{4})",info)
#match方法是从字符串的最开始匹配的 .*贪婪匹配 .*?非贪婪匹配 打括号分组
print(result.group(1))
print(result.group(2))

1.2 替换
import re
#提取字符串
#替换
#搜索
info="姓名:bobby 1987 生日:1987年10月1日 本科:2005年9月1日"
#提取字符串
print(re.findall("\d{4}",info))
result=re.match(".*生日.*?(\d{4}).*本科:(\d{4})",info)
#match方法是从字符串的最开始匹配的 .*贪婪匹配 .*?非贪婪匹配 打括号分组
print(result.group(1))
print(result.group(2))
#替换
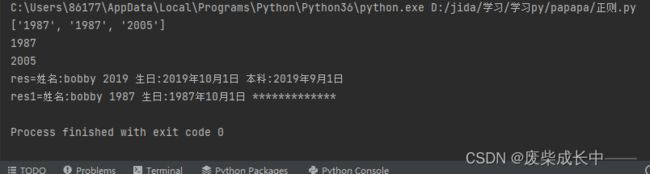
res=re.sub("\d{4}","2019",info)
res1=re.sub("本科:2005年9月1日","*************",info)
print("res="+res)
print("res1="+res1)
1.3 搜索
import re
#提取字符串
#替换
#搜索
info="姓名:bobby 1987 生日:1987年10月1日 本科:2005年9月1日"
#提取字符串
print(re.findall("\d{4}",info))
result=re.match(".*生日.*?(\d{4}).*本科:(\d{4})",info)
#match方法是从字符串的最开始匹配的 .*贪婪匹配 .*?非贪婪匹配 打括号分组
print(result.group(1))
print(result.group(2))
#替换
res=re.sub("\d{4}","2019",info)
res1=re.sub("本科:2005年9月1日","*************",info)
print("res="+res)
print("res1="+res1)
#搜索
name="my name is bobby"
print(re.search("bobby",name))
print(re.search("bobby",name).group())
#re.IGNORECASE忽略大小写
name1="my name is Bobby"
print(re.search("bobby",name1,re.IGNORECASE).group())
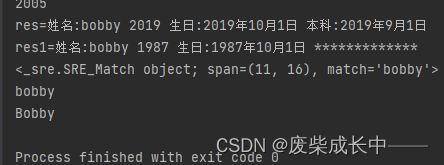
#DOTALL模式,即使换行符也可以继续读
print(re.match(".*bobby",name2,re.DOTALL).group())

2. beautifulsoup
通过这个库来知道将Html页面下载下来之后我们如何去解析html里面的元素,如何从这些元素中提取出我们想要的一些值,下载一定要下载beautifulsoup4。
2.1 各种解析器

2.2 提取方式
bs=BeautifulSoup(html,“html.parser”)
提取方式,首先定位到这个元素,所有操作都是基于bs这个对象进行的,如果要取它的title,可以直接写bs.title。点取属性,返回的是BeautifulSoup里面的一个类。
title_tag=bs.title
在类上就可以进行取值,在类上有一个属性string,可以用它直接获取内容。
print(title_tag.string)
from bs4 import BeautifulSoup
html="""
CHINA IN HISTORY


仕女图是中国历史文化的璀璨一角
仕女图亦称“仕女画”,是以中国封建社会宫女为题材的绘画艺术作品。仕女图最早出现于魏晋南北朝,繁荣兴盛于唐宋时期,元代因社会动荡政治冲突逐渐衰退,明清时期再次兴盛,并出现创作的鼎盛时代。魏晋以来,有一批历代名家的《仕女图》,将女性温柔婉约、仪态容貌描绘得栩栩如生、活灵活现,让人拍手叫绝,叹为观止!
中国艺术文化重形象思维,重传神,重意境。无论哪种笔法,都晕染着真善美。

世人都知于谦石灰吟,却少知这位清官也是一位显赫的民族战斗英雄
于谦远比我们知道的丰富很多,他所在的时代,宦官坏国,然而王振却依旧动不得于谦,每当权势滔天的王振想解决于谦,他的命令总是无法执行,得到的回应总是警告:你最好别动这个人。并非天子保于谦,而是对于于谦,识者无不敬服!在明朝最困难的时候,于谦运筹帷幄,杀伐果断,力挽狂澜,体现出超人的军事能力,他死后,锦衣卫搜查其家落泪,太后为他水米不进。英雄陨落,悲矣!
于谦为官兢兢业业,为百姓鞠躬尽瘁,但真正让他大施拳脚的时刻是土木堡之变。
于谦深知国不可一日无君,在皇帝沦为阶下囚,太子尚为襁褓,大明朝面临大厦将倾局面时,冒天下之大不韪,奏请郕王为帝,用于稳定局面。
有人说,中国人被一群英雄保护得好好的。我想说是的,中国从来不缺英雄,并且中国民众追随英雄。
掠影惊鸿
历史中的中国,就如一个男人成长。自负,鞭策,灾难,荣光壹壹经历。
近代史惨痛,可更早的历史中国是站在最高点的国邦。威震四海,不可撼动。
臣服,交好。是其他国家的选择。
可是1900年中国跌倒了,倒了很久,以至于动荡战乱,老一辈记忆刻下不可磨灭的悲痛。
中国当然会再站起来,在00后出生的50年前,毛泽东在天安门一锤定音。
新时代青年大多知道祖国经历民族耻辱,民族光辉事件的皮毛,却少有人去细看中国为什么能崛起,
历史中的中国做过哪些挣扎,又有哪些冲突。
我始终认为,中国的进步,是由无数个在领导位置、沉稳决策的智者与善良爱国、执行正确方针的民众打造的。
前者甚至比后者更重要。
这个网页就是用来稍稍记录历史中的中国如何走向今日繁华。更祝愿我华夏千秋业新篇永续!
 快捷通道
快捷通道






如果你要和平,请准备战争。
和平时代,军队还是应该保持锐气,万不可得"和平病"。
"""
bs=BeautifulSoup(html,"html.parser")
title_tag=bs.title
print(title_tag.string)

取div时会发现如果用点属性,只会取到第一个满足条件的div,所以上述方法适用的是像title这样只有一个的属性,像div这样有许多个的,就要用另外的方法——find。
2.3 find方法
bs=BeautifulSoup(html,“html.parser”)
2.3.1 find
bs.find(“div”) 也只能找到第一个符合条件的div
2.3.2 find_all
bs.find_all(“div”) 返回所有的div
可以用for循环来输出
div_tags=bs.find_all("div")
for tag in div_tags:
print(tag.string)
很多时候我们需要进一步定位,比如id来定位。
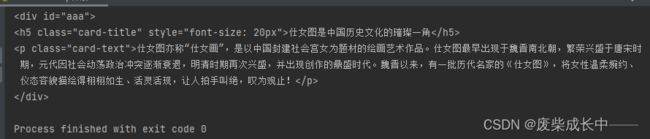
2.3.3 通过id和类型精确定位
div_tag1=bs.find("div",id="aaa")
print(div_tag1)
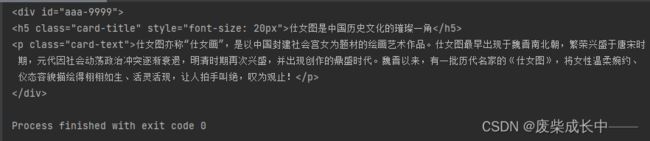
2.3.3.1 通过符合正则表达式的id定位
将上面的id="aaa"改为id="aaa-9999"方便演示
div_tag1=bs.find("div",id=re.compile("aaa-\d+"))
print(div_tag1)
2.3.4 通过内容查找元素

但是目前看作用不大,string后面也可以用正则

2.4 获取父子节点和兄弟节点
2.4.1 获取父子节点
2.4.1.1 contents属性,提取一级子元素
bs=BeautifulSoup(html,"html.parser")
div_tag2=bs.find("div",re.compile("bbb-\d+"))
childrens=div_tag2.contents
for child in childrens:
print(child.name)

None是因为程序把\n解析了,所以我们要加个判断
bs=BeautifulSoup(html,"html.parser")
div_tag1=bs.find("div",re.compile("bbb-\d+"))
childrens=div_tag1.contents
for child in childrens:
if child.name:
print(child.name)

2.4.1.2 descendants属性,提取所有级子元素
bs=BeautifulSoup(html,"html.parser")
div_tag2=bs.find("div",re.compile("bbb-\d+"))
childrens=div_tag2.descendants
for child in childrens:
if child.name:
print(child.name)
2.4.1.3 获取第一个父元素
注意:如果find()写find(“p”,class=“name”),class是关键词,冲突,所以要换个写法:
bs.find(“p”,{“class”:“name”})
bs=BeautifulSoup(html,"html.parser")
parent=bs.find("h5",{"class":"card-title"}).parent
print(parent)

2.4.1.4 获取所有父元素
bs=BeautifulSoup(html,"html.parser")
parents=bs.find("h5",{"class":"cart-title"})
for parent in parents:
print(parent.name)
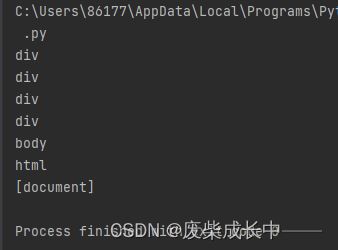
2.4.2 获取兄弟节点
2.4.2.1 获取之后的兄弟元素——next_siblings
bs=BeautifulSoup(html,"html.parser")
next_siblings=bs.find("p",string=re.compile("于谦深知.*")).next_siblings
for sibling in next_siblings:
print(sibling.string)
原码参照:

代码运行结果:

可以看见后面的兄弟元素内容提取出来了,前面的没有。那么如何提取前面的兄弟元素呢?
2.4.2.2 获取之前的兄弟元素——previous_siblings
bs=BeautifulSoup(html,"html.parser")
privious_siblings=bs.find("p",string=re.compile("于谦深知.*")).previous_siblings
for sibling in privious_siblings:
print(sibling.string)
源码参考:
代码运行结果:
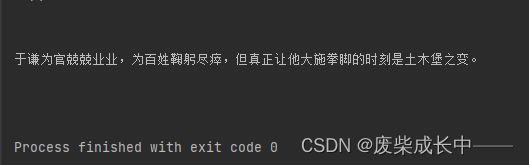
siblings用单数sibling可以取到前面一个兄弟元素,但是会受换行符的影响,换行符也会被当做兄弟元素
2.4.3 多值属性
tag=bs.find("p",string=re.compile("于谦为官.*"))
print(tag["class"])
print(tag.get("class"))
源码参考:
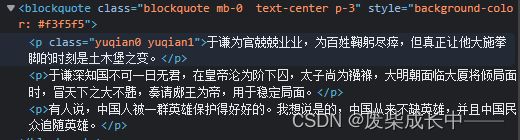
代码运行结果:

多值属性返回列表
单值属性返回字符串
3. xpath基本语法
3.1 xpath简介


3.2 xpath术语

3.3 xpath语法
3.3.1 xpath基础表达式
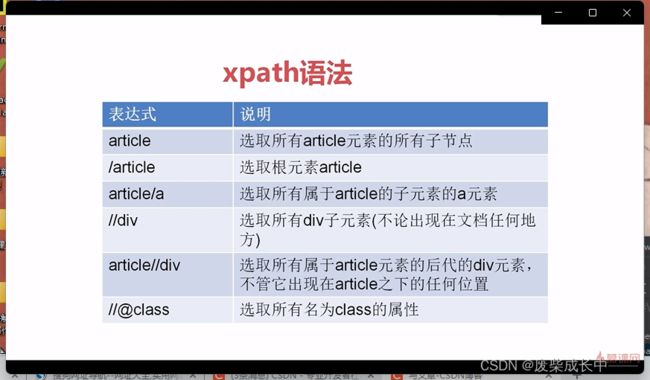

利用浏览器自动生成xpath路径
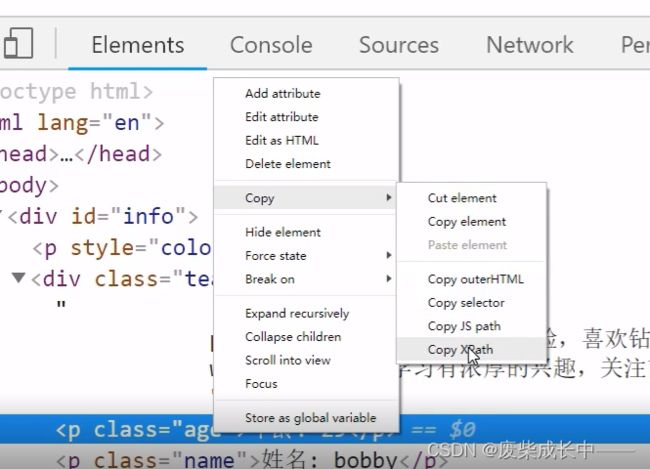
把xpath复制到编译器内时,注意双引号里面的双引号得换成单引号
3.3.2 提取标签节点
from scrapy import Selector
html="""
CHINA IN HISTORY
仕女图是中国历史文化的璀璨一角
仕女图亦称“仕女画”,是以中国封建社会宫女为题材的绘画艺术作品。仕女图最早出现于魏晋南北朝,繁荣兴盛于唐宋时期,元代因社会动荡政治冲突逐渐衰退,明清时期再次兴盛,并出现创作的鼎盛时代。魏晋以来,有一批历代名家的《仕女图》,将女性温柔婉约、仪态容貌描绘得栩栩如生、活灵活现,让人拍手叫绝,叹为观止!
中国艺术文化重形象思维,重传神,重意境。无论哪种笔法,都晕染着真善美。
世人都知于谦石灰吟,却少知这位清官也是一位显赫的民族战斗英雄
于谦远比我们知道的丰富很多,他所在的时代,宦官坏国,然而王振却依旧动不得于谦,每当权势滔天的王振想解决于谦,他的命令总是无法执行,得到的回应总是警告:你最好别动这个人。并非天子保于谦,而是对于于谦,识者无不敬服!在明朝最困难的时候,于谦运筹帷幄,杀伐果断,力挽狂澜,体现出超人的军事能力,他死后,锦衣卫搜查其家落泪,太后为他水米不进。英雄陨落,悲矣!
于谦为官兢兢业业,为百姓鞠躬尽瘁,但真正让他大施拳脚的时刻是土木堡之变。
于谦深知国不可一日无君,在皇帝沦为阶下囚,太子尚为襁褓,大明朝面临大厦将倾局面时,冒天下之大不韪,奏请郕王为帝,用于稳定局面。
有人说,中国人被一群英雄保护得好好的。我想说是的,中国从来不缺英雄,并且中国民众追随英雄。
掠影惊鸿
历史中的中国,就如一个男人成长。自负,鞭策,灾难,荣光壹壹经历。
近代史惨痛,可更早的历史中国是站在最高点的国邦。威震四海,不可撼动。
臣服,交好。是其他国家的选择。
可是1900年中国跌倒了,倒了很久,以至于动荡战乱,老一辈记忆刻下不可磨灭的悲痛。
中国当然会再站起来,在00后出生的50年前,毛泽东在天安门一锤定音。
新时代青年大多知道祖国经历民族耻辱,民族光辉事件的皮毛,却少有人去细看中国为什么能崛起,
历史中的中国做过哪些挣扎,又有哪些冲突。
我始终认为,中国的进步,是由无数个在领导位置、沉稳决策的智者与善良爱国、执行正确方针的民众打造的。
前者甚至比后者更重要。
这个网页就是用来稍稍记录历史中的中国如何走向今日繁华。更祝愿我华夏千秋业新篇永续!
快捷通道
如果你要和平,请准备战争。
和平时代,军队还是应该保持锐气,万不可得"和平病"。
"""
sel=Selector(text=html)
tag=sel.xpath("//*[@id="bbb-9999"]/p[1]")
print(tag)
print(tag.__class__)

可以看到,要的标签就是data里的值,那么怎么提取data里的值呢
3.3.3 提取标签字符串:extract函数
extract这个单词本身就是提取的意思,提取data里的值,返回为字符串list,因为有可能有多个值
from scrapy import Selector
sel=Selector(text=html).extract()
print(sel)
print(sel.__class__)

返回的是一个list,因为有可能有多个值,取第一个值就在extract()后面加个[0]
sel=Selector(text=html)
tag0=sel.xpath("//*[@id='bbb-9999']/p").extract()
tag=sel.xpath("//*[@id='bbb-9999']/p").extract()[0]
print(tag0)
print(tag0.__class__)
print(tag)
print(tag.__class__)

注意:extract()返回的list可能是个空值,这时候取[0]会抛异常,所以最好做下判断

3.3.4 提取标签里的内容
3.3.4.1 text()
在xpath(“//*[@id=‘bbb-9999’]/p[1]”)中的xpath表达式的后面加上/text()就可以获得所找标签的内容
源码参考:

sel=Selector(text=html)
tag=sel.xpath("//*[@id='bbb-9999']/blockquote/p/text()").extract()
print(tag)
print(tag.__class__)

sel=Selector(text=html)
tag=sel.xpath("//*[@id='bbb-9999']/blockquote/p/text()").extract()[0]
print(tag)
print(tag.__class__)

3.3.4.2 再反向演示一下extract的作用
sel=Selector(text=html)
tag=sel.xpath("//*[@id='bbb-9999']/blockquote/p/text()")
print(tag)
print(tag.__class__)

3.4.4.3 代码灵活化
sel=Selector(text=html)
name_xpath="//*[@id='bbb-9999']/blockquote/p/text()"
name=""
tag_texts=sel.xpath(name_xpath).extract()
if tag_texts:
name=tag_texts[0]
print(name)
3.3.4.2 关于多值属性
3.3.4.2.1 直接写@class要把所有属性都写上
sel=Selector(text=html)
tag=sel.xpath("//div[@class='aaa aa']/p/text()").extract()
print(tag)
源码参考:

运行结果:

那要是这个class属性又多又长,都要写上岂非太烦?所以有一个叫contains的函数,可实现四两拨千斤。
3.3.4.2.2 contains函数
sel=Selector(text=html)
tag=sel.xpath("//div[contains(@class,'aa')]/p/text()").extract()
print(tag)
运行结果:

源码参考:
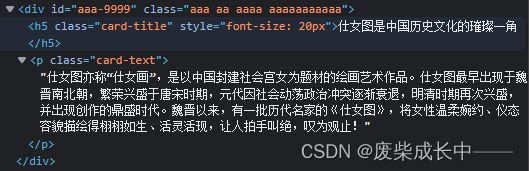
用contains,就算class的一个值没有写完整也可以查,比如上面,我写个a来查也可以
除了contains,其它内置方法还有很多,可以去https://developer.mozilla.org/en-US/docs/Web/XPath/Functions查看
还可以直接获取属性:
sel=Selector(text=html)
tag=sel.xpath("//div[contains(@class,'aa')]/@class")
print(tag)

tag=sel.xpath("//div[contains(@class,'aa')]/@class").extract()
print(tag)

另一个示例

|在xpath里是和的意思