OpenCV计算机视觉实战(Python)| 10、项目实战:文档扫描OCR识别
文章目录
- 简介
- 总结
-
- 1. 介绍
- 2. 流程
- 3. 程序
- 4. 知识点总结
简介
本节为《OpenCV计算机视觉实战(Python)》版第10讲,项目实战:文档扫描OCR识别,的总结。
总结
1. 介绍
识别图像中的所有的字符(汉字、英语等字体)。
2. 流程
边缘检测:
预处理 + 边缘检测

轮廓检测:
对检测到的轮廓进行排序,排序可以按照轮廓面积的大小,然后得到最大的轮廓(跟图像大小相同的轮廓),轮廓近似,得到四个点的轮廓。

透视变换:
将2维坐标值[x,y]转化为三维齐次坐标[x,y,1],新的坐标[X,Y,Z] ^T= M [x,y,1]^T,
而M=[M11,M12,M13; M21,M22,M23; M31,M32, 1],总共8个未知数,因此需要8个方程来求解。
八个方程:4个坐标点
字符识别:
OCR开源工具包:pytesseract
参考网址:
http://digi.bib.uni-mannheim.de/tesseract/
3. 程序
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h,w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w*r), height)
else:
r = width / float(w)
dim = (width, int(h*r))
resized = cv2.resize(image, dim, interpoation = inter)
return resized
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4,2), dtype='float32')
# 按顺序找到对应坐标0123,分别是:左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w 和 h 的值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) **2))
maxwidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2 ) + ((tr[1] - br[1] ) ** 2))
heigthB = np.sqrt(((tl[0] - bl[0]) **2) + ((tl[1] - bl[1]) **2))
maxheigth = max(int(heightA), int(heigthB))
# 变换后对应坐标的位置
dst = np.array([
[0,0],
[maxwidth - 1,0],
[maxwidth -1, maxheigth-1],
[0,maxheight-1]], dtype='float32')
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxwidth, maxheight))
# 返回变换后结果
return warped
# 读取输入
image = cv2.imread('')
# resize后坐标变了,将比例求出,坐标也会相同变化
ratio = image.shape[0]/500.0
orig = image.copy()
image = resize(orig, height = 500)
# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5,5), 0) # 高斯滤波去除噪声点
edged = cv2.Canny(gray, 75, 200) # 边缘检测
# 展示预处理结果
print('STEP1:边缘检测')
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 轮廓检测
cnts = cv2.findContours(edged.copy(), cv2.RETE_LIST, cv2.CHAIN_APPROX_SIMPLE)[1]
cnts = sorted(cnts, key = cv2.contourArea, reverse = True)[:5]
# 遍历轮廓
for c in cnts:
# 计算轮廓近似
peri = cv2.arcLength(c, TRUE)
# C表示输入的点集
# epsilon表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参考,越小越接近原始图形,越大越接近矩形;一般跟周长有关系
# TRUE表示封闭的
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 4个点的时间就拿出来:此时就是矩形
if len(approx) == 4:
screeCnt = approx
break
# 显示结果
print('STEP 2 : 获取轮廓')
cv2.drawContours(image, [screenCnt], -1, (0,255,0), 2)
cv2.imshow('OutLine', image)
cv2.waitKey(0)
cv2.destoryAllWindows()
# 透视变换
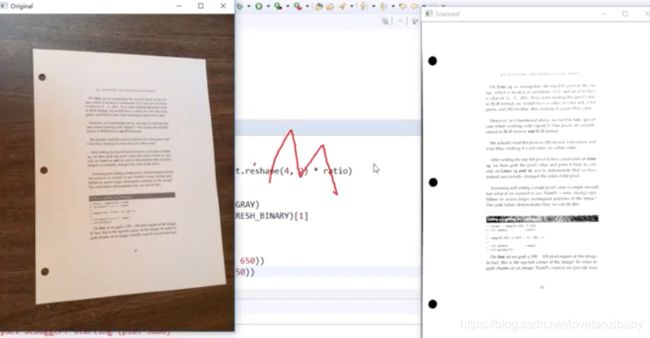
warped = four_point_transform(orig, screenCnt.reshape(4,2)*ratio) # orig原始图像,因此图像必须要*ratio还原坐标点
# 二值处理
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped, 100, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite('scan.jpg', ref)
# 显示结果
print('STEP3:透视变换')
cv2.imshow('Original', resize(orig, height = 650)
cv2.imshow('Scanned', resize(ref, height == 650)
cv2.waitKey(0)
cv2.destroyAllWindows()
由于字符识别不是我主要的研究方向,这里略过字符识别的程序。有需要的同学可以从这里学习。
4. 知识点总结
- 轮廓近似:如何用四个点近似轮廓,而非矩形近似
- 四个点排序:左上,右上,右下,左上
- 透视变换:M矩阵的计算
- resize:正向和逆向操作
- 字符识别工具包:tesseract