A Comprehensive Survey on Graph Neural Networks论文阅读笔记
A Comprehensive Survey on Graph Neural Networks
-
- 细节点
- 摘要
- 介绍部分
-
- 将机器学习应用到Graph领域的问题
- 2D卷积和Graph卷积相似之处和区别
- 文章的贡献之处
- 文章框架
- GNNs背景
-
- GNNs和network embedding
- GNNs和graph kernel methods
- GNNs 符号
-
- notations
- Spatial-Temporal Graph定义
- GNNs分类框架
-
- 网络结构划分
-
- RecGNNs:学习节点表示
- ConvGNNs:将网格数据的卷积推广到Graph
- Graph autoencoders(GAEs):将nodes/Graphs编码到latent vector空间,接着重构
-
- 用处:
- 学习网络嵌入表示
- Spatial-temporal graph neural networks (STGNNs)
-
- 应用场景
- 按不同图分析任务划分
-
- Node-level
- Edge-level
- Graph-level
- 按训练框架划分
-
- Semi-supervised learning for node-level classification
- Supervised learning for graph-level classification.
- Unsupervised learning for graph embedding
- RecGNN和ConvGNN模型总结和复杂度分析
- RGNN
-
- 论文阅读顺序
- 发展过程
- RGNN 和 ConvsGNN区别
- ConvGNNs
-
- 基于谱 VS 基于空间,空间Win!!!
-
- overall
- 谱方法GCN
-
- 论文阅读顺序
- 发展过程
- 空间方法
-
- overall
- 论文阅读顺序
- 发展过程
- 提升计算效率的一些方法
- 图Pooling模块
-
- overall
- paper
- 发展过程
- 理论方面的讨论
-
- Shape of receptive field
- VC维
- Graph isomorphism
- Equivariance and invariance
- Universal approximation
- GAE(Graph Autoencoders)
-
- Network Embedding
-
- overall
- paper
- 发展过程
- Graph Generation
-
- overall
- paper
- 发展过程
- SPATIAL-TEMPORAL GRAPH NEURAL NETWORKS
-
- overlall
- paper
- 发展过程
-
- RNN-based
- CNN-based
- 应用
-
- 应用领域
-
- Computer vision
- Natural language processing
- Traffic
- 推荐系统
- Chemistry
- 其他
- 未来方向
细节点
- 非欧几里得域:图(Graph)和流形(mainfolds)
- Thenotion of graph neural networks was initially outlined in Gori
et al. (2005) [14] and further elaborated in Scarselli et al.
(2009) [15], and Gallicchio et al. (2010) [16]. - 特征分解时间复杂度 O ( N 3 ) O(N^3) O(N3),节点对之间最短路径计算时间复杂度 O ( N 3 ) O(N^3) O(N3)
- 图卷积与其他神经网络的合成更加高效和方便。
- 不知道平衡二叉树是什么
- injective 函数(单射函数):如果所有x,y∈A,且x≠y,都有f(x)≠f(y),则称f为由A到B的单射
- 图的稀疏性导致positive node pairs(临近的节点对)数量远远少于负节点对的数量
摘要
- 在越来越多的应用中,使用从非欧式空间生成的数据
- 本文是一篇概述图神经网络在数据挖掘和机器学习中的应用
- 图神经网络的分类:recurrent graph neural networks,convolutional graph neural networks,graph autoencoders,spatial-temporal graph neural networks。
介绍部分
将机器学习应用到Graph领域的问题
- 图可能是不规则的,一个图可能有大小不等的无序节点,而来自图的节点可能有不同数量的邻居,这导致一些重要的操作(比如卷积)在image域中容易计算,但很难应用到graph域中
- 现有的机器学习假设实例(Instances)之间是相互独立的,然而在图中节点和节点之间是相关联的
2D卷积和Graph卷积相似之处和区别

文章的贡献之处
- 提出图神经网络的分类方法
- 对每个类别的GNN代表模型进行了详细的描述,比较
- 收集了大量的资源,包括最新的模型、基准数据集、开源代码和实际应用程序
- 给出现有方法的局限性,同时提出未来的研究方向:模型深度,scalability trade-off,异构性和动态性。
文章框架
- 第2节概述了GNNs的背景,列出了常用的notations,并定义了Graph相关的概念。
- 第3节阐明了图形神经网络的分类。
- 第4-7节提供了GNNs模型的概述。
- 第8节介绍了GNNs在不同领域的应用的集合。
- 第9节讨论了当前的挑战并提出了未来的方向。第X节对本文进行了总结。
GNNs背景
- 早期研究集中在recurrent graph neural networks用于学习节点的表示,迭代的方法直到达到一个稳定点。
- 出现了许多种重新定义图卷积的方法,主要两个派系:spectral-based,和spatial-based方法
GNNs和network embedding
GNNs的研究和graph embedding/network embedding(将网络节点表示为低维向量表示)有着密切的关系,GNN强调使用端到端方式开展图相关任务,GNNs是用于解决各种各样任务的一组神经网络模型。另一方面,网络嵌入还包括其他非深度学习方法:matrix factorization(矩阵分解),随机游动(random walks)。
GNNs和graph kernel methods
graph kernel 是用于解决图分类问题的主要技术
- 使用一个核函数来度量图对之间的相似性
- 图核可以通过确定性映射函数将图或节点嵌入到向量空间中
gnn直接基于图表示进行图分类,比图核方法更加高效。
GNNs 符号
notations

Spatial-Temporal Graph定义
- 是属性图,并且节点属性随时间动态变化,
- 时空图的定义: G ( t ) = ( V , E , X ( t ) ) G^{(t)}=\left(\mathbf{V}, \mathbf{E}, \mathbf{X}^{(t)}\right) G(t)=(V,E,X(t)),并且 X ( t ) ∈ R n × d \mathbf{X}^{(t)} \in \mathbf{R}^{n \times d} X(t)∈Rn×d,图节点特征随时间发生改变
GNNs分类框架
网络结构划分
RecGNNs:学习节点表示
它们假设图中的一个节点不断地与它的邻居交换信息/消息,直到到达一个稳定的平衡状态,
ConvGNNs:将网格数据的卷积推广到Graph
堆叠多个图卷积层以提取高层的节点特征表示,有基于节点的分类和基于图的分类:

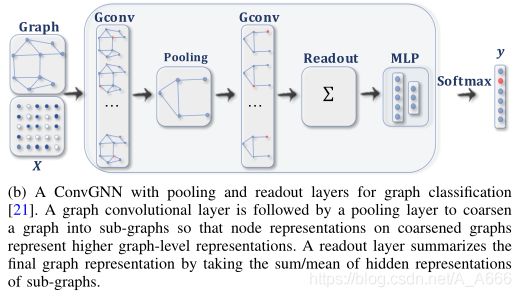
这里的池化操作是将图粗化为子图使得在粗化后的子图上的节点表示更高层次的特征,
Graph autoencoders(GAEs):将nodes/Graphs编码到latent vector空间,接着重构
用处:
学习网络的嵌入表示和Graph generative distributions,网络嵌入涉及到通过重构图的邻接矩阵来学习latent node的表示
学习网络嵌入表示
压缩和重构的是图的邻接矩阵
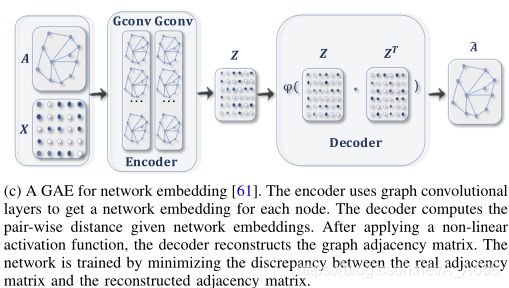
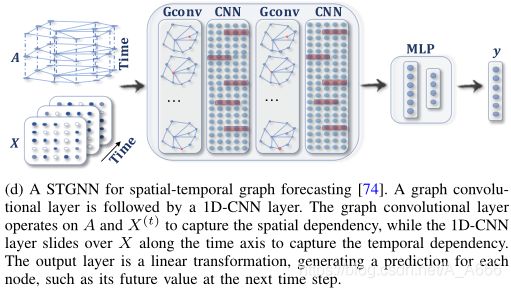
Spatial-temporal graph neural networks (STGNNs)
学习spatial-temporal graphs的隐模式(hidden patterns),同时考虑空间依赖性和时间依赖性,和CNN或者RNN结合获取时间和空间信息。
应用场景
- traffic speed forecasting
- driver maneuver anticipation
- human action recognition
按不同图分析任务划分
Node-level
用于节点回归和分类任务,代表网络:RecGNNs,ConvGNNs首先提取节点的high-level表示,然后使用一个MLP或者softmax实现端到端训练。
Edge-level
用于edge的分类和link预测,利用GNNs提取的节点的hidden表示作为输入,使用相似性函数或者神经网络来预测edge的标签/连接强度
Graph-level
用于图分类任务,经常与pooling和readout操作结合在一起
按训练框架划分
Semi-supervised learning for node-level classification
针对单个网络中部分节点被标记而其余节点未标记的情况,通过叠加GC layers并后面跟着一个softmax层实现多类别分类。
Supervised learning for graph-level classification.
利用GC layers 池化和/或读出层实现图的端到端学习,网络框架可以参考graph-level 的图卷积。
Unsupervised learning for graph embedding
两种类型:
- embed the graph into the latent representation,使用GC layers来实现
- 使用negative sampling approach采样节点作为负样本对,剩下的点作为正样本对,接着使用a logistic regression layer去区分正样本和负样本[42],这里没有理解这样做的原因。
RecGNN和ConvGNN模型总结和复杂度分析

RGNN
论文阅读顺序
[15] G N N ∗ GNN^* GNN∗->[16]GraphESN(改进不明显)->[17]Gated Graph Neural Network (GGNN)
发展过程
-
仅用于有向无环图
由于计算能力受限。
-
无环图、循环图、有向图和无向图
基于information diffusion mechanism,迭代直到达到稳定状态。
h v ( t ) = ∑ u ∈ N ( v ) f ( x v , x e ( v , u ) , x u , h u ( t − 1 ) ) \mathbf{h}_{v}^{(t)}=\sum_{u \in N(v)} f\left(\mathbf{x}_{v}, \mathbf{x}^{\mathbf{e}}(v, u), \mathbf{x}_{u}, \mathbf{h}_{u}^{(t-1)}\right) hv(t)=u∈N(v)∑f(xv,xe(v,u),xu,hu(t−1))
对参数方程 f f f的要求是收缩映射,当f(·)为神经网络时,参数的雅可比矩阵必须加一个惩罚项(正则化项)。当满足收敛准则时,将最后一步节点隐藏状态转发到读出层。节点的状态传播(直到稳定)和计算参数梯度(一次梯度)是交替进行的。
在GraphESN中,由一个编码层和一个输出层组成,这里使用编码层代替压缩状态函数来递归地更新节点状态(编码器不需要训练)最终得到一个不动点,接着作为输入进行训练。
在Gated Graph Neural Network (GGNN) 中,使用GRU作为递归函数,解决了 f f f收缩映射的条件,节点状态更新方程:使用当前节点和邻居节点的状态更新。并且使用BPTT进行参数的训练,但是对于大型图来说是一个问题。
h v ( t ) = G R U ( h v ( t − 1 ) , ∑ u ∈ N ( v ) W h u ( t − 1 ) ) \mathbf{h}_{v}^{(t)}=G R U\left(\mathbf{h}_{v}^{(t-1)}, \sum_{u \in N(v)} \mathbf{W h}_{u}^{(t-1)}\right) hv(t)=GRU⎝⎛hv(t−1),u∈N(v)∑Whu(t−1)⎠⎞
在SSE中提出了一种可以扩展到large graphs的思路:它交替抽取一批节点进行状态更新,抽取一批节点进行梯度计算。为了保证收敛性,SSE是对历史状态和新状态的一个加权平均。
h v ( t ) = ( 1 − α ) h v ( t − 1 ) + α W 1 σ ( W 2 [ x v , ∑ u ∈ N ( v ) [ h u ( t − 1 ) , x u ] ] ) \mathbf{h}_{v}^{(t)}=(1-\alpha) \mathbf{h}_{v}^{(t-1)}+\alpha \mathbf{W}_{1} \sigma\left(\mathbf{W}_{2}\left[\mathbf{x}_{v}, \sum_{u \in N(v)}\left[\mathbf{h}_{u}^{(t-1)}, \mathbf{x}_{u}\right]\right]\right) hv(t)=(1−α)hv(t−1)+αW1σ⎝⎛W2⎣⎡xv,u∈N(v)∑[hu(t−1),xu]⎦⎤⎠⎞
RGNN 和 ConvsGNN区别
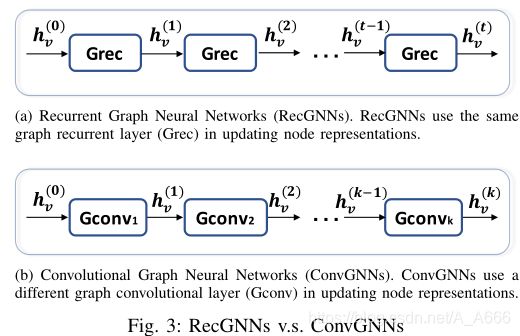
ConvGNNs
基于谱 VS 基于空间,空间Win!!!
overall
基于频谱的方法从Graph信号处理的角度通过引入滤波器来定义Graph卷积[82],其中,Graph卷积操作被解释为从Graph信号中去除噪声。
基于空间的方法继承了RecGNNs的思想,通过信息传播(Aggregation邻居信息)来定义图形卷积。
基于空间的方法由于其具有吸引力的效率、灵活性和通用性,最近得到了迅速发展。
- 谱模型的效率低于空间模型,谱模型要么需要进行特征向量计算,要么同时处理整个图。空间模型对大型图具有更大的可伸缩性,因为它们通过信息传播直接在Graph中执行卷积,并且计算可以在一批节点中进行,而不是在整个图中进行。
- 其次,依赖于图傅里叶基的谱模型很难推广到新的图。假设有一个固定的图形。对图的任何扰动都会导致特征基的改变
- 基于空间的模型在每个节点上执行局部的图形卷积,在不同位置和结构之间可以轻松地共享权值
- 基于空间的模型更灵活地处理多源图输入,如边输入[15]、[27]、[86]、[95]、[96]、有向图[25]、[72]、有符号图[97]和异构图[98]、[99],因为这些图输入可以很容易地合并到聚合函数中。
谱方法GCN
论文阅读顺序
Spectral Convolutional Neural Network (Spectral CNN)[19] ->ChebNet[21]->GCN[22]->CayleyNet[23] ->GCN[22]->Adaptive Graph Convolutional Network (AGCN) [40] -> Dual Graph Convolutional Network(DGCN)[41]->Mixture Model Network (MoNet) [44]
发展过程
- 在Spectral CNN中,定义谱的GCL为:
H : , j ( k ) = σ ( ∑ i = 1 f k − 1 U Θ i , j ( k ) U T H : , i ( k − 1 ) ) ( j = 1 , 2 , ⋯ , f k ) \mathbf{H}_{:, j}^{(k)}=\sigma\left(\sum_{i=1}^{f_{k-1}} \mathbf{U} \Theta_{i, j}^{(k)} \mathbf{U}^{T} \mathbf{H}_{:, i}^{(k-1)}\right) \quad\left(j=1,2, \cdots, f_{k}\right) H:,j(k)=σ(i=1∑fk−1UΘi,j(k)UTH:,i(k−1))(j=1,2,⋯,fk)
由于公式比较复杂,这里我们做详细地说明:
( k ) {(k)} (k)是GCL层的索引号,这里图的隐状态是 H ( k ) ∈ R n ∗ f k \mathbf{H}^{(k)}\in R^{n*f_k} H(k)∈Rn∗fk, n n n表示节点数, f k f_k fk表示通道数,在前向计算时,通道数会发生改变。 H ( 0 ) = X ∈ R n ∗ d \mathbf{H}^{(0)} = X \in R^{n*d} H(0)=X∈Rn∗d是图的初始状态,计算 H ( k ) \mathbf{H}^{(k)} H(k)的一个通道的状态时,使用了前一层所有通道的状态都做了一次图卷积并求和,这里不清楚的一点就是 g θ = Θ i , j ( k ) g_\theta = \Theta_{i, j}^{(k)} gθ=Θi,j(k)是一个矩阵的话,那么每一层是否是有很多的 Θ i , j ( k ) \Theta_{i, j}^{(k)} Θi,j(k)( f k − 1 ∗ f k f_{k-1}*f_k fk−1∗fk个 n ∗ n n*n n∗n的矩阵)呢?
上述方法存在的问题是:
1. 对图的任何扰动都会导致特征基$U$的变化.
- 其次,学习过滤器是依赖于邻域的,这意味着它们不能应用于具有不同结构的图
3. 计算特征分解需要 O ( n 3 ) O(n^3) O(n3)
- 在Chebyshev Spectral CNN (ChebNet) 中,使用Chebyshev polynomials of the diagonal matrix of eigenvalues对 g θ g_\theta gθ做近似。
x ∗ G g θ = U ( ∑ i = 0 K θ i T i ( Λ ~ ) ) U T x \mathbf{x} *_{G} \mathbf{g}_{\theta}=\mathbf{U}\left(\sum_{i=0}^{K} \theta_{i} T_{i}(\tilde{\boldsymbol{\Lambda}})\right) \mathbf{U}^{T} \mathbf{x} x∗Ggθ=U(i=0∑KθiTi(Λ~))UTx
其中 Λ ~ = 2 Λ / λ max − I n \tilde{\boldsymbol{\Lambda}}=2 \mathbf{\Lambda} / \lambda_{\max }-\mathbf{I}_{\mathbf{n}} Λ~=2Λ/λmax−In,使得 Λ ~ \tilde{\boldsymbol{\Lambda}} Λ~的取值范围为 [ − 1 , 1 ] [-1,1] [−1,1],切比雪夫多项式定义:
T i ( x ) = 2 x T i − 1 ( x ) − T i − 2 ( x ) T_{i}(\mathbf{x})=2 \mathbf{x} T_{i-1}(\mathbf{x})-T_{i-2}(\mathbf{x}) Ti(x)=2xTi−1(x)−Ti−2(x)
并且 T 0 ( x ) = 1 , T 1 ( x ) = x T_{0}(\mathbf{x})=1,T_{1}(\mathbf{x})=x T0(x)=1,T1(x)=x,又由于 T i ( L ~ ) = U T i ( Λ ~ ) U T T_{i}(\tilde{\mathbf{L}})=\mathbf{U} T_{i}(\tilde{\boldsymbol{\Lambda}}) \mathbf{U}^{T} Ti(L~)=UTi(Λ~)UT,其中 L ~ = 2 L / λ max − I n \tilde{\mathbf{L}}=2 \mathbf{L} / \lambda_{\max }-\mathbf{I}_{\mathbf{n}} L~=2L/λmax−In,可以将图卷积的式子进行化简,从而得到:
x ∗ G g θ = ∑ i = 0 K θ i T i ( L ~ ) x \mathbf{x} *_{G} \mathbf{g}_{\theta}=\sum_{i=0}^{K} \theta_{i} T_{i}(\tilde{\mathbf{L}}) \mathbf{x} x∗Ggθ=i=0∑KθiTi(L~)x
这样的修改使得卷积仅仅是在局部定义,意味着滤波器可以独立了于图的大小提取局部特征
-
CayleyNet
使用Cayley多项式,是参数化的有理复函数,可以捕获窄带信号其卷积的定义为:
x ∗ G g θ = c 0 x + 2 Re { ∑ j = 1 r c j ( h L − i I ) j ( h L + i I ) − j x } \mathbf{x} *_{G} \mathbf{g}_{\theta}=c_{0} \mathbf{x}+2 \operatorname{Re}\left\{\sum_{j=1}^{r} c_{j}(h \mathbf{L}-i \mathbf{I})^{j}(h \mathbf{L}+i \mathbf{I})^{-j} \mathbf{x}\right\} x∗Ggθ=c0x+2Re{j=1∑rcj(hL−iI)j(hL+iI)−jx}
ChebNet可以看作是CayleyNet的一种特殊情况。 -
Graph Convolutional Network (GCN)
GCN对ChebNet进行简化,假定 K = 1 , λ m a x = 2 K = 1,\lambda_{max} = 2 K=1,λmax=2,这样的话,卷积公式简化为:
x ∗ G g θ = θ 0 x − θ 1 D − 1 2 A D − 1 2 x \mathbf{x} *_{G} \mathbf{g}_{\theta}=\theta_{0} \mathbf{x}-\theta_{1} \mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}} \mathbf{x} x∗Ggθ=θ0x−θ1D−21AD−21x
同时为了限制参数数量同时便面过拟合,假设 θ = θ 0 = − θ 1 \theta = \theta_0 = -\theta_1 θ=θ0=−θ1,从而推导出接下来的卷积式:
x ∗ G g θ = θ ( I n + D − 1 2 A D − 1 2 ) x \mathbf{x} *_{G} \mathbf{g}_{\theta}=\theta\left(\mathbf{I}_{\mathbf{n}}+\mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}}\right) \mathbf{x} x∗Ggθ=θ(In+D−21AD−21)x
输入信号为矩阵 X X X时,将上述式整理为:
H = X ∗ G g Θ = f ( A ‾ X Θ ) \mathbf{H}=\mathbf{X} *_{G} \mathbf{g}_{\Theta}=f(\overline{\mathbf{A}} \mathbf{X} \Theta) H=X∗GgΘ=f(AXΘ)
但是不清楚这个 Θ \Theta Θ的表达式是什么,其中 A ‾ = I n + D − 1 2 A D − 1 2 \overline{\mathbf{A}}=\mathbf{I}_{\mathbf{n}}+\mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}} A=In+D−21AD−21,不过这个式子很容易造成GCN的不稳定,使用normalization技巧取代替 A ‾ \overline{\mathbf{A}} A,其中$ \overline{\mathbf{A}}=\tilde{\mathbf{D}}^{-\frac{1}{2}} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-\frac{1}{2}} , , ,\tilde{\mathbf{A}}=\mathbf{A}+\mathbf{I}{\mathbf{n}} , , ,\tilde{\mathbf{D}}{i i}=\sum_{i} \tilde{\mathbf{A}}_{i j}$,将上式表示为空间形式为:
h v = f ( Θ T ( ∑ u ∈ { N ( v ) ∪ v } A ˉ v , u x u ) ) ∀ v ∈ V \mathbf{h}_{v}=f\left(\mathbf{\Theta}^{T}\left(\sum_{u \in\{N(v) \cup v\}} \bar{A}_{v, u} \mathbf{x}_{u}\right)\right) \quad \forall v \in V hv=f⎝⎛ΘT⎝⎛u∈{N(v)∪v}∑Aˉv,uxu⎠⎞⎠⎞∀v∈V
- AGCN
- DGCN
空间方法
overall
The spatial graph convolutional operation essentially propagates node information along edges.(空间卷积操作实质上是沿着edge传递节点信息)
论文阅读顺序
GCN -> Neural Network for Graphs (NN4G) [24]->Contextual Graph Markov Model (CGMM)[24]->DCNN[25]-DGC[72]-> PGC-DGCNN[46]->Partition Graph Convolution (PGC) [75] ->Message Passing Neural Network (MPNN) [27]->Graph Isomorphism Network (GIN)[57]->GrapphSage[42]->Graph Attention Network (GA T) [43]->Mixture Model Network (MoNet) [44]->PA TCHY -SAN [26] -> Large-
scale Graph Convolutional Network (LGCN) [45] -》Fast Learning with Graph Convolutional Network (Fast-GCN) [49]->Huang et al. [51] ->Stochastic Training of Graph Convolutional Networks (StoGCN) [50]
发展过程
-
Neural Network for Graphs (NN4G) [24]
在文中使用了residual connections和skip connections
h v ( k ) = f ( W ( k ) T x v + ∑ i = 1 k − 1 ∑ u ∈ N ( v ) Θ ( k ) T h u ( k − 1 ) ) \mathbf{h}_{v}^{(k)}=f\left(\mathbf{W}^{(k)^{T}} \mathbf{x}_{v}+\sum_{i=1}^{k-1} \sum_{u \in N(v)} \Theta^{(k)^{T}} \mathbf{h}_{u}^{(k-1)}\right) hv(k)=f⎝⎛W(k)Txv+i=1∑k−1u∈N(v)∑Θ(k)Thu(k−1)⎠⎞
其中 h v ( 0 ) = 0 \mathbf{h}_{v}^{(0)}=\mathbf{0} hv(0)=0,将等式写成矩阵形式为:
H ( k ) = f ( X W ( k ) + ∑ i = 1 k − 1 A H ( k − 1 ) Θ ( k ) ) \mathbf{H}^{(k)}=f\left(\mathbf{X} \mathbf{W}^{(k)}+\sum_{i=1}^{k-1} \mathbf{A} \mathbf{H}^{(k-1)} \mathbf{\Theta}^{(k)}\right) H(k)=f(XW(k)+i=1∑k−1AH(k−1)Θ(k))
其中A是使用的是非规范化的邻接矩阵
-
Contextual Graph Markov Model (CGMM)具有概率可解释性的优点
-
Diffusion Convolutional Neural Network (DCNN)
将图卷积看作是一个扩散过程,假设信息以一定概率从一个节点转移到相邻节点,并最终达到均衡,文中定义的扩散图卷积为:
H ( k ) = f ( W ( k ) ⊙ P k X ) \mathbf{H}^{(k)}=f\left(\mathbf{W}^{(k)} \odot \mathbf{P}^{k} \mathbf{X}\right) H(k)=f(W(k)⊙PkX)
其中 f ( ⋅ ) f(\cdot) f(⋅)是一个激活函数, P ∈ R n × n \mathbf{P} \in \mathbf{R}^{n \times n} P∈Rn×n, P = D − 1 A \mathbf{P}=\mathbf{D}^{-1} \mathbf{A} P=D−1A,从上式中可以看出 H ( k ) \mathbf{H}^{(k)} H(k)是和 H ( k − 1 ) \mathbf{H}^{(k-1)} H(k−1)没有关系的,DCNN中将 H ( 1 ) H^{(1)} H(1),…, H ( K ) H^{(K)} H(K)连接到一起作为输出。 -
Diffusion Graph Convolution(DCG)将每一步扩散输出做了一个求和(这样做的原理是:扩散过程的平稳分布是概率转移矩阵的幂级数的和)
H = ∑ k = 0 K f ( P k X W ( k ) ) \mathbf{H}=\sum_{k=0}^{K} f\left(\mathbf{P}^{k} \mathbf{X} \mathbf{W}^{(k)}\right) H=k=0∑Kf(PkXW(k))
使用转移概率矩阵的幂意味着遥远的邻居对中心节点贡献很少的信息
-
PGC-DGCNN
基于最短路径增加遥远邻居的贡献。增加了一个shortest path
adjacency matrix S ( j ) S^{(j)} S(j)。计算最短路径复杂度为 O ( n 3 ) O(n^3) O(n3),如果u节点到v节点最短距离为j,则 S u , v ( j ) = 1 S^{(j)}_{u,v}=1 Su,v(j)=1,否则为0.同时引入超参数
H ( k ) = ∥ j = 0 r f ( ( D ~ ( j ) ) − 1 S ( j ) H ( k − 1 ) W ( j , k ] ) , \mathbf{H}^{(k)}=\|_{j=0}^{r} f\left(\left(\tilde{\mathbf{D}}^{(j)}\right)^{-1} \mathbf{S}^{(j)} \mathbf{H}^{(k-1)} \mathbf{W}^{(j, k]}\right), H(k)=∥j=0rf((D~(j))−1S(j)H(k−1)W(j,k]),
-
Partition Graph Convolution (PGC) [75]
根据特定的标准将节点的邻居划分为Q组,每一组使用不同的邻接矩阵,接着使用不同的参数矩阵,并将最终得到的结果相加。
H ( k ) = ∑ j = 1 Q A ‾ ( j ) H ( k − 1 ) W ( j , k ) \mathbf{H}^{(k)}=\sum_{j=1}^{Q} \overline{\mathbf{A}}^{(j)} \mathbf{H}^{(k-1)} \mathbf{W}^{(j, k)} H(k)=j=1∑QA(j)H(k−1)W(j,k)
H ( 0 ) = X , A ‾ ( j ) = ( D ~ ( j ) ) − 1 2 A ~ ( j ) ( D ~ ( j ) ) − 1 2 \mathbf{H}^{(0)}=\mathbf{X}, \overline{\mathbf{A}}^{(j)}=\left(\tilde{\mathbf{D}}^{(j)}\right)^{-\frac{1}{2}} \tilde{\mathbf{A}}^{(j)}\left(\tilde{\mathbf{D}}^{(j)}\right)^{-\frac{1}{2}} H(0)=X,A(j)=(D~(j))−21A~(j)(D~(j))−21, A ~ ( j ) = A ( j ) + I \tilde{\mathbf{A}}^{(j)} = {\mathbf{A}}^{(j)}+\mathbf{I} A~(j)=A(j)+I -
Message Passing Neural Network (MPNN)
将谱域的卷积看成是空间域的消息传递,因此这边消息传递的函数为:
h v ( k ) = U k ( h v ( k − 1 ) , ∑ u ∈ N ( v ) M k ( h v ( k − 1 ) , h u ( k − 1 ) , x v u e ) ) \mathbf{h}_{v}^{(k)}=U_{k}\left(\mathbf{h}_{v}^{(k-1)}, \sum_{u \in N(v)} M_{k}\left(\mathbf{h}_{v}^{(k-1)}, \mathbf{h}_{u}^{(k-1)}, \mathbf{x}_{v u}^{e}\right)\right) hv(k)=Uk(hv(k−1),∑u∈N(v)Mk(hv(k−1),hu(k−1),xvue)),
其中 h v ( 0 ) = x v , U k ( ⋅ ) , M k ( ⋅ ) \mathbf{h}_{v}^{(0)}=\mathbf{x}_{v}, U_{k}(\cdot), M_{k}(\cdot) hv(0)=xv,Uk(⋅),Mk(⋅)都是要学习的参数,读出(readout)函数 h G = R ( h v ( K ) ∣ v ∈ G ) \mathbf{h}_{G}=R\left(\mathbf{h}_{v}^{(K)} \mid v \in G\right) hG=R(hv(K)∣v∈G),是关于最后一层节点的函数
-
Graph Isomorphism Network (GIN)解决无法使用他们产生的图嵌入来区分不同结构的图
中心节点的权值由一个可学习参数 ϵ ( k ) \epsilon^{(k)} ϵ(k),得到图卷积/消息传递表达为:
h v ( k ) = M L P ( ( 1 + ϵ ( k ) ) h v ( k − 1 ) + ∑ u ∈ N ( v ) h u ( k − 1 ) ) \mathbf{h}_{v}^{(k)}=M L P\left(\left(1+\epsilon^{(k)}\right) \mathbf{h}_{v}^{(k-1)}+\sum_{u \in N(v)} \mathbf{h}_{u}^{(k-1)}\right) hv(k)=MLP⎝⎛(1+ϵ(k))hv(k−1)+u∈N(v)∑hu(k−1)⎠⎞ -
GraphSage不使用所有的邻域节点,而是对于每一个节点采样固定数量的邻居
h v ( k ) = σ ( W ( k ) ⋅ f k ( h v ( k − 1 ) , { h u ( k − 1 ) , ∀ u ∈ S N ( v ) } ) ) \mathbf{h}_{v}^{(k)}=\sigma\left(\mathbf{W}^{(k)} \cdot f_{k}\left(\mathbf{h}_{v}^{(k-1)},\left\{\mathbf{h}_{u}^{(k-1)}, \forall u \in S_{\mathcal{N}(v)}\right\}\right)\right) hv(k)=σ(W(k)⋅fk(hv(k−1),{hu(k−1),∀u∈SN(v)}))
f k f_{k} fk是节点的Aggregation函数,要求具有不变性,为什么那?
-
Graph Attention Network (GA T) [43]
假设相邻节点对于邻居节点的贡献是不相同的,因此学习两个连接节点之间的相对权值,GAT的图卷积/消息传递定义为:
h v ( k ) = σ ( ∑ u ∈ N ( v ) ∪ v α v u ( k ) W ( k ) h u ( k − 1 ) ) \mathbf{h}_{v}^{(k)}=\sigma\left(\sum_{u \in \mathcal{N}(v) \cup v} \alpha_{v u}^{(k)} \mathbf{W}^{(k)} \mathbf{h}_{u}^{(k-1)}\right) hv(k)=σ⎝⎛u∈N(v)∪v∑αvu(k)W(k)hu(k−1)⎠⎞
h v ( 0 ) = x v \mathbf{h}_{v}^{(0)}=\mathbf{x}_{v} hv(0)=xv,其中注意力系数的计算为:
α v u ( k ) = softmax ( g ( a T [ W ( k ) h v ( k − 1 ) ∥ W ( k ) h u ( k − 1 ) ) ) \alpha_{v u}^{(k)}=\operatorname{softmax}\left(g\left(\mathbf{a}^{T}\left[\mathbf{W}^{(k)} \mathbf{h}_{v}^{(k-1)} \| \mathbf{W}^{(k)} \mathbf{h}_{u}^{(k-1)}\right)\right)\right. αvu(k)=softmax(g(aT[W(k)hv(k−1)∥W(k)hu(k−1)))
同时,使用了multi-head attention,提高了模型的表达能力此外:图注意力模型有:GeniePath [55]
-
Mixture Model Network (MoNet) [44]
引入节点的伪坐标,并将两节点的相对位置映射为两节点之间的权重,实现不同位置参数的共享,使用带有可学习参数的高斯核来自适应学习权重函数。
-
PA TCHY -SAN [26]
PA TCHY -SAN[26]根据每个节点的图标签对其邻居进行排序,并选择顶部的q邻居。图标签本质上是节点评分,可以通过节点度、中心性和Weisfeiler-Lehman 来推导.
使用标准的1-D卷积聚合邻域信息,在图的数据处理上需要花费大量的时间。
-
Largescale Graph Convolutional Network (LGCN) [45]
采用不同的方法对邻域进行排序
提升计算效率的一些方法
-
GraphSage [42]
提出了一种a batch-training algorithm for ConvGNNs.
-
Fast Learning with Graph Convolutional Network (Fast-GCN) [49]
为每个图的卷积层采样固定数量的节点,并不处理所有的节点。它将图的卷积解释为节点嵌入函数在概率测度下的积分变换。
-
Huang et al. [51]
自适应的层采样方法,底层节点的采样是条件在高层节点的采样上的,具有更高的精度比Fasst-GCN
-
Stochastic Training of Graph Convolutional Networks (StoGCN) [50]
利用历史节点表示作为控制变量,将图卷积的接受野减小到任意小的规模,但是,StoGCN仍然需要保存所有节点的中间状态,这对于大型图来说是消耗内存的。
-
Cluster-GCN [58]
ConvGCNs训练算法的时间和内存复杂度比较([58]总结)。n是节点的总数。m是边的总数。K是层数。s为批大小。r是每个节点采样的邻居的数量.Cluster-GCN具有最小的内存消耗。

图Pooling模块
overall
- 直接使用所有的这些特征在计算上是很具有挑战性的,需要进行下采样策略,
两种策略
- down-sampling the nodes to generate samller representations,避免过拟合
- readout: 得到graph-level表示
paper
[23]使用Graclus algorithm 算法来对图节点聚类,从而实现图的粗化。
[17],[27],[46]使用注意力机制来增强mean/sum池化
set2set[101]->ChebNet->DGCNN->differentiable pooling (DiffPool) [54] ->SAGPool[102]
发展过程
-
图粗化算法使用特征分解来根据图的拓扑结构进行粗化。问题:时间复杂度太高
-
Graclus algorithm对原始图进行聚类得到粗化后的图
-
对得到的最后一层节点的隐特征,求统计特征(mean/max/sum)
h G = mean / max / sum ( h 1 ( K ) , h 2 ( K ) , … , h n ( K ) ) \mathbf{h}_{G}=\operatorname{mean} / \max / \operatorname{sum}\left(\mathbf{h}_{1}^{(K)}, \mathbf{h}_{2}^{(K)}, \ldots, \mathbf{h}_{n}^{(K)}\right) hG=mean/max/sum(h1(K),h2(K),…,hn(K))
-
[17],[27],[46]使用注意力机制来增强mean/sum池化
-
Set2Set在reduction之前增加新的信息。
-
Defferrard et al. [21],提出了更加高效的pooling策略:Craclus algorithm+balanced binary tree
-
DGCNN中提出SortPooling。
-
differentiable pooling (DiffPool) [54] 生成图的分层表示,不是直接对节点进行聚类,而是学习一个cluster assignment matrix S S S.
S ( k ) ∈ R n k × n k + 1 \mathbf{S}^{(k)} \in \mathbf{R}^{n_{k} \times n_{k+1}} S(k)∈Rnk×nk+1,其中 n k n_{k} nk是第 k k k层节点数。
S ( k ) = softmax ( Conv G N N k ( A ( k ) , H ( k ) ) ) \mathbf{S}^{(k)}=\operatorname{softmax}\left(\operatorname{Conv} G N N_{k}\left(\mathbf{A}^{(k)}, \mathbf{H}^{(k)}\right)\right) S(k)=softmax(ConvGNNk(A(k),H(k)))
缺点是计算复杂度会变成 O ( n 3 ) O(n^3) O(n3), -
SAGPool[102]既考虑节点特征,又考虑图拓扑,学习以一个self-attention的方式学习池化。
理论方面的讨论
Shape of receptive field
节点的接收野是最后一层节点能够接收到的所有节点的信息,就和CNN相同,
Micheli证明有限层的空间图卷积层可以cover图中的所有节点
VC维
什么是VC维?衡量研究对象(数据集与学习模型)可学习的指标,一个假设空间H的VC dimension,是这个H最多能够shatter掉的点的数量,记为dvc(H):翻译成人话是,不管数据是怎样分布的,H最多能区分多少个数据。我们可以想像,越是复杂的H能够区分的数据点就越多,VC维也就越大。
- VC维和模型复杂度是正相关的
- VC维的大小:与学习算法A无关,与输入变量X的分布也无关,与我们求解的目标函数f 无关。它只与模型和假设空间有关(模型复杂度和数据量)
GNN VC维的分析
如果使用sigmoid或正切双曲激活, G N N ∗ GNN^* GNN∗的VC维为 O ( p 4 n 2 ) O(p^4n^2) O(p4n2)
如果使用分段多项式激活函数,VC维为 O ( p 2 n ) O(p^2n) O(p2n)
Graph isomorphism
GNN将两个不同的Graph映射到不同的Embeddings,可以通过Weisfeiler-Lehman (WL) test两个图的非同构性。
为了实现等方差或不变性,GNN的组成部分必须对节点顺序保持不变。
Equivariance and invariance
执行节点级任务时,GNN必须是等变函数;执行图形级任务时,GNN必须是不变函数。
Universal approximation
-
众所周知,具有一隐层的多感知器前馈神经网络可以近似任何Borel可测函数.
-
Maron等[104]证明了不变图网络可以近似定义在图上的任意不变函数
GAE(Graph Autoencoders)
Network Embedding
overall
- 网络嵌入是节点的低维向量表示,它保留节点的拓扑信息
paper
DNGR[59]->SDNE[60]->Graph Autoencoder( G A E ∗ GAE^* GAE∗)[61]->Varia-
tional Graph Autoencoder (VGAE) [61]
发展过程
-
DNGR
利用多层感知器,堆叠降噪自编码器来对PPMI矩阵进行编码和解码
-
SDNE
在encode和decode上分别使用了两个loss函数:
第一损失函数使已学习的网络嵌入通过最小化节点嵌入网络之间的距离来保持节点的一阶邻近性: L 1 s t = ∑ ( v , u ) ∈ E A v , u ∥ enc ( x v ) − enc ( x u ) ∥ 2 L_{1 s t}=\sum_{(v, u) \in E} A_{v, u}\left\|\operatorname{enc}\left(\mathbf{x}_{v}\right)-\operatorname{enc}\left(\mathbf{x}_{u}\right)\right\|^{2} L1st=∑(v,u)∈EAv,u∥enc(xv)−enc(xu)∥2
其中$\mathbf{x}{v} =A{v, :} $,相当于是在对邻接矩阵进行encode
第二损失函数使学习到的网络嵌入通过最小化节点的输入与其重构输出之间的距离来保持节点的二阶接近性
上述的DNGR和SDNE仅仅考虑节点的结构信息,而没有考虑节点包含的特征信息(feature information),
-
G A E ∗ GAE^* GAE∗同时encode节点的结构信息和特征信息,并且由两个图卷积层构成:
Z = enc ( X , A ) = Gconv ( f ( Gconv ( A , X ; Θ 1 ) ) ; Θ 2 ) \mathbf{Z}=\operatorname{enc}(\mathbf{X}, \mathbf{A})=\operatorname{Gconv}\left(f\left(\operatorname{Gconv}\left(\mathbf{A}, \mathbf{X} ; \mathbf{\Theta}_{1}\right)\right) ; \mathbf{\Theta}_{2}\right) Z=enc(X,A)=Gconv(f(Gconv(A,X;Θ1));Θ2)
Z \mathbf{Z} Z就是 图的Embedding表示, f ( ⋅ ) f( \cdot ) f(⋅)表示ReLU激活函数解码器:再现图的邻接矩阵 A ^ v , u = dec ( z v , z u ) = σ ( z v T z u ) \hat{\mathbf{A}}_{v, u}=\operatorname{dec}\left(\mathbf{z}_{v}, \mathbf{z}_{u}\right)=\sigma\left(\mathbf{z}_{v}^{T} \mathbf{z}_{u}\right) A^v,u=dec(zv,zu)=σ(zvTzu),
训练目标:最小化真实邻接矩阵和重构邻接矩阵的negative cross entropy,
不过简单重构图的邻接矩阵很容易造成过拟合,由于自编码器的容量(过大还是过小?)
-
Variational Graph Autoencoder (VGAE) [61]
变分自编码器:优化变分下界:
L = E q ( Z ∣ X , A ) [ log p ( A ∣ Z ) ] − K L [ q ( Z ∣ X , A ) ∥ p ( Z ) ] L=E_{q(\mathbf{Z} \mid \mathbf{X}, \mathbf{A})}[\log p(\mathbf{A} \mid \mathbf{Z})]-K L[q(\mathbf{Z} \mid \mathbf{X}, \mathbf{A}) \| p(\mathbf{Z})] L=Eq(Z∣X,A)[logp(A∣Z)]−KL[q(Z∣X,A)∥p(Z)]
假定经验分布 q ( Z ∣ X , A ) q(\mathbf{Z} \mid \mathbf{X},\mathbf{A}) q(Z∣X,A)和先验分布 p ( Z ) p(\mathbf{Z}) p(Z)接近 -
Adversarially Regularized V ariational Graph Autoencoder (ARVGA) [62],
采用GAN的方式,生成器生成经验分布 q ( Z ∣ X , A ) q(\mathbf{Z} \mid \mathbf{X},\mathbf{A}) q(Z∣X,A),判别器要努力将生成器生成的分布和真实的先验分布 p ( Z ) p(\mathbf{Z}) p(Z)区别开来。
-
GraphSage[42]
定义loss函数的思路:强制接近的节点具有相似的表示,而距离较远的节点具有不同的表示
L ( z v ) = − log ( dec ( z v , z u ) ) − Q E v n ∼ P n ( v ) log ( − dec ( z v , z v n ) ) L\left(\mathbf{z}_{v}\right)=-\log \left(\operatorname{dec}\left(\mathbf{z}_{v}, \mathbf{z}_{u}\right)\right)-Q E_{v_{n} \sim P_{n}(v)} \log \left(-\operatorname{dec}\left(\mathbf{z}_{v}, \mathbf{z}_{v_{n}}\right)\right) L(zv)=−log(dec(zv,zu))−QEvn∼Pn(v)log(−dec(zv,zvn))
对于节点 v v v来说,他的Embedding表示 z v \mathbf{z}_{v} zv, u u u是 v v v的近邻节点, v n v_n vn是远离 v v v节点的,并且是通过negative sampling distribution得到的 -
DGI[56]利用网络嵌入通过最大化局部互信息来实现全局结构信息的捕获
-
Deep Recursive Network Embedding (DRNE)
假设节点的network embedding 近似其邻居节点网络嵌入的Aggregation,集成方法采用LSTM:
L = ∑ v ∈ V ∥ z v − L S T M ( { z u ∣ u ∈ N ( v ) } ) ∥ 2 L=\sum_{v \in V}\left\|\mathbf{z}_{v}-L S T M\left(\left\{\mathbf{z}_{u} \mid u \in N(v)\right\}\right)\right\|^{2} L=v∈V∑∥zv−LSTM({zu∣u∈N(v)})∥2
LSTM网络采用节点v的邻居按节点度排序的随机序列作为输入 -
Network Representations with Adversarially Regularized Autoencoders (NetRA) [64]
NetRA的编码器和解码器为LSTM网络,每个节点 v v v∈ V V V作为随机游动的起点,将游动结果输出到LSTM中。同时采用对抗训练的方法
Graph Generation
overall
思想:通过GAE编码,解码过程来学习图的生成过程,
研究前景:解决分子图生成问题,这在药物发现中具有很高的实用价值
生成图的方式:全局方式/序列方式(sequential manner)
paper
-
序列方法:Gomez et al. [111], Kusner et al. [112],and Dai et al. [113] ,Deep Generative Model of Graphs (DeepGMG) [65],GraphRNN
-
全局方法:Graph V ariational Autoencoder (GraphV AE) [67] ,(RGV AE) [68],(MolGAN) [69] ,NetGAN [70]
发展过程
-
Gomez et al. [111], Kusner et al. [112],and Dai et al. [113] 使用CNN和RNN作为编码器和解码器生成分子图的string representation
选择的方法适用于一般的图,迭代地向图中增加节点和边
-
Deep Generative Model of Graphs (DeepGMG) [65]
假定图的概率是所有可能的节点排列的和,通过一系列决策来生成图,即是否添加节点,添加哪个节点,是否添加一条边,以及哪个节点连接到新节点。
-
GraphRNN
一个graph-level神经网络(在节点序列中添加一个新节点)和一个edge-level神经网络(生成二进制序列表示新节点与之前生成节点之间的连接)来建模节点和边的生成过程。
-
Graph Variational Autoencoder (Graph VAE) [67]
将节点和边建模成独立的随机变量。优化变分下界
L ( ϕ , θ ; G ) = E q ϕ ( z ∣ G ) [ − log p θ ( G ∣ z ) ] + K L [ q ϕ ( z ∣ G ) ∥ p ( z ) ] L(\phi, \theta ; G)=E_{q_{\phi}(z \mid G)}\left[-\log p_{\theta}(G \mid \mathbf{z})\right]+K L\left[q_{\phi}(\mathbf{z} \mid G) \| p(\mathbf{z})\right] L(ϕ,θ;G)=Eqϕ(z∣G)[−logpθ(G∣z)]+KL[qϕ(z∣G)∥p(z)]使用ConvGNN作为编码器,MLP作为解码器,输出生成图的邻接矩阵,节点分布和边分布
-
Regularized Graph V ariational Autoencoder (RGV AE) [68]
对图变分自编码器施加有效性约束,以规范解码器的输出分布。
-
Molecular Generative Adversarial Network (MolGAN) [69]
集成convGNNs[114]、GANs[115]和强化学习目标,来生成期望的Graph
-
MolGAN由一个生成器和一个鉴别器组成,相互竞争以提高生成器的真实性。
生成器试图提出一个伪图及其特征矩阵,而鉴别器则试图从经验数据中区分出伪样本。此外,在鉴别器的基础上,还引入了一个奖励网络,以鼓励生成的图具有一定的属性。
-
NetGAN [70]
将LSTMs [7]和Wasserstein GANs [116] 结合to generate graphs。然后利用判别器识别fake random walks
Sequential VS global
- 顺序方法将图线性化为序列。由于周期的存在,它们可能会丢失结构信息。
- 全局方法一次生成一张图,但是无法扩展到大型Graph上。
SPATIAL-TEMPORAL GRAPH NEURAL NETWORKS
overlall
-
在许多实际应用中的Graph在Graph structure和Graph input方面都是动态的,Spatial-temporal graph neural networks (STGNNs)用于捕获图的动态特性(同时捕获图的时间和空间依赖),
-
方法思路:对图的动态输入进行建模,同时假设连接节点之间的依赖关系
-
实现方法:RNN-based,CNN-based
-
实现任务: 预测未来节点值或标签,预测时空图形标签
paper
- RNN-based方法 [48], [71], [72].GCRN,DCRNN,Structural-RNN
- CNN-based方法:CGCN ;ST-GCN;Graph WaveNet [76]
发展过程
RNN-based
标准的RNN:
H ( t ) = σ ( W X ( t ) + U H ( t − 1 ) + b ) \mathbf{H}^{(t)}=\sigma\left(\mathbf{W} \mathbf{X}^{(t)}+\mathbf{U H}^{(t-1)}+\mathbf{b}\right) H(t)=σ(WX(t)+UH(t−1)+b)
使用图卷积:
H ( t ) = σ ( Gconv ( X ( t ) , A ; W ) + Gconv ( H ( t − 1 ) , A ; U ) + b ) \mathbf{H}^{(t)}=\sigma\left(\operatorname{Gconv}\left(\mathbf{X}^{(t)}, \mathbf{A} ; \mathbf{W}\right)+\operatorname{Gconv}\left(\mathbf{H}^{(t-1)}, \mathbf{A} ; \mathbf{U}\right)+\mathbf{b}\right) H(t)=σ(Gconv(X(t),A;W)+Gconv(H(t−1),A;U)+b)
- Graph Convolutional Recurrent Network (GCRN) 将LSTM结合ChebNet。
- Diffusion Convolutional Recurrent Neural Network (DCRNN) 将diffusion graph convolutional layer和GRU结合
- DCRNN采用编解码框架来实现对节点未来K步值的预测
- Structural-RNN[73]包括两种RNN:node-RNN 和 an edge-RNN分别传递节点信息和边信息,整合信息是通过将edge-RNN的输出作为node-RNN输入。由于对不同的节点和边采取不同的RNN增加了模型的复杂度,划分语义组,同一语义组中节点和边共享同一个RNN模型
CNN-based
-
由于基于RNN的方法存在耗时的迭代传播和梯度爆炸/消失问题
-
基于CNN的方法:非递归处理,可并行计算、能稳定梯度、低内存需求
-
网络的输入为: X ∈ R T × n × d \mathcal{X} \in R^{T \times n \times d} X∈RT×n×d,图卷积层聚合在每一个时间步的空间信息( X [ i , : , : ] \mathcal{X}_{[i, :,:]} X[i,:,:]),1D-CNN延时间轴滑动 X [ : , i , : ] \mathcal{X}_{[:, i,:]} X[:,i,:]聚合时间信息。
预先定义的图结构
-
CGCN [74]
交叉ChebNet和1D-CNN,搭建spatial-temporal块(1D convolutional layer, a graph convolutional layer and another gated 1D convolutional layer ),
-
ST-GCN [75]
使用一维卷积层和PGC层组成spatial-temporal块
利用时空图的snapshots(快照,相当于动态图的某些时刻的图)学习latent静态图结构
-
Graph WaveNet [76]
提出自适应邻接矩阵(self-adaptive adjacency matrix)定义:
A a d p = SoftMax ( ReLU ( E 1 E 2 T ) ) \mathbf{A}_{a d p}=\operatorname{SoftMax}\left(\operatorname{ReLU}\left(\mathbf{E}_{1} \mathbf{E}_{2}^{T}\right)\right) Aadp=SoftMax(ReLU(E1E2T))
SoftMax函数是沿着行维计算的, E 1 E_1 E1表示源节点嵌入, E 2 E_2 E2表示带有可学习参数的目标节点嵌入。通过将 E 1 E_1 E1与 E 2 E_2 E2相乘,可以得到源节点与目标节点之间的依赖权值,在没有给出邻接矩阵的情况下表现也相当不错学习潜在的动态空间依赖关系可以进一步提高模型的精度
-
GaAN [48] RNN-based
注意力机制学习动态空间依赖关系,在给定当前节点输入的情况下,使用注意力函数更新两个连接节点之间的边权值。
-
ASTGCN [77] CNN-based
更进一步,空间注意函数和时间注意函数,学习潜在的动态空间依赖和时间依赖
不过学习节点的空间依赖,需要计算每对节点的权重,时间复杂度为 O ( n 2 ) O(n^2) O(n2).
应用
As graph-structured data are ubiquitous, GNNs have a wide variety of applications.
- 在评估节点分类时的两个缺陷:
- 所有实验中使用相同的训练/有效/测试分割会低估泛化误差。
- 不同的方法采用不同的训练技术,如超参数调优、参数初始化、学习率衰减和早期停止。
为了更公平的比较,参考:Shchur et al. [131].
- 图分类中:使用双cv交叉验证法:(使用外部的k次折叠cv进行模型评估,使用内部的k次折叠cv进行模型选择)
应用领域
Computer vision
-
scene graph generation, (图像解析为由对象及其语义关系组成的语义图)
论文: [137], [138], [139].
论文: [140]给定场景图,生成真实图,利用文本描述生成场景图,接着生成真实图
-
point clouds classification, and
[141], [142],[143] 将点云转化为k近邻图或者超点图,利用图卷积研究其拓扑结构
-
action recognition
识别视频中包含的人类动作,一些解决方案可以检测视频剪辑中人体关节的位置,[73], [75] 使用 STGNNs学习人类的动作模式。
人-物交互[144]、少镜头图像分类[145]、[146]、[147]、语义分割[148]、[149]、视觉推理[150]、问题回答[151]。
Natural language processing
- 文本分类,利用文档或单词之间的相互关系来推断文档标签[22]、[42]、[43]
- 自然语言数据虽然是顺序结构的,但是也包含一个内部图结构(syntactic dependency tree.)
Traffic
在智能交通系统中,预测交通网络中的交通速度、交通量或道路密度是至关重要的。[48],[72],[74]使用STGNNs解决流量预测问题。
出租车需求预测。根据历史出租车需求、位置信息、天气数据和事件特征,从而预测某一时段内某一位置的出租车需求数量。
推荐系统
以项目和用户为节点,通过利用项目与项目、用户与用户、用户与项目以及内容信息之间的关系。关键是给物品对用户重要性进行打分,将其转换为一个edge预测问题。
V an et al. [161] and Ying et al. [162] propose a GAE 。Monti et al. [163] 。
Chemistry
其他
- program verification [17],
- program reasoning [166],
- social influence prediction [167],
- adversarial attacks prevention [168],
- electrical health records modeling [169], [170],
- brain networks [171],
- event detection [172], and
- combinatorial optimization [173].
未来方向
-
Model depth
由于图卷积将相邻节点的表示法推得更近,理论上,在无限个图卷积层的情况下,所有节点的表示法都将收敛于一个单点。这就提出了一个问题:对于学习图表数据来说,深入学习是否仍然是一个很好的策略。
-
Scalability trade-off
破坏图的完整性为代价,获得的GNN的可扩展性,无论是抽样还是聚类,模型都会丢失部分图的信息:抽样,一个节点可能会错过它的有影响的邻居;聚类,一个图可能被剥夺了一个独特的结构模式。、
-
Heterogenity异构性
当前大多数GNN采取同构图,很难将当前的GNNs应用到异构图中,需要开发新的方法来发展解决异构图处理。
-
动态图
STGNNs可以解决部分的图的动态性,但是很少考虑在动态空间关系下进行图卷积.