Hbase(一)入门
Hbase(一)
-
-
- 一.Hbase概述
-
- 1.简介
- 2.Hbase数据模型
- 3.Hbase简化架构
- 4.写数据
- 5.MemStore Flush
- 6.读数据
- 7.StoreFile Compaction
- 二.Hbase安装
-
- 1.Hbase安装
- 2.Hbase Master高可用
- 三.Hbase Shell
-
- 1.namespace
- 2.table
- 3.DML操作
- 四.Hbase Java API
-
一.Hbase概述
1.简介
当您需要对大数据进行随机、实时的读写访问时,请使用Apache HBase™。这个项目的目标是在商用硬件集群上托管非常大的表——数十亿行X百万列。Apache HBase是一个开源的、分布式的、版本化的、非关系型数据库
实时随机读写、NoSQL数据库、列存储、可存储海量数据
2.Hbase数据模型

如图,这就是Hbse的一张表
从列的角度看,首先要有列族(多个列组成的集合),有一个特殊的列Row_Key(类似于MySQL的主键)
从行的角度看,我们可以把一张表水平分为多个部分,每个部分就是一个Region,每个Region中的不同列族都是一个store,我们实际存储就是以store为单位存储的
一个region的数据时存在一台机器里面的,而一个region不同的store是存在不同文件里的
那store是怎么存的呢?
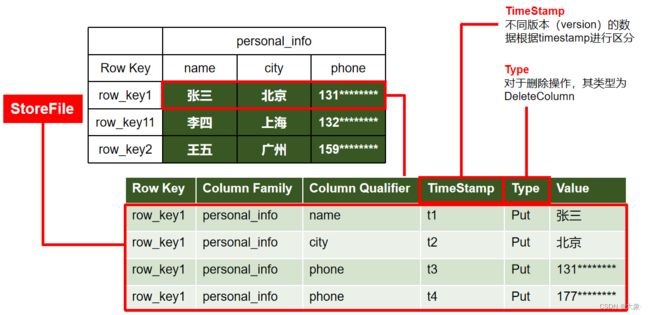
每个store是以行为单位进行列式存储,比如第一行,每一列的详细信息都会被存成一行,包括属于哪个Row_Key,哪个列族,属性名,时间戳,存储类型,具体的值
我们知道,Hbase底层是依赖HDFS的,而HFDS不支持修改,那我们怎么修改呢?实际上是假修改,实际是新增了一行,比如上图的电话,我们修改实际是新增一行,但是时间戳变了,我们读的时候读最新的时间戳的数据,所以修改对我们来说是个透明操作
Type:增加、修改都是Put类型,删除是Delete类型
再来看其他的一些概念
Name Space
命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间
Table
类似于关系型数据库的表概念。不同的是**,HBase定义表时只需要声明列族即可**,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景
Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要,Hbase只支持3种查询方式: 1、基于Rowkey的单行查询,2、基于Rowkey的范围扫描 ,3、全表扫描
Column
HBase中的每个列都由Column Family(列族)和Column Qualifier(列限定符,实际就是列名)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义
Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间,我们修改后读的最新数据就是通过时间戳确定的
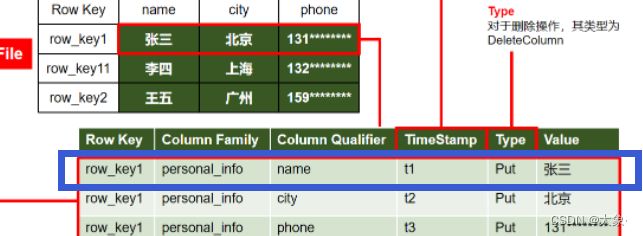
Cell
由{rowkey, column Family ,column Qualifier,Time Stamp} 唯一确定的单元。cell中的数据全部是字节码形式存储,下图蓝色部分
3.Hbase简化架构
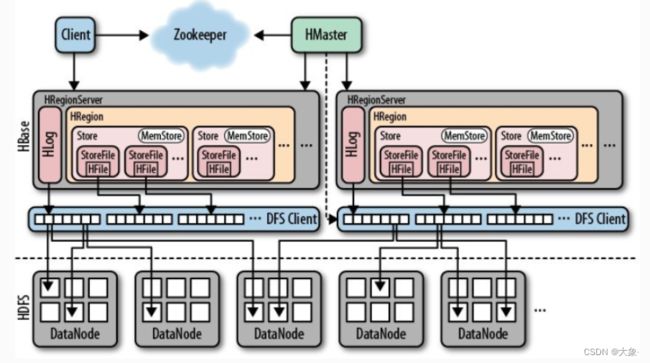
HRegionServer是Hbase中最核心的模块
-
管理多个
HRegion(一个Region对应某table中的一个Region)- 一个Region下有多个
Store(一个Store对应一个列族)- 一个Store里面有
MemStore(写缓存,K-V在Memstore中进行排序,达到阈值之后才会flush到StoreFile,每次flush生成一个新的StoreFile,由于这是在内存,可能由于故障数据丢失,为此在每个RegionServer中还会Hlog,记录所有写操作,万一MemStore数据丢失,Hlog中也有备份) - StoreFile底层是
Hfile,HFile为hdfs中的小文件,数量过大时,进行compact操作,合并成一个大文件
- 一个Store里面有
- 一个Region下有多个
-
负责响应用户IO请求,对数据操作,并且向HDFS文件系统中读写、删除、修改
-
SplitRegion, CompactRegion
-
有一个BlockCache(图中未标出):读缓存,每次新查询的数据会缓存在BlockCache中(LRU淘汰策略)
Hmaster
-
允许有多个master节点,使用zookeeper控制,保证只有一个master节点处于激活状态,当存活master机器宕机,其他的master节点向zookeeper竞争,成为存活的节点
-
管理用户对table的增,删,改,查操作
-
管理RegionServer的负载均衡,调整region分布
-
在Region分裂后,负责新region的分配
-
在RegionServer死亡后,负责对regionServer上的region的迁移
zookeeper
- 负责Hbase中多Hmaster的选举
- 实时监控RS的存活
- 存储Hbase的元数据信息
4.写数据
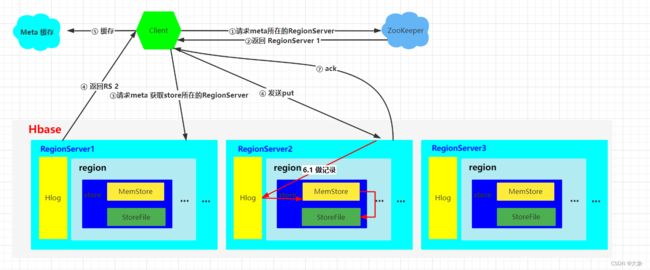
首先我们要清楚,我们写数据是写到一个HRegionServer里某一个region里的某个store里面,我们的目的就是找这个store
那我们首先要知道哪个RegionServer存了这个store,去问谁呢?去问元数据,也就是hbase下的meta这张表
那meta这张表的内容在哪里?它也是一张表啊,信息由ZooKeeper存储
5.MemStore Flush
1.当某个memstore的大小达到了hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写
当memstore的大小达到了
hbase.hregion.memstore.flush.size(默认值128M)×
hbase.hregion.memstore.block.multiplier(默认值4)
时,会阻止继续往该memstore写数据(写大量数据时)
2.当region server中memstore的总大小达到
java_heapsize
× hbase.regionserver.global.memstore.size(默认值0.4)
× hbase.regionserver.global.memstore.size.lower.limit(默认值0.95),
region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下
当region server中memstore的总大小达到
java_heapsize
× hbase.regionserver.global.memstore.size(默认值0.4)
时,会阻止继续往所有的memstore写数据
3.到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认1小时)
6.读数据
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server
2)访问对应的Region Server,获取hbase:meta表,根据读请求的
namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问
3)与目标Region Server进行通讯
4)分别在MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)
5)将查询到的新的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache
6)将合并后的最终结果返回给客户端
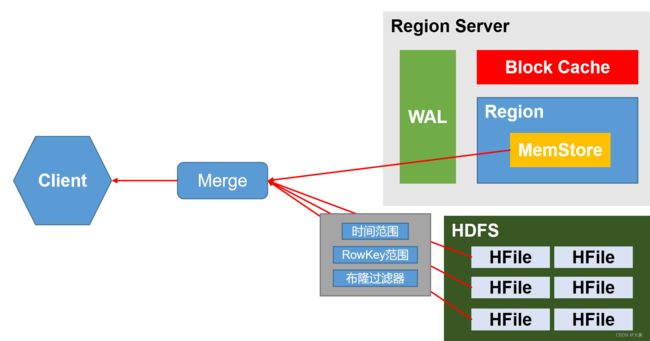
布隆过滤器会告诉你这个文件一定不存在某个数据,但不保证某数据存在,节省了时间
7.StoreFile Compaction
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction
Compaction分为两种,分别是Minor Compaction和Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。Major Compaction会将一个Store下的 所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据
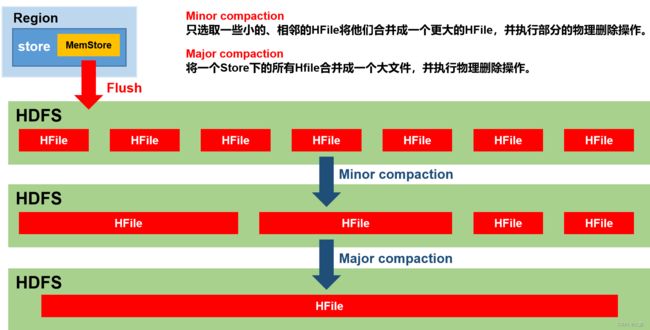
默认每次flush都会进行小合并,大合并则是周期性的(默认7天)
二.Hbase安装
1.Hbase安装
解压hbase
sudo vim /etc/profile.d/my_env.sh
添加环境变量
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
HBase的配置文件
1.hbase-env.sh修改内容:
export HBASE_MANAGES_ZK=false
2.hbase-site.xml修改内容:
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://hadoop102:8020/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>hadoop102,hadoop103,hadoop104value>
property>
configuration>
3.修改regionservers
vim regionservers
hadoop102
hadoop103
hadoop104
将上述改动的地方分发到另外即机器
启动ZooKeeper和Hadoop集群
进入Hbase的bin目录下
start-hbase.sh
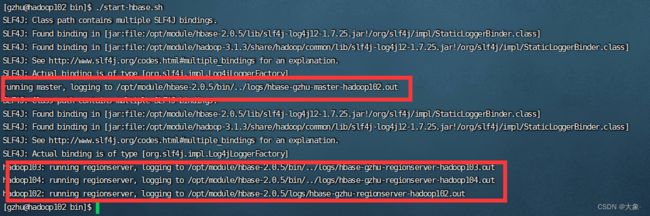
可以看到ZooKeeper上存储了一些信息
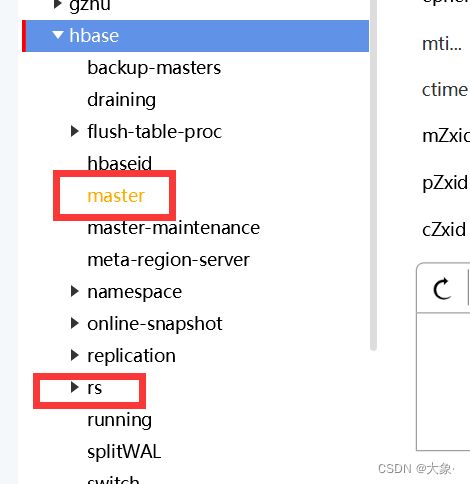
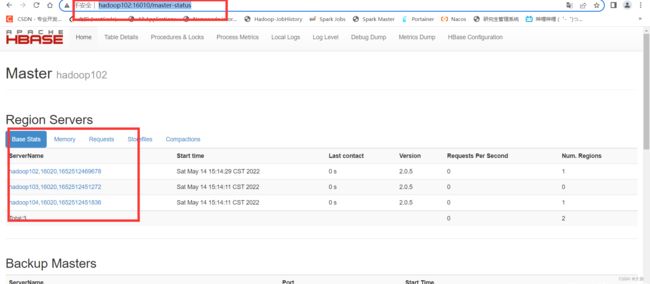
2.Hbase Master高可用
在HBase中HMaster负责监控HRegionServer的生命周期,均衡RegionServer的负载,如果HMaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对HMaster的高可用配置
1.关闭HBase集群(如果没有开启则跳过此步)
bin/stop-hbase.sh
2.在conf目录下创建backup-masters文件
vim conf/backup-masters
配置hadoop103
保存退出
可以看到两台机器都启动了master

三.Hbase Shell
1.namespace

创建namespace
第一种是创建普通的namespace,第二种是创建namespace的时候指定一些自定义的属性
create_namespace 'ns1'
create_namespace 'ns1', {'PROPERTY_NAME'=>'PROPERTY_VALUE'}
修改namespace属性
To add/modify a property:
alter_namespace 'ns1', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
To delete a property:
alter_namespace 'ns1', {METHOD => 'unset', NAME=>'PROPERTY_NAME'}
查看当前Hbase中有哪些namespace
list_namespace
查看某个具体的namespace
hbase> describe_namespace 'ns1'
删除namespace
drop_namespace "ns1"
查看namespace下的表
list_namespace_tables 'ns1'
注意: 要删除的namespace必须是空的,其下没有表
2.table
![]()
创建表
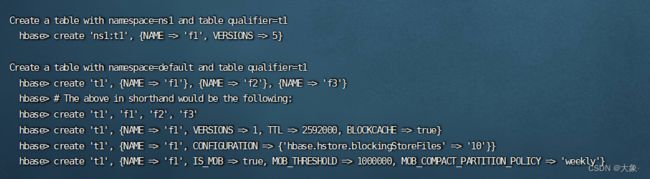
上图已经说的很详细了
create ‘ns1:t1’ 在namespace ns1下创建一张表t1
由于创建表必须要指定列族(不必指定列,列式动态的)
所以一个中括号就是指定一个列族,还可以包括这个列族的一些其他信息比如{NAME =>‘f1’,VERSIONS =>5}就是指定了一个列族f1并指明了保留最新的5个版本(修改数据实际是put了一条新数据,旧的数据会被清理,但会保留最新的5个版本)
查看表
describe 'ns1:t1'
修改表
# 修改列族f1的属性
hbase> alter 'ns1:t1', NAME => 'f1', VERSIONS => 5
# 修改多个列族
hbase> alter 'ns1:t1', 'f1', {NAME => 'f2', IN_MEMORY => true}, {NAME => 'f3', VERSIONS => 5}
# 删除某个列族
hbase> alter 'ns1:t1', NAME => 'f1', METHOD => 'delete'
hbase> alter 'ns1:t1', 'delete' => 'f1'
# 修改表的作用属性
hbase> alter 'ns1:t1', MAX_FILESIZE => '134217728'
#添加列族
hbase> alter 'ns1:t1',NAME=>'f2',VERSIONS=>'2'
删除表
disable 'ns1:t1'
drop 'ns1:t1'
3.DML操作
下表tbl有两个列族,实际上列族少一点比较好

插入数据
注意,是插入了一列,并不是一行,c1要指定哪个列族的哪个列
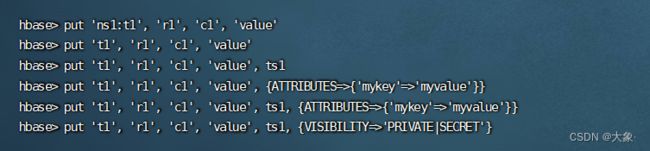
向mydb下的表mytbl,指定row_key为100,列族f1下的列name值为kun
put 'mydb:mytbl' ,'100','f1:name','kun'
向mydb下的表mytbl,指定row_key为100,列族f1下的列age值为23
put 'mydb:mytbl' ,'100','f1:age','23'
向mydb下的表mytbl,指定row_key为100,列族f2下的列tel值为17845612
put 'mydb:mytbl' ,'100','f2:tel','17845612'
查询数据

根据row_key查询一行

根据row_key查询一行的部分列(可以跨列族)

扫描表


可以根据row_key的范围进行扫描,STARTROW是闭,STOPROW是开,由于row_key是字典排序的,我们一般查询某个字段的STOPROW是,一般加个!,因为!的ASCII码几乎是最小的。STOPROW一般加个 | 因为 | 的 ASCII几乎是最大的

修改表
其实就是put了一条新数据,旧的数据没有立即删除,根据时间戳显示最新版本

put 'mydb:mytbl','100','f1:name','song'

如何查看旧的版本?
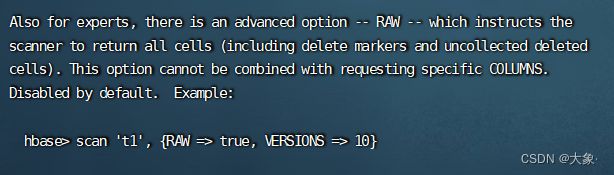
删除数据
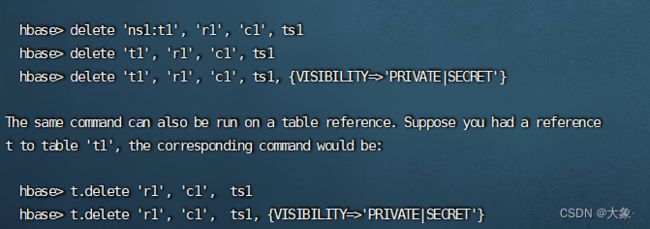
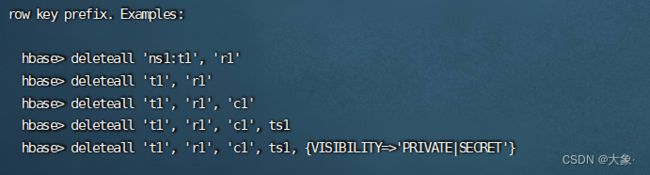
删除某一列的某个版本的数据标记是Delete
delete 'ns1:t1','row_key','cf:cl'
删除一列的全部版本标记是DeleteColumn
deleteall 'ns1:t1','row_key','cf:cl'
删除列族标记是DeleteFamily
deleteall 'ns1:t1','row_key'
四.Hbase Java API
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>2.0.5version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>2.0.5version>
dependency>
获取Hbase连接
private Connection connection;
private Admin admin;
@Before
public void initConn(){
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");
try {
connection = ConnectionFactory.createConnection(conf);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
创建namespace
public static void createNameSpace (String name) throws IOException {
Admin admin = connection.getAdmin();
NamespaceDescriptor.Builder builder = NamespaceDescriptor.create(name);
NamespaceDescriptor descriptor = builder.build();
// 命名空间数组
NamespaceDescriptor[] descriptors = admin.listNamespaceDescriptors();
try {
admin.createNamespace(descriptor);
}catch (NamespaceExistException e){
System.out.println("命名空间已经存在!");
}
}
表的操作
public class Table {
private Connection connection;
private Admin admin;
@Before
public void initConn(){
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");
try {
connection = ConnectionFactory.createConnection(conf);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
// 创建表
public void createTable(String namespace,String tblName,String ... cfs) throws IOException {
if(existsTable(namespace,tblName)) System.err.println("表"+tblName+"已存在!");
TableDescriptorBuilder tableDescriptorBuilder =
TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace, tblName));
if(cfs == null || cfs.length < 1){
System.err.println("至少指定一个列族");
return;
}
for (String cf : cfs) {
ColumnFamilyDescriptorBuilder cfDescriptorBuilder =
ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(cf));
ColumnFamilyDescriptor columnFamilyDescriptor = cfDescriptorBuilder.build();
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor);
}
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
admin.createTable(tableDescriptor);
}
// 判断表是否存在
public boolean existsTable(String namespace,String tableName) throws IOException {
return admin.tableExists(TableName.valueOf(namespace, tableName));
}
public void dropTable(String namespace,String tabName) throws IOException {
if(!existsTable(namespace, tabName)){
System.out.println("表不存在!");
}
admin.deleteTable(TableName.valueOf(namespace,tabName));
}
@Test
public void createTableTest() throws IOException {
createTable("mydb1","tbl1","cf1","cf2");
}
@After
public void close() throws IOException {
admin.close();
}
}
DML
public class DMLTest {
private Connection connection;
private Admin admin;
@Before
public void initConn(){
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");
try {
connection = ConnectionFactory.createConnection(conf);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
// 增加 修改
public void putData(String namespace,String tabName,String rowKey,String cf,String cl,String value) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tabName));
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cl),Bytes.toBytes(value));
table.put(put);
table.close();
}
// 删除数据
public void deleteData(String namespace,String tabName,String rowKey,String cf,String cl) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tabName));
// 删除一行数据 标记是DeleteFamily
Delete delete = new Delete(Bytes.toBytes(rowKey));
// 删除某一行的某个列族下的数据 添加这个属性
delete.addFamily(Bytes.toBytes(cf));
/* // 删除某一行某个列族下某一列某个版本的数据 添加这个属性
delete.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cl));
// 删除某一行某个列族下某一列全部版本的数据 添加这个属性
delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cl));*/
table.delete(delete);
}
// get
public void getData(String namespace,String tabName,String rowKey,String cf,String cl) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tabName));
// 查一行
Get get = new Get(Bytes.toBytes(rowKey));
/*// 查某个列族添加如下属性
get.addFamily(Bytes.toBytes(cf));*/
// 查某一列添加如下属性
get.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cl));
Result result = table.get(get);
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println(
Bytes.toString(CellUtil.cloneRow(cell)) + // row_key
Bytes.toString(CellUtil.cloneFamily(cell)) + // 列族
Bytes.toString(CellUtil.cloneQualifier(cell)) +// 列名
Bytes.toString(CellUtil.cloneValue(cell)));// 值
}
}
public void scanData(String namespace,String tabName,String rowKey,String cf,String cl) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tabName));
Scan scan = new Scan();
// 可以指定某个列族,某个列
/* scan.addColumn();
scan.addFamily()*/
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
System.out.println(
Bytes.toString(CellUtil.cloneRow(cell)) + // row_key
Bytes.toString(CellUtil.cloneFamily(cell)) + // 列族
Bytes.toString(CellUtil.cloneQualifier(cell)) +// 列名
Bytes.toString(CellUtil.cloneValue(cell)));// 值
}
}
}
@Test
public void addData() throws IOException {
putData("mydb1","tbl1","1","cf1","name","song");
}
@Test
public void deleteData() throws IOException {
deleteData("mydb1","tbl1","1","cf1","");
}
@Test
public void get() throws IOException {
getData("mydb1","tbl1","1","cf1","age");
}
@After
public void close() throws IOException {
admin.close();
}
}