今天在多个数据库当中迁移数据的时候碰到了一张表中有上千万的数据,记录下迁移的心得体会,讲的不对的地方批评指正,感激不尽,
需求:在两个不同的数据库中把数据从库1copy到库2,两个库的表完全一致(表名和表结构),数据一千万.
要点:批处理 + 批量SQL
批处理:
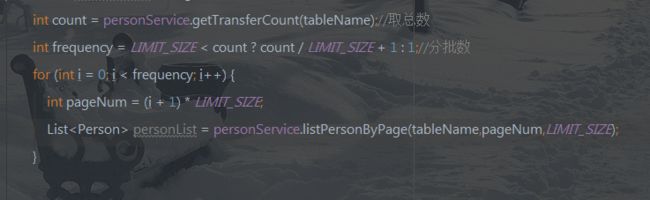
这里注意一个地方:
根据limit查询数据的时候当数据量越大的时候,limit越慢,千万级数据的数据,都后面就只能 呵呵呵……
优化查询语句:
![]()
当查询分页的offset越大的时候,查询的越慢,而且外面唯有假order by的时候默认就是按照ID升序排序的,所以当我们先找到了上次分页的最大ID的数据的时候,就可以缩小查询范围了。
批量SQL:
相信批量SQL大家都有很多心得,这里咱们就用最简单的批量SQL,insert into 表名 (字段1,字段2,……) values(),(),……
查询出的对象最好映射成map类型,然后遍历拼接value的字段,对于类型不同的数据都可以用单引号拼接上去,但是要注意空值,对于空值需要直接拼null(不要用单引号括起来),有多线程的经验的也可以使用多线程拼接,注意并发就可以啦!
Java新手上路,如果有不对的地方,欢迎大伙批评指出!