7天算法刷题
算法刷题《hot100》
第①天
☆215 数组中的第K个最大元素(堆排序思想,快速排序双指针思想)√(注意掌握堆排序)
/**
【重要】堆排序
1.前k个元素实现小根堆,
2.后面元素与堆顶元素比较,,当大于堆顶元素,替换堆顶元素重新建堆
最后堆顶元素就是第k大的元素
堆排序
从最后一个分支节点开始手动向下调整
*/
class Solution {
public int findKthLargest(int[] nums, int k) {
//初始建立大小为k的小根堆
for(int i=k/2-1;i>=0;i--){
downAdjust(nums,i,k);
}
//后面元素与堆顶元素比较
for(int i=k;i<nums.length;i++){
if(nums[i]>nums[0]){
swap(nums,i,0);
downAdjust(nums,0,k);
}
}
return nums[0];
}
public void downAdjust(int[] nums,int pos,int len){
//pos为初始节点下标,son为其孩子节点下标
//判断是否比左右孩子节点小
for(int son=pos*2+1;son<len;son=son*2+1){
if(son+1<len&&nums[son+1]<nums[son]){
son++;
}
if(nums[son]<nums[pos]){
swap(nums,pos,son);
pos=son;
}else{
break;
}
}
}
public void swap(int[] nums,int i,int j){
int tmp=nums[i];
nums[i]=nums[j];
nums[j]=tmp;
}
}
/*
two:
迭代,快速排序双指针法
*/
class Solution {
public int findKthLargest(int[] nums, int k) {
return findpos(nums,0,nums.length-1,nums.length-k);
}
public int findpos(int[] nums,int left,int right,int pos){
if(left<right){
//双指针法查找枢纽值位置,index及其左边的元素都小于nums[left]
int index=left;
for(int i=left+1;i<=right;i++){
if(nums[i]<nums[left]){
swap(nums,i,++index);//【关键】++index的理解,其实是对left+1到right的元素进行遍历交换
}
}
swap(nums,left,index);
//类quicksort思想
if(index==pos){
return nums[index];
}else if(index>pos){
return findpos(nums,left,index-1,pos);
}else{
return findpos(nums,index+1,right,pos);
}
}
return nums[left];
}
public void swap(int[] nums,int i,int j){
int tmp=nums[i];
nums[i]=nums[j];
nums[j]=tmp;
}
}
【知识点】
- PriorityQueue的用法
//1.默认为小根堆
PriorityQueue<Integer> minHeap=new PriorityQueue<>((o1,o2)->o1-o2);//默认为小根堆,
//2.大根堆
PriorityQueue<Integer> maxHeap=new PriorityQueue<>((o1,o2)->o2-o1);
//3.常见操作
minHeap.offer(object);
minHeap.poll();
minHeap.remove(object);
minHeap.contains(object);
- 快速排序两种写法的递归版本
//快速排序1:常规写法
public static void quicksort1(int[] nums,int left,int right){
if(left<right){
//partition
int low=left,high=right;
int pivot=nums[left];
while(low<high){
while(low<high&&nums[high]>=pivot) high--;
nums[low]=nums[high];
while(low<high&&nums[low]<=pivot) low++;
nums[high]=nums[low];
}
nums[low]=pivot;
//quicksort
quicksort1(nums,left,low-1);
quicksort1(nums,low+1,right);
}
}
//快速排序2:双指针写法
public static void quicksort2(int[] nums,int left,int right){
if(left<right){
//partition寻找枢纽值,双指针遍历,只能采取交换
int index=left;//【关键】index及其左边的字符都<=nums[left]
for(int i=left+1;i<=right;i++){
if(nums[i]<nums[left]){
swap(nums,i,++index);
}
}
swap(nums,left,index);
//quicksort
quicksort2(nums,left,index-1);
quicksort2(nums,index+1,right);
}
}
public static void swap(int[] nums,int i,int j){
int tmp=nums[i];
nums[i]=nums[j];
nums[j]=tmp;
}
- 堆排序思想
//堆排序,大根堆+升序
//升序,大根堆
public static void heapsort(int[] nums){
//初始建立大根堆
for(int i=nums.length/2-1;i>=0;i--){//【易错】最后一个分支节点,为下标
downadjust(nums,i,nums.length);
}
//堆排序
for(int j=nums.length-1;j>0;j--){//【关键】循环条件j>0理解
swap(nums,0,j);
downadjust(nums,0,j);
}
}
//向下调整
public static void downadjust(int[] nums,int pos,int len){
//pos为初始父节点下标
//判断左右子节点是否比根大
for(int son=pos*2+1;son<len;son=son*2+1){//判断左孩子存在
if(son+1<len&&nums[son+1]>nums[son]) son++;//右孩子存在且大于左孩子
if(nums[pos]<nums[son]){
swap(nums,pos,son);
pos=son;
}else{
break;//当本节点大于左右孩子
}
}
}
public static void swap(int[] nums,int i,int j){
int tmp=nums[i];
nums[i]=nums[j];
nums[j]=tmp;
}
/*数组中第K大的元素->数组中第pos=nums.length-k小(位置,下标)的元素
1.先对前面pos个元素建大根堆,
2.后面的元素,当比堆顶元素小时,和堆顶元素交换;
3.对堆顶执行向下调整
*/
3无重复字符的最长子串(双指针滑动窗口+map一次遍历)√(采用map,无需删除元素,采用下标更新)
class Solution {
public int lengthOfLongestSubstring(String s) {
if(s.length()==0) return 0;
if(s.length()==1) return 1;
Map<Character,Integer> map=new HashMap<>();
map.put(s.charAt(0),0);
int maxsublength=1;
for(int i=0,j=1;j<s.length();j++){
//有重复
if(map.containsKey(s.charAt(j))){
//1.重复元素在当前最大不重复子段中,i滑动到重复元素的后一个位置
//【关键】2.重复元素不在当前最大不重复子段中(map中元素没有删除),左指针不应该变,【左指针更新不能回退】
i=Math.max(i,map.get(s.charAt(j))+1);
}
//1.没有重复,将s.charAt(j)加入map
//2.有重复,更新重复元素在map中的下标
map.put(s.charAt(j),j);
maxsublength=maxsublength>j-i+1? maxsublength:j-i+1;
}
return maxsublength;
}
}
146 LRU缓存机制(Map存储+双向链表维护顺序)√(注意节点定义)
/**
1.采用链表将所有节点链接起来
节点设计
当插入和更新,获取节点,当前访问节点移到链表头结点
删除最近最久未访问节点
2.采用Map存储所有节点,判断所有节点是否存在
*/
class LRUCache {
int capacity;
int size;
Map<Integer,ListNode> map=new HashMap<>();
ListNode head=new ListNode(-1,-1);
ListNode tail=new ListNode(-1,-1);
public LRUCache(int capacity) {
this.capacity=capacity;
this.size=0;
head.next=tail;
tail.pre=head;
}
public int get(int key) {
if(map.containsKey(key)){
moveToFirst(head,map.get(key));
return map.get(key).value;
}
return -1;
}
public void put(int key, int value) {
//如果是新节点,添加到头部
if(!map.containsKey(key)){
//如果超出capacity,删除尾部节点
if(capacity==size){
map.remove(tail.pre.key); //【易错】map先删除节点后,链表再删除
tail.pre.pre.next=tail;
tail.pre=tail.pre.pre;
size--;
}
ListNode node=new ListNode(key,value);
node.next=head.next;
head.next.pre=node;
node.pre=head;
head.next=node;
map.put(key,node);
size++;
}else{ //旧节点,更新value值,移动到头部
map.get(key).value=value;
moveToFirst(head,map.get(key));
}
}
public void moveToFirst(ListNode head,ListNode node){
node.pre.next=node.next;
node.next.pre=node.pre;
node.next=head.next;
head.next.pre=node;
node.pre=head;
head.next=node;
}
}
class ListNode{
int key;
int value;
ListNode pre=null;
ListNode next=null;
public ListNode(){
}
public ListNode(int key,int value){
this.key=key;
this.value=value;
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
☆15 三数之和(一次遍历+类两数之和做法,注意去除重复元素)√
1.排序
2.遍历数组中每一个元素,与此同时从当前元素后面寻找两数之和为0-nums[i];
即nums[i]+(nums[left]+nums[right])==0;
采用双指针方法
/*
合并写在一个函数内部
*/
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> ret=new ArrayList<>();
Arrays.sort(nums);
for(int i=0;i<nums.length;i++){
if(i>0&&nums[i]==nums[i-1]) continue;//【关键】重复元素的跳过处理
//两数之和相同做法
int left=i+1,right=nums.length-1;
while(left<right){
int sumThree=nums[i]+nums[left]+nums[right];
if(sumThree==0){
ret.add(new ArrayList<Integer>(Arrays.asList(nums[i],nums[left],nums[right])));//【知识点】ArrayList带初值的初始化
//【关键:好的处理】成功找到以后,仍然继续寻找,i为下一个不为nums[i]的位置,j为下一个不为nums[j]的位置
while(left<right&&nums[left]==nums[++left]);
while(left<right&&nums[right]==nums[--right]);
}else if(sumThree<0){
left++;
}else{
right--;
}
}
}
return ret;
}
}
102 二叉树的层序遍历(levelsize一次处理一层)√
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
/*层序遍历,
逐层访问,一次访问一层所有节点
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> ret=new ArrayList<List<Integer>>();
if(root==null) return ret;
Queue<TreeNode> queue=new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()){
List<Integer> list=new ArrayList<Integer>();
int levelsize=queue.size();
while(levelsize--!=0){
TreeNode node=queue.poll();
list.add(node.val);
if(node.left!=null) queue.offer(node.left);
if(node.right!=null) queue.offer(node.right);
}
ret.add(new ArrayList(list));//【知识点】复制一个ArrayList到list
}
return ret;
}
}
*******************************************************************************************************************************************************************************************************************
200岛屿数量(网格类dfs通用解法:岛屿数量、最大岛屿面积、填海造陆、岛屿周长)√
- 岛屿数量
class Solution {
public int numIslands(char[][] grid) {
if(grid==null||grid.length==0) return 0;
int num_islands=0;
for(int r=0;r<grid.length;r++){
for(int c=0;c<grid[0].length;c++){
if(grid[r][c]!='1') continue;//【关键】遍历时不适合的节点直接跳过回溯
++num_islands;//【关键】出现适合的节点,只要出现了一个1,就代表有一个岛屿,而且这个岛屿至少有一个陆地;dfs标记它所有的陆地
dfs(grid,r,c);
}
}
return num_islands;
}
public void dfs(char[][] grid,int r,int c){
//1.判断base case:不在网格中,越界返回
if(r<0||r>=grid.length||c<0||c>=grid[0].length) return;
//2.如果这个格子不是岛屿,是海洋或者已经访问过的岛屿,返回
if(grid[r][c]!='1') return;
//3.是未访问过的岛屿
grid[r][c]='2';//标记为已经访问过
//访问上、下、左、右四个相邻节点,递归
dfs(grid,r-1,c);
dfs(grid,r+1,c);
dfs(grid,r,c-1);
dfs(grid,r,c+1);
}
}
33 搜索旋转排序树组(二分法+利用有序一半数组判断接下来的查找区间)√
/*
搜索旋转排序数组(数组中的值 互不相同)
设计一个时间复杂度为 O(log n) 的解决方案
二分法
1.确定left到mid和mid+1到right哪一个是有序的
【关键】2.根据有序的部分确定接下来的查找区间
*/
class Solution {
public int search(int[] nums, int target) {
int left=0;
int right=nums.length-1;
while(left<=right){//【易错】二分查找是需带等号
int mid=left+(right-left)/2;
if(nums[mid]==target) return mid;
//1.确定left~mid和mid+1到right哪一个是有序的
//【关键】2.根据有序的部分确定接下来的查找区间
if(nums[left]<nums[mid]){//左边是有序区间
if(target>=nums[left]&&target<nums[mid]){//target在左边有序区间内
right=mid-1;
}else{
left=mid+1;
}
}else{//右边是有序区间
if(mid+1<=right&&target>=nums[mid+1]&&target<=nums[right]){//target在右边有序区间内 //【易错】mid+1可能越界
left=mid+1;
}else{
right=mid-1;
}
}
}
return -1;
}
}
300 最长上升子序列(动态规划,子序列可不连续)√
/*
最长递增子序列——元素没有顺序,【关键】可不连续
动态规划
1.参数
F[k]为以nums[k]为尾部元素的最长递增子序列
2.递推方程
当nums[k]>=nums[i]时,F[k]=Math.max(F[k],F[i]+1); i取值从0到k-1;
当没有nums[i]比nums[k]小的时候,F[k]=1;
3.初值条件
F[0]=1;
*/
class Solution {
public int lengthOfLIS(int[] nums) {
if(nums.length<=1) return nums.length;
int[] F=new int[nums.length];
F[0]=1;
int maxlen=0;
for(int k=1;k<nums.length;k++){
F[k]=1;
for(int i=0;i<k;i++){//【关键】当前位置需要用到前面所有位置的结果
if(nums[i]<nums[k]){//严格递增,不能等于
F[k]=Math.max(F[k],F[i]+1);
}
}
maxlen=maxlen>F[k]? maxlen:F[k];
}
return maxlen;
}
}
最长递增子序列,输出maxlen和子序列元素集合
public List<Integer> lengthOfLIS(int[] nums) {
if(nums.length==0) return new ArrayList<Integer>();
if(nums.length==1) return new ArrayList<>(Arrays.asList(nums[0]));
int[] F=new int[nums.length];
int[] mark=new int[nums.length];//【关键】标记函数,记录最长递增子序列当前元素的前一个元素的数组下标
Arrays.fill(mark,-1);
F[0]=1;
int maxlen=0;
int maxpos=0;//maxpos为最长递增子序列的最后一个元素下标
for(int k=1;k<nums.length;k++){
F[k]=1;
for(int i=0;i<k;i++){//【关键】当前位置需要用到前面所有位置的结果
if(nums[i]<nums[k]&&F[i]+1>F[k]){
F[k]=F[i]+1;
mark[k]=i;//标记函数
}
if(maxlen<F[k]){
maxlen=F[k];
maxpos=k;
}
}
}
List<Integer> ret=new ArrayList<>();
ret.add(nums[maxpos]);
while(mark[maxpos]!=-1){//【小难点】在每个节点中存储前一个节点的值
ret.add(nums[mark[maxpos]]);
maxpos=mark[maxpos];
}
return ret;
}
☆2 链表两数相加(遍历两个链表,考虑进位+都遍历到null才跳出循环)
/*
两个数字,用链表倒序表示
遍历两个链表
1.当两个链表节点都不为null时,val相加,考虑进位
2.当有一个链表为null后,另一个不为null的链表节点和进位相加,考虑进位
3.当两个都为null后,考虑是否有进位
*/
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode head=new ListNode(-1);
ListNode r=head;
int tmp=0;//表示进位;
//【关键】不是常见的while(l1!=null&&l2!=null),遍历到有一个链表为null就跳出,因为后面tmp和另一个不为null的链表仍然可能产生进位
while(l1!=null||l2!=null){//同时为null,才能跳出循环
int l1num=l1==null? 0:l1.val;
int l2num=l2==null? 0:l2.val;
int sum=l1num+l2num+tmp;
tmp=sum>=10? 1:0;
sum=sum%10;
r.next=new ListNode(sum);
r=r.next;
if(l1!=null) l1=l1.next;
if(l2!=null) l2=l2.next;
}
//最后一位有多余进位
if(tmp==1){
r.next=new ListNode(1);
}
return head.next;
}
}
56 合并区间(排序+区间右端点大于等于上一个区间左端点合并)√
/*排序+双指针
1.将数组interval里面的区间按照区间左端点进行排序
2.当当前右端点大于后一个区间的左端点时,这两个区间可以合并;循环,找到可以合并的第一个区间和最后一个区间
*/
class Solution {
public int[][] merge(int[][] intervals) {
List<int[]> ret=new ArrayList<>();
//排序
Arrays.sort(intervals,new Comparator<int[]>(){
public int compare(int[] o1,int[] o2){
return o1[0]-o2[0];
}
});
ret.add(intervals[0]);
//合并区间
for(int i=1;i<intervals.length;i++){
if(intervals[i][0]<=ret.get(ret.size()-1)[1]){
ret.get(ret.size()-1)[1]=Math.max(ret.get(ret.size()-1)[1],intervals[i][1]); //合并区间的右端点的处理
}else{
ret.add(intervals[i]);
}
}
int[][] arr=new int[ret.size()][];
for(int i=0;i<ret.size();i++){
arr[i]=ret.get(i);
}
return arr;
}
}
第②天
236 二叉树的最近公共祖先(后序遍历+DFS)
/**
普通二叉树的最近公共祖先
后序遍历
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
return postorder(root,p,q);
}
public TreeNode postorder(TreeNode root,TreeNode p,TreeNode q){
//递归出口
if(root==null) return null;
TreeNode left=postorder(root.left,p,q);
TreeNode right=postorder(root.right,p,q);
//当前节点的处理
if(root.val==p.val||root.val==q.val){
return root;
}else if(left!=null&&right==null){
return left;
}else if(left==null&&right!=null){
return right;
}else if(left!=null&&right!=null){
return root;
}else{
return null;
}
}
}
☆142 环形链表2(快慢指针寻找第一次相遇+head和slow通同步遍历寻找入环节点)
/*
【快慢指针】
仅仅是判断有没有环,还需要找出入环的第一个节点
1.快慢指针判断有没有环,找到第一次相遇的节点
2.双指针,一个指针从head开始走,一个指针从第一次相遇的节点开始走,第二次相遇的节点就是入环节点
【题型归纳】——双指针
1.寻找距离尾部第K个节点
2.寻找环入口
3.寻找公共尾部节点
one【双指针第一次相遇】
1.fast走过链表末端,说明链表无环,直接返回null
2.有环,fast指针一定能够追上slow指针
A设链表共有a+b个节点,链表头部到链表入口有a个节点(不计链表入口节点),链表环有b个节点
B从第一步到相遇fast指针和slow指针分别走了f,s步,有:
fast走的步数是slow步数的2倍,f=2s(不含head节点)
fast比slow多走n个环的长度(n未知),f=s+nb(双指针都走过a步,然后在环内绕圈直到重合,重合是fast比slow多走“环的长度整数倍”
两式相减:f=2nb,s=nb。
即fast和slow指针分别走了2n,n个环的周长。n未知,不同链表不同
two【入环节点步数分析】
1.如果让指针从链表头部一直向前走并统计步数k,那么“所有走到链表入口节点的步数”是:k=a+nb。(先走a步到达入环节点,之后每绕一圈(b步),都会再次到达入口节点)
2.第一次相遇后,slow指针恰好走了nb步,slow此时再走a步就能,到达入口节点。
【难点】不知道a是多长
【性质】再构造一个指针,和slow一起走a步,恰好在入环节点重合。而从head往到入口节点恰好需要走a步。
three【算法】
1.slow和fast判断有无环,寻找第一次相遇的节点
2.定义一个新指针从head开始,和slow一起走a步,恰好在入环节点相遇。
为了减少空间使用,后面新指针可以用fast来代替。
*/
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode slow=head;
ListNode fast=head;
//寻找第一次相遇的节点
while(true){//【好的处理】一开始相等,跳出循环是下一次相等
//判断无环
if(fast==null||fast.next==null) return null;
slow=slow.next;
fast=fast.next.next;
if(slow==fast) break;
}
//寻找入环节点
fast=head;//【关键】
while(fast!=slow){
fast=fast.next;
slow=slow.next;
}
return slow;
}
}
46 全排列(回溯与剪枝、排列树,每层利用for循环+标记数组遍历+DFS)
/**
回溯与剪枝
排列树
1.搜索空间,dfs,完全二叉树,n层,每层有n个空间(考虑排列树)
2.约束条件:
满足约束条件,一直递归,直到递归出口
不满足约束条件,回溯(不满足约束条件,如元素已使用提前回溯,还有递归完正常回溯
*/
class Solution {
List<List<Integer>> ret=new ArrayList<>();
public List<List<Integer>> permute(int[] nums) {
int[] mark=new int[nums.length];
for(int i=0;i<mark.length;i++){
mark[i]=0;
}
dfs(nums,mark,1,new ArrayList<Integer>());
return ret;
}
public void dfs(int[] nums,int[] mark,int n,List<Integer> list){
//递归出口
if(n>nums.length){
ret.add(new ArrayList<Integer>(list));
}
//当前层节点遍历
for(int i=0;i<nums.length;i++){
//重复节点的处理
if(mark[i]!=0) continue;
//当前节点的处理
mark[i]=1;
list.add(nums[i]);
dfs(nums,mark,n+1,list);
//回溯
list.remove(list.size()-1);
mark[i]=0;
}
}
}
5 最长回文子串(动态规划法、中心扩展法)
/**
中心扩展法
回文子串包含两种:奇数和偶数
*/
class Solution {
public String longestPalindrome(String s) {
int maxLength=1;
int start=0,end=0;
//中心扩展,一次遍历
for(int i=0;i<s.length();i++){
int curLength1=countLength(s,i-1,i+1); //奇数
int curLength2=1;
if(i+1<s.length()&&s.charAt(i)==s.charAt(i+1)){ //偶数
curLength2=countLength(s,i,i+1);
}
int curLength=Math.max(curLength1,curLength2);
if(curLength>maxLength){
maxLength=curLength;
if(maxLength%2==0){ //偶数
start=i-maxLength/2+1;
end=i+maxLength/2;
}else{ //奇数
start=i-maxLength/2;
end=i+maxLength/2;
}
}
}
return s.substring(start,end+1);
}
//中心扩展法,判断回文子串的长度
public int countLength(String s,int left,int right){
while(left>=0&&right<=s.length()-1&&s.charAt(left)==s.charAt(right)){
left--;
right++;
}
return right-left-1;
}
}
/*动态规划
1.参数p[i][j]表示字符串s的第i到第j个字母组成的串s[i][j]是否为回文串
2.递推方程,由内到外,由小到大:
d[i][j]=d[i+1][j-1]&&s[i]==s[j]
3.初值条件
p[i][i]=true;
p[i][i+1]=(s[i]==s[j]);
注意:在状态转移方程中,我们是从长度较短的字符串向长度较长的字符串进行转移的——一定要注意动态规划的循环顺序。
就像希尔排序:
先循环步长,计算每一个长度较短的字符串是否为回文串,再计算后面长度较长的字符串是否为回文串
[复杂度分析]
o(n^2),动态规划的状态总数为o(n^2);对于每个状态,我们需要转移的时间为o(1);
[空间复杂度]
o(n^2),即动态规划状态需要的空间
*/
class Solution {
public String longestPalindrome(String s) {
//长度为1或0
if(s.length()<2) return s;
boolean[][] dp=new boolean[s.length()][s.length()];
//dp初值条件1:所有长度为1的子串都是回文串
for(int i=0;i<s.length();i++){
dp[i][i]=true;
}
int maxlen=1;//记录最大回文子串长度
int begin=0;//记录最大回文子串起始位置
//首先循环限定步长
for(int step=2;step<=s.length();step++){//【易错】此处step最大可以为s.length,而不是
//1.再遍历s中所有步长为step的子串,判断s[i][j]是否为回文串
for(int i=0;i<s.length();i++){//子串左边界
int j=i+step-1;//子串右边界,由i和step确定
if(j>=s.length()) break;//右边界越界
if(s.charAt(i)!=s.charAt(j)){
dp[i][j]=false;
}else{
if(j-i+1==2){//【关键】初始条件2:字符串为两个字符,当s[i]==s[j]时,为回文串。防止下面d[i+1][j-1]出现i+1>j-1的越界情况
dp[i][j]=true;
}else{//字符串字符数大于2
dp[i][j]=dp[i+1][j-1];
}
}
//2.若是回文子串,判断是否更新maxlength和begin
if(dp[i][j]&&j-i+1>maxlen){
maxlen=j-i+1;
begin=i;
}
}
}
return s.substring(begin,begin+maxlen);
}
}
/*
中心扩展算法
1.从动态规划可知,所有的状态在转移的时候的可能性都是唯一的——也就是说我们可以从每一种边界情况开始扩展,也可以得出所有状态对应的答案
2.边界情况:即为子串长度为1或者2的情况。
我们枚举每一种边界情况,并从对应的子串开始不断地向两边扩展。
如果两边的字母相同,我们就可以继续扩展。不同就可以停止扩展。
3."边界情况"对应的子串实际上就是我们扩展出来的回文串的“回文中心”.
本质:我们枚举所有回文中心,并尝试扩展;直到无法扩展为止。
此时的回文串长度,即为此回文中心下的最大回文串长度。
我们对所有的长度求出最大值,即可得到最终的答案。
*/
class Solution {
public String longestPalindrome(String s) {
if(s.length()<=1) return s;
//start和end记录最大回文子串的首尾位置
int start=0,end=0;
for(int i=0;i<s.length();i++){
//【关键】回文子串才能向外扩展
int len1=expandAroundCenter(s,i,i);
int len2=expandAroundCenter(s,i,i+1);
int len=Math.max(len1,len2);
if(len>end-start+1){//【难点】更新最大回文子串,注意下标的更新,(len-1)/2为中间节点(奇)or左半元素最右元素(下标),长度(编号)要加一
start=i-(len-1)/2;
// end=i+len/2;
end=len%2==1? i+(len-1)/2:i+(len-1)/2+1;
}
}
return s.substring(start,end+1);
}
//回文中心向外扩展,返回此回文中心扩展后的最大长度
public int expandAroundCenter(String s,int left,int right){
while(left>=0&&right<=s.length()-1&&s.charAt(left)==s.charAt(right)){
left--;
right++;
}
//跳出循环:1有一个边界越界;2两数不等
return right-left-1;
}
}
【知识点】中点寻找,下标与编号的关系

94 二叉树的中序遍历(非递归,颜色标记法;常规非递归写法)
*******************************************************************************************************************************************************************************************************************
105 从前序和中序遍历序列构造二叉树(根据中序遍历数组,我们能够确定左右子树在inorder和preorder的左右边界下标,递归构造二叉树)
/*
递归
1.根据中序遍历数组,我们能够确定左右子树在inorder和preorder的左右边界下标,进而递归构造二叉树
2.利用一个map存储元素在inorder中的位置下标
*/
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<inorder.length;i++){
map.put(inorder[i],i);
}
return buildTree2(preorder,0,preorder.length-1,inorder,0,inorder.length-1,map);
}
public TreeNode buildTree2(int[] preorder,int preleft,int preright,int[] inorder,int inleft,int inright,Map<Integer,Integer> map){
//本子树为空
if(preleft>preright) return null;
//当前根节点
TreeNode root=new TreeNode(preorder[preleft]);
int index=map.get(root.val);//根节点在inorder中的位置下标
//左右子树
root.left=buildTree2(preorder,preleft+1,preleft+index-inleft,inorder,inleft,index-1,map);
root.right=buildTree2(preorder,preleft+index-inleft+1,preright,inorder,index+1,inright,map);
return root;
}
}
☆148 排序链表o(N*logN)(分治法归并排序链表自顶向下:快慢指针寻找中点分界+分治递归+归并;自底向上,每个轮次依次对sublength的两个链表归并,串行处理)
/**
归并排序,自顶向下
1.快慢指针寻找中间分界
2.分治递归+归并
*/
class Solution {
//归并排序
public ListNode sortList(ListNode head) {
//递归出口
if(head==null||head.next==null) return head; //head==null为判断空链表
//快慢指针寻找中间节点
ListNode slow=head,fast=head.next;
while(fast!=null&&fast.next!=null){
slow=slow.next;
fast=fast.next.next;
}
ListNode righthead=slow.next;
slow.next=null;
ListNode left=sortList(head);
ListNode right=sortList(righthead);
return merge(left,right);
}
//合并两个有序链表
public ListNode merge(ListNode l1,ListNode l2){
ListNode head=new ListNode(-1);
ListNode tail=head;
while(l1!=null&&l2!=null){
if(l1.val<=l2.val){
tail.next=l1;
tail=tail.next;
l1=l1.next;
}else{
tail.next=l2;
tail=tail.next;
l2=l2.next;
}
}
if(l1!=null) tail.next=l1;
if(l2!=null) tail.next=l2;
return head.next;
}
}
☆98 验证二叉搜索树(中序遍历递归写法+全局遍历pre,中序遍历非递归写法)
```
/*
中序遍历+全局变量(前一个访问的元素),递归写法
判断当前节点是否大于中序遍历的前一个节点;
如果大于,说明满足BST,继续遍历;否则直接返回false。
*/
class Solution {
long pre=Long.MIN_VALUE;
public boolean isValidBST(TreeNode root) {
if(root==null) return true;
//访问左子树
if(!isValidBST(root.left)) return false;//左子树不为排序二叉树
//根节点处理
if(root.val<=pre) return false;
pre=root.val;
//访问右子树
return isValidBST(root.right);//【关键】前面已经验证了左子树和根节点正确,否则走不到这一步。
}
}
/*
中序遍历,非递归写法
1.用栈模拟递归
*/
class Solution {
public boolean isValidBST(TreeNode root) {
Deque<TreeNode> stack=new LinkedList<>();
long pre=Long.MIN_VALUE;
while(root!=null||!stack.isEmpty()){
//左子树处理,一直往左
while(root!=null){
stack.push(root);
root=root.left;
}
//根节点处理
root=stack.pop();
if(root.val<=pre) return false;
pre=root.val;
//右孩子当成左孩子处理
root=root.right;
}
return true;
}
}
/*
递归,前序遍历
左子树root.val
1.判断当前节点是否在区间内
2.递归判断左子树和右子树是否在区间内
*/
class Solution {
public boolean isValidBST(TreeNode root) {
return isValidBST(root,Long.MIN_VALUE,Long.MAX_VALUE);
}
public boolean isValidBST(TreeNode root,long left,long right){
if(root==null) return true;
if(root.val<=left||root.val>=right) return false;
return isValidBST(root.left,left,root.val)&&isValidBST(root.right,root.val,right);
}
}
```
240 搜索二维矩阵2(从右上角开始往下或者往左遍历)
/*
从右上角开始查找,
当matrix[i][j]target时,j--;
*/
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
if(matrix==null||matrix.length==0||matrix[0].length==0) return false;
int i=0,j=matrix[0].length-1;
while(i<matrix.length&&j>=0){
if(matrix[i][j]==target){
return true;
}else if(matrix[i][j]<target){
i++;
}else{
j--;
}
}
return false;
}
}
19 删除链表的倒数第N个结点(双指针,p1先走n步,p2再和p1一起走)
/*
双指针
p1先走n个节点,p2从head开始走,当p1走到null时,p2刚好走到倒数第n个节点
*/
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode newhead=new ListNode(-1);
newhead.next=head;
//1.p1先走n步
ListNode p1=newhead;
while(n--!=0&&p1!=null){
p1=p1.next;
}
//此处假定n输入正确,输入不正确直接返回
if(p1==null) return head;
//2.p1和p2一起走,直到p1.next==null,p2在第n个元素的前一个元素
ListNode p2=newhead;
while(p1.next!=null){
p1=p1.next;
p2=p2.next;
}
p2.next=p2.next.next;
return newhead.next;
}
}
第③天
39 组合总和(排序,dfs回溯+begin起始变量有顺序的遍历)
/*
回溯与剪枝+去重,回溯经典例题,元素可重复利用
dfs
1.搜索空间,n^n搜索树
2.终止条件 ==target
3.提前回溯sum>target
【难点】去除重复路径
1.产生重复路径的原因:由于每一个元素都可以重复使用,每一轮我们考虑了所有的候选数;同一答案更换顺序多次遍历就会产生重复
2.解决办法:在搜索时就去除重复,
a保证数组元素有序
b在每一轮搜索时,只能往后搜索,不能再使用前面的元素,避免重复
不会漏解,因为如果有解,在前面遍历到较小元素时就会得到该解。
遇到这一类“相同元素不计算顺序”的问题,我们在搜索时就需要按照某种顺序搜索。
具体的做法是在每一次搜索的时候设置下一轮搜索的起点begin
*/
class Solution {
List<List<Integer>> ret=new ArrayList<>();
public List<List<Integer>> combinationSum(int[] candidates, int target) {
Arrays.sort(candidates);
dfs(candidates,0,0,target,new ArrayList<Integer>());
return ret;
}
public void dfs(int[] candidates,int begin,int sum,int target,List<Integer> list){
//终止条件
if(sum==target){
ret.add(new ArrayList<>(list));
}
//【剪枝】提前回溯
if(sum>target) return;
//继续向下dfs
for(int i=begin;i<candidates.length;i++){//【关键】1.每一轮搜索,只能从当前位置往后搜索,一开始begin=0
list.add(candidates[i]);
sum+=candidates[i];
dfs(candidates,i,sum,target,list);//【易错】【关键】2.下一轮搜索仍然从i开始,因为元素可以重复利用,但是搜索结果不允许有递减,只能是非递减
sum-=candidates[i];
list.remove(list.size()-1);//remove删除Integer使用的是下标
}
}
}
☆78 子集(dfs回溯+begin起始变量有顺序的遍历)
/*
dfs+回溯+不能有重复list
1.终止条件(每个元素只能用一次,不能超过nums.length)
2.不能有重复(有顺序地遍历)
*/
class Solution {
List<List<Integer>> ret=new ArrayList<>();
public List<List<Integer>> subsets(int[] nums) {
dfs(nums,0,new ArrayList<Integer>());
return ret;
}
public void dfs(int[] nums,int begin,List<Integer> list){
//终止条件
if(list.size()>nums.length) return;
ret.add(new ArrayList<>(list));
//dfs,子集不能有重复,采用begin顺序遍历【关键】
for(int i=begin;i<nums.length;i++){
list.add(nums[i]);
dfs(nums,i+1,list);
list.remove(list.size()-1);
}
}
}
48 旋转图像(找规律,水平翻转+主对角线翻转)
/**
方法三:找规律、水平翻转+主对角线翻转(用翻转代替旋转)(原地翻转2)
* 方法一中==关键等式:matrix [row] [col] ->matrix [col] [n-1-row]==
* 水平翻转:matrix [row] [col] ->matrix [n-1-row] [col]
主对角线翻转:matrix [row] [col]->matrix [col] [row]
合并得到方法一中关键等式
*/
class Solution {
public void rotate(int[][] matrix) {
int n=matrix.length;
//水平翻转
for(int i=0;i<matrix.length/2;i++){//【易错】i的取值范围
for(int j=0;j<matrix[0].length;j++){
int tmp=matrix[i][j];
matrix[i][j]=matrix[n-1-i][j];
matrix[n-1-i][j]=tmp;
}
}
//主对角线翻转
for(int i=0;i<matrix.length;i++){
for(int j=0;j<i;j++){
int tmp=matrix[i][j];
matrix[i][j]=matrix[j][i];
matrix[j][i]=tmp;
}
}
}
}
/*
时间复杂度o(N^2)
空间复杂度o(1)
*/
☆31 下一个排列(降序最大,升序最小;从后往前找到第一个升序元素对+交换nums[i]和nums[k]+把尾部降序序列变成升序)
“下一个排列”的定义:
给定数字序列的字典序中,下一个更大的排列。
如果不存在下一个更大的排列(此时为降序序列,最大),则将数字重新排列成最小的排列(升序序列,最小)
算法分析

/**
降序序列组成数字最大,升序序列组成数字最小
1从后往前遍历,找到第一个逆序对(i,i+1),确定降序序列
2从降序序列中找到刚好大于的nums[i]的数字,swap
3将降序序列重排成升序序列
*/
class Solution {
public void nextPermutation(int[] nums) {
//1从后往前遍历,找到第一个逆序对(i,i+1),确定降序序列
int i=nums.length-2;
for(;i>=0;i--){
if(nums[i]<nums[i+1]){
break;
}
}
//2从降序序列中找到刚好大于的nums[i]的数字,swap
//整个序列可能存在逆序,为最大元素,此时只需重排,
if(i>=0){
for(int j=nums.length-1;j>i;j--){
if(nums[j]>nums[i]){
swap(nums,i,j);
break;
}
}
}
//3将降序序列重排成升序序列
for(int left=i+1,right=nums.length-1;left<right;left++,right--){
swap(nums,left,right);
}
}
public void swap(int[] nums,int i,int j){
int tmp=nums[i];
nums[i]=nums[j];
nums[j]=tmp;
}
}
64 最小路径和(只能向下或者向右移动,动态规划;回溯时间复杂度相对较高)
方法一:动态规划
1.参数
dp[i][j]从左上角到达当前节点的最小路径和
2.递推方程
对于不在第一行和第一列的元素,可以从其上方相邻元素向下移动一步到达,或者从其左方相邻元素向右移动一步到达
dp[i][j]=min{dp[i-1][j],dp[i][j-1]}+grid[i][j];
3.初值条件
dp[0][0]=grid[0][0];
第一行,每个元素只能从左上角元素开始向右移动到达
dp[0][i]=dp[0][i-1]+grid[0][i];
第一列,每个元素只能从左上角元素开始向下移动到达
dp[i][0]=dp[i-1][0]+grid[i][0];
class Solution {
public int minPathSum(int[][] grid) {
int[][] dp=new int[grid.length][grid[0].length];
//初值条件
dp[0][0]=grid[0][0];
for(int i=1;i<grid[0].length;i++){
dp[0][i]=dp[0][i-1]+grid[0][i];
}
for(int i=1;i<grid.length;i++){
dp[i][0]=dp[i-1][0]+grid[i][0];
}
//递推方程,从上往下,从左往右,行处理
for(int i=1;i<grid.length;i++){
for(int j=1;j<grid[0].length;j++){
dp[i][j]=Math.min(dp[i-1][j],dp[i][j-1])+grid[i][j];
}
}
return dp[grid.length-1][grid[0].length-1];
}
}
二维矩阵,类似图
最短路径和,Dijkstra算法,单源最短路径,计算一个节点到其他每个节点的最短路径
方法二:dfs+回溯
1.终止条件,到达最右下角matrix[m-1][n-1]
2.提前回溯,超出grid范围、重新遍历已遍历过得节点(此处只能向下或者向右走,不存在重复)
【此处超时】,但算法没错
class Solution {
int minpathsum=0;
public int minPathSum(int[][] grid) {
dfs(grid,0,0,0);
return minpathsum;
}
public void dfs(int[][] grid,int curpathsum,int r,int c){
//终止条件,
if(r==grid.length-1&&c==grid[0].length-1){
curpathsum+=grid[r][c];
if(minpathsum==0){
minpathsum=curpathsum;
}else{
minpathsum=minpathsum=grid.length||c<0||c>=grid[0].length) return;
curpathsum+=grid[r][c];
dfs(grid,curpathsum,r+1,c);
dfs(grid,curpathsum,r,c+1);
}
}
*******************************************************************************************************************************************************************************************************************
62 不同路径(从左上角到右下角只能向下或者向右,动态规划。dfs回溯也可以,时间会很长)
/*
动态规划
1.参数
dp[i][j]为到达matrix[i][j]处路径条数
2.递推方程
dp[i][j]=dp[i-1][j]+dp[i][j-1],当i>0和j>0
3.初值条件
dp[0][0]=1;
第一行
dp[0][i]=1;
第一列
dp[i][0]=1;
*/
class Solution {
public int uniquePaths(int m, int n) {
int[][] dp=new int[m][n];
//初值条件
dp[0][0]=1;
for(int i=1;i<n;i++){
dp[0][i]=1;
}
for(int i=1;i<m;i++){
dp[i][0]=1;
}
//递推方程
for(int i=1;i<m;i++){
for(int j=1;j<n;j++){
dp[i][j]=dp[i-1][j]+dp[i][j-1];
}
}
return dp[m-1][n-1];
}
}
/*
1.虽然此处仍然是只能向下或者向右,但是此处不用动态规划,而是采用dfs回溯;
动态规划只能求解最优解问题,而dfs回溯可以列举所有可能的情况
2.此处只能向下或者向右,一次遍历中不会遍历已经遍历过得元素
①终止条件
位置走到matrix[m-1][n-1]
②提前回溯
越界,走出matrix网格
③递归dfs
只能向下或者向右
*/
class Solution {
int pathcnt=0;
public int uniquePaths(int m, int n) {
dfs(m,n,0,0);
return pathcnt;
}
public void dfs(int m,int n,int r,int c){
//终止条件
if(r==m-1&&c==n-1){
pathcnt++;
return;
}
//提前回溯
if(r<0||r>=m||c<0||c>=n) return;
//继续dfs
dfs(m,n,r+1,c);
dfs(m,n,r,c+1);
}
}
- 采用dfs回溯和动态规划的时间对比
m=23,n=12

![]()
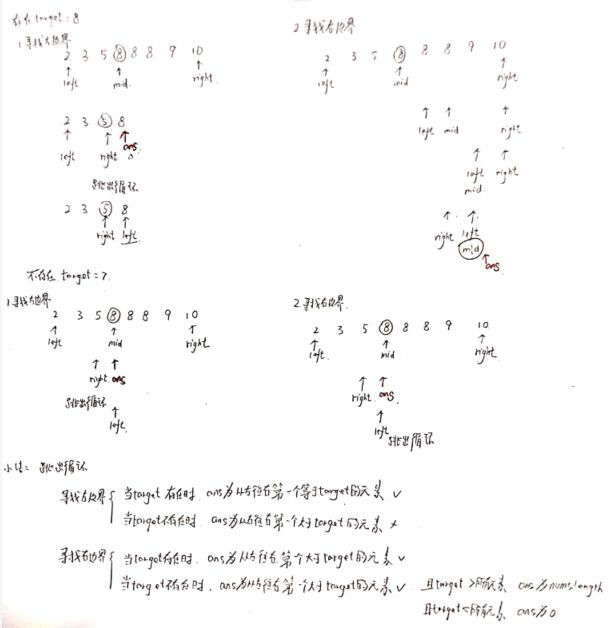
☆34 在排序数组中查找元素的第一个和最后一个位置(二分查找,寻找重复元素左边界和寻找右边界)
- 寻找target开始和结束的位置——要找的就是
数组中 “第一个等于target的位置” ,记作leftIndex——寻找数组中第一个 ”大于等于“ target的下标(等于好理解,大于不好理解,如果不存在等于target的元素时)
和 “第一个大于target的位置减一”,记作rightIndex——寻找数组中第一个大于target的下标
-
两者的判断条件不同,为了代码的复用,我们定义binarySearch(nums,target,lower)表示在nums数组中二分查找target的位置,
如果lower为true,则查找第一个大于等于target的下标,否则查找第一个大于target的下标 -
最后,因为target可能不存在数组中,我们需要校验我们得到的两个下标leftIndex和rightIndex,不符合条件就返回[-1,-1]
/**
二分查找
寻找左边界和右边界
*/
class Solution {
public int[] searchRange(int[] nums, int target) {
if(nums==null||nums.length<=0) return new int[]{-1,-1};
int[] ret=new int[2];
//寻找左边界
int left=0,right=nums.length-1;
while(left<=right){
int mid=left+(right-left)/2;
if(target<=nums[mid]){
right=mid-1;
}else{
left=mid+1;
}
}
//跳出循环,right为左边界左边的一个元素,left处于左边界,
//left可能跑到最右边
ret[0]=left<=nums.length-1&&nums[left]==target? left:-1; //【易错】left和right可能会出现越界的情况
//寻找右边界
left=0;
right=nums.length-1;
while(left<=right){
int mid=left+(right-left)/2;
if(target>=nums[mid]){
left=mid+1;
}else{
right=mid-1;
}
}
//right可能跑到最左边
ret[1]=right>=0&&nums[right]==target? right:-1;
return ret;
}
}
☆322 零钱兑换(动态规划,F[i]为组成金额为i所需的最少硬币数量,F[i]=min(F[i-cj])+1。Dfs回溯也可以,时间会很长)
动态规划
-
参数
F[i]为组成金额为i所需的最少的硬币数量
-
递推方程
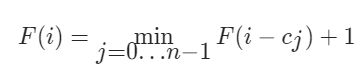
cj代表第j种硬币的面额,F[i]可以从F[ i-cj ]中转移过来 -
初值条件
F[0]=0;
其他F[i]初始化为amount+1,表明不存在硬币能组合金额i
public class Solution{
public int coinChange(int[] coins,int amount){
int[] dp=new int[amount+1];
//初值条件
Arrays.fill(dp,amount+1);//【关键】一开始假设不存在,面额为1的硬币需要amount个,现在初始化为amount+1表明不存在
dp[0]=0;
//递推方程
for(int i=1;i<=amount;i++){
for(int j=0;j<coins.length;j++){//【关键】遍历所有面额的硬币,关键在i>=coins[j](因为nums数组不一定有序,所以需要全程遍历)
if(i>=coins[j]){
dp[i]=Math.min(d[i],dp[i-coins[j]]+1);
}
}
}
return dp[amount]==amount+1? -1:dp[amount];//dp[amount]初始化为amount+1,若到最后没有变化,表明没有合适的组合;
}
}
回溯与剪枝
-
问题可以优化为:
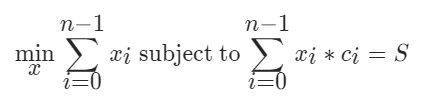
s是总金额,共有i种面值的硬币,ci是第i种面值硬币的面值,xi是所采用的第i种硬币的数量,
xi*ci不会超过总金额,所以0<=xi<=s/ci,每种硬币的使用数量其实有上限 -
dfs回溯遍历i中硬币的情况,搜索树为完全二叉树
终止条件:如果金额数为s
提前回溯:如果金额数大于s
剪枝:当前硬币数量>=成功一次的硬币数量
class Solution {
int mincnt=-1;
public int coinChange(int[] coins, int amount) {
dfs(coins,0,amount,0,0);
return mincnt;
}
/*
cur,当前硬币总金额
cnt,当前硬币总数量
*/
public void dfs(int[] coins,int begin,int amount,int cur,int cnt){
//终止条件
if(cur==amount){
mincnt=mincnt==-1? Math.min(mincnt,cnt);
return;
}
//提前回溯
if(cur>amount) return;
//剪枝
if(mincnt!=-1&&mincnt<=cnt) return;
//dfs
for(int i=begin;i<coins.length;i++){
dfs(coins,i,amount,cur+coins[i],cnt+1);
}
}
}
dfs回溯与动态规划时间对比

![]()
22 括号生成(dfs回溯与剪枝)
/**
括号生成
当生成左括号没有限制
只有当当前存在的左括号数量大于右括号数量时,才能生成右括号
dfs回溯
3层,完全二叉树,每层两个空间
1.终止条件
2.提前回溯
3.往下遍历
*/
class Solution {
List<String> ret=new ArrayList<>();
public List<String> generateParenthesis(int n) {
dfs(0,0,n,new StringBuilder());
return ret;
}
public void dfs(int leftcount,int rightcount,int n,StringBuilder sb){
//终止条件
if(leftcount==n&&rightcount==n){
ret.add(sb.toString());
return;
}
//提前回溯
//往下遍历
if(leftcount<n){
sb.append("(");
dfs(leftcount+1,rightcount,n,sb);
sb.delete(sb.length()-1,sb.length());
}
if(rightcount<leftcount){
sb.append(")");
dfs(leftcount,rightcount+1,n,sb);
sb.delete(sb.length()-1,sb.length());
}
}
}
198 打家劫舍(动态规划,F[i]为考虑前面i间房子所偷得最大金额,F[i]=max(F[i-1],F[i-2]+nums[i].如果考虑输出节点,F[i]为包括当前节点所偷得最大金额,F[i]=max(F[j])+nums[i],可以设标记函数追溯)
/*
动态规划(考虑子问题规模)
1.参数
从前往后,dp[i]为考虑前i间房子所偷得金额
2.递推方程
dp[i]=max{dp[i-1],dp[i-2]+nums[i]}//大问题转化为小问题
3.初值条件
dp[0]=nums[0];
dp[1]=Math.max(nums[0],nums[1]);
*/
class Solution {
public int rob(int[] nums) {
if(nums.length==1) return nums[0];
int[] dp=new int[nums.length];
//初值条件
dp[0]=nums[0];
dp[1]=Math.max(nums[0],nums[1]);
int maxmoney=Math.max(nums[0],nums[1]);//【关键】maxmoney初值设定
//递推方程
for(int i=2;i<nums.length;i++){
dp[i]=Math.max(dp[i-1],dp[i-2]+nums[i]);
maxmoney=Math.max(maxmoney,dp[i]);
}
return maxmoney;
}
}
第④天
☆394 字符串解码(双辅助栈法;递归法)
方法一:辅助栈法
实例:s = “3[a2[c]]”
本题难点:括号内嵌套括号,需要”由内向外“ ”生成与拼接“字符串,这与栈的后入先出特性对应。
算法流程——构建辅助栈stack_multi和stack_res,遍历字符串s中每个字符c
当c为字母时,在res尾部添加c
当c为数字时,将数字字符转化为int,更新multi
当c为 [ 时,将当前的res和multi入栈,并且重置下一层里res为空和multi为0
res记录当前层字母
multi在当前层记录下一层的重复次数
进入新的 [ 后,res和multi需要重新记录
当c为 ] 时,
multi出栈,计算2[c],tmp=multi*res
res出栈,计算a2[c],更新当前层res,res=last_res+tmp;
/**
两个栈模拟递归,存储上一级的状态
stack_res存储前面入栈的字符串
stack_multi存储数字
*/
class Solution {
public String decodeString(String s) {
int multi=0;
StringBuilder res=new StringBuilder();
Deque<Integer> stack_multi=new LinkedList<>();
Deque<String> stack_res=new LinkedList<>();
for(Character c:s.toCharArray()){
if(c=='['){ //开启下一层
stack_multi.push(multi);
stack_res.push(res.toString());
multi=0;
res=new StringBuilder();
}
else if(c>='a'&&c<='z'){
res.append(c+"");
}
else if(c==']'){
StringBuilder tmp=new StringBuilder();
int cur_multi=stack_multi.pop();
for(int i=0;i<cur_multi;i++){ //【易错】不能在循环里面放stack_multi.pop(),会计算多次
tmp.append(res);
}
res=new StringBuilder(stack_res.pop()+tmp); //【关键】返回上一层
}else{
multi=multi*10+Integer.parseInt(c+""); //继续往下遍历
}
}
return res.toString();
}
}
复杂度分析
时间复杂度:o(N),一次遍历s
空间复杂度:o(N),辅助栈在极端情况下需要线性空间
79 单词搜索(dfs回溯,每个字符比较)
/*
网格遍历
dfs回溯
1.终止条件
找到单词(不是最后比较整个单词,而是通过比较每个字符进而比较整个单词)
2.回溯
(1)越界,在网格之外
(2)访问已经遍历过的格子
(3)word查找的字符长度越界//【此回溯易忘】
(4)网格字符与word当前遍历字符不等
3.递归
上下左右
【问题】每次dfs都全部遍历
*/
class Solution {
boolean flag=false;
public boolean exist(char[][] board, String word) {
int[][] visited=new int[board.length][board[0].length];
for(int i=0;i<visited.length;i++){
for(int j=0;j<visited[0].length;j++){
visited[i][j]=0;
}
}
for(int r=0;r<board.length;r++){
for(int c=0;c<board[0].length;c++){
if(visited[r][c]==1) continue;
dfs(board,r,c,visited,word,new StringBuilder(),0);
}
}
return flag;
}
//k为此轮遍历中word中的第k个字符,k从0开始
public void dfs(char[][] board,int r,int c,int[][] visited,String word,StringBuilder sb,int k){
//终止条件
if(word.equals(sb.toString())){
flag=true;
return;
}
//提前回溯,越界,遍历到已访问过节点
if(r<0||r>=board.length||c<0||c>=board[0].length) return;
if(visited[r][c]==1) return;
//剪枝
if(k>word.length()-1) return;
if(board[r][c]!=word.charAt(k)) return;
//当前节点处理
//遍历相邻节点
visited[r][c]=1;
sb.append(board[r][c]);
dfs(board,r-1,c,visited,word,sb,k+1);
dfs(board,r+1,c,visited,word,sb,k+1);
dfs(board,r,c-1,visited,word,sb,k+1);
dfs(board,r,c+1,visited,word,sb,k+1);
sb.delete(sb.length()-1,sb.length());
visited[r][c]=0;
}
}
☆287 寻找重复数(抽屉原理+二分查找;数组当链表+快慢指针;)
class Solution{
public int findDuplicate(int[] nums){//数组大小为n+1,数组内的数为1到n
int left=1;
int right=nums.length-1;
while(left<right){//【关键】跳出循环
int mid=(left+right)>>>1;//【好的处理】mid并不是nums的中间位置.当left+right溢出时,无符号右移保证结果依然正确
//1.对于每个mid统计nums中小于等于其的元素数量
int cnt=0;
for(int num:nums){
if(num<=mid){
cnt+=1;
}
}
//【关键】2.根据抽屉原理,确定重复元素所在区间,重复元素为[left,mid]
if(cnt>mid){
right=mid;//【核心】当cnt>mid时,重复元素在左侧区间,往左,确定重复元素所在区间
}else{
left=mid+1;//cnt<=mid时,重复元素在右侧区间,往右,确定重复元素所在区间
}
}
//3.跳出循环,重复元素在左边往左,在右边往右,夹逼定理,最后跳出循环left=right时,找到重复元素,但是nums中该元素可能有好几个
return left;
}
}
739 每日温度(递减栈;暴力法)
/**
维护一个递减栈(栈中后面的元素<=前面的元素,因为如果后面的大,前面的元素就出栈了
1.第一个元素入栈
2.遍历第二个元素到最后一个元素,当前元素>栈中元素,栈中元素找到第一个大于它的元素,栈中元素出栈
3.遍历结束后,仍在栈中的元素表示后面没有比它大的元素
*/
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
int[] ret=new int[temperatures.length];
Deque<Integer> stack=new LinkedList<>(); //维护一个递减栈(单调不增),存储元素下标
stack.push(0);
//遍历当前元素
for(int i=1;i<temperatures.length;i++){
//元素出栈
while(!stack.isEmpty()&&temperatures[stack.peek()]<temperatures[i]){
int pos=stack.pop();
ret[pos]=i-pos;
}
//当前元素入栈
stack.push(i);
}
//遍历结束
while(!stack.isEmpty()){
ret[stack.pop()]=0;
}
return ret;
}
}
11 盛最多水的容器(双指针+短板决定最终面积)
/**
s=(j-i)*min(height[i],height[j])
1.双指针,短板决定最终面积
2.向内移动短板,面积可能不变或变大
向内移动长板,面积可能不变或变小
因此向内移动短板
*/
class Solution {
public int maxArea(int[] height) {
int i=0,j=height.length-1;
int maxArea=0;
while(i<j){
int s=(j-i)*Math.min(height[i],height[j]);
maxArea=maxArea>s? maxArea:s;
if(height[i]<=height[j]){
i++;
}else{
j--;
}
}
return maxArea;
}
}
*******************************************************************************************************************************************************************************************************************
152 乘积最大的子数组(双状态动态规划;暴力)
/**
乘积最大连续子数组
双动态规划
对于每个位置,乘积最大,乘积最小
1.参数
dpMax[i]为以第nums[i]元素结尾的连续子数组max,正负未知
dpMin[i]为以第nums[i]元素结尾的连续子数组min,正负未知
2.递推方程
当nums[i]为负,dpMax[i]=dpMin[i-1]*nums[i],dpMin[i]=dpMax[i-1]*nums[i]
当nums[i]为正, dpMax[i]=dpMax[i-1]*nums[i],dpMin[i]=dpMin[i-1]*nums[i]
3.初值条件
dpMax[0]=nums[0];
dpMin[0]=nums[0];
*/
class Solution {
public int maxProduct(int[] nums) {
int[] dpMax=new int[nums.length];
int[] dpMin=new int[nums.length];
dpMax[0]=nums[0];
dpMin[0]=nums[0];
int max=nums[0];
//递推方程
for(int i=1;i<nums.length;i++){
if(nums[i]<=0){
dpMax[i]=Math.max(dpMin[i-1]*nums[i],nums[i]); //【易错】当前面为0时,后面可以为当前元素
dpMin[i]=Math.min(dpMax[i-1]*nums[i],nums[i]);
}else if(nums[i]>0){
dpMax[i]=Math.max(dpMax[i-1]*nums[i],nums[i]);
dpMin[i]=Math.min(dpMin[i-1]*nums[i],nums[i]);
}
max=Math.max(max,dpMax[i]);
}
return max;
}
}
560 和为K的子数组(前缀和+map;暴力)
-
定义
pre[i]为nums[i]及其前面的所有元素之和,将pre[i]出现的次数存储到map中 -
题中“寻找和为k的连续子数组”可转化为:
遍历到当前元素,当前元素的前缀和为
pre[i],如果前面存在前缀和为值pre[i]-k,记为pre[j],那么[j+1,i]即为一个“和为k的连续子数组” -
pre[i]只与pre[i-1]有关,所以pre[i]的计算可以只使用一个pre来表示pre[i-1]迭代计算(当然也可以使用一个pre数组(这里有一个空间复杂度的优化)
【易错】一个元素为k,也是属于连续子数组等于k,所以map初始化时需要加入键值对(0,1)
public class Solution{
public int subarraySum(int[] nums,int k){
int cnt=0;
int pre=0;//对nums[0]的处理
Map<Integer,Integer> map=new HashMap<>();
map.put(0,1);//【关键】】一个元素为k,也是属于连续子数组等于k,所以map初始化时需要加入键值对`(0,1)`
for(int i=0;i<nums.length;i++){
//当前遍历元素的处理
pre+=nums[i];//当前元素前缀和
if(map.containsKey(pre-k)){//【关键】存在pre[i]-k的前缀和
cnt+=map.get(pre-k);
}
map.put(pre,map.getOrDefault(pre,0)+1);
}
return cnt;
}
}
221 最大正方形(动态规划+找正方形的最大边长;暴力法遍历每个为一格子以其为正方形左上角格子判断新增一行一列是否有效)
/**
1.参数
dp[i][j]为以当前元素为正方形的右下角元素,所能构成的最大正方形边长
2.递推方程
dp[i][j]=min{dp[i-1][j],dp[i][j-1],dp[i-1][j-1]}+1
3.初值条件
当matrix[i][j]==1
dp[0][0]=1
dp[0][i]=1 i从1到matrix[0].length
dp[i][0]=1 i从1到matrix.length
*/
class Solution {
public int maximalSquare(char[][] matrix) {
int maxlength=0;
int[][] dp=new int[matrix.length][matrix[0].length];
//初值条件
for(int i=0;i<matrix.length;i++){
if(matrix[i][0]=='1'){
dp[i][0]=1;
maxlength=1;
}
}
for(int i=1;i<matrix[0].length;i++){
if(matrix[0][i]=='1'){
dp[0][i]=1;
maxlength=1;
}
}
//递推方程
for(int i=1;i<matrix.length;i++){
for(int j=1;j<matrix[0].length;j++){
if(matrix[i][j]=='1'){
dp[i][j]=Math.min(Math.min(dp[i-1][j],dp[i][j-1]),dp[i-1][j-1])+1;
maxlength=maxlength>dp[i][j]? maxlength:dp[i][j];
}
}
}
return maxlength*maxlength; //得到的是边长,返回的是面积
}
}
☆208 实现trie(前缀树)(children指针和isEnd状态标志+插入字符串+查找前缀)
前缀树/字典树概念
Trie又称前缀树/字典树
是一棵有根树,其每个节点包含一下字段:
- 指向子节点的指针数组children。
对于本题而言,数组长度为26,即小写英文字母的数量。
此时children[0]对应小写字母a,children[1]对应小写字母b…,children[25]对应小写字母z。- 布尔字段isEnd,表示该节点是否为字符串的结尾。
插入字符串
我们从字典树的根开始,插入字符串。对于当前字符对应的子节点,有两种情况:
-
子节点存在。
沿着指针移动到子节点,继续处理下一个字符。
-
子节点不存在。
创建一个新的子节点,记录在children数组的对应位置上,然后沿着指针移动到子节点,继续搜索下一个字符。
重复以上步骤,直到处理字符串的最后一个字符,然后将当前节点标记为字符串的结尾。
查找前缀
我们从字典树的根开始,查找前缀。对于当前字符对应的子节点,有两种情况:
-
子节点存在,沿着指针移动到子节点,继续搜索下一个字符。
-
子节点不存在。说明字典树中不包含该前缀,返回空指针。
重复上述步骤,直到返回空指针或者搜索完前缀的最后一个字符。
若搜索到了前缀的末尾,就说明字典树中存在该前缀。此外,若前缀末尾对应节点的isEnd为真,就说明字典树中存在该字符串。
class Trie {
//对于每一个节点都存在子节点,和isEnd状态;从根节点到isEnd位true节点只存在一条路径,对应一个单词
private Trie[] children=new Trie[26];;
private boolean isEnd=false;;
/** Initialize your data structure here. */
public Trie() {
}
/** Inserts a word into the trie. */
public void insert(String word) {
Trie node=this;//★★【关键】指向当前对象,相当于根节点
for(int i=0;i<word.length();i++){
int index=word.charAt(i)-'a';
//当前字符不存在,插入
if(node.children[index]==null){
node.children[index]=new Trie();//★★【核心】具体字符并不存储在节点中,字符就像left和right只用于索引孩子
}
//本身存在or插入后存在
node=node.children[index];//【关键】指向下一个对象
}
node.isEnd=true;
}
/** Returns if the word is in the trie. */
public boolean search(String word) {
//1.word字符是否存在
Trie node=this;
for(int i=0;i<word.length();i++){
int index=word.charAt(i)-'a';
if(node.children[index]==null){
return false;//字符不存在,
}
node=node.children[index];
}
//2.判断结尾节点isEnd是否为true
return node.isEnd==true;
}
/** Returns if there is any word in the trie that starts with the given prefix. */
public boolean startsWith(String prefix) {
//1.word字符是否存在
Trie node=this;
for(int i=0;i<prefix.length();i++){
int index=prefix.charAt(i)-'a';
if(node.children[index]==null){
return false;//字符不存在,
}
node=node.children[index];
}
return true;
}
}
☆114 二叉树展开为链表(保留前一个节点信息+保留右子树信息,递归;迭代+利用栈实现前序遍历保存了右节点信息;特殊方法+处理当前节点将右子树连接到左子树的最右节点)
方法二:前序遍历和修改同步进行
一边前序遍历,一边修改,会破坏二叉树子节点的信息
- 在前序遍历等过程中,需要存储节点的左右子节点信息
- 遍历到当前节点时处理前一个节点
pre.right=cur
递归写法
/*
前序遍历
递归,保留前一个节点,遍历到当前节点时,pre.right=cur
*/
class Solution {
TreeNode pre=null;
public void flatten(TreeNode root) {
preorder(root);
}
public void preorder(TreeNode root){
if(root!=null){
//保存左右子树
TreeNode leftNode=root.left;
TreeNode rightNode=root.right;
//前序遍历
if(pre!=null){
pre.right=root;
}
root.left=null;
pre=root;
preorder(leftNode);
preorder(rightNode);
}
}
}
迭代写法——利用栈实现前序遍历(保存了右节点信息)
class Solution {
public void flatten(TreeNode root) {
if(root==null) return;
TreeNode pre=null;
Deque<TreeNode> stack=new LinkedList<>();
stack.push(root);
while(!stack.isEmpty()){
TreeNode cur=stack.pop();
if(pre!=null){
pre.left=null;
pre.right=cur;
}
if(cur.right!=null) stack.push(cur.right);//【关键】先存储右孩子,使用的是栈
if(cur.left!=null) stack.push(cur.left);
pre=cur;
}
}
}
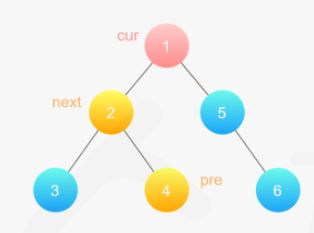
方法三:右子树的处理(不太好理解)
对于当前节点,
- 如果左子树不为空,找到左子树中最右边的节点,作为前驱节点
- 将右子树付给前驱节点的右子节点
- 将当前节点的左子树赋给right,left置空(到此,完成当前节点的处理)
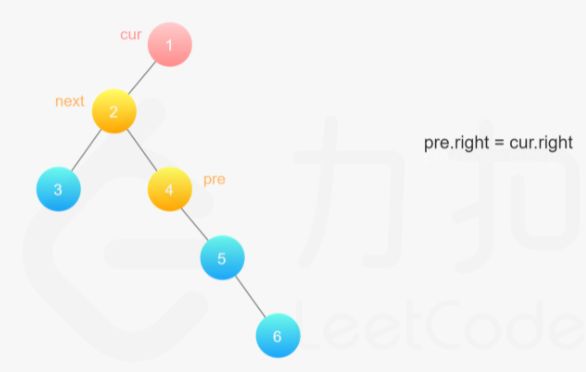


class Solution {
public void flatten(TreeNode root) {
TreeNode cur=root;
while(cur!=null){
//如果当前节点的左子树不为空
if(cur.left!=null){
TreeNode next=cur.left;
//1.找到左子树的最右节点
TreeNode nextRight=next;
while(nextRight.right!=null){
nextRight=nextRight.right;
}
//2.将当前节点的右子树赋给左子树的最右节点
nextRight.right=cur.right;
//3.当前节点的处理
cur.left=null;
cur.right=next;
}
//情况1:下一个待处理的节点是cur的右孩子;情况2:如果左子树为空,处理右子树
cur=cur.right;
}
}
}
第⑤天
☆207 课程表(拓扑排序 “入度计数数组+邻接表的存储”+队列实现BFS、DFS回溯)
class Solution {
//存储结果
List<Integer> ret=new ArrayList<>();
public boolean canFinish(int numCourses, int[][] prerequisites) {
//1.存储顶点入度
int[] cnt=new int[numCourses];
//图的邻接表
List<List<Integer>> edges=new ArrayList<>();
for(int i=0;i<numCourses;i++){
edges.add(new ArrayList<Integer>());
}
for(int[] info:prerequisites){
edges.get(info[1]).add(info[0]);
cnt[info[0]]++;
}
//2.BFS
Queue<Integer> queue=new LinkedList<>();
//初始入度为0的节点添加到queue中
for(int i=0;i<numCourses;i++){
if(cnt[i]==0){
queue.offer(i);
}
}
while(!queue.isEmpty()){
//当前节点处理
int u=queue.poll();
ret.add(u);
//相邻节点入度减一,若入度为0则添加到queue中
for(int v:edges.get(u)){
cnt[v]--;
if(cnt[v]==0){
queue.offer(v);
}
}
}
//返回
//当ret中顶点个数等于numCourses,得到拓扑排序;否则存在环
return ret.size()==numCourses;
}
}
/*
拓扑排序
dfs,结果逆向
1.终止条件,回溯
Valid==false,前面存在环,返回
visited[u]==1,当前节点处存在环,返回
visited[u]==2,遍历到已经完成的节点,返回
2.dfs回溯
for(int v:edges.get(u))当前节点的相邻节点
List edges 邻接表
int[] visited 标记数组
boolean valid 是否存在环
stack ret 结果逆向
*/
class Solution {
//存储结果
Deque<Integer> ret=new LinkedList<>();
//存在环
boolean valid=true;
public boolean canFinish(int numCourses, int[][] prerequisites) {
//1.邻接表
List<List<Integer>> edges=new ArrayList<>();
for(int i=0;i<numCourses;i++){
edges.add(new ArrayList<Integer>());
}
for(int[] info:prerequisites){
edges.get(info[1]).add(info[0]);
}
//标记数组
int[] visited=new int[numCourses];
//2.dfs
for(int i=0;i<numCourses;i++){
//已经遍历过跳过
if(visited[i]==2) continue;
dfs(i,edges,visited);
if(valid==false) return false;//存在环,提前返回
}
//3.返回
return true;
}
public void dfs(int u,List<List<Integer>> edges,int[] visited){
//1.终止条件,回溯
//前面存在环,返回
if(valid==false) return;
//遍历到已经完成的节点,返回
if(visited[u]==2) return;
//当前节点处存在环,返回
if(visited[u]==1){
valid=false;
return;
}
//2.当前节点处理
visited[u]=1;
for(int v:edges.get(u)){
dfs(v,edges,visited);
}
//3.遍历完成
visited[u]=2;
ret.push(u);
}
}
☆494 目标和(dfs回溯;转化为01背包问题)
/**
dfs回溯
*/
class Solution {
int ret=0;
public int findTargetSumWays(int[] nums, int target) {
dfs(nums,0,target,0);
return ret;
}
public void dfs(int[] nums,int index,int target,int sum){
//终止条件
if(index>=nums.length&&target==sum){
ret++;
}
//提前回溯
if(index>=nums.length){
return;
}
//当前节点处理,往后遍历
dfs(nums,index+1,target,sum+nums[index]);
dfs(nums,index+1,target,sum-nums[index]);
}
}
/**
1设正数之和为x,负数之和为y
x-y=target
x+y=sum
x=(target+sum)/2;
2转化为数组nums中找价值为x的0-1背包问题
one参数
dp[i]为价值为i的装填方法数
two递推方程
dp[i]=dp[i]+dp[i-nums],遍历nums
three初值条件
dp[0]=1
*/
class Solution {
public int findTargetSumWays(int[] nums, int target) {
//1.转化为数组nums中找价值为x的0-1背包问题
int sum=0;
for(int num:nums){
sum+=num;
}
int x=(target+sum)/2;
//提前返回
if(target>sum) return 0;
if((target+sum)%2!=0) return 0;
if(target+sum<0) return 0;
//2.0-1背包问题
int[] dp=new int[x+1];
dp[0]=1;
//【关键】递推方程
for(int num:nums){
for(int j=x;j>=num;j--){ //对于每个nums,遍历对应dp
dp[j]=dp[j]+dp[j-num];
}
}
return dp[x];
}
}
75 颜色分类(双指针)
/*
双指针
0往左边放,2往右边放
left左边的元素都是0,right右边的元素都是2
*/
class Solution {
public void sortColors(int[] nums) {
int left=0,right=nums.length-1;
for(int i=0;i<=right;i++){
if(nums[i]==0){
swap(nums,i,left++);
//i--;//×【易错】左边元素left都是处理过的,不存在0或者2,不用在此判断当前位置
}else if(nums[i]==2){
swap(nums,i,right--);
i--;
}
}
}
public void swap(int[] nums,int i,int j){
int tmp=nums[i];
nums[i]=nums[j];
nums[j]=tmp;
}
}
347 前K个高频元素(类似找前k大元素,小根堆,快速排序思想)
/**
1.计算每个元素出现的次数,采用map存储;使用list存储节点;
2.寻找第k大的元素,小根堆
*/
class Solution {
public int[] topKFrequent(int[] nums, int k) {
//1.计算每个元素出现的次数,采用Map进行存储
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<nums.length;i++){
map.put(nums[i],map.getOrDefault(nums[i],0)+1);
}
//【关键】将map中的元素存储到ArrayList中
List<int[]> list=new ArrayList<>();
for(Map.Entry<Integer,Integer> entry:map.entrySet()){
list.add(new int[]{entry.getKey(),entry.getValue()});
}
//2.堆排序,寻找第k大的元素,小根堆
//建立大小为k的小根堆
for(int i=k/2-1;i>=0;i--){
downAdjust(list,i,k);
}
//遍历后续元素
for(int i=k;i<list.size();i++){
if(list.get(i)[1]>list.get(0)[1]){
swap(list,i,0);
downAdjust(list,0,k);
}
}
//返回
int[] ret=new int[k];
for(int i=0;i<k;i++){
ret[i]=list.get(i)[0];
}
return ret;
}
//向下调整
public void downAdjust(List<int[]> list,int pos,int len){
//pos为下标
for(int son=pos*2+1;son<len;son=son*2+1){
if(son+1<len&&list.get(son+1)[1]<list.get(son)[1]) son++;
if(list.get(son)[1]<list.get(pos)[1]){
swap(list,son,pos);
pos=son;
}else{
break;
}
}
}
public void swap(List<int[]> list,int i,int j){
int[] tmp=list.get(i);
list.set(i,list.get(j));
list.set(j,tmp);
}
}
/**
1.计算每个元素出现的次数,采用map存储;使用list存储节点
2.快速排序思想,查找第k大的元素
*/
class Solution {
public int[] topKFrequent(int[] nums, int k) {
//1.计算每个元素出现的次数,采用map存储;使用list存储节点
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<nums.length;i++){
map.put(nums[i],map.getOrDefault(nums[i],0)+1);
}
List<int[]> list=new ArrayList<>();
for(Map.Entry<Integer,Integer> entry:map.entrySet()){
list.add(new int[]{entry.getKey(),entry.getValue()});
}
findpos(list,0,list.size()-1,k-1); //pos为下标
//返回
int[] ret=new int[k];
for(int i=0;i<k;i++){
ret[i]=list.get(i)[0];
}
return ret;
}
//2.快速排序思想,查找第k大的元素
public void findpos(List<int[]> list,int left,int right,int pos){
//pos为下标
//寻找枢纽值
int index=left;
for(int i=left+1;i<=right;i++){
if(list.get(i)[1]>list.get(left)[1]){ //逆序排序
swap(list,i,++index);
}
}
swap(list,left,index);
if(index==pos){ //注意编号和下标
return;
}else if(pos<index){
findpos(list,left,index-1,pos);
}else{
findpos(list,index+1,right,pos);
}
}
public void swap(List<int[]> list,int i,int j){
int[] tmp=list.get(i);
list.set(i,list.get(j));
list.set(j,tmp);
}
}
55 跳跃游戏(动态规划;性质如果能够到达当前位置,那么也就一定能够到达当前位置的左边所有位置)
/*
方法二:【性质】如果能够到达当前位置,那么也就一定能够到达当前位置的左边所有位置
*/
class Solution {
public boolean canJump(int[] nums) {
int k=0;//k为当前能够到达的最大位置
for(int i=0;i<nums.length;i++){
if(i>k) return false;//【关键】遍历元素位置下标大于当前能够到达的最大位置下标,不能到达
//能够到达当前位置,看是否更新能够到达的最大位置k
k=Math.max(k,i+nums[i]); //【关键】
}
//跳出则表明能够到达最大位置
return true;
}
}
/*
方法一:动态规划
1.参数
F[k]表示从前面0到k-1个元素是否可以跳到第k个元素上,如果可以F[k]为true,否则为false
2.递推方程
F[k]有前面0到k-1位置的F[j]决定,如果F[j]==true并且j+nums[j]>=k,则可以调到第k个位置
3.初值条件
F[0]=true;
*/
class Solution {
public boolean canJump(int[] nums) {
boolean[] F=new boolean[nums.length];
//初值条件
F[0]=true;
//递推方程
for(int k=1;k<nums.length;k++){
for(int j=0;j<k;j++){
if(F[j]==true&&k-j<=nums[j]){//【易错】nums[j]为可以跳跃的最大长度
F[k]=true;
break;
}
}
}
return F[nums.length-1];
}
}
*******************************************************************************************************************************************************************************************************************
416 分割等和子集(转化为01背包问题,动态规划,一维和二维)
/*
转化为0-1背包问题,找到价值和为sum/2的情况
1.参数
dp[i]表示价值为i的组合是否能够找到
2.递推方程
dp[i]=dp[i-num],有一个生效即有效
3.初值条件
dp[0]=true;
*/
class Solution {
public boolean canPartition(int[] nums) {
//1.计算目标价值
int sum=0;
for(int num:nums){
sum+=num;
}
//提前返回
if(sum%2!=0) return false;
int x=sum/2;
//2.0-1背包问题
boolean[] dp=new boolean[x+1];
dp[0]=true;
for(int num:nums){ //【关键】对于每个num元素,遍历每个dp元素
for(int i=x;i>=num;i--){
if(dp[i-num]==true){
dp[i]=true;
}
}
}
return dp[x];
}
}
437 路径总和3(前缀和、用map存储+前序遍历回溯;以每个节点作为根节点向下前序遍历、两次前序遍历)
/*
方法一:前缀和+前序遍历回溯
1.使用map记录从根节点开始,到达每个节点的路径和,及其出现的路径和次数
2.当前节点的路径和-target,能够在前面找到该路径和 或者 “剩余路径和”为0
*/
class Solution {
int cnt=0;
public int pathSum(TreeNode root, int targetSum) {
Map<Integer,Integer> map=new HashMap<>();
map.put(0,1);
preorder(root,targetSum,0,map);
return cnt;
}
public void preorder(TreeNode root,int targetSum,int prePathSum,Map<Integer,Integer> map){
if(root==null) return;
int curPathSum=prePathSum+root.val;
if(map.containsKey(curPathSum-targetSum)){
cnt+=map.get(curPathSum-targetSum);
}
map.put(curPathSum,map.getOrDefault(curPathSum,0)+1);
//遍历子树
preorder(root.left,targetSum,curPathSum,map);
preorder(root.right,targetSum,curPathSum,map);
//回溯
map.put(curPathSum,map.getOrDefault(curPathSum,0)-1); //【易错】不是删除,而是数量减一
}
}
☆139 单词拆分(动态规划,dp[i]=dp[j]&&check(s[j…i-1]),j的范围从0到i-1每次遍历一轮+用set存储字典)
/**
动态规划
1.参数
dp[i]表示前i个元素是否可以拆分,boolean
如果i为下标,dp[i]=dp[j]&&check(j+1,i);但是j可以不包含任何元素,此时j=-1,但是数组下标不包含-1
因此偏移,i为编号,dp[i]表示考虑前i个元素,下标从0到i-1
2.递推方程
dp[i]=dp[j]&&check(j,i-1),前面的j表示元素个数,后面的j表示元素下标【关键】
3.初值条件
dp[0]=true;
*/
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
//将字典存储到set中
Set<String> set=new HashSet<>();
for(String word:wordDict){
set.add(word);
}
//动态规划
boolean[] dp=new boolean[s.length()+1];
dp[0]=true;
for(int i=1;i<=s.length();i++){ //i为元素个数
for(int j=i-1;j>=0;j--){ //j为元素下标
if(dp[j]&&check(s.substring(j,i),set)){ //有一个可拆分,当前可拆分,跳出循环
dp[i]=true;
break;
}
}
}
return dp[s.length()];
}
public boolean check(String str,Set<String> set){
return set.contains(str);
}
}
17 电话号码的字母组合(先用map存储所有数字对应字母序列+用list存储对应输入数字对应的字母序列+dfs回溯全排列)
```java
/**
1.map存储键值对,电话号码:字母序列
2.dfs回溯
*/
class Solution {
List<String> ret=new ArrayList<>();
public List<String> letterCombinations(String digits) {
if(digits==null||digits.length()<=0) return ret;
Map<Character,String> map=new HashMap<>();
map.put('2',"abc");
map.put('3',"def");
map.put('4',"ghi");
map.put('5',"jkl");
map.put('6',"mno");
map.put('7',"pqrs");
map.put('8',"tuv");
map.put('9',"wxyz");
dfs(digits,0,new StringBuilder(),map);
return ret;
}
public void dfs(String digits,int index,StringBuilder sb,Map<Character,String> map){
//1.终止条件
if(index>=digits.length()){
ret.add(sb.toString());
return;
}
//输入一定有效
//2当前节点处理,往下遍历
for(int i=0;i<map.get(digits.charAt(index)).length();i++){
sb.append(map.get(digits.charAt(index)).charAt(i)+"");
dfs(digits,index+1,sb,map);
//回溯
sb.delete(sb.length()-1,sb.length());
}
}
}
```
647 回文子串(中心扩展法)
/*
【区分最长回文子串——动态规划、中心扩展法】
*/
class Solution {
int ret=0;
public int countSubstrings(String s) {
for(int i=0;i<s.length();i++){
expandAroundCenter(s,i,i);//【关键】中心扩展法,两个中心
expandAroundCenter(s,i,i+1);
}
return ret;
}
//中心扩展法
public void expandAroundCenter(String s,int left,int right){
while(left>=0&&right<s.length()&&s.charAt(left)==s.charAt(right)){
ret++;
left--;
right++;
}
}
}
☆96 不同的二叉搜索树(动态规划)
动态规划
特定条件:节点从1到n
-
假设n个节点存在二叉排序树的个数时
G(n),令f(i)为以i为根节点的二叉搜索树的个数,则G(n)=f(1)+f(2)+…+f(n) -
当i为根节点时,左子树节点的个数为i-1个,右子树节点的个数为n-i个
【关键】二叉排序树的左子树和右子树仍然是一棵二叉排序树
f(i)=G(i-1)*G(n-i) -
综合上述公式,得到卡特兰数公式:
G(n)=G(0)*G(n-1)+G(1)*G(n-2)+…+G(n-1)*G(0)
- one参数
G(n)表示n个节点存在的二叉排序树
- two递推方程
G(n)=G(0)*G(n-1)+G(1)*G(n-2)+…+G(n-1)*G(0)
- three初值条件
dp[0]=1;
dp[1]=1;
class Solution{
public int numTrees(int n){
int[] dp=new int[n+1];
//初值条件
dp[0]=1;
dp[1]=1;
for(int i=2;i<=n;i++){//【难点】计算每个节点数情况下二叉排序树个数
for(int j=1;j<=i;j++){//以j为根节点的二叉搜索树的个数
dp[i]+=dp[j-1]*dp[i-j]//【关键】
}
}
return dp[n];
}
}
第⑥天
206 反转链表
/**
递归
1.递归出口
2.到达最后一个节点,返回新的头结点
处理当前节点
*/
class Solution {
public ListNode reverseList(ListNode head) {
if(head==null) return head;//空节点处理
//递归出口
if(head.next==null){
return head;
}
//处理当前节点
ListNode newhead=reverseList(head.next);
head.next.next=head;
head.next=null;
return newhead;
}
}
53 最大子序列和(动态规划,F[k]为以nums[k]为最后一个元素的子数组 的最大和)
/**
最大和连续子数组
动态规划
1.参数
dp[i]表示考虑元素nums[i]子序列的最大和
2.递推方程
dp[i]=max{d[i-1]+nums[i],nums[i]}
3.初值条件
dp[0]=nums[0]
*/
class Solution {
public int maxSubArray(int[] nums) {
int[] dp=new int[nums.length];
dp[0]=nums[0];
int maxSum=nums[0];
for(int i=1;i<nums.length;i++){
dp[i]=Math.max(dp[i-1]+nums[i],nums[i]);
maxSum=Math.max(dp[i],maxSum);
}
return maxSum;
}
}
21 合并两个有序链表(尾插法,递归法)
//非递归写法
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode head=new ListNode(-1);
ListNode tail=head;
while(l1!=null&&l2!=null){
if(l1.val<=l2.val){
tail.next=l1;
tail=tail.next;
l1=l1.next;
}else{
tail.next=l2;
tail=tail.next;
l2=l2.next;
}
}
if(l1!=null){
tail.next=l1;
}else{
tail.next=l2;
}
return head.next;
}
}
//递归写法
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
if(l1==null) return l2;
if(l2==null) return l1;
if(l1.val<=l2.val){
l1.next=mergeTwoLists(l1.next,l2);
return l1;
}else{
l2.next=mergeTwoLists(l1,l2.next);
return l2;
}
}
}
☆1 无序两数之和(利用map把当前元素的前面元素(元素及其下标)都存入map中)
/**
利用map存储遍历元素,
一次遍历,每遍历到一个元素,检查是否==target
用重复元素,不能再使用双指针
*/
class Solution {
public int[] twoSum(int[] nums, int target) {
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<nums.length;i++){
if(map.containsKey(target-nums[i])){
return new int[]{i,map.get(target-nums[i])};
}
map.put(nums[i],i);
}
return new int[2];
}
}
160 相交链表(没有交点,同时到达null(无需特殊处理);有交点,同时到达交点;)
/**
1.较长链表先走k步,走到等长
2.再一起走,走到相交节点
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
int len1=0,len2=0;
ListNode l1=headA,l2=headB;
while(l1!=null){
len1++;
l1=l1.next;
}
while(l2!=null){
len2++;
l2=l2.next;
}
int len=len1>=len2? len1-len2:len2-len1;
l1=len1>=len2? headA:headB;
l2=len1<len2? headA:headB;
while(len--!=0){
l1=l1.next;
}
while(l1!=null&&l2!=null){
if(l1==l2){
return l1;
}
l1=l1.next;
l2=l2.next;
}
return null;
}
}
/**
"a+c"+b="b+c"+a
l1走完自己走l2
l2走完自己走l1
相交,能走到相交节点
不想交,各走完两条链表,一起走到null
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode l1=headA,l2=headB;
while(!(l1==null&&l2==null)){
if(l1==l2){
return l1;
}
l1=l1==null? headB:l1.next;
l2=l2==null? headA:l2.next;
}
return null;
}
}
*******************************************************************************************************************************************************************************************************************
121 买卖股票的最佳时机(minprice,从最开始到当前元素的前一个元素中股票最低价)
/**
一次遍历,记录前面出现的最小元素
*/
class Solution {
public int maxProfit(int[] prices) {
int maxvalue=0;
int min=prices[0];
for(int i=1;i<prices.length;i++){
maxvalue=Math.max(maxvalue,prices[i]-min);
min=Math.min(min,prices[i]);
}
return maxvalue;
}
}
141 环形链表(快慢指针+同时从第一个节点出发,注意while循环条件)
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode slow=head;
ListNode fast=head;
while(true){
if(fast==null||fast.next==null) return false;
slow=slow.next;
fast=fast.next.next;
if(slow==fast){
return true;
}
}
}
}
20 有效的括号
/**
一次遍历
1.遇到左括号入栈
2.遇到右括号出栈,并对比
*/
class Solution {
public boolean isValid(String s) {
Deque<Character> stack=new LinkedList<>();
for(int i=0;i<s.length();i++){
if(s.charAt(i)=='('||s.charAt(i)=='['||s.charAt(i)=='{'){
stack.push(s.charAt(i));
}else if(s.charAt(i)==')'){
if(stack.isEmpty()||stack.peek()!='(') return false;
stack.pop();
}else if(s.charAt(i)==']'){
if(stack.isEmpty()||stack.peek()!='[') return false;
stack.pop();
}else{
if(stack.isEmpty()||stack.peek()!='{') return false;
stack.pop();
}
}
return stack.isEmpty();
}
}
104 二叉树的最大深度(递归做法)
/**
递归
*/
class Solution {
public int maxDepth(TreeNode root) {
if(root==null) return 0;
return Math.max(maxDepth(root.left),maxDepth(root.right))+1;
}
}
/**
层序遍历
*/
class Solution {
public int maxDepth(TreeNode root) {
if(root==null) return 0;
int depth=0;
Queue<TreeNode> queue=new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()){
depth++;
int levelsize=queue.size();
while(levelsize--!=0){
TreeNode node=queue.poll();
if(node.left!=null) queue.offer(node.left);
if(node.right!=null) queue.offer(node.right);
}
}
return depth;
}
}
234 回文链表(快慢指针+栈,快慢指针+翻转一般链表)
/**
1.快慢指针寻找链表的中间节点
2.前面一般节点入栈
*/
class Solution {
public boolean isPalindrome(ListNode head) {
if(head==null||head.next==null) return true;
Deque<ListNode> stack=new LinkedList<>();
//快慢指针寻找中间节点
ListNode slow=head,fast=head.next;
while(fast!=null&&fast.next!=null){
slow=slow.next;
fast=fast.next.next;
}
//当fast.next==null时,此时链表数量为偶数,slow在左半边链表最后一个节点
//当fast==null时,此时链表数量为奇数,slow在中间节点
ListNode l1=head,l2;
if(fast==null){
while(l1!=slow){
stack.push(l1);
l1=l1.next;
}
l2=l1.next;
}else{
while(l1!=slow.next){
stack.push(l1);
l1=l1.next;
}
l2=l1;
}
//比较
while(!stack.isEmpty()){
if(stack.peek().val!=l2.val) return false;
stack.pop();
l2=l2.next;
}
return true;
}
}
第⑦天
70 爬楼梯
/**
动态规划
1.参数
dp[i]表示到达第i阶的方法
2.递推方程
dp[i]=dp[i-1]+dp[i-2]
3.初值条件
dp[0]=1
dp[1]=1
*/
class Solution {
public int climbStairs(int n) {
if(n==0||n==1) return 1;
int[] dp=new int[n+1];
dp[0]=1;
dp[1]=1;
for(int i=2;i<=n;i++){
dp[i]=dp[i-1]+dp[i-2];
}
return dp[n];
}
}
155 最小栈(易错,对象相等equals)
class MinStack {
Deque<Integer> stack=new LinkedList<>();
Deque<Integer> min_stack=new LinkedList<>();//单调递减栈,可以等
/** initialize your data structure here. */
public MinStack() {
}
public void push(int val) {
stack.push(val);
if(min_stack.isEmpty()||val<=min_stack.peek()){
min_stack.push(val);
}
}
public void pop() {
if(!stack.isEmpty()){
if(stack.peek().equals(min_stack.peek())){
min_stack.pop();
}
stack.pop();
}
}
public int top() {
if(!stack.isEmpty()){
return stack.peek();
}
return -1;
}
public int getMin() {
if(!min_stack.isEmpty()){
return min_stack.peek();
}
return -1;
}
}
543 二叉树的直径(前序遍历+从上往下,后序遍历+从下往上)
/**
计算二叉树的直径,路径边的个数
后序遍历,从下往上
*/
class Solution {
int max=0;
public int diameterOfBinaryTree(TreeNode root) {
postorder(root);
return max;
}
public int postorder(TreeNode root){
if(root==null) return 0;
int left=postorder(root.left);
int right=postorder(root.right);
max=Math.max(left+right,max);
return Math.max(left,right)+1;
}
}
169 多数元素(投票算法)
/**
多数元素,投票法
1.遇到多数元素,cnt++
遇到其他元素,cnt--
2.如果cnt==0,重置多数元素
*/
class Solution {
public int majorityElement(int[] nums) {
int major=nums[0];
int cnt=1;
for(int i=1;i<nums.length;i++){
if(major==nums[i]){
cnt++;
}else{
cnt--;
if(cnt==0){
major=nums[i];
cnt=1;
}
}
}
return major;
}
}
101 对称二叉树(从根节点开始,两个指针分别遍历左子树和右子树)
/**
分割成两个二叉树
*/
class Solution {
public boolean isSymmetric(TreeNode root) {
if(root==null) return true;
return preorder(root.left,root.right);
}
public boolean preorder(TreeNode root1,TreeNode root2){
if(root1==null&&root2==null) return true;
if(root1==null||root2==null) return false;
if(root1.val!=root2.val) return false;
return preorder(root1.left,root2.right)&&preorder(root1.right,root2.left);
}
}
*******************************************************************************************************************************************************************************************************************
226 翻转二叉树(后序遍历,交换左右子树)
/**
后序遍历
*/
class Solution {
public TreeNode invertTree(TreeNode root) {
postorder(root);
return root;
}
public void postorder(TreeNode root){
if(root!=null){
postorder(root.left);
postorder(root.right);
TreeNode tmp=root.left;
root.left=root.right;
root.right=tmp;
}
}
}
136 只出现一次的数字(位运算)
/**
一次遍历
a^a=0
*/
class Solution {
public int singleNumber(int[] nums) {
int ret=nums[0];
for(int i=1;i<nums.length;i++){
ret^=nums[i];
}
return ret;
}
}
283 移动零(双指针)
/**
双指针,一次遍历
不调换,移动非零元素
*/
class Solution {
public void moveZeroes(int[] nums) {
int index=0;
for(int i=0;i<nums.length;i++){
if(nums[i]!=0){
swap(nums,index++,i);
}
}
}
public void swap(int[] nums,int i,int j){
int tmp=nums[i];
nums[i]=nums[j];
nums[j]=tmp;
}
}
☆617 合并二叉树(递归,新建二叉树+前序遍历,迭代+层序遍历)
/**
新建二叉树,递归
*/
class Solution {
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
//递归出口
if(root1==null) return root2;
if(root2==null) return root1;
TreeNode root=new TreeNode(root1.val+root2.val);
root.left=mergeTrees(root1.left,root2.left);
root.right=mergeTrees(root1.right,root2.right);
return root;
}
}
☆448 找到所有数组中消失的数字(从前往后遍历数组,将元素与下标匹配)
/**
不使用额外空间
1.原地swap,hash数组
一次遍历,元素num[i]放到nums[nums[i]-1]的位置上
2.可能存在重复的数字
*/
class Solution {
public List<Integer> findDisappearedNumbers(int[] nums) {
List<Integer> list=new ArrayList<>();
//1.一次遍历,元素num[i]放到nums[nums[i]-1]的位置上
for(int i=0;i<nums.length;i++){
if(nums[nums[i]-1]!=nums[i]){ //【关键】当原来的位置上不对时,才替换
swap(nums,i,nums[i]-1);
i--;
}
}
//2.对比,寻找不存在的数字
for(int i=0;i<nums.length;i++){
if(i!=nums[i]-1){
list.add(i+1);
}
}
return list;
}
public void swap(int[] nums,int i,int j){
int tmp=nums[i];
nums[i]=nums[j];
nums[j]=tmp;
}
}
☆581 最短无序连续子数组(两次遍历+从左到右寻找右边界+从右到左寻找左边界)
/**
1.无序数组左边界
无序数组右边界
2.从左往右,寻找右边界,max为元素左边最大值,当nums[i]min时,left=i;
*/
class Solution {
public int findUnsortedSubarray(int[] nums) {
//从左往右,寻找右边界
int max=nums[0];
int right=0;
for(int i=1;i<nums.length;i++){
if(nums[i]<max){
right=i;
}
max=Math.max(max,nums[i]);
}
//从右往左,寻找左边界
int min=nums[nums.length-1];
int left=nums.length-1;
for(int i=nums.length-2;i>=0;i--){
if(nums[i]>min){
left=i;
}
min=Math.min(min,nums[i]);
}
return right>left? right-left+1:0;
}
}
第⑧天
238 除自身以外数组的乘积(左右两次遍历)
/*
1.两次遍历
第一次遍历从左往右,遍历到当前元素,res[i]存储除了当前元素外左边元素的乘积
第二次遍历从右往左,遍历到当前元素,res[i]在乘以除了当前元素右边元素的乘积
2.返回数组不算空间复杂度,其他空间复杂度要求o(1)
*/
class Solution {
public int[] productExceptSelf(int[] nums) {
int[] res=new int[nums.length];
//【关键】初始乘积
int product=1;
//1.从左往右遍历
for(int i=0;i<nums.length;i++){
//当前元素位置处理
res[i]=product;
product*=nums[i];//为下一个位置更新product
}
//2.从右往左遍历
product=1;
for(int i=nums.length-1;i>=0;i--){
//当前元素处理
res[i]*=product;
product*=nums[i];
}
return res;
}
}
49 字母异位词分组(辅助计数字母数组转化为String作为key辨析字母异位词+map)
/*
辅助计数数组
仍有map存储结果,将辅助计数数组转化为字符串作为key
*/
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String,List<String>> map=new HashMap<>();
for(String str:strs){
//1.辅助计数数组做key
byte[] cnt=new byte[26];//【易错】byte[]可以通过new String()转化为String,但是int[]不可行
for(int i=0;i<str.length();i++){
cnt[str.charAt(i)-'a']++;
}
String key=new String(cnt);
//2.当前str加入map
if(!map.containsKey(key)){
map.put(key,new ArrayList<String>());
}
map.get(key).add(str);
}
List<List<String>> ret=new ArrayList<>();
for(Map.Entry<String,List<String>> entry:map.entrySet()){
ret.add(entry.getValue());
}
return ret;
}
}
438 找到字符串中所有字母异位词(双指针+滑动窗口,
字母异位词计数辅助数组比较sCnt[s.charAt(right)-‘a’]>pCnt[s.charAt(right)-‘a’];滑动窗口+字母异位词计数辅助数组比较Arrays.equals(sCnt,pCnt);)
/*
方法一:滑动窗口+双指针(辅助计数数组)
1.定义左右指针left,right
2.【关键】当sCnt[s.charAt(right)-'a']<=pCnt[p.charAt(right)-'a']当前子串元素计数小于等于p串中相应元素计数时,right向右滑动,
否则left向右滑动,s中其对应的字符计数减一;直至s中right对应的字符计数<=p中相应的字符对应的计数
3.当right-left+1==p.length()时,找到字母异位串
*/
class Solution{
public List<Integer> findAnagrams(String s,String p){
List<Integer> ret=new ArrayList<>();
//边界情况
if(p.length()>s.length()){
return ret;
}
//1.p窗口各字符初始计数
int[] pCnt=new int[26];
int[] sCnt=new int[26];
for(int i=0;i<p.length();i++){
pCnt[p.charAt(i)-'a']++;
}
//【关键】2.s双指针,right指针和left指针滑动
int left=0;
for(int right=0;right<s.length();right++){
//【易错】当前right字符处理
sCnt[s.charAt(right)-'a']++;
//s中当前right元素计数<=p串中相应元素计数时,right向右滑动;否则left向右滑动,s中其对应的字符计数减一;直至s中right对应的字符计数<=p中相应的字符对应的计数
while(sCnt[s.charAt(right)-'a']>pCnt[s.charAt(right)-'a']){
sCnt[s.charAt(left++)-'a']--;
}
if(right-left+1==p.length()){
ret.add(left);
}
}
return ret;
}
}
337 打家劫舍3(树形打家劫舍,树形动态规划+后序遍历+动态规划思想偷当前不偷当前)
树形动态规划(递归+后序遍历)
每个节点可以选择偷或者不偷两种状态,根据题目意思,相邻节点不可偷
- 当前节点选择偷时,那么两个孩子节点就不能选择偷了
- 当前节点选择不偷时,两个子树只需要拿最多的前出来就行(两个孩子节点偷不偷没有关系)
我们可以使用一个大小为2的数组来表示状态:int[] res=new int[2] 其中0表示不偷,1表示偷
-
参数
-
res[0]表示当前节点不偷,考虑当前节点及其子树能够偷到的最大金额(累后续累计)
-
res[1]表示当前节点偷,考虑当前节点及其子树能够偷到的最大金额
-
-
递推方程
-
当前节点不偷:考虑当前节点及其子树能够偷到的最大金额=左子树能够偷到的最大金额+右子树能够偷到的最大金额(只与左孩子和右孩子偷不偷无所谓)
res[0]=Math.max(left[0],left[1])+Math.max(right[0],right[1]) -
当前节点偷:考虑当前节点及其子树能够偷到的最大金额=左孩子不偷时左子树能够偷到的最大金额+右孩子不偷时右子树能够偷到的最大金额(左孩子,右孩子不能偷)+当前节点金额
res[1]=left[0]+right[0]+root.val
-
class Solution{
public int rob(TreeNode root){
int[] res=postorder(root);
return Math.max(res[0],res[1]);
}
public int[] postorder(TreeNode root){
//子节点为空,返回偷到金额为空
if(root==null) return new int[2];
//1.左右子树处理
int[] left=postorder(root.left);
int[] right=postorder(root.right);
//2.当前节点处理
int[] res=new int[2];
//当前节点不偷
res[0]=Math.max(left[0],left[1])+Math.max(right[0],right[1]);
//当前节点偷
res[1]=left[0]+right[0]+root.val;
return ret;
}
}
279 完全平方数(动态规划,零钱兑换,dp[i]=Math.min(dp[i],dp[i-nums[j]]+1))(每轮遍历所有零钱种类)
/*
动态规划
【零钱兑换问题】
完全背包问题
1.参数
dp[i]表示组成金额i所需要的最少硬币数量
2.递推方程
dp[i]=Math.min(dp[i],dp[i-nums[j]]+1)
j的范围从0到nums.length-1,每次完全遍历nums数组
但是需要保证更新时i>nums[j],否则数组下标为负数
*/
class Solution {
public int numSquares(int n) {
int[] dp=new int[n+1];
//1.初值条件
Arrays.fill(dp,n+1);//默认初始化都为n+1
dp[0]=0;
//2.递推方程
for(int i=1;i<=n;i++){
dp[i]=i;//最少为i个硬币
for(int j=1;j*j<=i;j++){//【关键】【区别零钱兑换】j*j有序
dp[i]=Math.min(dp[i],dp[i-j*j]+1);
}
}
return dp[n];
}
}
253 会议室2(遍历每个会议室的最后一个会议的结束时间;最小堆,每次将会议放入结束时间最早的会议室,或者新开会议室)
/*
会议室|
给定一个“会议时间安排”的数组,每个会议时间都会包括开始和结束时间
考虑能否同时参加所有会议
*/
public static boolean canAttendMeetings(int[][] intervals){
//二维数组根据会议开始时间排序
Arrays.sort(intervals,new Comparator<int[]>(){
public int compare(int[] o1,int[] o2){
return o1[0]-o2[0];
}
});
for(int i=0;i<intervals.length-1;i++){
if(intervals[i][1]>intervals[i+1][0]){
return false;
}
}
return true;
}
/*
会议室||
给定一个“会议时间安排”的数组,每个会议时间都会包括开始和结束时间,
为了避免会议冲突,同时要充分考虑会议室资源,
请你计算至少需要多少间会议室才能满足这些会议安排。
*/
/*
方法一:常规做法
1.对所有会议,按照开始时间排升序;
2.【贪心算法】每来一个新的会议,遍历所有会议室,
one如果有空的会议室(当前会议开始时间 晚于 该会议室最后会议的结束时间),将该会议加入该会议室,并更新该会议室会议最后结束时间
two如果该会议的开始时间与所有会议室的最晚结束时间冲突,新开一间会议室,更新该会议室的结束时间
*/
public static int MinMeetingRooms1(int[][] intervals){
List<Integer> rooms=new ArrayList<>();
//对会议按照开始时间排序
Arrays.sort(intervals,(o1,o2)->o1[0]-o2[0]);
//遍历所有会议
for(int i=0;i<intervals.length;i++){
//刚开始没有会议室
if(rooms.size()==0){
rooms.add(intervals[i][1]);//将第一个会议开辟一间会议室
continue;
}
//遍历所有会议室,找可用的会议室
int j=0;
for(;j<rooms.size();j++){
if(intervals[i][0]>=rooms.get(j)){//1.找到可用的会议室
rooms.set(j,intervals[i][1]);
break;
}
}
if(j==rooms.size()){//2.没有找到可用的会议室
rooms.add(intervals[i][1]);
}
}
return rooms.size();
}
/*
方法二:最小堆
*/
public static int MinMeetingRooms2(int[][] intervals){
//按照会议开始时间对intervals排序
Arrays.sort(intervals,(o1,o2)->o1[0]-o2[0]);
PriorityQueue<Integer> minHeap=new PriorityQueue<>();
//遍历所有会议
for(int i=0;i<intervals.length;i++){
//第一个会议endtime直接加入minHeap
if(i==0){
minHeap.offer(intervals[i][1]);
continue;
}
//1.当前会议开始时间大于等于最小堆堆顶会议结束时间,“堆顶会议删除”,当前会议加入堆;重新建立最小堆
//2.当前会议开始时间小于最小堆堆顶会议结束时间,直接将当前会议加入最小堆;重新建立堆
/*【关键】当前会议每次都和所有会议室中的最后会议的最小结束时间作比较,
如果当前会议开始时间>=最小堆堆顶最小会议结束时间,则可以加入该会议室,更新该会议室的最晚结束时间;
最小堆中只保留所有会议室的最晚会议的结束时间,并且堆顶为所有会议室中的最小结束时间;
*/
if(intervals[i][0]>=minHeap.peek()){
minHeap.poll();
}
minHeap.offer(intervals[i][1]);
}
return minHeap.size();
}
面试遇到的题
【快手一面】1143 最长公共子序列长度(二维动态规划,dp[i][j]表示考虑text1的前i个字符,text2的前j个字符最长公共子序列长度)
/**
最长公共子序列
1.参数
dp[i][j]为考虑text1的前i个字符和text2的前j个字符,最长公共序列长度(不连续),i为编号,元素数量
2.递推方程
当text1[i-1]==text2[j-1],dp[i][j]=dp[i-1][j-1]+1
否则,dp[i][j]=max{dp[i-1][j],dp[i][j-1]}
3.初值条件
dp[0][0]=0;
dp[0][j]=0;
dp[i][0]=0;
*/
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int[][] dp=new int[text1.length()+1][text2.length()+1];
dp[0][0]=0;
for(int j=1;j<text2.length();j++){ //i和j为元素数量
dp[0][j]=0;
}
for(int i=1;i<text1.length();i++){
dp[i][0]=0;
}
//转移方程
for(int i=1;i<=text1.length();i++){ //i和j为元素数量
for(int j=1;j<=text2.length();j++){
if(text1.charAt(i-1)==text2.charAt(j-1)){
dp[i][j]=dp[i-1][j-1]+1;
}else{
dp[i][j]=Math.max(dp[i][j-1],dp[i-1][j]);
}
}
}
return dp[text1.length()][text2.length()];
}
}
/**
最长公共子串
1.参数
dp[i][j]为考虑text1的第i个字符和text2的第j个字符,最长公共子串长度(连续),i为编号
2.递推方程
当text1[i-1]==text2[j-1]时,dp[i][j]=dp[i-1][j-1]+1
否则dp[i][j]=0
3.初值条件
dp[0][0]=0;
dp[0][j]=0;
dp[i][0]=0;
*/
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int maxLength=0;
int[][] dp=new int[text1.length()+1][text2.length()+1];
dp[0][0]=0;
for(int j=1;j<text2.length();j++){ //i和j为元素数量
dp[0][j]=0;
}
for(int i=1;i<text1.length();i++){
dp[i][0]=0;
}
//转移方程
for(int i=1;i<=text1.length();i++){ //i和j为元素数量
for(int j=1;j<=text2.length();j++){
if(text1.charAt(i-1)==text2.charAt(j-1)){
dp[i][j]=dp[i-1][j-1]+1;
}else{
dp[i][j]=0;
}
maxLength=Math.max(maxLength,dp[i][j]);
}
}
return maxLeng
}
}
【字节一面】无序数组寻找两数之和,数据有重复
输入:nums=[1,2,3,4,5,5,6,6,7,8],target=10
输出:返回一个所有两数之和的元素下标
一共有五对:[[1,9],[2,8],[3,7],[3,6],[4,5]
import java.util.*;
public class Main {
public static void main(String[] args) {
int[] nums=new int[]{1,2,3,4,5,5,6,6,7,8};
int target=10;
//【重要】采用结果变量存储结果
List<int[]> ret=twosum(nums,target); //注意返回结果的输出,上次面试就是在这里卡了好久
//【重要】输出
for(int[] arr:ret){ //所有的输出都打印出来
System.out.println(Arrays.toString(arr)); //数组输出为String
}
for(int i=0;i<ret.size();i++){
System.out.printf("%d\t%d \n",ret.get(i)[0],ret.get(i)[1]); //采用打印空格换行输出
}
}
/**
采用map>存储当前元素前面的所有元素出现的下标,
重复元素采用一个list存储
*/
public static List<int[]> twosum(int[] nums,int target){
List<int[]> ret=new ArrayList<>();
if(nums==null||nums.length<=0) return ret;
Map<Integer,List<Integer>> map=new HashMap<>();
map.put(0,new ArrayList<>(Arrays.asList(nums[0])));
for(int i=1;i<nums.length;i++){
if(map.containsKey(target-nums[i])){ //存在两数之和
for(int num:map.get(target-nums[i])){
ret.add(new int[]{num,i});
}
}
if(map.containsKey(nums[i])){ //当前元素及其下标加入map
map.get(nums[i]).add(i);
}else{
map.put(nums[i],new ArrayList<>(Arrays.asList(i)));
}
}
return ret;
}
}
面试做题注意:
-
拿到题目的时候不要害怕,认真审题:了解题意和限制条件,思考输入是什么,输出是什么;(不要着急编码)
-
结合常见题型,但是不要陷入思维定式;要学会思考;
-
函数的定义
public static 返回类型 函数名(参数){},好好思考返回值,输入输出,不要慌 -
在编码的过程中尽量慢一点,不要慌,慢慢来比较快;多思考一下得到的是什么数据类型;
-
编码完成以后
- 输出是什么,在main函数中定义返回变量并调用功能函数
- 不要一写完就告诉面试官,而是自己需要测试并且写完输入输出以后再告诉面试官好了,所有的返回结果都打印出来
注意字节的代码题是直接写,不是leetcode或者牛客网的形式,所有的东西都需要自己定义,更加要求你的水平
一定要先和面试官沟通好思路,输入,输出,不懂的就问,不要自己在这里瞎写
写一个LRU类(此处为一维的LRU,不是做题的二维的LRU)
/*
定义了一个LRU类
put函数,get函数
更新节点的值,获取节点的值,都需要把当前节点移动到最前面去
插入节点时,如果size中去,可以快速找到该节点
一维的:
还没有理解
*/
【滴滴一面】判断字符串A是不是字符串B的子集
我们定义一个字符串的超集为:若字符串A包含字符串B中的所有字符,且字符串A中某一个字符a的数量不小于a在字符串B中的数量,那么A为B的超集。
例如:若字符串A为“abbccdd”,B为“abcdd”,那么A是B的超集。
若A为“abbccd”,B是“abcdd”,那么A不是B的超集。
现给定字符串A、B,判断A是否是B的超集。
/**
思路一:采用map
1.遍历str1,采用map存储str1的每个字符及其出现的次数
2.遍历str2
*/
public boolean IsSuperSet(String str1,String str2){
//假设str1为超集,str2为子集
Map<Character,Integer> map=new HashMap<>();
for(int i=0;i<str1.length();i++){
map.put(str1.charAt(i),map.getOrDefault(str1.charAt(i),0)+1);
}
for(int i=0;i<str2.length();i++){
if(!map.containsKey(str2.charAt(i))){
return false;
}else{
if(map.get(str1.charAt(i))==0){
return false;
}else{
map.put(str2.charAt(i),map.get(str2.charAt(i))-1);
}
}
}
}