【学习笔记-李宏毅】GAN(生成对抗网络)全系列(一)
文章目录
- 前言
- 相关链接
- 1. Introduction
-
- 1. 1 Basic Idea of GAN
- 1.2 GAN as structured learning
- 1.3 Generator可以自己学吗?
-
- VAE(Variational Auto-encoder)
- 2. CGAN, Conditional Generation by GAN
-
- 2.1 discriminator的架构改进
- 2.2 Stack GAN
- 2.3 Image-to-image
- 2.4 Speech Enhancement(提升语音的质量)
- 2.5 Video Generation
- 3. Unsupervised Conditional Generation
-
- 3.1 方法1:直接转换
-
- 3. 使用Cycle GAN
- 方法2:VAE GAN: Project to Common Space
- GAN(生成对抗网络)全系列(二)
- 更多资料
前言
红色文字代表重点,黄色文字代表次重点,绿色文字代表了解,黑色文字为解释说明
相关链接
- 视频:https://www.youtube.com/playlist?list=PLJV_el3uVTsMq6JEFPW35BCiOQTsoqwNw
1. Introduction
1. 1 Basic Idea of GAN
GAN, Generative Adversarial Network,作用是训练一个Generator,用于生成东西。 例如,如果是图片领域,可以生成人脸图片,如果是文本领域,可以用来生成文章
Generator的使用:给Generator一个随机的Vector,然后Generator生成一个随机的“长Vector”(图片、文字等)

输入的Vector的dimension(就是每个值)对应一个特征,例如上图中的第一个0.1可能就对应头发的颜色
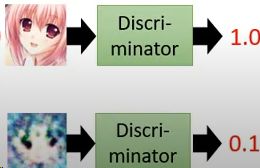
Discriminator(判别器):在训练Generator的时候,要同时训练一个Discriminator,作用是判别一张图片的真实程度。
Discriminator 接受一个图片,输出一个Scalar(数值),Scalar越大表示图片越真实
GAN的训练过程(简易版)
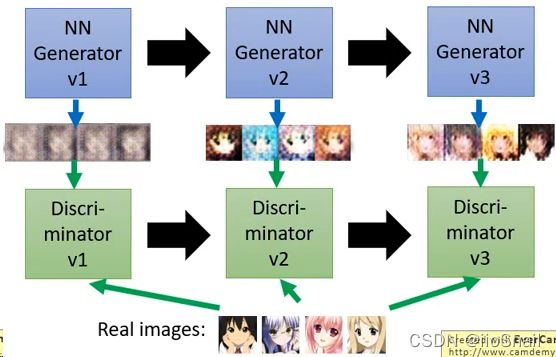
1. 准备一个真实图片的数据集
2. 随机初始化Generator和Discriminator,此时Generator生成图片是瞎生成,Discriminator也是瞎分辨
3. 训练Discriminator:
3.1 让Generator生成一组图片,然后让Discriminator来分辨真假,同时也会告诉Discriminator真实的图片长什么样子
3.2. 根据第 3.1 步的损失来更新Discriminator
4. 训练Generator:
4.1. 继续让Generator生成一组图片,然后让Discriminator来分别真假。注意,本次只会让Discriminator看生成的图片
4.2. 根据第 4.1 步得到的损失来更新Generator
5. 重复迭代3,4步,直到满意为止
(最原始的)GAN训练过程(公式版),在每一个迭代过程做的事如下:
1. 从数据集中拿到 m m m 个样本 { x 1 , x 2 , … , x m } \{ x^1, x^2, \dots, x^m \} {x1,x2,…,xm}
2. 从distribution中拿出 m m m 个噪音向量 { z 1 , z 2 , … , z m } \{ z^1, z^2, \dots, z^m \} {z1,z2,…,zm}(就是生成m个均匀分布的随机向量,当然也可以是其他分布)
3. 让Generator根据噪音向量生成数据 { x ~ 1 , x ~ 2 , … , x ~ m } \{ \tilde{x}^1, \tilde{x}^2, \dots, \tilde{x}^m \} {x~1,x~2,…,x~m},即 x ~ i = G ( z i ) \tilde{x}^i =G(z^i) x~i=G(zi)(这里的 x ~ i \tilde{x}^i x~i 就是一张图片,例如,要生成一张64x64的图片,那么 x ~ i \tilde{x}^i x~i 就是一个4096维的向量)
4. 更新Discriminator的参数 θ d \theta_d θd,更新过程如下:
4.1. 计算Discriminator对“真实数据”判别结果,即 D ( x i ) ∈ [ 0 , 1 ] D(x^i) \in [0,1] D(xi)∈[0,1],我们希望该值越大越好
4.2. 计算Discriminator对“生成数据”的判别结果,即 D ( x ~ i ) D(\tilde{x}^i) D(x~i),我们希望该结果越小越好
4.3. 计算 m m m 个样本的“平均损失”, V ~ = 1 m ∑ i = 1 m log D ( x i ) + 1 m ∑ i = 1 m log ( 1 − D ( x ~ i ) ) \tilde{V} = \frac{1}{m}\sum_{i=1}^{m}\log D(x^i) + \frac{1}{m}\sum_{i=1}^{m}\log\left( 1- D(\tilde{x}^i)\right) V~=m1i=1∑mlogD(xi)+m1i=1∑mlog(1−D(x~i)) 其中 V ~ \tilde{V} V~ 是负数,所以越大越好
4.4. 更新参数 θ d \theta_d θd,即 θ d ← θ d + η ∇ V ~ ( θ d ) \theta_d \leftarrow \theta_d + \eta\nabla\tilde{V}(\theta_d) θd←θd+η∇V~(θd)
5. 更新Generator的参数 θ g \theta_g θg,更新过程如下
5.1. 再从distribution中拿出一组噪音向量 { z 1 , z 2 , … , z m } \{ z^1, z^2, \dots, z^m \} {z1,z2,…,zm}
5.2. 让Generator再生成一组数据,然后送给Discriminator进行判别,并得出分数 D ( G ( z i ) ) D\left(G(z^i)\right) D(G(zi))
5.3. 计算“平均损失” V ~ = 1 m ∑ i = 1 m log D ( G ( z i ) ) \tilde{V} = \frac{1}{m}\sum_{i=1}^{m}\log D\left(G(z^i)\right) V~=m1i=1∑mlogD(G(zi)) 同样, V ~ \tilde{V} V~ 是负数,所以越大越好
5.4. 更新Generator的参数, θ g ← θ g + η ∇ V ~ ( θ g ) \theta_g \leftarrow \theta_g + \eta\nabla\tilde{V}(\theta_g) θg←θg+η∇V~(θg)
如果给定两个噪音向量之间连续的内差,Generator会告诉你这两个图片之间的过渡过程

1.2 GAN as structured learning
Structured Learning 是什么:如果一个任务的输出是sequence、matrix, graph, tree等,那么这个任务就叫 Structured Learning
Structured learning 的特点:
1. 你可以把每种输出都看做是一个“类别(Class)”
2. 输出空间巨大(输出种类太多),意味着输出的“class”根本就没有对应的“train data”,例如生成的人脸图片在训练集中根本就找不到
3. 测试阶段,网络的输出必须是新东西。例如:测试阶段生成的人脸图片是在训练阶段没有生成过的
4. 需要更加智能的网络
5. 网络必须有大局观,例如生成文章时,单看其中的几个字并不能判断出结果的好坏,要看整个文章
Structured Learning两种方式:
1. Bottom Up(自底向上):从部分到整体
2. Top Down(自顶向下):从整体到部分
可以把GAN看做是Structured Learning
GAN的Generator可以看成是Bottom UP的,因为它是一个模块一个模块学习的,例如在生成动漫头像的task中,它先学会生成轮廓,再学会生成眼睛,然后再学会生成嘴巴,然后一直下去
GAN的Discriminator可以看成是Top Down的,因为它是从整体来评判目标的好坏
1.3 Generator可以自己学吗?
基本思路:使用Supervised Learning的方式,给图片赋予一个向量,然后输入为该向量,输出为图片向量,目标是让Generator的输出与原始图片越接近越好。
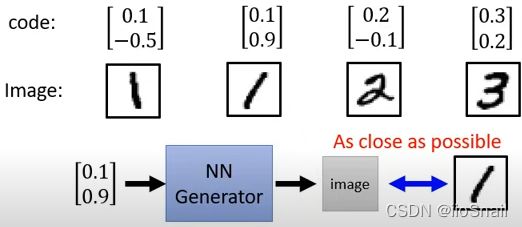
注意这里面的每一个dimension要对应一个特征,例如第一个dimension对应0.1,0.2对应着数字1,2, 而第二个-0.5,0.9对应旋转程度
如何定义上面的Code(输入向量)?可以使用Auto-Encoder
思路:将图片输入Encoder,进行编码,然后将编码送给Decoder去尽可能还原图片,最终Decoder就是我们要的Generator

缺陷:由于图片数量是有限的,无法穷举所有的Code,这样在测试阶段一旦给Decoder(也就是Generator)一个没见过的Code,可能就会瞎产生图片。但这个问题可以用 VAE(Variational Auto-Encoder) 解决
假设code是二维的,最终的效果为:

输入的每一个dimension代表着一种特征
VAE(Variational Auto-encoder)
思路:在原来的基础上改造Encoder,让Encoder多产生一个variance( σ \sigma σ),然后从distribution中拿出一组噪音向量( e e e),然后将三者合并(code,variance,噪音向量),得出新的向量送给Decoder
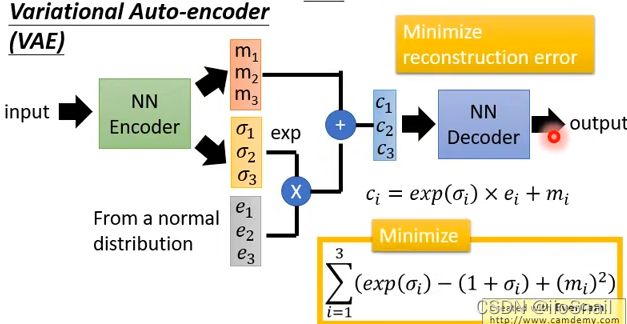
优点:由于结合了variance和噪音,可以使Decoder(Generator)更加稳定,使得在测试阶段即使看到了没有见过的输入,也能产生合理的图片
2. CGAN, Conditional Generation by GAN
Conditional GAN(CGAN):要指定GAN生成什么类别的图片,即在输入的时候,除了随机的noise,还要额外给GAN一个class,来指代要输入的类别,例如“dog”、“cat”等

同样,在训练Discriminator的时候,也要考虑class

Conditional GAN的训练过程(公式版):
先Train Discriminator
1. 从数据集中拿出 m m m 个样本 { ( c 1 , x 1 ) , ( c 2 , x 2 ) , … , ( c m , x m ) } \{ (c^1, x^1),(c^2, x^2),\dots,(c^m, x^m) \} {(c1,x1),(c2,x2),…,(cm,xm)},其中 x i x^i xi 是图片, c i c^i ci 是图片对应的类别
2. 从distribution中拿出 m m m 个噪音向量 { z 1 , z 2 , … , z m } \{ z^1, z^2, \dots, z^m \} {z1,z2,…,zm}
3. 让Generator根据噪音向量和类别生成数据 { x ~ 1 , x ~ 2 , … , x ~ m } \{ \tilde{x}^1, \tilde{x}^2, \dots, \tilde{x}^m \} {x~1,x~2,…,x~m},即 x ~ i = G ( c i , z i ) \tilde{x}^i =G(c^i, z^i) x~i=G(ci,zi)
4. 再从数据集中拿出 m m m 个样本 { x ^ 1 , x ^ 2 , … , x ^ m } \{ \hat{x}^1, \hat{x}^2, \dots, \hat{x}^m \} {x^1,x^2,…,x^m},这次不拿对应类别
5. 更新Discriminator的参数 θ d \theta_d θd,步骤如下:
5.1 让Discriminator判别真实样本及其对应的类别,即 D ( c i , x i ) ∈ [ 0 , 1 ] D(c^i, x^i) \in [0,1] D(ci,xi)∈[0,1],该值越大越好
5.2 让Discriminator判别生成样本及其对应的类别,即 D ( c i , x ~ i ) D(c^i, \tilde{x}^i) D(ci,x~i) , 该值越小越好
5.3 让Discriminator判别真实样本对应错误的类别,即 D ( c i , x ^ i ) D(c^i, \hat{x}^i) D(ci,x^i),该值越小越好。
5.4. 计算 m m m 个样本的“损失函数”, V ~ = 1 m ∑ i = 1 m log D ( c i , x i ) + 1 m ∑ i = 1 m log ( 1 − D ( c i , x ~ i ) ) + 1 m ∑ i = 1 m log ( 1 − D ( c i , x ^ i ) ) \tilde{V} = \frac{1}{m}\sum_{i=1}^{m}\log D(c^i, x^i) + \frac{1}{m}\sum_{i=1}^{m}\log\left( 1- D(c^i, \tilde{x}^i)\right) + \frac{1}{m}\sum_{i=1}^{m}\log\left( 1- D(c^i, \hat{x}^i)\right) V~=m1i=1∑mlogD(ci,xi)+m1i=1∑mlog(1−D(ci,x~i))+m1i=1∑mlog(1−D(ci,x^i)) 其中 V ~ \tilde{V} V~ 是负数,所以越大越好
5.5. 更新参数 θ d \theta_d θd,即 θ d ← θ d + η ∇ V ~ ( θ d ) \theta_d \leftarrow \theta_d + \eta\nabla\tilde{V}(\theta_d) θd←θd+η∇V~(θd)
接下来Train Generator
6. 从distribution中拿出 m m m 个噪音向量 { z 1 , z 2 , … , z m } \{ z^1, z^2, \dots, z^m \} {z1,z2,…,zm}
7. 从数据集中挑选出 m m m 个类别 { c 1 , c 2 , … , c m } \{ c^1, c^2, \dots, c^m \} {c1,c2,…,cm}
8. 更新Generator的参数 θ g \theta_g θg,更新过程如下:
8.1. 让Generator生成一组数据,然后送给Discriminator进行判别,并得出分数 D ( G ( c i , z i ) ) D\left(G(c^i, z^i)\right) D(G(ci,zi))
8.2. 计算“损失函数” V ~ = 1 m ∑ i = 1 m log D ( G ( c i , z i ) ) \tilde{V} = \frac{1}{m}\sum_{i=1}^{m}\log D\left(G(c^i, z^i)\right) V~=m1i=1∑mlogD(G(ci,zi)) 同样, V ~ \tilde{V} V~ 是负数,所以越大越好
8.3. 更新Generator的参数, θ g ← θ g + η ∇ V ~ ( θ g ) \theta_g \leftarrow \theta_g + \eta\nabla\tilde{V}(\theta_g) θg←θg+η∇V~(θg)
2.1 discriminator的架构改进
常见的架构是将“样本是否真实”和“样本与类别是否对应”的两个分数结合起来,给定一个分数,但是这样会有一个缺点:Network可能无法分辨当前的低分是样本不够真实导致的还是样本类别不对应导致的。
原始的样子:
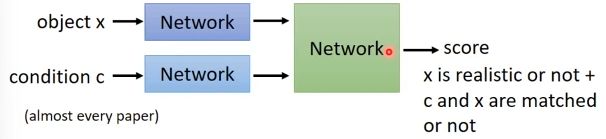
Discriminator改进的架构:将“真实性判别”和“类别是否对应”分开来:
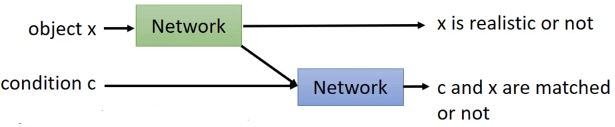
2.2 Stack GAN
Stack GAN:Conditional GAN 的一种,思路为:先产生小的图片,然后再产生大的图片。 论文链接:StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
2.3 Image-to-image
论文链接:Image-to-Image Translation with Conditional Adversarial Networks
Image-to-image:给机器一张图片,然后让他产生一张新的图片。 例如,给机器一张卡通图片,让机器产生一个真实的图片。
思路:给Generator一个早已向量 z z z 和图片,然后Generator产生一个新的图片。接下来把输入图片和输出图片同时丢给Discriminator,让其产生一个Scalar来评判结果的好坏

Patch GAN:上面的Gan并不是一次处理整张图片,因为图片太大会导致overfiting和训练时间长的问题。所以它是每次拿输入图片的一小块区域,然后进行处理,这个技术称为 Patch GAN
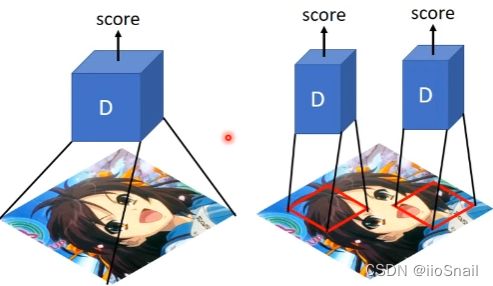
2.4 Speech Enhancement(提升语音的质量)
Speech Enhancement:使用算法提升语音的质量,称为Speech Enhancement

左边是包含噪音的声音,右边是enhance之后,不包含噪音的部分
传统的做法:使用Supervised learning的方式进行训练,目标是使得Output(输出的清晰的语音)和标签(真实清晰的语音)越接近越好
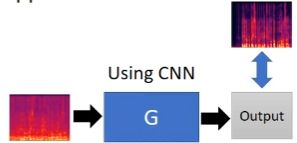
用GAN的方式:在“传统的做法”上增加Discriminator,让Discriminator判断产生的输入和输出是不是“一对”

2.5 Video Generation
Video Generation:给机器一段视频,然后让机器产生接下一帧的画面
思路:给Generator前几帧的画面,让其产生下一帧的画面。然后把产生的帧画面和之前的画面接起来,送给Discriminator,让其判断这是否是个合理的视频

3. Unsupervised Conditional Generation
Unsupervised Conditional Generation:给机器两堆数据,目的是让机器根据一种风格的数据生成另一种风格的数据。但训练资料并没有标注哪两个数据是一对。 例如,我们想根据真实的图片生成油画风格的图片

3.1 方法1:直接转换
思路:训练一个Generator使得其可以将输入从domain X转换到另一个domain Y。同时再训练一个Discriminator,任务是判断一个输入是不是domain Y的。

直接这样做有一个缺点:Generator可能会产生一个跟原图完全无关的东西,只要这个东西能让Discriminator认为是domain Y的就行了。所以需要加一些constraint
目前文献上的做法:
1. 啥都不管,直接train,因为network本身就会倾向于不要对输入改造太多,尤其是Network比较浅的时候。相关论文:The Role of Minimal Complexity Functions in Unsupervised Learning of Semantic Mappings
2. 对Generator的输入和输出进行embedding(例如利用VGG等预训练好的模型进行embedding),然后让两个embedding越接近越好

3. 使用Cycle GAN
基本思路:训练两个Generator,第一个是将输入从domain X转到domain Y(这个是最终需要用的)。第二个Generator是将第一个Generator的输出再从domain Y转回domain X,然后让第二个Generator的输出和一开始的输入越接近越好。
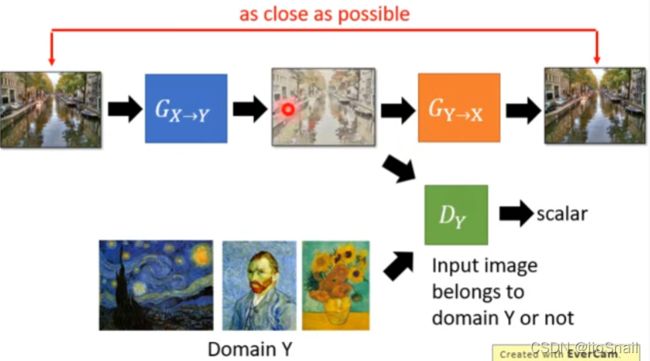
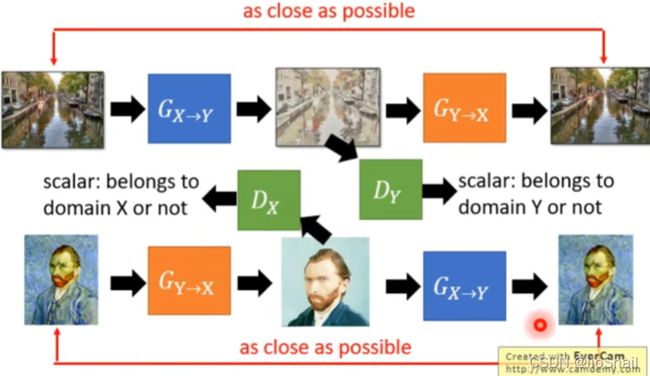
进阶思路:Discriminatior也可以做循环。之前只有一个Discriminator,用来判断输出 G X → Y G_{X\rightarrow Y} GX→Y 的输出是否是domain Y。现在再增加一个Discriminator,判断 G Y → X G_{Y\rightarrow X} GY→X 的输出是不是domain X。
方法2:VAE GAN: Project to Common Space
假设我们要将真实人物头像转为动漫人物,我们可以这么做:训练两组VAE,第一对Encoder和Decoder负责对真实人物进行编码和解码,第二对儿Encoder和Decoder负责对动漫人物进行编码和解码。当我们需要转换时,我们只需要将真实人物头像使用第一对的Encoder进行编码,然后用第二对的Decoder进行解码即可。
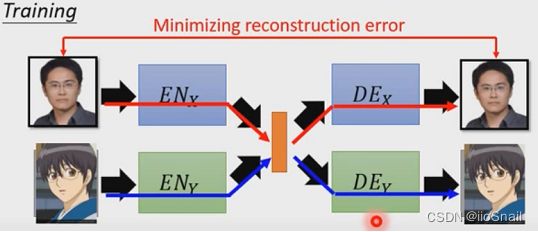
训练两组VAE,分别针对真实人物头像和动漫人物头像。
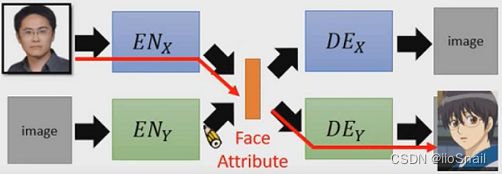
训练完成后,我们只需要将真实人物头像使用 E N X EN_X ENX进行编码,然后使用 D E Y DE_Y DEY进行解码,这样就能成功转换了。
上述方法存在一个问题:第一组VAE的中间向量和第二组的不一定兼容。例如,真实人物的向量编码第一个dimension可能代表性别,第二个代表年龄,而动漫人物的向量编码可能正好是反过来的,这样就会导致生成的动漫人物和真实人物相差甚远。
为了解决上述问题,一个常见的方法为:共享Encoder的最后几层和Decoder的前几层权重

除此之外还有许多其他方法,更多的方法可参考视频:https://www.youtube.com/watch?v=-3LgL3NXLtI&list=PLJV_el3uVTsMq6JEFPW35BCiOQTsoqwNw&index=3
GAN(生成对抗网络)全系列(二)
由于CSDN对文章长度有限制,所以进行分篇:
GAN(生成对抗网络)全系列(二)链接:https://blog.csdn.net/zhaohongfei_358/article/details/123953391
更多资料
- 各式各样的GAN:https://github.com/hindupuravinash/the-gan-zoo