TF-IDF算法讲解
什么是 TF-IDF 算法?
TF(全称TermFrequency),中文含义词频,简单理解就是关键词出现在网页当中的频次。
IDF(全称InverseDocumentFrequency),中文含义逆文档频率,简单来说就是该关键词出现在所有文档里面的一种数据集合。
TF-IDF用来评估字词对于文档集合中某一篇文档的重要程度。TF-IDF的计算公式为:
TF-IDF = 某文档中某词或字出现的次数/该文档的总字数或总词数 * log(全部文档的个数/(包含该词或字的文档的篇数)+1)
TF-IDF的思想比较简单,但是却非常实用。然而这种方法还是存在着数据稀疏的问题,也没有考虑字的前后信息。
在信息检索中,tf-idf或TFIDF(术语频率 – 逆文档频率的缩写)是一种数字统计,旨在反映单词对集合或语料库中的文档的重要程度。
它经常被用作搜索信息检索,文本挖掘和用户建模的加权因子。tf-idf值按比例增加一个单词出现在文档中的次数,并被包含该单词的语料库中的文档数量所抵消,这有助于调整某些单词在一般情况下更频繁出现的事实。Tf-idf是当今最受欢迎的术语加权方案之一;数字图书馆中83%的基于文本的推荐系统使用tf-idf。比如关键词“中国”在A网页里面出现了100次,那么它的TF值则是100次(词频),假设搜索引擎所收录的所有网页里面有1亿网页包含“中国”该关键词,那么IDF将由IDF公式计算出它对应的数据值。统一来理解则是TF是计算自己网页内的关键词频次,而TDF是计算所有文档里面包含该关键词的一种概率数值。
搜索引擎经常使用tf-idf加权方案的变体作为在给定用户查询的情况下对文档的相关性进行评分和排序的中心工具。tf-idf可以成功地用于各种主题领域的停用词过滤,包括文本摘要和分类。
TF (Term Frequency)—— “单词频率”
意思就是说,我们计算一个查询关键字中某一个单词在目标文档中出现的次数。举例说来,如果我们要查询 “Car Insurance”,那么对于每一个文档,我们都计算“Car” 这个单词在其中出现了多少次,“Insurance”这个单词在其中出现了多少次。这个就是 TF 的计算方法。
TF背后的隐含的假设是,查询关键字中的单词应该相对于其他单词更加重要,而查询关键字中的单词相对文档的重要程度,即查询关键字中的单词与文档的的相关度,与单词在文档中出现的次数成正比。比如,“Car” 这个单词在文档 A 里出现了 5 次,而在文档 B 里出现了 20 次,那么 TF 计算就认为文档 B 可能更相关。
然而,信息检索工作者很快就发现,仅有TF不能比较完整地描述文档的相关度。因为语言的因素,有一些单词可能会比较自然地在很多文档中反复出现,比如英语中的 “The”、“An”、“But” 等等。这些词大多起到了链接语句的作用,是保持语言连贯不可或缺的部分。然而,如果我们要搜索 “How to Build A Car” 这个关键词,其中的 “How”、“To” 以及 “A” 都极可能在绝大多数的文档中出现,这个时候 TF 就无法帮助我们区分文档的相关度了。
IDF(Inverse Document Frequency)—— “逆文档频率”
就在这样的情况下应运而生。这里面的思路其实很简单,那就是我们需要去 “惩罚”(Penalize)那些出现在太多文档中的单词。
也就是说,真正携带 “相关” 信息的单词仅仅出现在相对比较少,有时候可能是极少数的文档里。这个信息,很容易用 “文档频率” 来计算,也就是,有多少文档涵盖了这个单词。很明显,如果有太多文档都涵盖了某个单词,这个单词也就越不重要,或者说是这个单词就越没有信息量。因此,我们需要对 TF 的值进行修正,而 IDF 的想法是用 DF(文档频率) 的倒数来进行修正。倒数的应用正好表达了这样的思想,DF 值越大越不重要。
让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。
一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行"词频"(Term Frequency,缩写为TF)统计。
结果你肯定猜到了,出现次数最多的词是----“的”、“是”、“在”----这一类最常用的词。它们叫做"停用词"(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、“蜜蜂”、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,“蜜蜂"和"养殖"的重要程度要大于"中国”,也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词(“的”、“是”、“在”)给予最小的权重,较常见的词(“中国”)给予较小的权重,较少见的词(“蜜蜂”、“养殖”)给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是这个算法的细节。
第一步,计算词频。

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

或者

第二步,计算逆文档频率。
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
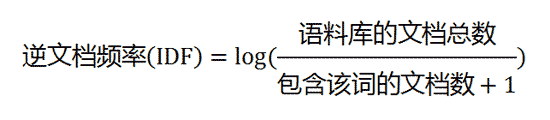
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF。
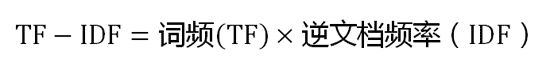
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,“中国”、“蜜蜂”、“养殖"各出现20次,则这三个词的"词频”(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
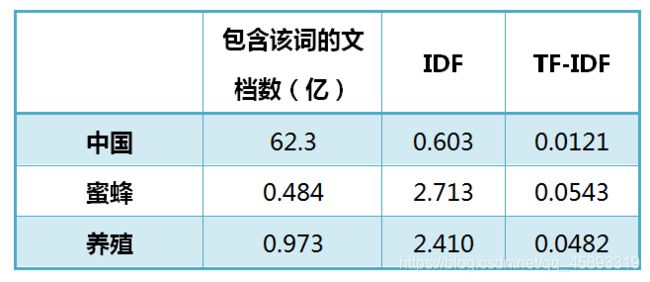
log(250亿/(62.3亿+1))约等于0.603
“中国”这个词的词频怎么算的就不知道了
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词(“中国”、“蜜蜂”、“养殖”)的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。这一点对于SEO特别重要)
TF-IDF算法思想:
TF-IDF的核心思想是通过该算法进行有效的计算网页的核心关键词。虽然语义分析以及中文分词能够简单的计算出页面的关键词主题,但是由于互联网内容信息重复度较大,同一个内容单纯从分词角度来讲是不足以满足搜索引擎针对网页的内容是否更加符合用户的需求。而TF-IDF则可以用过算法公式来计算用户搜索词与网页之间的相似度。
比如网页标题“小黑的同桌叫马天”,这里面“的”、“叫”在搜索引擎里面一般都称为停用词(stop words),也就是无意义词。而去掉这些词剩下的词则是小黑、同桌、马天。根据分词原理,这三个词都是名词,那么作为用户而言去看这个标题明显知道是阐述马天是网页的核心关键词,但是对于搜索引擎来说并不能深刻的理解该网页的核心关键词。对于这三个词,一般我们都有一个词的重要程度系数。从常见度来说,越常见的东西则不重要,反之越不常见越重要。那么搜索引擎是如何知道该词的常见程度呢?可以通过相关搜索结果数来计算关键词的重要度。
TF-IDF算法应用:(以下两段我再次看只是大概懂了)
关于TF-IDF的算法实战应用,最常见的方式则是利用TF-IDF算法的计算方式来进行定位网页的核心词,从而网站大量提升关键词排名。首先我们要理解真正原创文章的含义,真正的内容原创有两种,一种是网页内容与总语料库文档不重合,另一种则是关键词与该关键词的相关结果文档不重合。而TF-IDF最佳的运用方式则是可以采用换汤不换药的操作方式来进行关键词排名。比如优化一个关键词“山药的功效与作用”,那么我们可以去抄袭一篇“人参的功效与作用”的文章,并且替换网页里面的所有人参关键词,尽管这篇文章在人参里面是重复性很高的文章。但是在山药的功效与作用里面它就是独一无二的。并且刻意增加山药文章里面的TF值,让搜索引擎认定该网页的核心关键词。
镜像站专门干这事!
网站镜像是通过TF-IDF算法应用的经典案例,内容全部抄袭,网页标题(title)与文章标题不同,目的就是用来提升网页的点击率。并且文章标题我们可以发现互博国际该关键词是一个由多个词组成的词组,通过分词符号可以让互博国际变成一个关键词(词组形成关键词)。并且在网页内容里面,自然的分布关键词的频次(TF),从而达到关键词的强调性,即使内容在其他文章里面出现,但是在互博国际里面,该内容则是独一无二的原创(不重合)。为了提升网页的点击率,我们可以将网页的标题(title)写的更加规范,这样排名一旦上来,还有利于用户的点击,从而提升网页关键词的排名更佳状态。
以上参考:SEO算法篇,TFIDF算法讲解及在SEO中的利用
代码 看看就行(没必要会写,会复制粘贴即可)
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vec = TfidfVectorizer()
# stop words自定义停用词表,为列表List类型
# token_pattern过滤规则,正则表达式,如r"(?u)bw+b
# max_df=0.5,代表一个单词在 50% 的文档中都出现过了,那么它只携带了非常少的信息,因此就不作为分词统计
documents = [
'this is the bayes document',
'this is the second second document',
'and the third one',
'is this the document'
]
tfidf_matrix = tfidf_vec.fit_transform(documents)
# 拟合模型,并返回文本矩阵 表示了每个单词在每个文档中的 TF-IDF 值
print('输出每个单词在每个文档中的 TF-IDF 值,向量里的顺序是按照词语的 id 顺序来的:', '\n', tfidf_matrix.toarray())
print('不重复的词:', tfidf_vec.get_feature_names())
print('输出每个单词对应的 id 值:', tfidf_vec.vocabulary_)
print('返回idf值:', tfidf_vec.idf_)
print('返回停用词表:', tfidf_vec.stop_words_)