课程笔记-三维点云处理03 ——Clustering聚类
课程笔记-三维点云处理03 ——Clustering聚类
本系列笔记是对深蓝学院所开设的课程:《三维点云处理》的笔记
课程每周更新,我也会努力将每周的知识点进行总结,并且整理成笔记发上来,欢迎各位多多交流&批评指正!!
本文主要为课程第三章的笔记!
课程链接:
三维点云处理——深蓝学院
目录
正式内容:
####################################################
Math prerequisite
聚类定义

聚类就是一种按一定特征分类的问题:

上图为五种常见的python交互算法
方法的背后有很多的数学原理
线性代数、高等数学、概率论等一些数学基础都会被用到

线性代数方面
- 谱定理(之前课上有讲过)

- 瑞丽熵

上面两个定理都非常的重要,在谱聚类的时候会用到。
概率论方面
- 联合概率 离散、连续都需要讨论
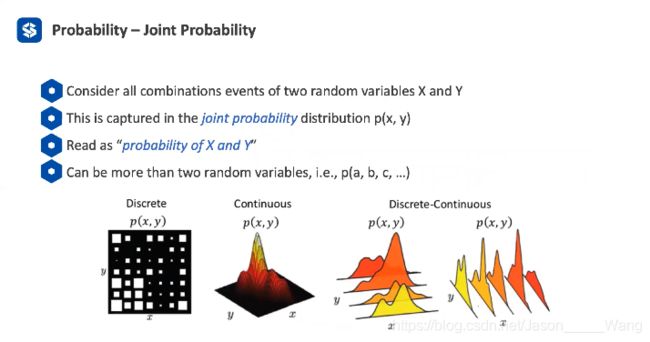
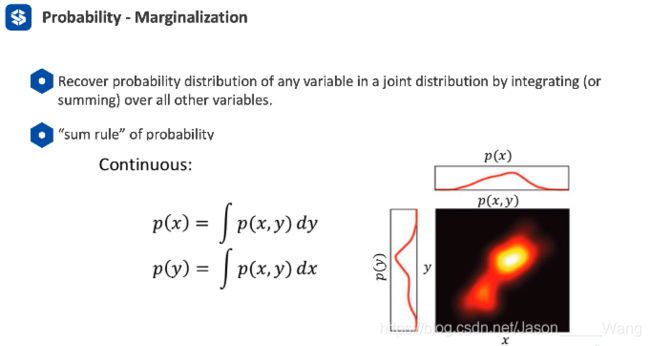
2. 边缘分布 marginalization
一个联合概率的 heatmap
离散的情况:

3. 条件概率
联合概率不关心另一个参数,而条件概率需要知道参数,只考虑这一条线就好了 而联合概率是一整条线的分布
条件概率并不是一个合法的分布,但是可以通过一个归一化进行分布
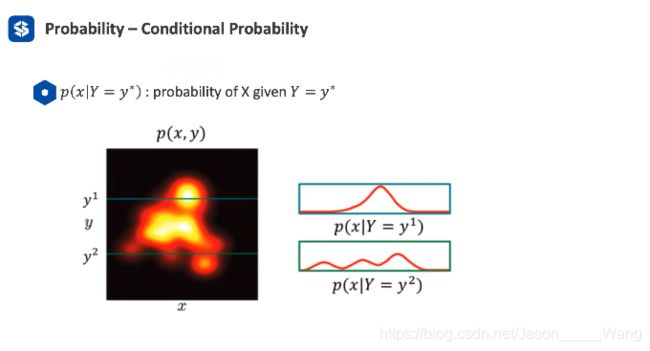
条件概率并不是一个合法的分布,但是可以通过一个归一化进行分布,即贝叶斯公式

进一步 贝叶斯公式可以被拓展成四种公式。

4. 图论相关知识

有向图:即两个参数是有联系的(有相关性)就可以以有向图的形式表示
如果两个事件独立,则无法用有向图表示
- 需要记住公式 p(x,z) =p(z)p(x|z) 以及右边的两节点的有向图 后续会用到

无向图: 各个参数之间只有联通关系而没有因果关系
- 优化方法
拉格朗日乘子法

应用于有条件的优化问题
即当一个点为最优值的时候,他一定是跟梯度方向相反,法线相切的,否则的话就会有梯度方向上的分量,还可以望梯度方向走
用数学公式的方法表示:

即解决一个 三个变量的一阶导数等于零的方程
K-Means
常见、简单、且效果非常好
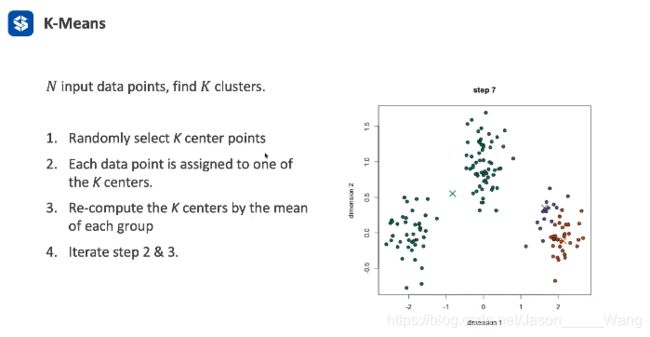
特点:需要给定类属 他不会自己生成
步骤:
- 随机选择K个中心作为K个类的中心点
- 计算每个点属于哪一个类(离哪个核最近)
- 更新中心点位置,(把类里面的中心点作为新核
- 重复上述过程



其实核心的部分两步:
固定中心 ,去归类
固定类,选取中心
对应上述的两个图
举例说明:
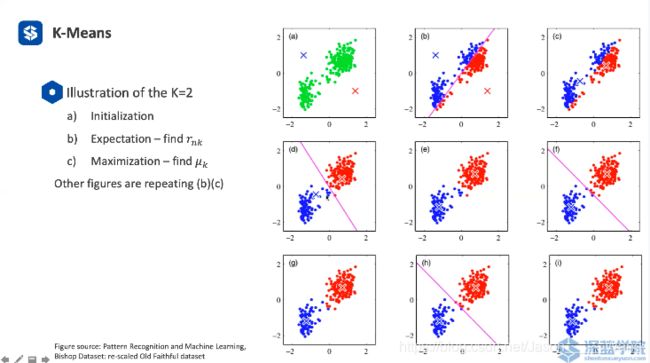
一直迭代
迭代停止有两个条件: (判断是否收敛)
1.类的中心点不再移动或者移动的特别小
2. 连续两次迭代的分类不在改变(就永远的都不改变了)
3. 还有可能出现的一点就是 循环 有一些点不断跳动,导致无限循环(也要考虑 可以设置一个最大迭代次数)
技巧

- 不应该随机选取中心点 而是应该选数据点中的随便一个点(能节省很多次)
- 对同样的数据跑几次kmeans 取损失函数最小的结果(因为会受到初始化的随机性影响)

只考虑一个点时 就变成了 sequential Kmeans
k-medoids:改进版K-means


如果数据有噪声,就会被拉偏(受极端值影响)
用距离之和最小的数据点中的一个点 代替平均值 进行核替代
而且还能判断猫狗之类不可量化的 东西(如1当猫2当狗 这种聚类方法就可以做聚类)
局限:如果距离不能用的话,就用不了聚类
Kmeans 的应用:
- 可以用来做压缩

比如对一个图片来说,可以把Nx3的点变成Kx3的点 即可以把Nx3压缩成N个 标签

就是选取几种颜色代替原有的多种颜色
事实上,用10-20种颜色就一定能代替了(根据上面) 而不压缩的话可能会有1600万种颜色
其实就可以将3个通道变成一个通道,然后就储存一个标签就好了

压缩率事实上是非常高的
不足与限制
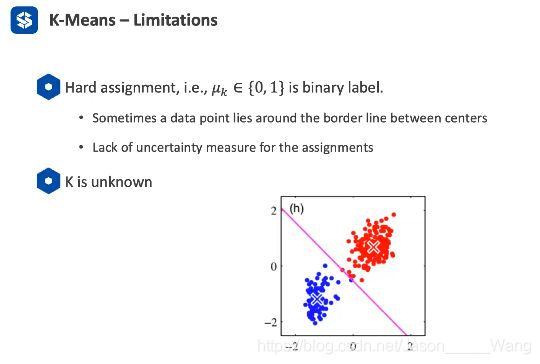
- k是不知道的 所以是靠实验的
- 对噪声很敏感 所以可能要缓解
- 是非常绝对的判断,没有概率信息 (如边界点就没有办法判断)
Gaussian Mixture Model (GMM)
高斯混合模型
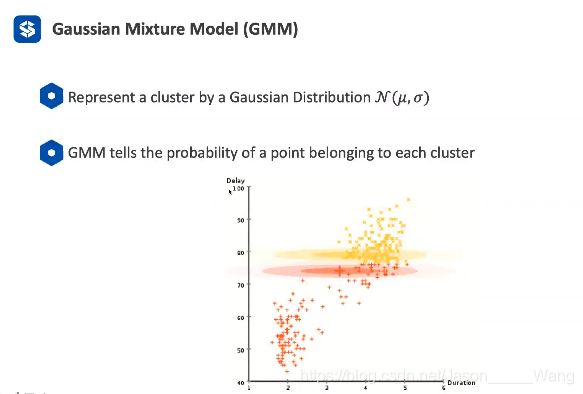
可以理解成,在K-Means 的基础上,对每一个类用一个高斯分布来描述
高斯分布复习:
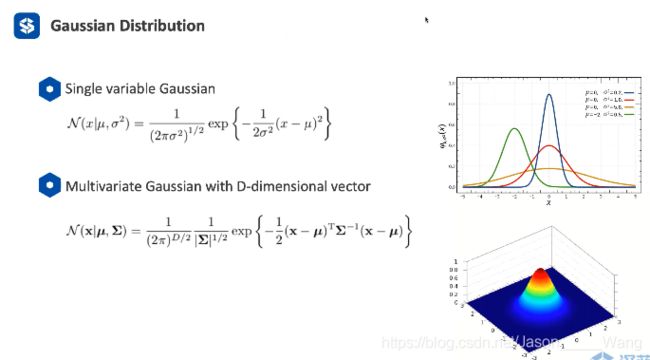

数学上,GMM表示为k个高斯模型的组合 (其中K 是给定的)
所以 一个GMM是由3个参数描述的,μ σ π
如果确定了这三个参数,就能确定一个高斯分布
(可以根据高斯分布用来产生新的数据)
 Zk 用来表达一个点属于哪一个类 等于就为1 不等于就为0 但这个是有概率的
Zk 用来表达一个点属于哪一个类 等于就为1 不等于就为0 但这个是有概率的
要考虑先验分布


后验概率计算:

但是问题是 高斯模型的参数是需要计算的:不是已知的

就是上面这两个核心的公式

如果出现一个点就是一个高斯分布的情况,方差为0,就会把系统搞崩
这个时候MLE就不再适用了,需要换做其它的模型

或者如果出现一个方差数值为零或者特别小,就强行把他初始化成另一个值就可以了




可以转化成一个求拉格朗日乘子法的问题

总结 如何做GMM MLE

1.E-step 算后验概率 γ

2.算M-step 高斯模型
表达为图像可以理解成这样:

Expectation-Maximization (EM)

刚才所讲到 的 estep 和mstep 其实都是从EM算法中获取的
EM算法也是一个非常重要的模型
它所解决的问题: 给定一堆数据点 用最大似然的方法估算出模型的参数 θ(不断迭代优化θ)

回顾一下 GMM函数:
可以发现 可以用最大似然优化概率函数,也可直接用EM优化算子,得出的结论其实是一样的

回顾一下 k-means
事实上 Kmeans 是一种特殊的 GMM

可以把Kmeans 看成一个方差为0的GMM
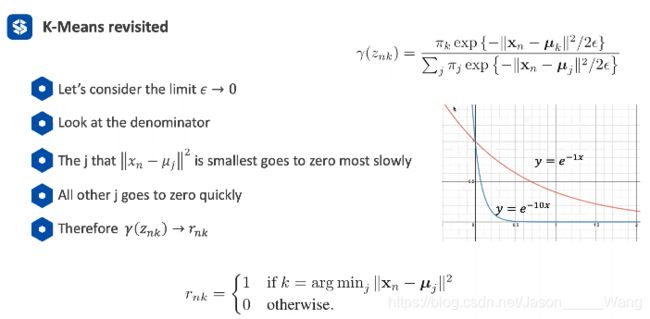
总结

EM是一个通用的算法 GMM可以认为是一个EM的应用(应用在高斯线性组合) Kmeans又可以理解成一个GMM的特殊情况
总结: KNN

总结 GMM
复杂度跟Kmeans 一样

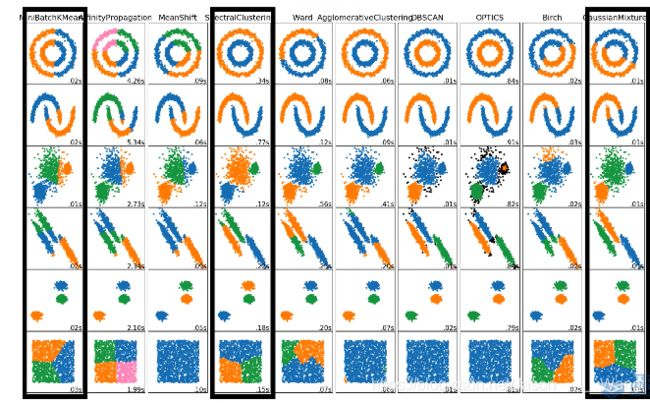
可以看到 针对不同形状或聚类方式不同的点,
KMEANS 和GMM有时表现的都不够好 因为Kmeans倾向于按圆分类,而 GMM倾向于按椭圆分类
所以后来要介绍 谱聚类 也就是中间的那个框 可以解决常见的点聚类,有较好的适应性
Spectral Clustering

GMM和kMEANS一般都是基于欧式空间上的,所以都会按照圆或者椭圆去聚类
但是谱聚类关注的是点与点的连接性

会用到无向图的概念:节点与节点之间有无方向的连线
可以把一个无向图画成矩阵的形式,一类的和不一类的 (是对称矩阵,所以对角线为0)
建立谱聚类

3种方法确定怎么是一类
- 有权重的连线(距离的导数)根据相似度取连线
- 只与跟他最近的K个点有连线 分两种:一种是 单方面是最近的K个即可建立连线 另一种是双方都是才建立连线 同样根据距离的远近进行排序
- 每一个节点间都有连线
建立矩阵:

建立一个对角矩阵D 储存每一列对角的和 物理意义是其所连接的点所有权重的位置之和
建立一个拉普拉斯矩阵L : 最简单的L可以用L=D-W
然后有两种方法对拉普拉斯矩阵进行归一化
 谱聚类 大概总结成三个步骤:
谱聚类 大概总结成三个步骤:
- 找去相似矩阵
- 做特征值分解 找出K个最小特征值
- 在特征值上做Kmeans
衍生: 归一化与特征化 的谱聚类

上图为归一化的,其实就是用了归一化的拉普拉斯算子

经过归一化的谱聚类 更倾向于每一个类里面的密度是接近的
没有归一化的谱聚类倾向于每个点的数量是均等的
结合具体应用具体进行分析
谱聚类的效果
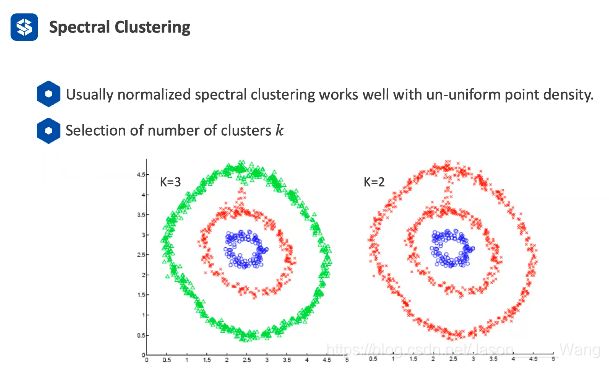
不同的参数会导致不一样的结果
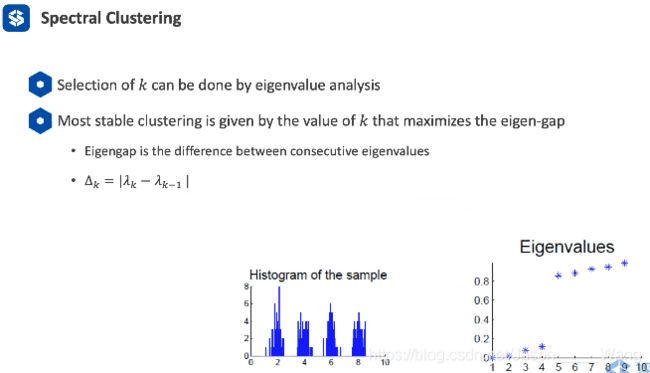
总结:
谱聚类可以理解成经过一个拉普拉斯的Kmeans

复杂度:N的三次方
优点是基于连结性的,而不是基于欧氏距离的
另一个优点是可以自己发现种类
但是缺点是复杂度极高
总结
 讲了三种建模方法
讲了三种建模方法
作业
用自己方法做出分类的数据集,并可视化
