吴恩达机器学习作业1-线性回归
题目概述: 整个2的部分需要根据城市人口数量,预测开小吃店的利润 数据在ex1data1.txt里,第一列是城市人口数量,第二列是该城市小吃店利润。
用到2个公式:
代价函数:

![]()
批量梯度下降 进行优化:

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#print(np.eye(5)) #简单练习
path ='ex1data1.txt'
data = pd.read_csv(path, header=None, names=['Population', 'Profit'])
#header=None即指定原始文件数据没有列索引,names为列索引添加名字
#print(data.head()) #header显示前5行
#print(data.describe()) #数据详细值分析
data.plot(kind='scatter', x='Population', y='Profit', figsize=(12,8))
#print(plt.show()) #输出图
data.insert(0, 'Ones', 1)#在第0列插入一列,这列值全为1
clos=data.shape[1] #shape[1]取列数,[0]取行数
X=data.iloc[:,0:clos-1]#iloc,行全选,选0,1列,是前闭后开集合
y=data.iloc[:,clos-1:clos]#选最后一列
#print(X.head()) #验证X,y
#print(y.head())
X = np.matrix(X.values)#将X,y转化成矩阵
y = np.matrix(y.values)
theta=np.matrix([0,0]) #将theta转化成空矩阵
def computeCost(X, y, theta):#计算代价函数
inner=np.power(((X*theta.T)-y),2)
return np.sum(inner)/(2 * len(X))#len(X)为行数,即公式中的m
#print(computeCost(X, y, theta))
#批量梯度下降(优化)
def gradientDescent(X, y, theta, alpha, iters):#alpha学习率,iters迭代次数
temp = np.matrix(np.zeros(theta.shape))#一个与theta相同维度的0矩阵
parameters=int(theta.ravel().shape[1]) #ravel()将多维降为一维
cost = np.zeros(iters)#保存迭代之后的cost
for i in range(iters):
error=(X*theta.T)-y
for j in range(parameters):
term=np.multiply(error,X[:,j])
temp[0,j]=theta[0,j] - np.sum(term)*(alpha/len(X))
theta=temp
cost[i]=computeCost(X, y, theta)
return theta, cost
alpha = 0.01
iters= 1500
g,cost = gradientDescent(X, y, theta, alpha, iters)
print(g)
print(computeCost(X, y, g))#使用拟合值来计算代价函数(误差)
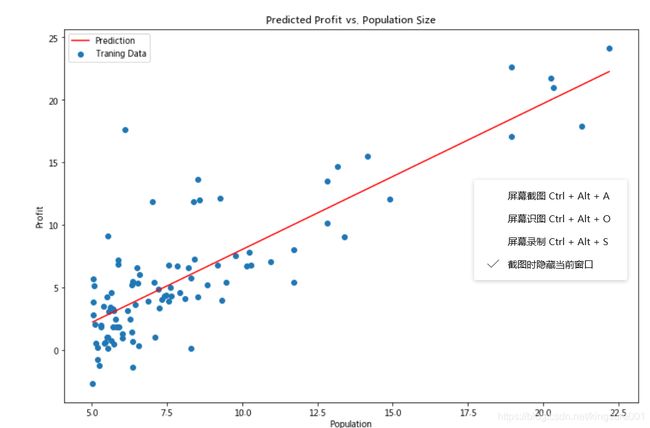
# 画图
x = np.linspace(data.Population.min(), data.Population.max(), 100) #横坐标在最大和最小之间分100份
f = g[0, 0] + (g[0, 1] * x)
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
print(plt.show())
多变量线性回归
ex1data2.txt里的数据,第一列是房屋大小,第二列是卧室数量,第三列是房屋售价 根据已有数据,建立模型,预测房屋的售价
虽然变成了多变量,之前的def gradientDescent()函数仍然可用,
原理一样,只需要换一个3个变量的数据集,但由于数据值之间相差较大,多了一个“归一化处理”
下面代码就不写之前写过的函数了;
path ='ex1data2.txt'
data2 = pd.read_csv(path, header=None, names=['Size', 'Bedrooms', 'Price'])
#header=None即指定原始文件数据没有列索引,names为列索引添加名字
#归一化处理
data2 = (data2 - data2.mean()) / data2.std()
#data2.mean()均值,data2.std()最大最小之间的差值
data2.insert(0, 'Ones', 1)
cols = data2.shape[1]# 初始化X2和y2
X2 = data2.iloc[:,0:cols-1]
y2 = data2.iloc[:,cols-1:cols]
# 转换成matrix格式,初始化theta
X2 = np.matrix(X2.values)
y2 = np.matrix(y2.values)
theta2 = np.matrix(np.array([0,0,0]))
g,cost = gradientDescent(X2, y2, theta2, alpha, iters)
print(g)
print(computeCost(X2, y2, g))#使用拟合值来计算代价函数(误差)
正规方程
![]()
用第一个数据集的完整代码:
import numpy as np
import pandas as pd
path ='ex1data1.txt'
data = pd.read_csv(path, header=None, names=['Population', 'Profit'])
data.insert(0, 'Ones', 1)#在第0列插入一列,这列值全为1
clos=data.shape[1] #shape[1]取列数,[0]取行数
X=data.iloc[:,0:clos-1]#iloc,行全选,选0,1列,是前闭后开集合
y=data.iloc[:,clos-1:clos]#选最后一列
X = np.matrix(X.values)#将X,y转化成矩阵
y = np.matrix(y.values)
theta=np.matrix([0,0]) #将theta转化成空矩阵
def normalEqn(X, y):
theta=np.linalg.inv(X.T@X)@X.T@y
return theta
theta=normalEqn(X, y)
print(theta)
正规方程与梯度下降的比较,请访问:
https://blog.csdn.net/kingsure001/article/details/107465231